
Cursus
Supervised Learning in R: Regressie
4 Hr
46.5K
Lineaire regressie is een krachtig hulpmiddel in data-analyse en data science. Het wordt gebruikt om de relatie te kwantificeren tussen een afhankelijke variabele en één of meer onafhankelijke variabelen. Als je bekend bent met lineaire regressie, ken je waarschijnlijk ook de veelgebruikte maat voor goodness-of-fit, r-kwadraat, die aangeeft welk deel van de variantie in de afhankelijke variabele wordt verklaard door de onafhankelijke variabele(n). Misschien ben je echter minder bekend met de aangepaste r-kwadraat, die vaak wordt gebruikt bij complexere modellen met meerdere voorspellers.
Dit artikel geeft je een volledig begrip van aangepaste r-kwadraat, het belang ervan bij modelbeoordeling, de belangrijkste verschillen met r-kwadraat en de toepassingen in meervoudige regressiescenario’s, zodat je deze modelstatistieken volledig beheerst. Als start raad ik je sterk aan om DataCamps cursussen Introduction to Regression with statsmodels in Python en Introduction to Regression in R te volgen om meer te leren over regressiemodellen en hoe je verschillende prestatiematen, waaronder aangepaste r-kwadraat, interpreteert.
R-kwadraat meet het deel van de variantie in de afhankelijke variabele dat wordt verklaard door de onafhankelijke variabele of variabelen van het model. De aangepaste r-kwadraat verklaart eveneens de variantie, maar houdt een extra factor in gedachten: zoals de naam al aangeeft, corrigeert het de r-kwadraatwaarde door het toevoegen van irrelevante, waarmee we sterk collineaire bedoelen, variabelen te bestraffen. Dit doet het door zowel het aantal voorspellers als de steekproefgrootte mee te nemen.
Om de aangepaste r-kwadraat te vinden, moeten we eerst de r-kwadraat bepalen. Hoewel er verschillende manieren zijn om de r-kwadraatwaarde te vinden, is de onderstaande formule een van de meest gangbare:
Hier wordt r-kwadraat berekend als één min het quotiënt van de som van kwadratische residuen over de totale som van kwadraten.
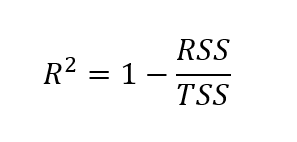
Waarbij:
Nadat we de r-kwadraatwaarde hebben gevonden, kunnen we de aangepaste r-kwadraat bepalen. Dat doen we door onze r-kwadraatwaarde in de onderstaande formule te vullen.
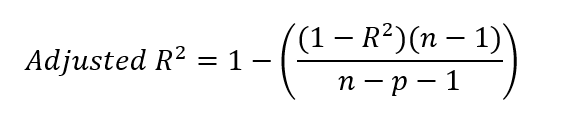
Waarbij:
Om te oefenen kunnen we een voorbeeld proberen. Stel: we hebben een dataset met 30 observaties. We maken een meervoudig lineair regressiemodel met vijf voorspellers. We vinden een r-kwadraat van 0,8. Zo kunnen we met deze informatie de aangepaste r-kwadraat bepalen:

Je vraagt je misschien af waar de -1 in de vergelijking vandaan komt, zowel in de teller als in de noemer. Ter verduidelijking: n−1 in de teller staat voor de vrijheidsgraden en corrigeert voor het gebruik van het steekproefgemiddelde bij het berekenen van de variantie. Dit komt omdat we bij het berekenen van de variantie doorgaans het steekproefgemiddelde gebruiken als schatting voor het populatiegemiddelde. Omdat het steekproefgemiddelde niet het werkelijke populatiegemiddelde is, wordt de variantie vaak onderschat. Om deze vertekening te corrigeren, verminderen we de vrijheidsgraden met 1.
In de noemer corrigeert n−p−1 voor het aantal voorspellers p in het model, waarbij p het aantal onafhankelijke variabelen is. De extra −1 in de noemer corrigeert voor het schatten van het intercept van het model, wat ook één vrijheidsgraad kost. Onthoud dat we in een regressiemodel zowel de hellingscoëfficiënten voor de voorspellers als het intercept schatten om de volledige complexiteit te dekken.
Hoewel zowel r-kwadraat als aangepaste r-kwadraat de prestaties van regressiemodellen evalueren, is er een belangrijk verschil tussen de twee statistieken. De r-kwadraatwaarde neemt altijd toe of blijft gelijk wanneer meer voorspellers aan het model worden toegevoegd, zelfs als die voorspellers de verklarende kracht van het model niet significant verbeteren. Dit kan een misleidende indruk geven van de effectiviteit van het model.
Aangepaste r-kwadraat corrigeert de r-kwadraatwaarde om rekening te houden met het aantal onafhankelijke variabelen in het model. De aangepaste r-kwadraatwaarde kan afnemen als een nieuwe voorspeller de model-fit niet verbetert, waardoor het een betrouwbaardere maatstaf voor modelnauwkeurigheid is. Om die reden kan aangepaste r-kwadraat door data-analisten worden gebruikt als hulpmiddel om te beslissen welke voorspellers ze meenemen.
Begrijpen wanneer je aangepaste r-kwadraat boven r-kwadraat gebruikt is belangrijk voor het bouwen van betrouwbare modellen. Hieronder staan scenario’s waarin aangepaste r-kwadraat geschikt is om modellen te evalueren.
In het algemeen heeft aangepaste r-kwadraat de voorkeur boven r-kwadraat in meervoudige regressiemodellen omdat het rekening houdt met het aantal voorspellers en het toevoegen van irrelevante variabelen bestraft. Toch zijn er situaties waarin r-kwadraat nog steeds passend kan zijn:
Laten we een voorbeeld bekijken waarin de nuances tussen r-kwadraat en aangepaste r-kwadraat een rol spelen. Stel dat we deze twee regressiemodellen hebben:
Je zou kunnen zeggen dat model 1 meer van de totale variantie in de data lijkt te verklaren omdat het een hogere r-kwadraatwaarde heeft. Maar we moeten ook meenemen dat model 2 mogelijk meer van de werkelijke onderliggende relatie tussen de variabelen verklaart, omdat het corrigeert voor irrelevante voorspellers. De hogere aangepaste r-kwadraat van model 2 suggereert dat het een betrouwbaardere fit biedt door onnodige complexiteit te bestraffen, en het is mogelijk ook minder gevoelig voor overfitting. Persoonlijk, en bij afwezigheid van andere informatie, zou ik model 2 kiezen.
Laten we praktische voorbeelden verkennen van het berekenen van aangepaste r-kwadraat in R en Python. We gebruiken de “Fish Market”-dataset van Kaggle, die handig is om het gewicht van een vis te schatten op basis van soort en fysieke metingen. Voor de eenvoud ronden we de uitvoer af op vijf decimalen.
Download de dataset en sla die op in je werkmap. Gebruik de volgende code om een lineair model te fitten dat het gewicht van de vis voorspelt als functie van een paar verschillende variabelen, waaronder Length1, Height, Width en Length3, die respectievelijk verwijzen naar de verticale lengte van de vis, de hoogte van de vis, de diagonale breedte van de vis en de kruislengte van de vis.
# Load the dataset
data <- read.csv("data/Fish.csv")
# Remove rows with missing values
data <- na.omit(data)
# Model 1: Using 4 predictors ('Length1', 'Height', 'Width', 'Length3')
model1 <- lm(Weight ~ Length1 + Height + Width + Length3, data = data)Nu controleren we de r-kwadraat en aangepaste r-kwadraat, en we zien het volgende. De aangepaste r-kwadraat ligt heel dicht bij de r-kwadraatwaarde, net iets lager.
r_squared_model1 <- round(summary(model1)$r.squared, 4)
r_squared_model1 <- round(summary(model1)$adj.r.squared, 4)0.88527
0.88229Wat als we nu een ander model proberen door nog een voorspeller toe te voegen? Deze keer maken we een tweede model en voegen we Length2 toe, wat verwijst naar de diagonale lengte van de vis. Op dezelfde manier als hiervoor kunnen we de r-kwadraat en aangepaste r-kwadraat van ons nieuwe model controleren.
# Model 2: Adding one more predictor ('Length2')
model2 <- lm(Weight ~ Length1 + Height + Width + Length3 + Length2, data = data)r_squared_model2 <- round(summary(model1)$r.squared, 4)
r_squared_model2 <- round(summary(model1)$adj.r.squared, 4)0.88529
0.88154Voor model 2 zien we dat de r-kwadraatwaarde vergeleken met model 1 nauwelijks is toegenomen. Ook zien we dat de aangepaste r-kwadraat is gedaald, en die daling was groter dan de toename in r-kwadraat. Dit vertelt ons dat de toegevoegde voorspeller geen goede was.
Als je erover nadenkt, was Length2, de diagonale lengte van de vis, waarschijnlijk sterk gecorreleerd met ofwel de andere variabelen in het model of een lineaire combinatie daarvan. In het bijzonder verwachten we dat de diagonale lengte van de vis sterk samenhangt met de lengte van de vis en de kruislengte van de vis. We zien dus dat onze nieuwe variabele geen nieuwe, relevante informatie toevoegde.
Voor de volledigheid kunnen we ook laten zien hoe je de aangepaste r-kwadraat met de hand vindt. We gebruiken de r-kwadraatwaarde en de modelparameters en volgen de eerder getoonde formule.
# Save R-squared as a variable
r_squared_model2 <- summary(model2)$r.squared
# Get the number of observations (n) for both models
n <- nrow(data) # Same for both models
# Get the number of predictors (excluding intercept) for each model
p_model1 <- length(coef(model1)) - 1
p_model2 <- length(coef(model2)) - 1
# Adjusted r-squared formula for Model 1
adjusted_r_squared_model1 <- 1 - ((1 - r_squared_model1) * (n - 1)) / (n - p_model1 - 1)
# Adjusted r-squared formula for Model 2
adjusted_r_squared_model2 <- 1 - ((1 - r_squared_model2) * (n - 1)) / (n - p_model2 - 1)
# Print R-squared values for both models
cat("R-Squared for Model 1:", r_squared_model1, "\n")
cat("R-Squared for Model 2:", r_squared_model2, "\n")
# Print the Adjusted R-Squared values for both models
cat("Adjusted R-Squared for Model 1:", adjusted_r_squared_model1, "\n")
cat("Adjusted R-Squared for Model 2:", adjusted_r_squared_model2, "\n")De onderstaande code laat een implementatie van hetzelfde voorbeeld in Python zien.
# Import requied libraries
import pandas as pd
import statsmodels.api as sm
# Load the dataset
data = pd.read_csv('data/Fish.csv')
# Drop rows with missing values if any exist
data = data.dropna()
# Define predictors for Model 1 (4 variables)
X1 = data[['Length1', 'Height', 'Width', 'Length3']]
# Add a constant (intercept)
X1 = sm.add_constant(X1)
# Define the target variable 'Weight'
y = data['Weight']
# Fit Model 1
model1 = sm.OLS(y, X1).fit()
# Define predictors for Model 2 (5 variables)
X2 = data[['Length1', 'Height', 'Width', 'Length3', 'Length2']]
# Add a constant (intercept)
X2 = sm.add_constant(X2)
# Fit Model 2
model2 = sm.OLS(y, X2).fit()
# Save r-squared as a variable
r_squared_model1 = model1.rsquared # R-Squared for Model 1
r_squared_model2 = model2.rsquared # R-Squared for Model 2
# Get the number of observations
n = X1.shape[0] # Same for both models
# Get the number of predictors (excluding intercept) for each model
p_model1 = X1.shape[1] - 1 # Number of predictors for Model 1
p_model2 = X2.shape[1] - 1 # Number of predictors for Model 2
# Adjusted R-Squared formula for Model 1
adjusted_r_squared_model1 = 1 - ((1 - r_squared_model1) * (n - 1)) / (n - p_model1 - 1)
# Adjusted R-Squared formula for Model 2
adjusted_r_squared_model2 = 1 - ((1 - r_squared_model2) * (n - 1)) / (n - p_model2 - 1)
# Print R-squared for both models
print("R-Squared for Model 1:", r_squared_model1)
print("R-Squared for Model 2:", r_squared_model2)
# Print the Adjusted R-Squared values for both models
print("Adjusted R-Squared for Model 1:", adjusted_r_squared_model1)
print("Adjusted R-Squared for Model 2:", adjusted_r_squared_model2)We kunnen in Python ook functies gebruiken om de r-kwadraat en aangepaste r-kwadraat van de regressiemodellen te bepalen:
# Model 1
print("Model 1 R-Squared:", model1.rsquared)
print("Model 1 Adjusted R-Squared:", model1.rsquared_adj)
# Model 2
print("Model 2 R-Squared:", model2.rsquared)
print("Model 2 Adjusted R-Squared:", model2.rsquared_adj)Als je moeite had met de code hierboven, bekijk dan onze tutorials Essentials of Linear Regression in Python en How to Do Linear Regression in R voor een stapsgewijze gids om verschillende maten van het regressiemodel te implementeren en te interpreteren. Als Excel je voorkeurs-tool is, bekijk dan onze tutorial Linear Regression in Excel: A Comprehensive Guide For Beginners om te leren hoe je lineaire regressiemodellen in Excel implementeert en visualiseert.
Als we het over aangepaste r-kwadraat hebben, is het goed om onze termen scherp te houden. Er zijn termen die op elkaar lijken maar verschillende doelen hebben. Hier heb ik een tabel gemaakt die enkele gelijk klinkende maar verschillende begrippen vergelijkt: r-kwadraat, aangepaste r-kwadraat en voorspelde r-kwadraat.
| Metric | Measures | Use Case | Strengths | Limitations |
|---|---|---|---|---|
| R-squared | Aandeel van de variantie dat door het model wordt verklaard | Begrijpen hoe goed het model past op de trainingsdata | Eenvoudig te interpreteren en geeft snel de modelfit aan | Misleidend bij het vergelijken van modellen met verschillende voorspellers, gevoelig voor overfitting |
| Adjusted R-squared | Aandeel van de variantie dat wordt verklaard, gecorrigeerd voor het aantal voorspellers | Modellen vergelijken met verschillende aantallen voorspellers | Bestraft het toevoegen van irrelevante variabelen, voorkomt overfitting | Geeft geen indicatie van voorspellende prestaties op nieuwe data |
| Predicted R-squared | Hoe goed het model nieuwe data voorspelt | Modelprestaties beoordelen op ongeziene data | Geeft aan hoe goed het model generaliseert naar nieuwe data | Vereist cross-validatie of een holdout-dataset, rekentechnisch kostbaar |
Tot slot kijken we naar enkele veelgemaakte fouten, want er bestaan nogal wat misverstanden over het gebruik ervan in regressie.
Aangepaste r-kwadraat is een belangrijke maatstaf voor het evalueren van de prestaties van regressiemodellen, vooral wanneer je met meerdere onafhankelijke variabelen werkt. In vergelijking met r-kwadraat geeft het een realistischer en betrouwbaarder beeld van de modelnauwkeurigheid wanneer meerdere voorspellers betrokken zijn.
Als je nieuwsgierig bent hoe R en Python de coëfficiënten van lineaire regressiemodellen vinden, bekijk dan de volgende tutorials: Normal Equation for Linear Regression Tutorial en QR Decomposition in Machine Learning: A Detailed Guide.
Leer met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
