
Courses
Học có giám sát với R: Hồi quy
4 giờ
46.5K
Hồi quy tuyến tính là một công cụ mạnh mẽ trong phân tích dữ liệu và khoa học dữ liệu. Nó được dùng để định lượng mối quan hệ giữa biến phụ thuộc và một hoặc nhiều biến độc lập. Nếu bạn quen thuộc với hồi quy tuyến tính, bạn có thể cũng quen với thước đo độ phù hợp (goodness-of-fit) phổ biến là r-squared, cho biết tỷ lệ phương sai của biến phụ thuộc được giải thích bởi (các) biến độc lập. Tuy nhiên, bạn có thể ít quen thuộc hơn với adjusted r-squared, vốn thường được sử dụng với các mô hình phức tạp hơn có nhiều biến dự báo.
Bài viết này sẽ giúp bạn hiểu toàn diện về adjusted r-squared, tầm quan trọng của nó trong đánh giá mô hình, những khác biệt then chốt so với r-squared, và cách ứng dụng trong các kịch bản hồi quy bội để bạn có thể nắm vững các thống kê mô hình này. Khi bắt đầu, tôi rất khuyến nghị khóa học Introduction to Regression with statsmodels in Python và khóa Introduction to Regression in R của DataCamp để tìm hiểu về các mô hình hồi quy và cách diễn giải những chỉ số hiệu năng khác nhau, bao gồm adjusted r-squared.
R-squared đo lường tỷ lệ phương sai của biến phụ thuộc được giải thích bởi (các) biến độc lập trong mô hình. Adjusted r-squared cũng giải thích phương sai, nhưng có thêm một yếu tố: Đúng như tên gọi, nó hiệu chỉnh giá trị r-squared bằng cách phạt việc đưa vào các biến không liên quan, tức là các biến có đồng tuyến tính cao. Nó làm điều này bằng cách tính đến cả số lượng biến dự báo và kích thước mẫu.
Để tìm adjusted r-squared, trước hết ta phải tính r-squared. Mặc dù có nhiều cách tính r-squared, công thức dưới đây là một trong những cách phổ biến nhất:
Ở đây, r-squared được tính bằng 1 trừ thương số giữa tổng bình phương phần dư và tổng bình phương tổng thể.
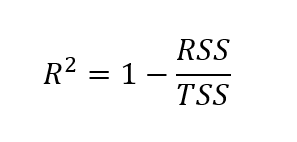
Trong đó:
Sau khi có giá trị r-squared, ta có thể tính adjusted r-squared bằng cách thay giá trị r-squared vào công thức dưới đây.
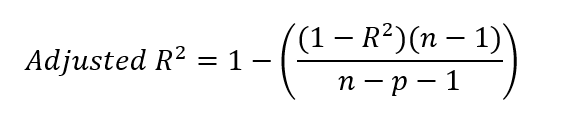
Trong đó:
Để luyện tập, hãy thử một ví dụ. Xét tình huống sau: Chúng ta có một bộ dữ liệu gồm 30 quan sát. Ta xây dựng mô hình hồi quy tuyến tính bội với năm biến dự báo. Ta thu được r-squared bằng 0,8. Dưới đây là cách dùng các thông tin này để tìm adjusted r-squared:

Bạn có thể thắc mắc về -1 trong công thức, cả ở tử số lẫn mẫu số. Để làm rõ, n−1 ở tử số thể hiện bậc tự do, hiệu chỉnh cho việc sử dụng trung bình mẫu khi tính phương sai. Bởi vì khi tính phương sai, ta thường dùng trung bình mẫu để ước lượng trung bình tổng thể. Vì trung bình mẫu không phải trung bình tổng thể thực sự nên phương sai có xu hướng bị đánh giá thấp. Để sửa thiên lệch này, ta giảm bậc tự do đi 1.
Ở mẫu số, n−p−1 điều chỉnh theo số lượng biến dự báo p trong mô hình, trong đó p là số biến độc lập. Dấu −1 bổ sung ở mẫu số hiệu chỉnh cho việc ước lượng hệ số chặn của mô hình, cũng tiêu tốn một bậc tự do. Hãy nhớ rằng, trong mô hình hồi quy, ta ước lượng cả các hệ số dốc cho biến dự báo và hệ số chặn để phản ánh đầy đủ độ phức tạp.
Mặc dù cả r-squared và adjusted r-squared đều đánh giá hiệu năng mô hình hồi quy, có một khác biệt then chốt giữa hai thước đo này. Giá trị r-squared luôn tăng hoặc giữ nguyên khi thêm nhiều biến dự báo vào mô hình, ngay cả khi các biến đó không cải thiện đáng kể khả năng giải thích của mô hình. Vấn đề này có thể tạo ấn tượng sai lệch về hiệu quả của mô hình.
Adjusted r-squared hiệu chỉnh giá trị r-squared để tính đến số lượng biến độc lập trong mô hình. Giá trị adjusted r-squared có thể giảm nếu một biến dự báo mới không cải thiện độ phù hợp của mô hình, khiến nó trở thành thước đo đáng tin cậy hơn về độ chính xác của mô hình. Vì lý do này, adjusted r-squared có thể được các nhà phân tích dữ liệu dùng như một công cụ để quyết định nên bao gồm những biến dự báo nào.
Việc hiểu khi nào nên dùng adjusted r-squared thay cho r-squared rất quan trọng để xây dựng mô hình đáng tin cậy. Dưới đây là các kịch bản phù hợp để dùng adjusted r-squared đánh giá mô hình.
Nhìn chung, mặc dù adjusted r-squared được ưa chuộng hơn r-squared trong các mô hình hồi quy bội vì nó tính đến số biến dự báo và phạt việc thêm biến không liên quan, vẫn có những tình huống r-squared có thể phù hợp:
Hãy xét một ví dụ nơi những khác biệt tinh tế giữa r-squared và adjusted r-squared phát huy tác dụng. Giả sử chúng ta có hai mô hình hồi quy sau:
Ta có thể nói mô hình 1 dường như giải thích nhiều phương sai tổng thể trong dữ liệu hơn vì có r-squared cao hơn. Nhưng ta cũng phải cân nhắc rằng mô hình 2 có thể giải thích tốt hơn mối quan hệ nền tảng thực sự giữa các biến vì nó tính đến các biến dự báo không liên quan. Adjusted r-squared cao hơn của mô hình 2 cho thấy nó cung cấp độ phù hợp đáng tin cậy hơn bằng cách phạt độ phức tạp không cần thiết, và có thể ít bị quá khớp hơn. Cá nhân tôi, trong trường hợp không có thêm thông tin khác, sẽ chọn mô hình 2.
Hãy khám phá các ví dụ thực hành tính adjusted r-squared trong R và Python. Chúng ta sẽ dùng bộ dữ liệu “Fish Market” từ Kaggle, hữu ích để ước lượng cân nặng của cá dựa trên loài và các số đo hình học. Để đơn giản, chúng ta sẽ làm tròn kết quả đến năm chữ số thập phân.
Tải bộ dữ liệu và lưu trong thư mục làm việc của bạn. Dùng đoạn mã sau để khớp một mô hình tuyến tính dự đoán cân nặng của cá như một hàm của một vài biến, bao gồm Length1, Height, Width và Length3, lần lượt là chiều dài dọc của cá, chiều cao của cá, bề rộng đường chéo của cá và chiều dài chéo của cá.
# Load the dataset
data <- read.csv("data/Fish.csv")
# Remove rows with missing values
data <- na.omit(data)
# Model 1: Using 4 predictors ('Length1', 'Height', 'Width', 'Length3')
model1 <- lm(Weight ~ Length1 + Height + Width + Length3, data = data)Giờ chúng ta kiểm tra các giá trị r-squared và adjusted r-squared, và thấy như sau. Adjusted r-squared rất gần với r-squared, chỉ thấp hơn một chút.
r_squared_model1 <- round(summary(model1)$r.squared, 4)
r_squared_model1 <- round(summary(model1)$adj.r.squared, 4)0.88527
0.88229Nếu giờ ta thử tạo một mô hình khác bằng cách thêm một biến dự báo nữa thì sao? Lần này, ta tạo mô hình thứ hai và thêm Length2, tức là chiều dài đường chéo của cá. Tương tự như trước, ta có thể kiểm tra r-squared và adjusted r-squared của mô hình mới.
# Model 2: Adding one more predictor ('Length2')
model2 <- lm(Weight ~ Length1 + Height + Width + Length3 + Length2, data = data)r_squared_model2 <- round(summary(model1)$r.squared, 4)
r_squared_model2 <- round(summary(model1)$adj.r.squared, 4)0.88529
0.88154Với mô hình 2, ta thấy giá trị r-squared hầu như không tăng so với mô hình 1. Ngoài ra, adjusted r-squared giảm, và mức giảm của adjusted r-squared còn lớn hơn mức tăng của r-squared. Điều này cho thấy biến dự báo ta thêm vào không tốt.
Nếu suy xét kỹ, Length2 (chiều dài đường chéo của cá) có thể tương quan cao với các biến khác trong mô hình hoặc với một tổ hợp tuyến tính của các biến đó. Đặc biệt, ta kỳ vọng chiều dài đường chéo của cá tương quan cao với chiều dài của cá và chiều dài chéo của cá. Vì vậy biến mới của ta không bổ sung thông tin mới, phù hợp.
Vì sự đầy đủ, ta cũng có thể minh họa cách tự tính adjusted r-squared bằng tay. Ta dùng giá trị r-squared và các tham số mô hình, và làm theo công thức đã trình bày trước đó.
# Save R-squared as a variable
r_squared_model2 <- summary(model2)$r.squared
# Get the number of observations (n) for both models
n <- nrow(data) # Same for both models
# Get the number of predictors (excluding intercept) for each model
p_model1 <- length(coef(model1)) - 1
p_model2 <- length(coef(model2)) - 1
# Adjusted r-squared formula for Model 1
adjusted_r_squared_model1 <- 1 - ((1 - r_squared_model1) * (n - 1)) / (n - p_model1 - 1)
# Adjusted r-squared formula for Model 2
adjusted_r_squared_model2 <- 1 - ((1 - r_squared_model2) * (n - 1)) / (n - p_model2 - 1)
# Print R-squared values for both models
cat("R-Squared for Model 1:", r_squared_model1, "\n")
cat("R-Squared for Model 2:", r_squared_model2, "\n")
# Print the Adjusted R-Squared values for both models
cat("Adjusted R-Squared for Model 1:", adjusted_r_squared_model1, "\n")
cat("Adjusted R-Squared for Model 2:", adjusted_r_squared_model2, "\n")Đoạn mã sau minh họa cùng ví dụ bằng Python.
# Import requied libraries
import pandas as pd
import statsmodels.api as sm
# Load the dataset
data = pd.read_csv('data/Fish.csv')
# Drop rows with missing values if any exist
data = data.dropna()
# Define predictors for Model 1 (4 variables)
X1 = data[['Length1', 'Height', 'Width', 'Length3']]
# Add a constant (intercept)
X1 = sm.add_constant(X1)
# Define the target variable 'Weight'
y = data['Weight']
# Fit Model 1
model1 = sm.OLS(y, X1).fit()
# Define predictors for Model 2 (5 variables)
X2 = data[['Length1', 'Height', 'Width', 'Length3', 'Length2']]
# Add a constant (intercept)
X2 = sm.add_constant(X2)
# Fit Model 2
model2 = sm.OLS(y, X2).fit()
# Save r-squared as a variable
r_squared_model1 = model1.rsquared # R-Squared for Model 1
r_squared_model2 = model2.rsquared # R-Squared for Model 2
# Get the number of observations
n = X1.shape[0] # Same for both models
# Get the number of predictors (excluding intercept) for each model
p_model1 = X1.shape[1] - 1 # Number of predictors for Model 1
p_model2 = X2.shape[1] - 1 # Number of predictors for Model 2
# Adjusted R-Squared formula for Model 1
adjusted_r_squared_model1 = 1 - ((1 - r_squared_model1) * (n - 1)) / (n - p_model1 - 1)
# Adjusted R-Squared formula for Model 2
adjusted_r_squared_model2 = 1 - ((1 - r_squared_model2) * (n - 1)) / (n - p_model2 - 1)
# Print R-squared for both models
print("R-Squared for Model 1:", r_squared_model1)
print("R-Squared for Model 2:", r_squared_model2)
# Print the Adjusted R-Squared values for both models
print("Adjusted R-Squared for Model 1:", adjusted_r_squared_model1)
print("Adjusted R-Squared for Model 2:", adjusted_r_squared_model2)Chúng ta cũng có thể dùng các hàm trong Python để lấy trực tiếp giá trị r-squared và adjusted r-squared của các mô hình hồi quy:
# Model 1
print("Model 1 R-Squared:", model1.rsquared)
print("Model 1 Adjusted R-Squared:", model1.rsquared_adj)
# Model 2
print("Model 2 R-Squared:", model2.rsquared)
print("Model 2 Adjusted R-Squared:", model2.rsquared_adj)Nếu bạn gặp khó khăn với các đoạn mã trên, hãy xem các hướng dẫn của chúng tôi về Essentials of Linear Regression in Python và How to Do Linear Regression in R để học từng bước triển khai và diễn giải các chỉ số của mô hình hồi quy. Nếu Excel là công cụ phân tích ưa thích của bạn, hãy tham khảo bài hướng dẫn Linear Regression in Excel: A Comprehensive Guide For Beginners để học cách triển khai và trực quan hóa các mô hình hồi quy tuyến tính trong Excel.
Khi bàn về adjusted r-squared, chúng ta nên dành thời gian làm rõ thuật ngữ. Có những khái niệm nghe có vẻ giống nhau nhưng mục đích khác nhau. Ở đây, tôi tạo một bảng so sánh một số khái niệm nghe tương tự nhưng khác biệt: r-squared, adjusted r-squared và predicted r-squared.
| Chỉ số | Đo lường | Tình huống sử dụng | Điểm mạnh | Hạn chế |
|---|---|---|---|---|
| R-squared | Tỷ lệ phương sai được mô hình giải thích | Hiểu mức độ mô hình khớp với dữ liệu huấn luyện | Dễ diễn giải và nhanh chóng cho biết độ phù hợp mô hình | Dễ gây hiểu lầm khi so sánh mô hình có số biến dự báo khác nhau, dễ bị quá khớp |
| Adjusted R-squared | Tỷ lệ phương sai được giải thích, đã hiệu chỉnh theo số biến dự báo | So sánh các mô hình có số biến dự báo khác nhau | Phạt việc thêm biến không liên quan, giúp ngăn quá khớp | Không cho biết hiệu năng dự đoán trên dữ liệu mới |
| Predicted R-squared | Mức độ mô hình dự đoán dữ liệu mới tốt ra sao | Đánh giá hiệu năng mô hình trên dữ liệu chưa thấy | Cho biết khả năng khái quát hóa lên dữ liệu mới | Cần cross-validation hoặc tập giữ lại, tốn chi phí tính toán |
Cuối cùng, hãy xem một số sai lầm phổ biến vì có vài hiểu nhầm thường gặp về việc sử dụng nó trong hồi quy.
Adjusted r-squared là chỉ số quan trọng để đánh giá hiệu năng của các mô hình hồi quy, đặc biệt khi làm việc với nhiều biến độc lập. So với r-squared, nó cung cấp thước đo độ chính xác của mô hình thực tế và đáng tin cậy hơn khi có nhiều biến dự báo tham gia.
Nếu bạn tò mò cách R và Python tìm các hệ số của mô hình hồi quy tuyến tính, hãy xem các hướng dẫn sau: Normal Equation for Linear Regression Tutorial và QR Decomposition in Machine Learning: A Detailed Guide.
Học cùng DataCamp
Courses
Courses
Courses