
Corso
Supervised Learning in R: Regression
4 h
46.5K
La regressione lineare è uno strumento potente nell’analisi dei dati e nella data science. Si usa per quantificare la relazione tra una variabile dipendente e una o più variabili indipendenti. Se conosci la regressione lineare, potresti già avere familiarità con la comune misura di bontà dell’adattamento chiamata r quadrato, che indica la quota di varianza della variabile dipendente spiegata dalle variabili indipendenti. Tuttavia, potresti conoscere meno l’r quadrato aggiustato, che si usa spesso con modelli più complessi con più predittori.
Questo articolo ti darà una comprensione completa dell’r quadrato aggiustato, della sua importanza nella valutazione dei modelli, delle principali differenze rispetto all’r quadrato e delle sue applicazioni negli scenari di regressione multipla, così da padroneggiare a fondo queste statistiche di modello. Per cominciare, ti consiglio vivamente i corsi di DataCamp Introduction to Regression with statsmodels in Python e Introduction to Regression in R per imparare i modelli di regressione e come interpretare le diverse metriche di performance, incluso l’r quadrato aggiustato.
L’r quadrato misura la quota di varianza della variabile dipendente spiegata dalla o dalle variabili indipendenti del modello. L’r quadrato aggiustato spiega anch’esso la varianza, ma con una considerazione in più: come suggerisce il nome, aggiusta il valore di r quadrato penalizzando l’inclusione di variabili irrilevanti, ossia altamente collineari. Lo fa tenendo conto sia del numero di predittori sia della dimensione del campione.
Per calcolare l’r quadrato aggiustato, dobbiamo prima calcolare l’r quadrato. Sebbene esistano diversi modi per trovare il valore di r quadrato, la formula seguente è una delle più comuni:
Qui, l’r quadrato è calcolato come uno meno il quoziente tra la somma dei quadrati dei residui e la somma dei quadrati totale.
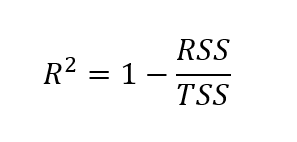
Dove:
Dopo aver trovato il valore di r quadrato, possiamo ricavare l’r quadrato aggiustato. Lo facciamo inserendo il nostro valore di r quadrato nella formula seguente.
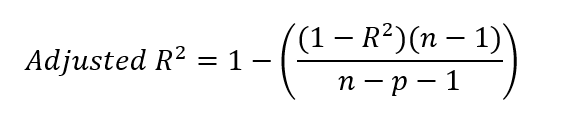
Dove:
Per esercitarti, proviamo un esempio. Considera questo scenario: abbiamo un dataset con 30 osservazioni. Creiamo un modello di regressione lineare multipla con cinque predittori. Otteniamo un r quadrato di 0,8. Ecco come possiamo usare queste informazioni per trovare l’r quadrato aggiustato:

Potresti chiederti del -1 presente nell’equazione, sia al numeratore sia al denominatore. Per chiarire, n−1 al numeratore tiene conto dei gradi di libertà, correggendo l’uso della media campionaria nel calcolo della varianza. Questo perché, quando calcoliamo la varianza, usiamo tipicamente la media del campione come stima della media della popolazione. Poiché la media del campione non è la vera media della popolazione, la varianza tende a essere sottostimata. Per correggere questo bias, riduciamo i gradi di libertà di 1.
Al denominatore, n−p−1 aggiusta per il numero di predittori p nel modello, dove p è il numero di variabili indipendenti. L’ulteriore −1 al denominatore corregge la stima dell’intercetta del modello, che consuma anch’essa un grado di libertà. Dobbiamo ricordare che, in un modello di regressione, stimiamo sia i coefficienti angolari dei predittori sia l’intercetta per tener conto della complessità complessiva.
Sebbene sia l’r quadrato sia l’r quadrato aggiustato valutino le prestazioni dei modelli di regressione, esiste una differenza chiave tra le due metriche. Il valore di r quadrato aumenta sempre o rimane invariato quando si aggiungono più predittori al modello, anche se quei predittori non migliorano in modo significativo il potere esplicativo del modello. Questo problema può creare un’impressione fuorviante dell’efficacia del modello.
L’r quadrato aggiustato modifica il valore di r quadrato per tenere conto del numero di variabili indipendenti nel modello. Il valore di r quadrato aggiustato può diminuire se un nuovo predittore non migliora l’adattamento del modello, rendendolo una misura più affidabile dell’accuratezza del modello. Per questo motivo, l’r quadrato aggiustato può essere usato come strumento dagli analisti per decidere quali predittori includere.
Capire quando usare l’r quadrato aggiustato al posto dell’r quadrato è importante per costruire modelli affidabili. Ecco alcuni scenari in cui è appropriato usare l’r quadrato aggiustato per valutare i modelli.
In generale, sebbene l’r quadrato aggiustato sia preferito all’r quadrato nei modelli di regressione multipla perché tiene conto del numero di predittori e penalizza l’aggiunta di variabili irrilevanti, ci sono alcuni scenari in cui potrebbe essere comunque appropriato usare l’r quadrato:
Consideriamo un esempio in cui entrano in gioco le sfumature tra r quadrato e r quadrato aggiustato. Supponiamo di avere questi due modelli di regressione:
Potremmo dire che il modello 1 sembra spiegare una quota maggiore della varianza complessiva nei dati perché ha un valore di r quadrato più alto. Ma dobbiamo anche considerare che il modello 2 potrebbe spiegare meglio la relazione di fondo tra le variabili perché tiene conto dei predittori irrilevanti. Il r quadrato aggiustato più alto del modello 2 suggerisce che fornisce un adattamento più affidabile penalizzando la complessità non necessaria, e potrebbe anche essere meno incline all’overfitting. Personalmente, e in assenza di altre informazioni, sceglierei il modello 2.
Esploriamo esempi pratici di calcolo dell’r quadrato aggiustato in R e Python. Useremo il dataset “Fish Market” di Kaggle, utile per stimare il peso di un pesce in base alla specie e alle sue misure fisiche. Per semplicità, arrotonderemo l’output a cinque cifre decimali.
Scarica il dataset e salvalo nella tua directory di lavoro. Usa il codice seguente per adattare un modello lineare che prevede il peso del pesce in funzione di alcune variabili, tra cui Length1, Height, Width e Length3, che si riferiscono rispettivamente alla lunghezza verticale del pesce, all’altezza del pesce, alla larghezza diagonale del pesce e alla lunghezza trasversale del pesce.
# Load the dataset
data <- read.csv("data/Fish.csv")
# Remove rows with missing values
data <- na.omit(data)
# Model 1: Using 4 predictors ('Length1', 'Height', 'Width', 'Length3')
model1 <- lm(Weight ~ Length1 + Height + Width + Length3, data = data)Ora controlliamo i valori di r quadrato e r quadrato aggiustato, e vediamo quanto segue. L’r quadrato aggiustato è molto vicino al valore di r quadrato, solo leggermente più basso.
r_squared_model1 <- round(summary(model1)$r.squared, 4)
r_squared_model1 <- round(summary(model1)$adj.r.squared, 4)0.88527
0.88229E se provassimo ora a creare un altro modello aggiungendo un altro predittore? Questa volta creiamo un secondo modello e aggiungiamo Length2, che si riferisce alla lunghezza diagonale del pesce. Come prima, possiamo controllare i valori di r quadrato e r quadrato aggiustato del nuovo modello.
# Model 2: Adding one more predictor ('Length2')
model2 <- lm(Weight ~ Length1 + Height + Width + Length3 + Length2, data = data)r_squared_model2 <- round(summary(model1)$r.squared, 4)
r_squared_model2 <- round(summary(model1)$adj.r.squared, 4)0.88529
0.88154Per il modello 2, vediamo che il valore di r quadrato è aumentato a malapena rispetto al modello 1. Inoltre, notiamo che il valore di r quadrato aggiustato è diminuito, e la diminuzione dell’r quadrato aggiustato è stata maggiore dell’aumento dell’r quadrato. Questo ci dice che il predittore aggiunto non era una buona scelta.
Se ci pensiamo, Length2, che si riferisce alla lunghezza diagonale del pesce, probabilmente era fortemente correlata con altre variabili nel modello o con una combinazione lineare delle altre variabili. In particolare, ci aspettiamo che la lunghezza diagonale del pesce sia altamente correlata con la lunghezza del pesce e la lunghezza trasversale del pesce. Quindi vediamo che la nuova variabile non ha aggiunto informazioni nuove e rilevanti.
Per completezza, possiamo anche mostrare come trovare a mano l’r quadrato aggiustato. Usiamo il valore di r quadrato e i parametri del modello, seguendo la formula mostrata in precedenza.
# Save R-squared as a variable
r_squared_model2 <- summary(model2)$r.squared
# Get the number of observations (n) for both models
n <- nrow(data) # Same for both models
# Get the number of predictors (excluding intercept) for each model
p_model1 <- length(coef(model1)) - 1
p_model2 <- length(coef(model2)) - 1
# Adjusted r-squared formula for Model 1
adjusted_r_squared_model1 <- 1 - ((1 - r_squared_model1) * (n - 1)) / (n - p_model1 - 1)
# Adjusted r-squared formula for Model 2
adjusted_r_squared_model2 <- 1 - ((1 - r_squared_model2) * (n - 1)) / (n - p_model2 - 1)
# Print R-squared values for both models
cat("R-Squared for Model 1:", r_squared_model1, "\n")
cat("R-Squared for Model 2:", r_squared_model2, "\n")
# Print the Adjusted R-Squared values for both models
cat("Adjusted R-Squared for Model 1:", adjusted_r_squared_model1, "\n")
cat("Adjusted R-Squared for Model 2:", adjusted_r_squared_model2, "\n")Il codice seguente mostra l’implementazione dello stesso esempio in Python.
# Import requied libraries
import pandas as pd
import statsmodels.api as sm
# Load the dataset
data = pd.read_csv('data/Fish.csv')
# Drop rows with missing values if any exist
data = data.dropna()
# Define predictors for Model 1 (4 variables)
X1 = data[['Length1', 'Height', 'Width', 'Length3']]
# Add a constant (intercept)
X1 = sm.add_constant(X1)
# Define the target variable 'Weight'
y = data['Weight']
# Fit Model 1
model1 = sm.OLS(y, X1).fit()
# Define predictors for Model 2 (5 variables)
X2 = data[['Length1', 'Height', 'Width', 'Length3', 'Length2']]
# Add a constant (intercept)
X2 = sm.add_constant(X2)
# Fit Model 2
model2 = sm.OLS(y, X2).fit()
# Save r-squared as a variable
r_squared_model1 = model1.rsquared # R-Squared for Model 1
r_squared_model2 = model2.rsquared # R-Squared for Model 2
# Get the number of observations
n = X1.shape[0] # Same for both models
# Get the number of predictors (excluding intercept) for each model
p_model1 = X1.shape[1] - 1 # Number of predictors for Model 1
p_model2 = X2.shape[1] - 1 # Number of predictors for Model 2
# Adjusted R-Squared formula for Model 1
adjusted_r_squared_model1 = 1 - ((1 - r_squared_model1) * (n - 1)) / (n - p_model1 - 1)
# Adjusted R-Squared formula for Model 2
adjusted_r_squared_model2 = 1 - ((1 - r_squared_model2) * (n - 1)) / (n - p_model2 - 1)
# Print R-squared for both models
print("R-Squared for Model 1:", r_squared_model1)
print("R-Squared for Model 2:", r_squared_model2)
# Print the Adjusted R-Squared values for both models
print("Adjusted R-Squared for Model 1:", adjusted_r_squared_model1)
print("Adjusted R-Squared for Model 2:", adjusted_r_squared_model2)Possiamo anche usare funzioni in Python per ottenere i valori di r quadrato e r quadrato aggiustato dei modelli di regressione:
# Model 1
print("Model 1 R-Squared:", model1.rsquared)
print("Model 1 Adjusted R-Squared:", model1.rsquared_adj)
# Model 2
print("Model 2 R-Squared:", model2.rsquared)
print("Model 2 Adjusted R-Squared:", model2.rsquared_adj)Se hai avuto difficoltà con le sezioni di codice qui sopra, dai un’occhiata ai nostri tutorial su Essentials of Linear Regression in Python e How to Do Linear Regression in R per seguire la guida passo passo all’implementazione e all’interpretazione delle diverse metriche del modello di regressione. Se Excel è il tuo strumento di analisi preferito, consulta il nostro tutorial su Linear Regression in Excel: A Comprehensive Guide For Beginners per imparare a implementare e visualizzare modelli di regressione lineare in Excel.
Quando consideriamo l’r quadrato aggiustato, è bene tenere in ordine i termini. Ci sono termini che sembrano simili ma hanno scopi diversi. Qui ho creato una tabella che confronta alcune idee dal suono simile ma distinte: r quadrato, r quadrato aggiustato e r quadrato predetto.
| Metrica | Misura | Uso | Punti di forza | Limitazioni |
|---|---|---|---|---|
| R quadrato | Quota di varianza spiegata dal modello | Comprendere quanto bene il modello si adatta ai dati di training | Semplice da interpretare e fornisce rapidamente l’adattamento del modello | Fuorviante quando si confrontano modelli con predittori diversi, vulnerabile all’overfitting |
| R quadrato aggiustato | Quota di varianza spiegata, aggiustata per il numero di predittori | Confrontare modelli con numeri diversi di predittori | Penalizza l’aggiunta di variabili irrilevanti, previene l’overfitting | Non indica la performance predittiva su nuovi dati |
| R quadrato predetto | Quanto bene il modello predice nuovi dati | Valutare le prestazioni del modello su dati non visti | Indica quanto bene il modello generalizza a nuovi dati | Richiede cross-validation o un dataset di holdout, computazionalmente costoso |
Infine, vediamo alcuni errori comuni perché ci sono frequenti fraintendimenti sul suo uso nella regressione.
L’r quadrato aggiustato è una metrica importante per valutare le prestazioni dei modelli di regressione, soprattutto quando si hanno più variabili indipendenti. Rispetto alla metrica r quadrato, fornisce una misura più realistica e affidabile dell’accuratezza del modello quando sono coinvolti più predittori.
Se ti incuriosisce come R e Python trovano i coefficienti dei modelli di regressione lineare, dai un’occhiata ai seguenti tutorial: Normal Equation for Linear Regression Tutorial e QR Decomposition in Machine Learning: A Detailed Guide.
Impara con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

