
Kurs
Supervised Learning in R: Regression
4 sa
46.4K
Doğrusal regresyon, veri analizi ve veri biliminde güçlü bir araçtır. Bağımlı değişken ile bir veya daha fazla bağımsız değişken arasındaki ilişkiyi nicelleştirmek için kullanılır. Doğrusal regresyona aşinaysanız, bağımlı değişkendeki varyansın bağımsız değişken(ler) tarafından açıklanan oranını gösteren yaygın bir uyum iyiliği ölçüsü olan r-kareye de aşina olabilirsiniz. Ancak, birden çok yordayıcının yer aldığı daha karmaşık modellerde sıkça kullanılan düzeltilmiş r-kareye daha az aşina olabilirsiniz.
Bu makale size düzeltilmiş r-kareyi kapsamlı bir şekilde açıklayacak; model değerlendirmesindeki önemini, r-kareden temel farklarını ve çoklu regresyon senaryolarındaki kullanımını ele alacak, böylece bu model istatistiklerine tamamen hâkim olabileceksiniz. Başlarken, regresyon modellerini ve düzeltilmiş r-kare dahil farklı performans ölçütlerinin nasıl yorumlanacağını öğrenmek için DataCamp’in Python’da statsmodels ile Regresyona Giriş ve R’de Regresyona Giriş kurslarını almanızı önemle tavsiye ederim.
R-kare, modelin bağımsız değişken(ler)i tarafından açıklanan bağımlı değişkendeki varyansın oranını ölçer. Düzeltilmiş r-kare de varyansı açıklar, ancak ek bir husus içerir: Adından da anlaşılacağı gibi, düzelterek alakasız, yani yüksek derecede çoklu doğrusal bağlantı içeren, değişkenlerin modele dahil edilmesini cezalandırır. Bunu, hem yordayıcı sayısını hem de örneklem büyüklüğünü hesaba katarak yapar.
Düzeltilmiş r-kareyi bulmak için önce r-kareyi bulmamız gerekir. R-kare değerini bulmanın farklı yolları olsa da aşağıdaki formül en yaygın olanlardan biridir:
Burada r-kare, bir eksi artık kareler toplamının toplam kareler toplamına bölümünün sonucu olarak hesaplanır.
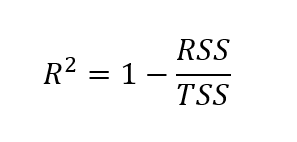
Burada:
R-kare değerini bulduktan sonra düzeltilmiş r-kareyi hesaplayabiliriz. Bunu, r-kare değerimizi aşağıdaki formüle yerleştirerek yaparız.
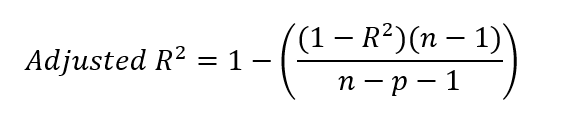
Burada:
Alıştırma yapmak için bir örneği deneyebiliriz. Şu senaryoyu düşünün: 30 gözlem içeren bir veri setimiz var. Beş yordayıcılı bir çoklu doğrusal regresyon modeli kuruyoruz. R-kareyi 0,8 olarak buluyoruz. Bu bilgiyi kullanarak düzeltilmiş r-kareyi şu şekilde hesaplayabiliriz:

Denklemde hem payda hem payda yer alan -1 hakkında merak ediyor olabilirsiniz. Açıklığa kavuşturmak için, paydaki n−1 serbestlik derecelerini hesaba katar ve varyans hesaplanırken örneklem ortalamasının kullanılmasını düzeltir. Bunun nedeni, varyans hesaplanırken genellikle anakütle ortalamasının bir tahmini olarak örneklem ortalamasının kullanılmasıdır. Örneklem ortalaması gerçek anakütle ortalaması olmadığından varyans genellikle olduğundan düşük tahmin edilir. Bu yanlılığı düzeltmek için serbestlik derecelerini 1 azaltırız.
Paydada ise n−p−1, modeldeki yordayıcı sayısı olan p için bir düzeltmedir; burada p bağımsız değişken sayısını ifade eder. Paydadaki ilave −1 ise modelin sabit teriminin (intercept) tahmin edilmesi için bir düzeltmedir; bu da bir serbestlik derecesi tüketir. Unutmamalıyız ki bir regresyon modelinde, tam karmaşıklığı hesaba katmak için hem yordayıcıların eğim katsayılarını hem de sabit terimi tahmin ederiz.
Her ikisi de regresyon modelinin performansını değerlendiriyor olsa da bu iki ölçüt arasında temel bir fark vardır. Modele daha fazla yordayıcı eklendiğinde, bu yordayıcılar modelin açıklayıcı gücünü anlamlı biçimde artırmasa bile r-kare değeri her zaman artar veya aynı kalır. Bu durum, modelin etkinliğine dair yanıltıcı bir izlenim yaratabilir.
Düzeltilmiş r-kare, modeldeki bağımsız değişken sayısını hesaba katacak şekilde r-kareyi düzeltir. Yeni bir yordayıcı modelin uyumunu iyileştirmiyorsa düzeltilmiş r-kare düşebilir; bu da onu model doğruluğunun daha güvenilir bir ölçüsü yapar. Bu nedenle, veri analistleri hangi yordayıcıları dahil edeceklerine karar vermede bir araç olarak düzeltilmiş r-kareyi kullanabilir.
Güvenilir modeller kurarken r-kare yerine düzeltilmiş r-kareyi ne zaman kullanacağınızı bilmek önemlidir. Aşağıdaki senaryolarda modelleri değerlendirirken düzeltilmiş r-kareyi kullanmak uygundur.
Genel olarak, çoklu regresyon modellerinde yordayıcı sayısını hesaba katıp alakasız değişkenlerin eklenmesini cezalandırdığı için düzeltilmiş r-kare, r-kareye tercih edilir; ancak bazı durumlarda r-kareyi kullanmak yine de uygun olabilir:
R-kare ile düzeltilmiş r-kare arasındaki nüansların devreye gireceği bir örnek düşünelim. Diyelim ki iki regresyon modelimiz var:
Model 1’in daha yüksek r-kare değerine sahip olduğu için verideki toplam varyansın daha fazlasını açıkladığını söyleyebiliriz. Ancak, Model 2’nin alakasız yordayıcıları hesaba kattığı için değişkenler arasındaki gerçek temel ilişkiyi daha iyi açıklıyor olabileceğini de göz önünde bulundurmalıyız. Model 2’nin daha yüksek düzeltilmiş r-karesi, gereksiz karmaşıklığı cezalandırarak daha güvenilir bir uyum sunduğunu ve aşırı öğrenmeye daha az yatkın olabileceğini gösterir. Kişisel olarak ve başka bilgi olmaksızın ben Model 2’yi seçerdim.
R ve Python’da düzeltilmiş r-kareyi hesaplamaya dair pratik örnekleri inceleyelim. Kaggle’dan, bir balığın türü ve fiziksel ölçümlerine göre ağırlığını tahmin etmek için yararlı olan “Fish Market” veri setini kullanacağız. Basitleştirmek için çıktıyı beş ondalık haneye yuvarlayacağız.
Veri setini indirin ve çalışma dizininize kaydedin. Aşağıdaki kodu kullanarak, balığın ağırlığını birkaç farklı değişkenin bir fonksiyonu olarak tahmin eden bir doğrusal model kurun; bu değişkenler sırasıyla balığın düşey uzunluğu, balığın yüksekliği, balığın diyagonal genişliği ve balığın çapraz uzunluğunu ifade eden Length1, Height, Width ve Length3 değerleridir.
# Load the dataset
data <- read.csv("data/Fish.csv")
# Remove rows with missing values
data <- na.omit(data)
# Model 1: Using 4 predictors ('Length1', 'Height', 'Width', 'Length3')
model1 <- lm(Weight ~ Length1 + Height + Width + Length3, data = data)Şimdi r-kare ve düzeltilmiş r-kare değerlerine bakalım; aşağıdakileri görürüz. Düzeltilmiş r-kare, r-kare değerine çok yakındır, yalnızca biraz daha düşüktür.
r_squared_model1 <- round(summary(model1)$r.squared, 4)
r_squared_model1 <- round(summary(model1)$adj.r.squared, 4)0.88527
0.88229Peki şimdi bir yordayıcı daha ekleyerek başka bir model oluşturmaya çalışsak ne olur? Bu kez ikinci bir model kuruyor ve balığın diyagonal uzunluğunu ifade eden Length2’yi ekliyoruz. Öncekiyle aynı şekilde, yeni modelimizin r-kare ve düzeltilmiş r-kare değerlerini kontrol edebiliriz.
# Model 2: Adding one more predictor ('Length2')
model2 <- lm(Weight ~ Length1 + Height + Width + Length3 + Length2, data = data)r_squared_model2 <- round(summary(model1)$r.squared, 4)
r_squared_model2 <- round(summary(model1)$adj.r.squared, 4)0.88529
0.88154Model 2 için, model 1 ile karşılaştırıldığında r-kare değerinin neredeyse hiç artmadığını görüyoruz. Ayrıca düzeltilmiş r-kare değerinin düştüğünü ve bu düşüşün r-karedeki artıştan daha büyük olduğunu görüyoruz. Bu, eklediğimiz yordayıcının iyi bir seçim olmadığını gösterir.
Düşünürsek, balığın diyagonal uzunluğunu ifade eden Length2 muhtemelen modeldeki diğer değişkenlerden biriyle ya da bu değişkenlerin doğrusal bir birleşimiyle yüksek korelasyona sahiptir. Özellikle, balığın diyagonal uzunluğunun, balığın uzunluğu ve çapraz uzunluğu ile yüksek korelasyon göstermesini bekleriz. Dolayısıyla yeni değişkenimizin yeni ve ilgili bilgi eklemediğini görüyoruz.
Tamlık adına, düzeltilmiş r-kareyi elle nasıl bulacağımızı da gösterebiliriz. R-kare değerini ve model parametrelerini kullanır, daha önce gösterdiğimiz formülü izleriz.
# Save R-squared as a variable
r_squared_model2 <- summary(model2)$r.squared
# Get the number of observations (n) for both models
n <- nrow(data) # Same for both models
# Get the number of predictors (excluding intercept) for each model
p_model1 <- length(coef(model1)) - 1
p_model2 <- length(coef(model2)) - 1
# Adjusted r-squared formula for Model 1
adjusted_r_squared_model1 <- 1 - ((1 - r_squared_model1) * (n - 1)) / (n - p_model1 - 1)
# Adjusted r-squared formula for Model 2
adjusted_r_squared_model2 <- 1 - ((1 - r_squared_model2) * (n - 1)) / (n - p_model2 - 1)
# Print R-squared values for both models
cat("R-Squared for Model 1:", r_squared_model1, "\n")
cat("R-Squared for Model 2:", r_squared_model2, "\n")
# Print the Adjusted R-Squared values for both models
cat("Adjusted R-Squared for Model 1:", adjusted_r_squared_model1, "\n")
cat("Adjusted R-Squared for Model 2:", adjusted_r_squared_model2, "\n")Aşağıdaki kod aynı örneğin Python’daki bir uygulamasını gösterir.
# Import requied libraries
import pandas as pd
import statsmodels.api as sm
# Load the dataset
data = pd.read_csv('data/Fish.csv')
# Drop rows with missing values if any exist
data = data.dropna()
# Define predictors for Model 1 (4 variables)
X1 = data[['Length1', 'Height', 'Width', 'Length3']]
# Add a constant (intercept)
X1 = sm.add_constant(X1)
# Define the target variable 'Weight'
y = data['Weight']
# Fit Model 1
model1 = sm.OLS(y, X1).fit()
# Define predictors for Model 2 (5 variables)
X2 = data[['Length1', 'Height', 'Width', 'Length3', 'Length2']]
# Add a constant (intercept)
X2 = sm.add_constant(X2)
# Fit Model 2
model2 = sm.OLS(y, X2).fit()
# Save r-squared as a variable
r_squared_model1 = model1.rsquared # R-Squared for Model 1
r_squared_model2 = model2.rsquared # R-Squared for Model 2
# Get the number of observations
n = X1.shape[0] # Same for both models
# Get the number of predictors (excluding intercept) for each model
p_model1 = X1.shape[1] - 1 # Number of predictors for Model 1
p_model2 = X2.shape[1] - 1 # Number of predictors for Model 2
# Adjusted R-Squared formula for Model 1
adjusted_r_squared_model1 = 1 - ((1 - r_squared_model1) * (n - 1)) / (n - p_model1 - 1)
# Adjusted R-Squared formula for Model 2
adjusted_r_squared_model2 = 1 - ((1 - r_squared_model2) * (n - 1)) / (n - p_model2 - 1)
# Print R-squared for both models
print("R-Squared for Model 1:", r_squared_model1)
print("R-Squared for Model 2:", r_squared_model2)
# Print the Adjusted R-Squared values for both models
print("Adjusted R-Squared for Model 1:", adjusted_r_squared_model1)
print("Adjusted R-Squared for Model 2:", adjusted_r_squared_model2)Python’da ayrıca regresyon modellerinin r-kare ve düzeltilmiş r-kare değerlerini bulmak için işlevleri de kullanabiliriz:
# Model 1
print("Model 1 R-Squared:", model1.rsquared)
print("Model 1 Adjusted R-Squared:", model1.rsquared_adj)
# Model 2
print("Model 2 R-Squared:", model2.rsquared)
print("Model 2 Adjusted R-Squared:", model2.rsquared_adj)Yukarıdaki kod bölümlerinde herhangi bir sorun yaşadıysanız, adım adım nasıl uygulanacağını ve regresyon modelinin farklı metriklerinin nasıl yorumlanacağını öğrenmek için Python’da Doğrusal Regresyonun Temelleri ve R’de Doğrusal Regresyon Nasıl Yapılır eğitimlerimize göz atın. Tercih ettiğiniz analiz aracı Excel ise, doğrusal regresyon modellerini Excel’de nasıl uygulayıp görselleştireceğinizi öğrenmek için Excel’de Doğrusal Regresyon: Yeni Başlayanlar İçin Kapsamlı Kılavuz yazımıza bakın.
Düzeltilmiş r-kareyi ele alırken terimleri net tutmak gerekir. Benzer görünse de farklı amaçlara hizmet eden bazı terimler vardır. Burada, benzer sesli ancak farklı kavramlar olan r-kare, düzeltilmiş r-kare ve tahmin edilen r-kareyi karşılaştıran bir tablo oluşturdum.
| Metri̇k | Ölçtüğü | Kullanım Durumu | Güçlü Yönler | Sınırlılıklar |
|---|---|---|---|---|
| R-kare | Model tarafından açıklanan varyans oranı | Modelin eğitim verilerine ne kadar iyi uyduğunu anlama | Yorumlaması basit, hızlıca model uyumu sağlar | Farklı yordayıcılara sahip modeller karşılaştırılırken yanıltıcı olabilir, aşırı öğrenmeye açık |
| Düzeltilmiş R-kare | Yordayıcı sayısı için düzeltilmiş açıklanan varyans oranı | Farklı sayıda yordayıcıya sahip modelleri karşılaştırma | Alakasız değişkenlerin eklenmesini cezalandırır, aşırı öğrenmeyi önler | Yeni verideki öngörü performansını göstermez |
| Tahmin edilen R-kare | Modelin yeni verileri ne kadar iyi tahmin ettiğini | Görülmemiş veride model performansını değerlendirme | Modelin yeni veriye ne kadar genellendiğini gösterir | Çapraz doğrulama veya ayrılmış bir veri seti gerektirir, hesaplama maliyeti yüksektir |
Son olarak, regresyondaki kullanımına dair bazı yaygın yanlış anlamalar olduğu için sık yapılan hatalara bakalım.
Düzeltilmiş r-kare, özellikle birden çok bağımsız değişkenle çalışırken regresyon modellerinin performansını değerlendirmek için önemli bir metriktir. R-kare ölçütüne kıyasla, birden fazla yordayıcı içeren durumlarda model doğruluğunu daha gerçekçi ve güvenilir bir şekilde ölçer.
R ve Python’un doğrusal regresyon modellerinin katsayılarını nasıl bulduğunu merak ediyorsanız şu eğitimlere göz atın: Doğrusal Regresyon için Normal Denklem Eğitimi ve Makine Öğreniminde QR Ayrışımı: Ayrıntılı Bir Rehber.
DataCamp ile öğrenin
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
