Programa
Engenheiro de dados profissional Em Python
40 h
Compreender os métodos é apenas a metade da história; ver como o CDC oferece valor tangível em cenários do mundo real é igualmente importante.
O CDC permite atualizações contínuas e incrementais nos data warehouses, propagando apenas as alterações em vez de recarregar conjuntos de dados completos. Essa abordagem garante que as ferramentas e os painéis de business intelligence exibam os dados mais atuais.
Por exemplo, uma empresa de varejo pode atualizar seu painel de vendas quase em tempo real para revelar rapidamente tendências e percepções emergentes.
O CDC replica dados entre sistemas, garantindo que qualquer alteração feita no sistema de origem seja imediatamente espelhada nos bancos de dados de destino. Isso é especialmente útil durante projetos de migração de dados ou ao manter backups e réplicas em ambientes híbridos.
Por exemplo, a replicação de dados de sistemas locais para bancos de dados na nuvem, como o AWS RDS ou o Snowflake, garante a consistência entre as plataformas.
Em sistemas distribuídos, como os que envolvem microsserviços ou vários aplicativos, o CDC garante que cada componente opere com os dados mais atualizados, sincronizando as alterações em tempo real.
Por exemplo, a sincronização das informações do cliente em várias plataformas mantém uma experiência de usuário consistente em todas elas.
Por fim, o CDC fornece registros detalhados de alterações que são essenciais para fins de auditoria. Ao rastrear quem fez as alterações e quando elas ocorreram, as equipes podem atender aos requisitos regulamentares, solucionar problemas e realizar análises forenses detalhadas.
As instituições financeiras, por exemplo, dependem de registros abrangentes de CDC para auditar as modificações nos dados dos clientes e garantir a conformidade com políticas rigorosas de governança de dados.
Depois de explorar os métodos e os casos de uso, vamos examinar algumas ferramentas populares que facilitam as implementações do CDC. A escolha certa depende do seu caso de uso -se você precisa de streaming em tempo real, migração para a nuvem ou soluções ETL empresariais.
O AWS DMS usa CDC baseado em log para replicar continuamente os dados dos sistemas locais para a nuvem do AWS com o mínimo de tempo de inatividade, o que o torna uma excelente opção para migrações. O AWS DMS é uma solução robusta se o seu objetivo for mover dados para a nuvem com tempo de atividade confiável.
Melhor para: Migrações para a nuvem e arquiteturas baseadas em AWS.
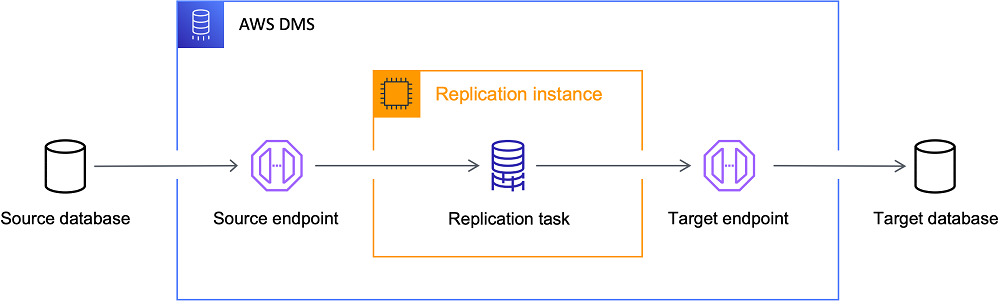
A arquitetura do AWS DMS. Fonte da imagem: AWS
O Debezium é uma plataforma CDC de código aberto que captura e transmite as alterações do banco de dados para sistemas como o Apache Kafka.
Pessoalmente, achei o Debezium extremamente útil para transmitir alterações de banco de dados para o Kafka, especialmente em ambientes distribuídos em que vários serviços dependem de atualizações em tempo real. Seus recursos de escalabilidade e integração fazem dele uma opção de destaque.
Melhor para: Fluxo de dados em tempo real e arquiteturas orientadas por eventos.
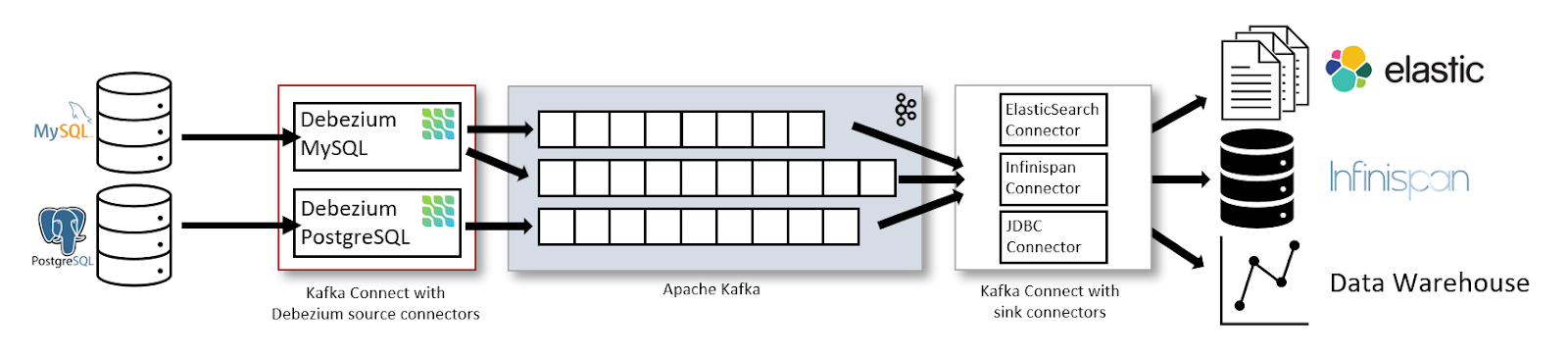
A arquitetura de streaming de dados com o Kafka Connect e o Debezium. Fonte da imagem: Debezium
O Apache Kafka não é uma ferramenta de CDC propriamente dita, mas serve como espinha dorsal para o processamento de eventos de CDC quando combinado com ferramentas como o Debezium. O Kafka permite pipelines confiáveis orientados por eventos, análises em tempo real e sincronização de dados entre vários consumidores.
Melhor para: Transmissão de dados de CDC para arquiteturas orientadas por eventos.
Para ilustrar como os eventos CDC podem ser enviados para o Kafka, considere o seguinte trecho de Python. O código inicializa um produtor do Kafka e envia um evento CDC (representando uma operação de atualização em uma tabela orders ) para um tópico do Kafka chamado cdc-topic:
from kafka import KafkaProducer
import json
# Initialize the Kafka producer with bootstrap servers and a JSON serializer for values.
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
# Define a CDC event that includes details of the operation.
cdc_event = {
"table": "orders",
"operation": "update",
"data": {"order_id": 123, "status": "shipped"}
}
# Send the CDC event to the 'cdc-topic' and flush to ensure transmission.
producer.send('cdc-topic', cdc_event)
producer.flush()
print("CDC event sent successfully!")A Talend e a Informatica são plataformas ETL abrangentes que oferecem a funcionalidade CDC integrada para capturar e processar alterações de dados, reduzindo as configurações manuais. Eles são especialmente vantajosos em cenários complexos de transformação de dados, nos quais as soluções integradas podem simplificar as operações.
Melhor para: Soluções ETL de nível empresarial com CDC integrado.
Vários bancos de dados relacionais oferecem recursos nativos de CDC, reduzindo a necessidade de ferramentas externas:
Melhor para: Minimizar as dependências de ferramentas externas de CDC.
Os provedores de nuvem também oferecem soluções de CDC para seus ecossistemas:
Melhor para: CDC em ambientes do Google Cloud ou do Microsoft Azure.
Embora o CDC ofereça benefícios significativos, ele também traz desafios que devem ser gerenciados para uma implementação confiável.
Manter a integridade dos dados pode ser um desafio ao lidar com interrupções na rede, transações atrasadas ou falhas no sistema. Protocolos robustos de tratamento de erros e reconciliações regulares são essenciais para evitar discrepâncias entre os sistemas de origem e de destino. A solução antecipada desses problemas ajuda a manter um pipeline de dados confiável.
Certos métodos CDC, especialmente os que dependem de acionadores ou de sondagens frequentes, podem introduzir carga adicional nos bancos de dados de origem. Equilibrar a necessidade de atualizações quase em tempo real com as restrições de desempenho dos seus sistemas de produção é fundamental para uma operação tranquila.
Embora o CDC capture com eficiência as alterações brutas, pode ser necessário um processamento posterior adicional, como limpeza ou transformação de dados. A integração da lógica de transformação sem atrasar as entregas ou introduzir erros aumenta a complexidade da implementação do CDC, portanto, é necessário um planejamento cuidadoso.
Para colocar a teoria em prática, você precisa aderir às práticas recomendadas. Aqui estão dicas práticas de minha experiência que me ajudaram a criar pipelines de CDC robustos.
Selecione uma abordagem de CDC que se alinhe ao seu volume de dados, aos requisitos de latência e à arquitetura do sistema. O CDC baseado em registro geralmente é ideal para ambientes com muitas transações, enquanto os métodos baseados em acionamento ou sondagem podem ser mais adequados para aplicativos menores. Avaliar suas necessidades específicas antecipadamente pode economizar tempo e recursos posteriormente.
Implemente um monitoramento abrangente usando painéis de controle em tempo real e alertas automatizados. Revisões regulares de registros e verificações de integridade são essenciais para garantir que todas as alterações sejam capturadas com precisão e que todos os problemas sejam resolvidos imediatamente.
Uma pequena configuração incorreta de CDC baseada em log em um projeto passou despercebida por dias, levando a uma perda silenciosa de dados em análises downstream. A implementação dos alertas do Grafana ajudou a detectar instantaneamente as atualizações ausentes, evitando erros dispendiosos.
Integrar pontos de verificação de validação de dados no pipeline do CDC para garantir que somente alterações precisas e consistentes sejam propagadas.
Pela minha experiência, a configuração de verificações de validação automatizadas no pipeline do CDC me poupou de horas de depuração de problemas de propagação de dados incorretos. Ferramentas como o dbt e o Apache Airflow têm sido fundamentais para garantir a consistência em vários sistemas downstream.
Antes de transferir sua solução CDC para a produção, teste-a completamente em um ambiente de preparação. Simule cargas de trabalho e cenários de falha do mundo real e valide recursos como reversão e viagem no tempo para garantir que o sistema se comporte conforme o esperado em todas as condições. Esse teste rigoroso é importante para que a implementação da produção ocorra sem problemas.
Seu sistema CDC deve se adaptar às alterações de esquema sem interrupções à medida que seus conjuntos de dados evoluem. Use ferramentas que suportem a evolução automática do esquema e mantenha um controle de versão adequado para que os novos campos sejam integrados sem problemas. Essa abordagem estratégica evita erros inesperados e tempo de inatividade quando as estruturas de dados são alteradas.
Ao capturar com precisão apenas os dados modificados, o CDC minimiza a carga do sistema e permite que a análise em tempo real e os aplicativos de streaming funcionem adequadamente. Independentemente de você estar implementando a replicação, a sincronização ou o registro de auditoria de dados, selecionar o método de CDC adequado e seguir as práticas recomendadas é fundamental para criar um pipeline de dados confiável e eficiente.
Para aqueles que desejam aprofundar seus conhecimentos, incentivo você a explorar os seguintes cursos do DataCamp:
Boa codificação - e um brinde à criação de sistemas de dados resilientes e em tempo real!
Saiba mais sobre engenharia de dados com estes cursos!
Programa
Curso
Curso
blog
Elena Kosourova
15 min
blog
Matt Crabtree
14 min
blog
Adejumo Ridwan Suleiman
13 min
blog
Tim Lu
12 min
