
Track
Professional Data Engineer in Python
40 hr
Understanding the methods is only half the story; seeing how CDC delivers tangible value in real-world scenarios is equally important.
CDC enables continuous, incremental updates to data warehouses by propagating only the changes instead of reloading complete datasets. This approach ensures that business intelligence tools and dashboards display the most current data.
For example, a retail company can update its sales dashboard in near‑real‑time to quickly reveal emerging trends and insights.
CDC replicates data across systems by ensuring that any change made in the source system is immediately mirrored in target databases. This is especially useful during data migration projects or when maintaining backups and replicas across hybrid environments.
For instance, replicating data from on‑premises systems to cloud databases such as AWS RDS or Snowflake guarantees consistency across platforms.
In distributed systems—such as those involving microservices or multiple applications—CDC ensures that every component operates on the most up‑to‑date data by synchronizing changes in real time.
For example, synchronizing customer information across various platforms maintains a consistent user experience across the board.
Finally, CDC provides detailed change logs that are essential for auditing purposes. By tracking who made changes and when these changes occurred, teams can meet regulatory requirements, troubleshoot issues, and perform in-depth forensic analyses.
Financial institutions, for example, rely on comprehensive CDC logs to audit customer data modifications and ensure compliance with stringent data governance policies.
After exploring the methods and use cases, let’s examine some popular tools that facilitate CDC implementations. The right choice depends on your use case—whether you need real-time streaming, cloud migration, or enterprise ETL solutions.
AWS DMS uses log-based CDC to continuously replicate data from on‑premises systems to the AWS cloud with minimal downtime, making it an excellent choice for migrations. AWS DMS is a robust solution if your goal is to move data to the cloud with reliable uptime.
Best for: Cloud migrations and AWS-based architectures.
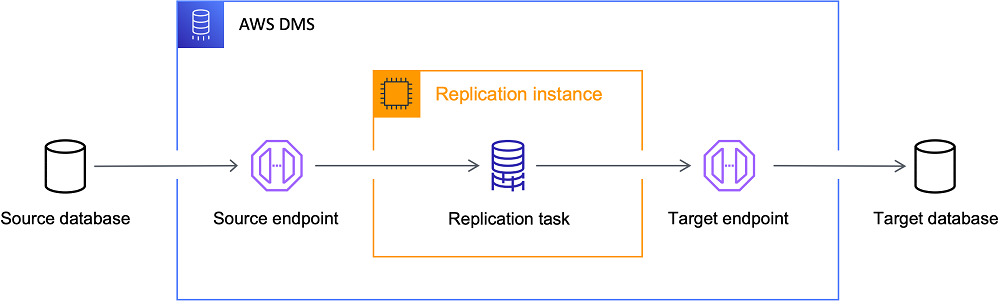
The AWS DMS Architecture. Image source: AWS
Debezium is an open‑source CDC platform that captures and streams database changes into systems like Apache Kafka.
Personally, I’ve found Debezium extremely useful for streaming database changes into Kafka, especially in distributed environments where multiple services depend on real‑time updates. Its scalability and integration capabilities make it a standout option.
Best for: Real-time data streaming and event-driven architectures.
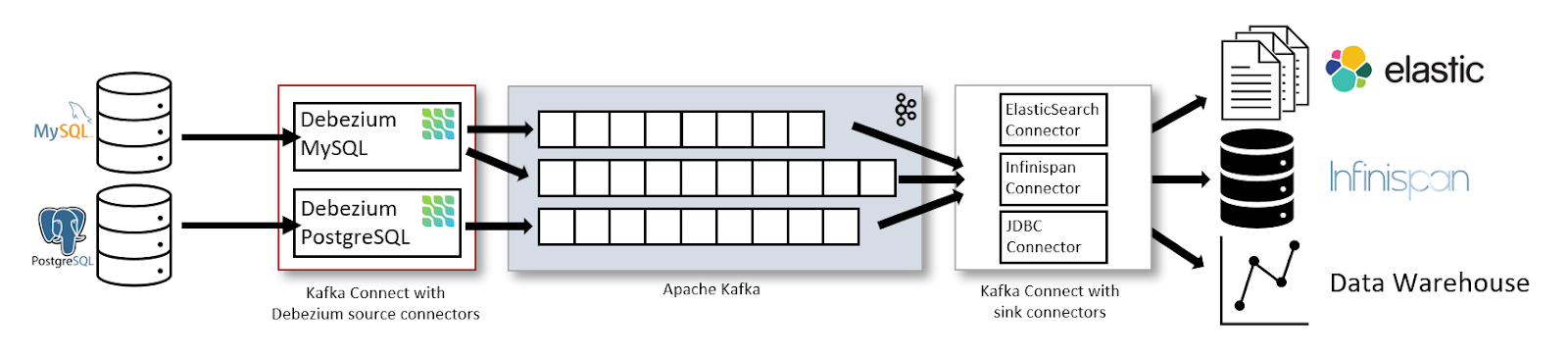
The Data Streaming Architecture with Kafka Connect and Debezium. Image source: Debezium
Apache Kafka isn't a CDC tool itself but serves as the backbone for processing CDC events when paired with tools like Debezium. Kafka enables reliable event-driven pipelines, real-time analytics, and data synchronization across multiple consumers.
Best for: Streaming CDC data to event-driven architectures.
To illustrate how CDC events can be sent to Kafka, consider the following Python snippet. The code initializes a Kafka producer and sends a CDC event (representing an update operation on an orders table) to a Kafka topic named cdc-topic:
from kafka import KafkaProducer
import json
# Initialize the Kafka producer with bootstrap servers and a JSON serializer for values.
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
# Define a CDC event that includes details of the operation.
cdc_event = {
"table": "orders",
"operation": "update",
"data": {"order_id": 123, "status": "shipped"}
}
# Send the CDC event to the 'cdc-topic' and flush to ensure transmission.
producer.send('cdc-topic', cdc_event)
producer.flush()
print("CDC event sent successfully!")Talend and Informatica are comprehensive ETL platforms offering built‑in CDC functionality to capture and process data changes, reducing manual configurations. They are especially advantageous in complex data transformation scenarios, where integrated solutions can simplify operations.
Best for: Enterprise-grade ETL solutions with built-in CDC.
Several relational databases offer native CDC features, reducing the need for external tools:
Best for: Minimizing dependencies on external CDC tools.
Cloud providers also offer CDC solutions for their ecosystems:
Best for: CDC within Google Cloud or Microsoft Azure environments.
While CDC offers significant benefits, it also comes with challenges that must be managed for a reliable implementation.
Maintaining data integrity can be challenging when dealing with network interruptions, delayed transactions, or system glitches. Robust error-handling protocols and regular reconciliations are vital to prevent discrepancies between the source and target systems. Addressing these issues early helps maintain a dependable data pipeline.
Certain CDC methods—particularly those that rely on triggers or frequent polling—can introduce additional load on source databases. Balancing the need for near‑real‑time updates with the performance constraints of your production systems is key to a smooth operation.
Although CDC efficiently captures raw changes, additional downstream processing, such as data cleansing or transformation, may be required. Integrating transformation logic without delaying deliveries or introducing errors adds complexity to CDC implementation, so careful planning is necessary.
Putting theory into practice requires adherence to best practices. Here are actionable tips from my experience that helped me build robust CDC pipelines.
Select a CDC approach that aligns with your data volume, latency requirements, and system architecture. Log-based CDC is usually optimal for high-transaction environments, while trigger‑ or polling‑based methods might be more suitable for smaller applications. Evaluating your specific needs upfront can save time and resources later.
Implement comprehensive monitoring using real‑time dashboards and automated alerts. Regular log reviews and health checks are essential to ensure that every change is captured accurately and that any issues are promptly addressed.
A minor log-based CDC misconfiguration in one project went unnoticed for days, leading to silent data loss in downstream analytics. Implementing Grafana alerts helped catch missing updates instantly, preventing costly errors.
Integrate data validation checkpoints within the CDC pipeline to ensure that only accurate and consistent changes are propagated.
From my experience, setting up automated validation checks in the CDC pipeline saved me from hours of debugging incorrect data propagation issues. Tools like dbt and Apache Airflow have been instrumental in enforcing consistency across multiple downstream systems.
Before moving your CDC solution to production, thoroughly test it in a staging environment. Simulate real‑world workloads and failure scenarios and validate features such as rollback and time travel to ensure the system behaves as expected under all conditions. This rigorous testing is important for a smooth production rollout.
Your CDC system must adapt to schema changes without disruption as your datasets evolve. Use tools that support automatic schema evolution and maintain proper version control so that new fields are integrated smoothly. This strategic approach prevents unexpected errors and downtime when data structures change.
By precisely capturing only the modified data, CDC minimizes system load and enables real‑time analytics and streaming applications to function properly. Whether you are implementing data replication, synchronization, or audit logging, selecting the appropriate CDC method and following best practices is key to building a reliable and efficient data pipeline.
For those who want to deepen their understanding, I encourage you to explore the following DataCamp courses:
Happy coding—and here’s to building resilient, real‑time data systems!
Learn more about data engineering with these courses!
Track
Course
Course
blog
Jake Roach
12 min
blog
Mike Shakhomirov
11 min
blog
Elena Kosourova
15 min
blog
Kurtis Pykes
15 min
Tutorial
Bex Tuychiev
Tutorial
Amberle McKee

