Lernpfad
Professioneller Dateningenieur in Python
40 Std.
Die Methoden zu verstehen ist nur die halbe Miete. Genauso wichtig ist es, zu sehen, wie CDC in realen Szenarien einen greifbaren Wert schafft.
CDC ermöglicht kontinuierliche, inkrementelle Aktualisierungen von Data Warehouses, indem nur die Änderungen weitergegeben werden, anstatt komplette Datensätze neu zu laden. Dieser Ansatz stellt sicher, dass die Business Intelligence-Tools und Dashboards die aktuellsten Daten anzeigen.
Ein Einzelhandelsunternehmen kann zum Beispiel sein Verkaufs-Dashboard fast in Echtzeit aktualisieren, um neue Trends und Erkenntnisse schnell zu erkennen.
CDC repliziert Daten zwischen Systemen, indem es sicherstellt, dass jede Änderung im Quellsystem sofort in den Zieldatenbanken gespiegelt wird. Dies ist besonders nützlich bei Datenmigrationsprojekten oder bei der Verwaltung von Backups und Repliken in hybriden Umgebungen.
Die Replikation von Daten aus lokalen Systemen in Cloud-Datenbanken wie AWS RDS oder Snowflake garantiert die Konsistenz über alle Plattformen hinweg.
In verteilten Systemen - wie z.B. solchen mit Microservices oder mehreren Anwendungen - stellt CDC sicher, dass jede Komponente mit den aktuellsten Daten arbeitet, indem Änderungen in Echtzeit synchronisiert werden.
Die Synchronisierung von Kundeninformationen über verschiedene Plattformen hinweg sorgt zum Beispiel für ein einheitliches Nutzererlebnis auf allen Ebenen.
Schließlich liefert CDC detaillierte Änderungsprotokolle, die für Auditing-Zwecke unerlässlich sind. Indem sie nachverfolgen, wer wann Änderungen vorgenommen hat, können die Teams die gesetzlichen Anforderungen erfüllen, Probleme beheben und eingehende forensische Analysen durchführen.
Finanzinstitute zum Beispiel verlassen sich auf umfassende CDC-Protokolle, um Änderungen an Kundendaten zu überprüfen und die Einhaltung strenger Data-Governance-Richtlinien sicherzustellen.
Nachdem wir die Methoden und Anwendungsfälle erkundet haben, wollen wir uns einige beliebte Tools ansehen, die die Umsetzung von CDC erleichtern. Die richtige Wahl hängt von deinem Anwendungsfall ab -ob du Echtzeit-Streaming, Cloud-Migration oder ETL-Lösungen für Unternehmen brauchst.
AWS DMS nutzt logbasierte CDC, um Daten kontinuierlich und mit minimaler Ausfallzeit von lokalen Systemen in die AWS-Cloud zu replizieren, was es zu einer hervorragenden Wahl für Migrationen macht. AWS DMS ist eine robuste Lösung, wenn dein Ziel darin besteht, Daten mit zuverlässiger Betriebszeit in die Cloud zu verlagern.
Am besten für: Cloud-Migrationen und AWS-basierte Architekturen.
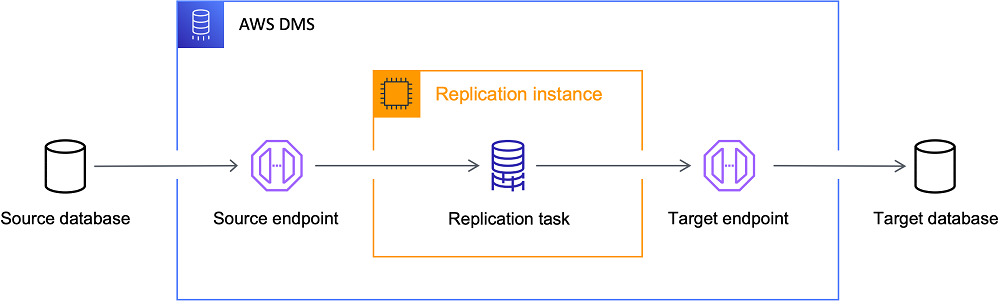
Die AWS DMS-Architektur. Bildquelle: AWS
Debezium ist eine Open-Source-CDC-Plattform, die Datenbankänderungen erfasst und in Systeme wie Apache Kafka streamt.
Ich persönlich finde Debezium sehr nützlich für das Streaming von Datenbankänderungen in Kafka, vor allem in verteilten Umgebungen, in denen mehrere Dienste auf Echtzeit-Updates angewiesen sind. Seine Skalierbarkeit und Integrationsmöglichkeiten machen es zu einer herausragenden Option.
Am besten für: Echtzeit-Daten-Streaming und ereignisgesteuerte Architekturen.
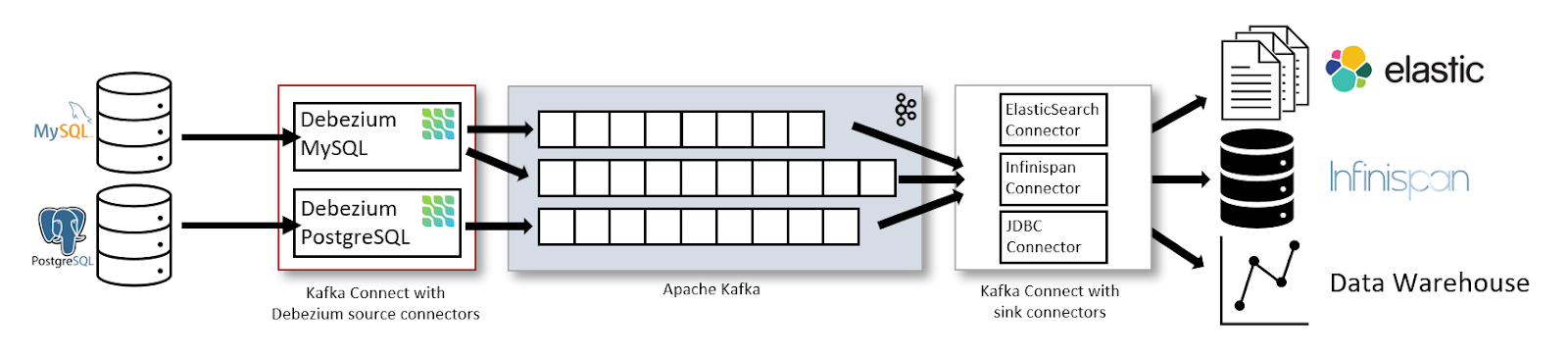
Die Daten-Streaming-Architektur mit Kafka Connect und Debezium. Bildquelle: Debezium
Apache Kafka ist kein eigenes CDC-Tool, sondern dient in Verbindung mit Tools wie Debezium als Rückgrat für die Verarbeitung von CDC-Ereignissen. Kafka ermöglicht zuverlässige ereignisgesteuerte Pipelines, Echtzeit-Analysen und die Synchronisierung von Daten über mehrere Verbraucher hinweg.
Am besten für: Streaming von CDC-Daten in ereignisgesteuerten Architekturen.
Um zu veranschaulichen, wie CDC-Ereignisse an Kafka gesendet werden können, schau dir das folgende Python-Snippet an. Der Code initialisiert einen Kafka-Producer und sendet ein CDC-Ereignis (das eine Update-Operation für eine Tabelle orders darstellt) an ein Kafka-Topic namens cdc-topic:
from kafka import KafkaProducer
import json
# Initialize the Kafka producer with bootstrap servers and a JSON serializer for values.
producer = KafkaProducer(
bootstrap_servers='localhost:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
# Define a CDC event that includes details of the operation.
cdc_event = {
"table": "orders",
"operation": "update",
"data": {"order_id": 123, "status": "shipped"}
}
# Send the CDC event to the 'cdc-topic' and flush to ensure transmission.
producer.send('cdc-topic', cdc_event)
producer.flush()
print("CDC event sent successfully!")Talend und Informatica sind umfassende ETL-Plattformen mit eingebauter CDC-Funktionalität, um Datenänderungen zu erfassen und zu verarbeiten und so manuelle Konfigurationen zu reduzieren. Sie sind besonders vorteilhaft in komplexen Datenumwandlungsszenarien, in denen integrierte Lösungen den Betrieb vereinfachen können.
Am besten für: ETL-Lösungen für Unternehmen mit integriertem CDC.
Einige relationale Datenbanken bieten native CDC-Funktionen, sodass weniger externe Tools benötigt werden:
Am besten für: Minimierung der Abhängigkeiten von externen CDC-Tools.
Cloud-Anbieter bieten auch CDC-Lösungen für ihre Ökosysteme an:
Am besten für: CDC in Google Cloud- oder Microsoft Azure-Umgebungen.
CDC bietet zwar erhebliche Vorteile, bringt aber auch Herausforderungen mit sich, die für eine zuverlässige Umsetzung gemeistert werden müssen.
Die Aufrechterhaltung der Datenintegrität kann eine Herausforderung sein, wenn es zu Netzwerkunterbrechungen, verzögerten Transaktionen oder Systemproblemen kommt. Robuste Fehlerbehandlungsprotokolle und regelmäßige Abstimmungen sind unerlässlich, um Diskrepanzen zwischen dem Quell- und dem Zielsystem zu vermeiden. Die frühzeitige Behebung dieser Probleme trägt dazu bei, dass die Datenpipeline zuverlässig funktioniert.
Bestimmte CDC-Methoden - insbesondere solche, die auf Triggern oder häufigen Abfragen basieren - können die Quelldatenbanken zusätzlich belasten. Der Schlüssel zu einem reibungslosen Betrieb liegt darin, den Bedarf an zeitnahen Aktualisierungen mit den Leistungsbeschränkungen deiner Produktionssysteme in Einklang zu bringen.
Auch wenn CDC rohe Änderungen effizient erfasst, kann eine zusätzliche nachgelagerte Verarbeitung, wie z. B. eine Datenbereinigung oder -umwandlung, erforderlich sein. Die Integration der Transformationslogik ohne Lieferverzögerungen oder Fehler erhöht die Komplexität der CDC-Implementierung, daher ist eine sorgfältige Planung erforderlich.
Um die Theorie in die Praxis umzusetzen, muss man sich an die besten Praktiken halten. Hier sind Tipps aus meiner Erfahrung, die mir geholfen haben, robuste CDC-Pipelines aufzubauen.
Wähle einen CDC-Ansatz, der zu deinem Datenvolumen, deinen Latenzanforderungen und deiner Systemarchitektur passt. Log-basiertes CDC ist in der Regel optimal für Umgebungen mit vielen Transaktionen, während trigger- oder polling-basierte Methoden für kleinere Anwendungen besser geeignet sind. Wenn du deine spezifischen Bedürfnisse im Voraus abschätzt, kannst du später Zeit und Ressourcen sparen.
Implementiere eine umfassende Überwachung mit Echtzeit-Dashboards und automatischen Warnmeldungen. Regelmäßige Überprüfungen des Protokolls und Gesundheitschecks sind wichtig, um sicherzustellen, dass jede Änderung korrekt erfasst wird und dass alle Probleme umgehend behoben werden.
Eine geringfügige logbasierte CDC-Fehlkonfiguration in einem Projekt blieb tagelang unbemerkt und führte zu einem stillen Datenverlust bei nachgelagerten Analysen. Die Implementierung von Grafana-Warnungen half, fehlende Aktualisierungen sofort zu erkennen und kostspielige Fehler zu vermeiden.
Integriere Prüfpunkte zur Datenvalidierung in die CDC-Pipeline, um sicherzustellen, dass nur korrekte und konsistente Änderungen weitergegeben werden.
Ich habe die Erfahrung gemacht, dass die Einrichtung automatischer Validierungsprüfungen in der CDC-Pipeline mich vor stundenlanger Fehlersuche bei der Datenübermittlung bewahrt hat. Tools wie dbt und Apache Airflow haben dazu beigetragen, die Konsistenz zwischen mehreren nachgelagerten Systemen zu gewährleisten.
Bevor du deine CDC-Lösung in die Produktion überführst, solltest du sie gründlich in einer Staging-Umgebung testen. Simuliere reale Arbeitsbelastungen und Ausfallszenarien und validiere Funktionen wie Rollback und Zeitreisen, um sicherzustellen, dass sich das System unter allen Bedingungen wie erwartet verhält. Diese strengen Tests sind wichtig für eine reibungslose Produktionseinführung.
Dein CDC-System muss sich ohne Unterbrechung an Schemaänderungen anpassen, wenn sich deine Datensätze weiterentwickeln. Verwende Tools, die eine automatische Schemaentwicklung unterstützen, und sorge für eine angemessene Versionskontrolle, damit neue Felder reibungslos integriert werden können. Dieser strategische Ansatz verhindert unerwartete Fehler und Ausfallzeiten, wenn sich Datenstrukturen ändern.
Indem CDC nur die geänderten Daten präzise erfasst, minimiert es die Systembelastung und sorgt dafür, dass Echtzeit-Analysen und Streaming-Anwendungen ordnungsgemäß funktionieren. Ganz gleich, ob du Datenreplikation, Synchronisierung oder Audit-Logging implementierst, die Auswahl der geeigneten CDC-Methode und die Einhaltung von Best Practices sind der Schlüssel zum Aufbau einer zuverlässigen und effizienten Datenpipeline.
Wenn du dein Wissen vertiefen möchtest, empfehle ich dir, die folgenden DataCamp-Kurse zu besuchen:
Viel Spaß beim Programmieren - und auf den Aufbau stabiler Echtzeit-Datensysteme!
Lerne mehr über Data Engineering mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
