Curso
Introdução a LLMs em Python
3 h
33.6K
O campo da Inteligência Artificial (IA) está testemunhando uma explosão nos recursos dos Modelos de Linguagem Grande (LLMs), que são cada vez mais hábeis em tarefas que exigem compreensão e geração sofisticadas de linguagem humana. À medida que esses modelos se tornam mais avançados, a necessidade de métodos de avaliação robustos se torna necessária.
É aqui que entra em cena o benchmark MMLU (Massive Multitask Language Understanding). Trata-se de um teste abrangente e desafiador para os sistemas de IA mais avançados da atualidade. A pontuação do MMLU se tornou um indicador importante do progresso de um modelo e uma força motriz na busca contínua para criar máquinas mais inteligentes.
Entender o significado do MMLU e sua função é importante para qualquer pessoa envolvida em ciência de dados ou IA, pois ele fornece uma maneira padronizada de avaliar o conhecimento geral e as habilidades de raciocínio desses modelos em uma grande variedade de assuntos. Esses recursos são fundamentais para o desenvolvimento de modelos de linguagem de grande porte.
Neste artigo, veremos o que é o MMLU, o que envolve o processo de avaliação do MMLU, como o extenso conjunto de dados do MMLU está estruturado e por que esse benchmark é tão importante para o avanço da IA.
O MMLU (Massive Multitask Language Understanding) é um benchmark abrangente projetado para avaliar o conhecimento e as habilidades de solução de problemas de modelos de linguagem grandes (LLMs) em uma ampla e diversificada gama de assuntos. Ele consiste em perguntas de múltipla escolha que abrangem 57 tarefas diferentes, incluindo matemática elementar, história dos EUA, ciência da computação, direito e muito mais.
A ideia central por trás do benchmark MMLU é testar o conhecimento adquirido e as habilidades de raciocínio de um modelo em uma configuração de zero ou poucas tentativas, o que significa que o modelo deve responder a perguntas com pouco ou nenhum exemplo específico de tarefa.
Essa abordagem visa medir a capacidade dos modelos de entender e aplicar o conhecimento da fase de pré-treinamento a tarefas para as quais não foram explicitamente ajustados, refletindo uma forma mais geral e robusta de inteligência. O desempenho de um modelo é normalmente resumido por sua pontuação MMLU, indicando sua precisão nesses diversos domínios.
A estrutura de avaliação MMLU é profundamente significativa para a pesquisa e o desenvolvimento de IA por vários motivos importantes, como:
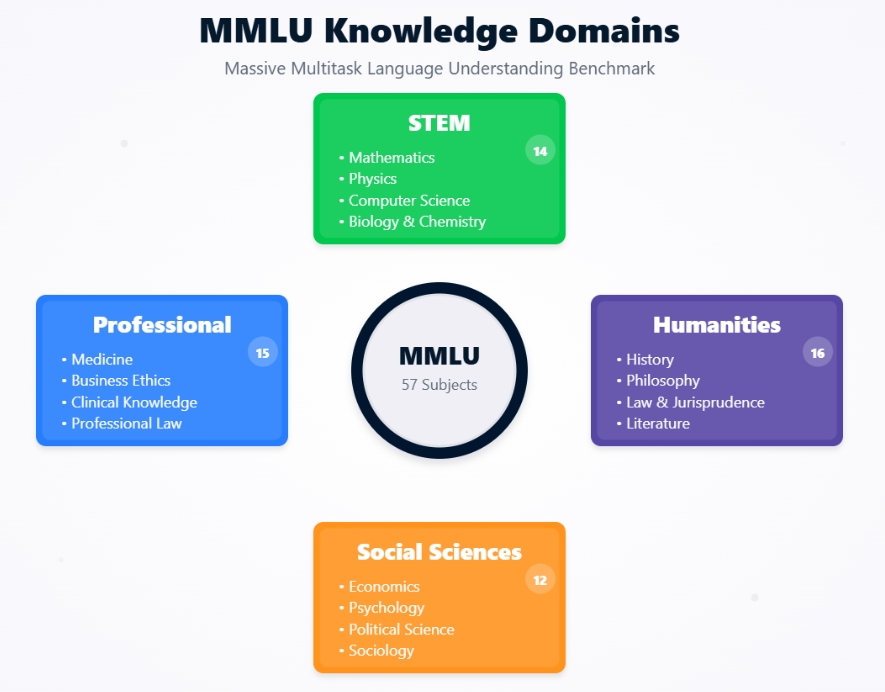
Domínios de conhecimento do MMLU
O surgimento do MMLU é mais bem compreendido quando se observa a evolução da avaliação do modelo de linguagem e as motivações que impulsionaram sua criação.
O MMLU foi apresentado por Dan Hendrycks e uma equipe de pesquisadores em seu artigo de 2020, "Measuring Massive Multitask Language Understanding". A principal motivação foi a observação de que os benchmarks existentes estavam ficando saturados por LLMs que melhoravam rapidamente.
Os modelos estavam alcançando um desempenho quase humano ou até mesmo sobre-humano em benchmarks como GLUE e SuperGLUE, mas nem sempre estava claro se isso se traduzia em uma compreensão ampla e humana do mundo.
Os criadores do MMLU procuraram desenvolver um teste mais desafiador e abrangente que pudesse:
O objetivo era criar uma avaliação que pudesse diferenciar melhor os recursos de LLMs cada vez mais avançados e fornecer um caminho mais claro para sistemas inteligentes mais gerais.
O MMLU representa uma etapa significativa na evolução dos padrões de referência para a compreensão de linguagem natural (NLU).
As primeiras avaliações de NLU geralmente se concentravam em tarefas individuais, como análise de sentimentos, reconhecimento de entidades nomeadas ou tradução automática, cada uma com seu próprio conjunto de dados e métricas.
Introduzido em 2018, o GLUE (General Language Understanding Evaluation) era uma coleção de nove tarefas NLU diversas, projetadas para fornecer uma métrica de número único para o desempenho geral do modelo. Ele se tornou um padrão por um tempo, mas logo foi superado por modelos.
Desenvolvido em 2019 como um sucessor mais desafiador do GLUE, o SuperGLUE apresentava tarefas mais difíceis e uma linha de base humana mais abrangente. No entanto, até mesmo a SuperGLUE viu modelos se aproximarem rapidamente do desempenho humano.
O MMLU melhorou em relação a esses benchmarks anteriores de várias maneiras importantes. Com 57 tarefas, o conjunto de dados do MMLU é muito mais extenso e abrange uma gama muito maior de assuntos acadêmicos e profissionais do que o GLUE (9 tarefas) ou o SuperGLUE (8 tarefas + um conjunto de dados de diagnóstico). Essa amplitude dificulta a especialização dos modelos e incentiva um conhecimento mais geral.
Enquanto o GLUE/SuperGLUE testou vários fenômenos linguísticos, o MMLU avalia diretamente o conhecimento em domínios específicos, como direito, medicina e ética, o que exige mais do que apenas o processamento da linguagem.
O MMLU prioriza a avaliação de modelos com o mínimo de exemplos específicos de tarefas. Isso contrasta com muitas tarefas no GLUE/SuperGLUE, em que os modelos eram frequentemente ajustados em conjuntos de treinamento específicos da tarefa. Isso faz com que a avaliação do MMLU seja um teste melhor da capacidade de generalização de um modelo a partir de seu pré-treinamento.
As perguntas do MMLU geralmente são projetadas para serem desafiadoras até mesmo para os seres humanos, especialmente em domínios especializados, proporcionando um caminho mais longo para medir o progresso da IA.
Ao abordar esses aspectos, a MMLU estabeleceu um padrão novo e mais exigente para o que significa para um LLM "entender" o idioma e o mundo.
Para que você possa realmente apreciar o benchmark MMLU, é essencial entender sua estrutura subjacente e como ele avalia os modelos de linguagem. Vamos analisar a composição do conjunto de dados do MMLU, a amplitude dos assuntos que ele abrange e as metodologias de avaliação específicas que o tornam um teste robusto dos recursos de IA.
O ponto forte da avaliação do MMLU está em seu conjunto de dados meticulosamente selecionado, projetado para ser amplo e profundo.
O conjunto de dados do MMLU não é uma entidade monolítica, mas uma coleção de 57 tarefas distintas, cada uma correspondendo a uma área temática específica. Esses assuntos são intencionalmente diversos, abrangendo várias categorias principais:
Cada tarefa do conjunto de dados MMLU consiste em perguntas de múltipla escolha. Normalmente, cada pergunta apresenta um problema ou consulta seguido de quatro respostas possíveis, uma das quais é a correta. As perguntas foram elaboradas para testar o conhecimento em vários níveis de dificuldade, desde o ensino médio até a faculdade e até mesmo níveis profissionais especializados.
Por exemplo, uma pergunta da matéria "Medicina Profissional" exigiria um nível de conhecimento esperado de um profissional da área médica, o que a tornaria um teste desafiador até mesmo para LLMs altamente capacitados.
O grande volume e a diversidade de perguntas garantem que os modelos não podem simplesmente confiar na memorização das respostas, mas devem ter um entendimento genuíno do assunto para obter uma pontuação alta no MMLU.
As perguntas do conjunto de dados do MMLU são provenientes de uma variedade de materiais do mundo real para garantir sua relevância e dificuldade. Essas fontes incluem:
Essa estratégia de fornecimento garante que as perguntas reflitam o tipo de conhecimento e os desafios de raciocínio encontrados em ambientes acadêmicos e profissionais.
O objetivo é avaliar a capacidade de um modelo de entender e aplicar o conhecimento em contextos semelhantes aos enfrentados por seres humanos instruídos.
Um aspecto fundamental do significado do MMLU e de seu poder de avaliação está no uso dos paradigmas de aprendizado de zero e poucos disparos. Essas metodologias são importantes para testar a capacidade de um modelo de generalizar seu conhecimento sem treinamento extensivo específico da tarefa.
Em um cenário de zero-shot, o LLM recebe perguntas de uma tarefa específica do MMLU (por exemplo, "Álgebra abstrata" ou "Cenários morais") sem ter visto qualquer exemplos dessa tarefa específica durante sua fase de ajuste fino ou no próprio prompt.
O modelo deve entender a pergunta e selecionar a resposta correta de múltipla escolha com base apenas em seu conhecimento pré-treinado.
Por exemplo, o prompt pode ser simplesmente:
A seguir, você encontrará perguntas de múltipla escolha (com respostas) sobre [nome do assunto].
[Pergunta]
A) [Opção A] Você pode usar o sistema para fazer o que quiser.
B) [Opção B] Você pode usar o sistema de gerenciamento de risco para obter informações sobre o que está acontecendo.
C) [Opção C]
D) [Opção D] Você pode usar o sistema de gerenciamento de dados para obter informações sobre o que está acontecendo.
Resposta:
Em seguida, espera-se que o modelo forneça a letra da opção correta. Essa configuração testa rigorosamente a capacidade do modelo de generalizar sua compreensão para domínios e estilos de perguntas totalmente novos.
Em uma configuração de poucas tentativas, o modelo recebe um pequeno número de exemplos (geralmente cinco, por isso "5 tentativas") da tarefa específica do MMLU diretamente no prompt antes de antes de se deparar com a pergunta real do teste.
Esses exemplos consistem em uma pergunta, as opções de múltipla escolha e a resposta correta.
Por exemplo:
A seguir, você encontrará perguntas de múltipla escolha (com respostas) sobre disputas morais.
Pergunta: John Doe é um engenheiro de software que trabalha para uma empresa que desenvolve armas autônomas. Ele tem sérias preocupações éticas sobre o possível uso indevido dessa tecnologia, que poderia causar vítimas civis. No entanto, ele também tem uma família para sustentar e teme perder o emprego se falar sobre o assunto. Qual é o principal conflito ético que John está enfrentando?
A) Conflito de interesses
B) Dilema do denunciante
C) Negligência profissional
D) Direitos de propriedade intelectual
Resposta: B
[... Mais 4 exemplos ...]
Pergunta: [Pergunta do teste real]
A) [Opção A] Você pode usar o sistema para fazer o que quiser.
B) [Opção B] Você pode usar o sistema de gerenciamento de risco para obter informações sobre o que está acontecendo.
C) [Opção C]
D) [Opção D] Você pode usar o sistema de gerenciamento de dados para obter informações sobre o que está acontecendo.
Resposta:
O modelo usa esses poucos exemplos para entender o contexto, o estilo e o raciocínio esperado para a tarefa antes de tentar a nova pergunta que não foi vista. Isso testa a capacidade do modelo de aprendizagem e adaptação rápidas e dentro do contexto.
A importância dessas metodologias na avaliação do MMLU é que elas refletem como os seres humanos geralmente abordam novos problemas, seja aplicando o conhecimento existente a algo totalmente novo (zero-shot) ou aprendendo rapidamente com alguns exemplos (few-shot).
Essas configurações de avaliação simulam tarefas comuns de processamento de linguagem do mundo real.
Os cenários de disparo zero são semelhantes a um usuário que faz uma pergunta a uma IA sobre um tópico ao qual a IA nunca foi especificamente solicitada antes. Por exemplo, um usuário pode fazer a um assistente de IA de uso geral uma pergunta jurídica complexa ou uma consulta filosófica com nuances. A capacidade da IA de fornecer uma resposta sensata se baseia em seu amplo conhecimento pré-treinado.
Os cenários de poucos disparos espelham situações em que um usuário fornece contexto ou exemplos para orientar a IA. Por exemplo, um usuário pode mostrar à IA alguns exemplos de como resumir relatórios médicos antes de pedir que ela resuma um novo relatório, ou fornecer exemplos de um estilo poético específico antes de pedir que a IA gere um poema nesse estilo.
Ao avaliar os modelos em configurações de zero e poucos disparos, o MMLU oferece uma visão mais abrangente de sua flexibilidade e recursos de aprendizagem, que são importantes para a criação de sistemas de IA realmente úteis e adaptáveis.
A capacidade de apresentar um bom desempenho nessas condições é um forte indicador do potencial de um modelo para aplicação prática em uma ampla gama de tarefas, sem a necessidade de retreinamento extenso e dispendioso para cada novo problema.
A evolução dos modelos de linguagem no benchmark MMLU destaca o rápido desenvolvimento da IA. Vamos analisar o desempenho inicial, os avanços subsequentes nas pontuações do MMLU e comparar os recursos de IA com os benchmarks de especialistas humanos.
Introduzido no final de 2020, o MMLU revelou rapidamente as limitações dos LLMs de última geração existentes. Os primeiros encontros com o conjunto de dados do MMLU foram difíceis. As pontuações iniciais do MMLU para a maioria dos modelos contemporâneos estavam em torno de 25 a 30%, enquanto o maior GPT-3 atingiu cerca de 44%.
Como você pode ver, até mesmo modelos capazes, como as primeiras versões do GPT-3, tiveram dificuldades, mostrando que a compreensão ampla e semelhante à humana estava distante.
Os principais desafios incluíam déficits de conhecimento especializado (por exemplo, direito, medicina), raciocínio complexo limitado, fragilidade em cenários de zero ou poucas chances e vulnerabilidade a opções de distração nas perguntas. Essas descobertas ressaltaram o valor da MMLU na identificação das fronteiras do LLM.
Desde o lançamento do MMLU, o desempenho do LLM aumentou. Esse progresso decorre de inovações arquitetônicas, aumento da escala do modelo, melhores dados de treinamento e métodos refinados, como o ajuste fino de instruções e o aprendizado por reforço com feedback humano (RLHF). Consequentemente, as pontuações do MMLU aumentaram muito.
Os principais fatores incluem a confirmação das leis de escala, refinamentos arquitetônicos nos Transformers, técnicas avançadas de treinamento que aprimoram o raciocínio e o alinhamento e o design inerente do MMLU que promove a proficiência em multitarefas. O desenvolvimento de práticas sofisticadas de MLOps também desempenhou um papel crucial na otimização dos processos de treinamento e implantação de modelos.
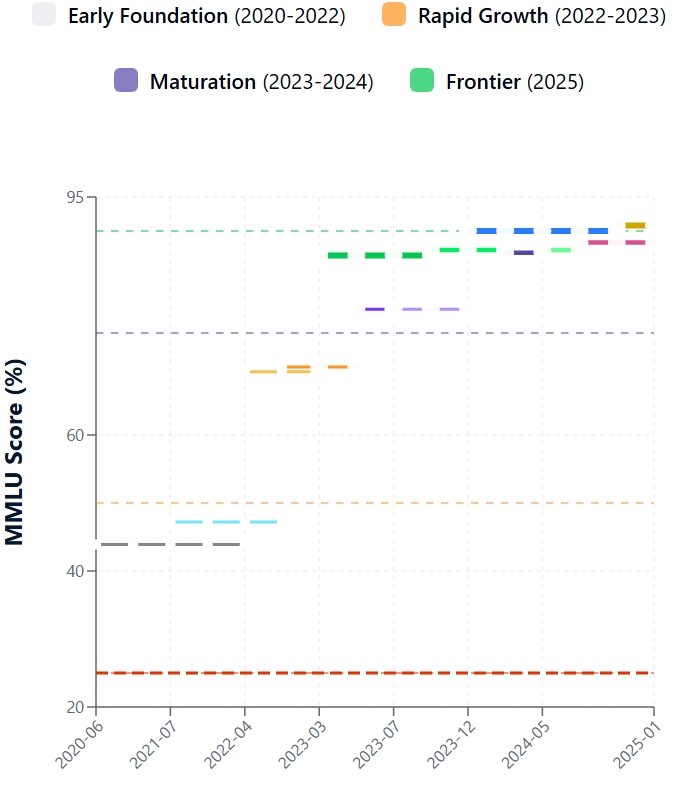
Evolução da pontuação do MMLU
O MMLU justapõe de forma crucial o desempenho da IA com o intelecto humano. A pesquisa original do MMLU definiu a precisão do especialista humano em torno de 90%. Inicialmente, os LLMs ficaram significativamente defasados. No entanto, os modelos mais recentes reduziram drasticamente essa diferença.
Os principais modelos agora relatam pontuações MMLU que atendem ou superam ligeiramente o benchmark médio de especialistas humanos. É importante observar que "especialista humano" é um intervalo, e o desempenho do modelo varia de acordo com o assunto. Por exemplo, o recente modelo GPT-4.1 registra uma pontuação de 90,2% no MMLU, e o Claude 4 Opus atinge 88,8%.
Embora seja impressionante, exceder as pontuações médias não equivale a compreensão, bom senso ou criatividade semelhantes aos humanos. Os modelos ainda podem ser frágeis ou ter dificuldades com novos raciocínios. As pontuações de zero disparo, um teste mais puro de generalização, também melhoraram, mas geralmente ficam atrás dos resultados de poucos disparos.
Atingir e, às vezes, superar as pontuações do MMLU de especialistas humanos tem implicações profundas: valida o progresso da IA, aumenta a utilidade no mundo real em campos de conhecimento intensivo, catalisa o desenvolvimento de benchmarks mais desafiadores (como o MMLU-Pro) e aumenta os diálogos éticos e sociais sobre o papel da IA. Embora as altas pontuações do MMLU sejam marcos importantes, o foco continua sendo a criação de uma IA robusta, interpretável e alinhada com a ética.
Embora o benchmark MMLU original tenha avançado significativamente na avaliação do LLM, suas limitações se tornaram aparentes com o rápido progresso da IA. Isso levou a derivados como o MMLU-Pro e o MMLU-CF, visando a avaliações mais rigorosas.
O MMLU original enfrentou vários desafios à medida que os modelos se tornaram mais sofisticados. Uma grande preocupação é que as perguntas do conjunto de dados MMLU disponíveis publicamente podem estar nos dados de treinamento do LLM, aumentando as pontuações do MMLU e não refletindo a verdadeira generalização.
Algumas perguntas em qualquer benchmark grande podem ser falhas, ambíguas ou desatualizadas, afetando a confiabilidade da avaliação do MMLU. À medida que os principais modelos se aproximavam de pontuações perfeitas, a capacidade do MMLU de diferenciar os recursos de raciocínio avançado diminuía, o que levou a pedidos de tarefas mais complexas.
Seu conjunto fixo de perguntas não evolui com os avanços do modelo ou com novas áreas de conhecimento. Por ser de múltipla escolha, o MMLU não testa as capacidades cruciais de geração, explicação ou criatividade do LLM. Abordar essas questões é vital para uma avaliação significativa da IA.
O MMLU-Pro foi desenvolvido para testar o raciocínio mais profundo com perguntas mais desafiadoras. O MMLU-Pro aumenta a dificuldade da avaliação, concentrando-se em perguntas que exigem compreensão profunda e raciocínio sofisticado. Os principais aprimoramentos incluem:
O MMLU-Pro reflete os esforços contínuos para garantir que os benchmarks impulsionem os avanços no raciocínio de IA.
O MMLU-CF (Contamination-Free) trata especificamente da contaminação de dados no benchmarking LLM. O objetivo do MMLU-CF é fornecer uma avaliação do MMLU com perguntas altamente improváveis de serem incluídas nos dados de treinamento do modelo. As estratégias incluem:
O MMLU-CF é importante para a integridade do benchmark. Uma pontuação alta no MMLU em uma versão livre de contaminação indica de forma mais confiável a generalização e o raciocínio genuínos, e não a memorização. Isso é vital para que você possa acompanhar com precisão o progresso da IA e fazer uma comparação justa dos modelos.
A criação e a ampla aceitação do benchmark MMLU tiveram um impacto significativo no campo da IA, moldando tanto as investigações teóricas quanto os usos no mundo real. Entender suas implicações é fundamental para que você compreenda sua importância geral.
O MMLU moldou significativamente a direção da pesquisa em IA. Ao estabelecer um alto padrão de conhecimento e raciocínio amplos, ele impulsionou inovações na arquitetura de modelos e nas metodologias de treinamento.
Os pesquisadores estão constantemente explorando novas maneiras de melhorar a pontuação MMLU de seus modelos, levando a avanços em áreas como:
A integração das metodologias LLMOps tornou-se essencial para gerenciar esses processos de desenvolvimento de modelos cada vez mais complexos.
Além disso, o surgimento de abordagens inovadoras como o LMQL para interações estruturadas com LLMs demonstra como o campo está se expandindo para criar ferramentas mais especializadas para trabalhar com LLMs.
Os recursos obtidos com a busca de uma melhor avaliação do MMLU se traduzem diretamente em aplicativos mais avançados e confiáveis no mundo real.
Os modelos que apresentam bom desempenho no MMLU geralmente são mais hábeis em tarefas que exigem compreensão e raciocínio profundos, abrindo portas em vários setores, como o de serviços:
O progresso refletido nas pontuações do MMLU sustenta a utilidade crescente de modelos de linguagem grandes nesses campos.
Implementações modernas, como a Llama 3, mostram como os LLMs avançados podem ser implementados de forma eficaz em cenários reais.
A jornada da avaliação de modelos de linguagem está longe de terminar. O próprio MMLU, juntamente com seus derivados, aponta para várias tendências e desafios emergentes.
Os benchmarks futuros provavelmente incorporarão formatos de avaliação mais diversificados, incluindo respostas a perguntas abertas, diálogos interativos e conclusão de tarefas em ambientes simulados para avaliar uma gama mais ampla de recursos de IA.
À medida que a IA avança no sentido de compreender e gerar conteúdo em texto, imagens, áudio e vídeo, os padrões de referência precisarão evoluir para avaliar essas habilidades multimodais.
Há uma ênfase cada vez maior no desenvolvimento de padrões de referência que testem rigorosamente a segurança, a justiça, a parcialidade e o alinhamento ético do modelo. A implementação de fluxos de trabalho automatizados de MLOps será fundamental para manter a integridade da avaliação em escala.
Garantir a integridade do benchmark por meio de métodos como os do MMLU-CF continuará sendo um desafio importante, principalmente porque as organizações adotam estruturas abrangentes de MLOps para gerenciar seus sistemas de IA.
É inegável que o benchmark MMLU reformulou a forma como medimos e impulsionamos o progresso em modelos de linguagem grandes. Desde seu abrangente conjunto de dados MMLU até seus desafiadores métodos de avaliação MMLU, ele impulsiona a IA para um conhecimento mais amplo e um raciocínio mais profundo. À medida que os modelos continuarem a evoluir, o mesmo acontecerá com os benchmarks que os orientam, garantindo um futuro de IA cada vez mais capaz e versátil.
Você está pronto para se aprofundar no mundo dos LLMs e MLOs? Explore o curso Conceitos de modelos de linguagem grande (LLMs) para expandir seus conhecimentos.
Principais cursos da DataCamp
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Nisha Arya Ahmed
12 min
blog
Abid Ali Awan
8 min
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
