
Course
Introduction to Deep Learning in Python
4 hr
263.5K
The massive adoption of tools like ChatGPT and other generative AI tools has resulted in a huge debate on the benefits and challenges of AI and how it will reshape our society. To better assess these questions, it’s important to know how the so-called Large Language Models (LLMs) behind next-generation AI tools work.
This article provides an introduction to Reinforcement Learning from Human Feedback (RLHF), an innovative technique that combines reinforcement learning techniques and human guidance to help LLMS like ChatGPT deliver impressive results. We will cover what RLHF is, its benefits, limitations, and its relevance in the future development of the fast-paced field of generative AI. Keep reading!
To understand the role of RLHF, we first need to speak about the training process of LLMs.
The underlying technology of the most popular LLMs is a transformer. Since its development by Google researchers, transformers have become the state-of-the-art model in the field of AI and deep learning, as they provide a more effective method to handle sequential data, like the words in a phrase.
To gain a more detailed introduction to LLMs and transformers, check out our Large Language Models (LLMs) Concepts Course.
Transformers are pre-trained with a huge corpus of text gathered from the Internet using self-supervised learning, an innovative type of training that doesn’t require human action to label data. Pretrained transformers are capable of solving a wide array of natural language processing (NLP) problems.
However, for an AI tool like ChatGPT to provide engaging, accurate, and human-like answers, using a pre-trained LLM will not be enough. In the end, human communication is a creative and subjective process. What makes a text “good” is deeply influenced by human values and preferences, making it very difficult to measure or capture using a clear, algorithmic solution.
The idea behind ELF is to use human feedback to measure and improve the performance of the model. What makes RLHF unique compared to other reinforcement learning techniques is the use of human participation to optimize the model instead of a statistically-predefined function to maximize the reward of the agent.
This strategy allows for a more adaptable and personalized learning experience, making LLMs suitable for all kinds of sector-specific applications, such as code assistance, legal research, essay writing, and poem generation.
RLHF is a challenging process that involves a multiple-model training process and different stages of deployment. In essence, it can be broken down into three different steps.
The first stage entails selecting a pre-trained LLM that will be later fine-tuned using RLHF.
You could also pre-train your LLM from scratch, but this is a costly and time-consuming process. Hence, we highly recommend choosing one of the many pre-trained LLMs available for the public.
If you want to know more about how to train LLM, our How to Train a LLM with PyTorch tutorial provides an illustrative example.
Notice that, to meet the specific need of your model, before starting the fine-tuning phase using human feedback, you could fine-tune your model on additional texts or conditions.
For example, if you want to develop an AI legal assistant, you could fine-tune your model with a corpus of legal text to make your LLM particularly familiar with legal wording and concepts.
Instead of using a statistically pre-defined reward model (that would be very restrictive to calibrate human preferences), RLHF uses human feedback to help the model develop a more subtle reward model. The process goes as follows:
The following image illustrates the whole process:
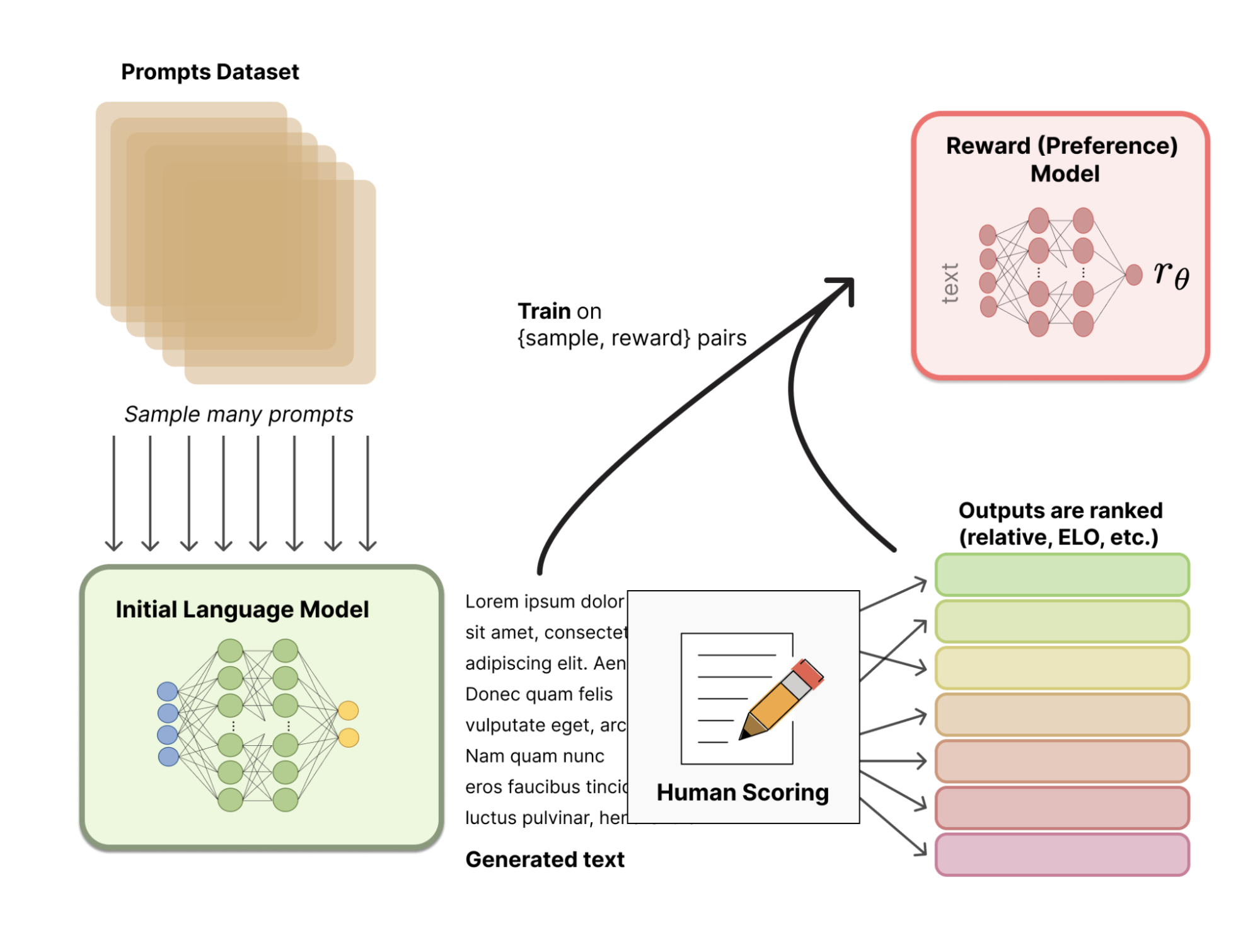
Source: Hugging Face
In the last stage, the LLM produces new texts and uses its human-feedback-based reward model to produce a quality score. The score is then used by the model to improve its performance on subsequent prompts.
Human feedback and fine-tuning with reinforcement learning techniques are thus combined in an iterative process that continues until a certain degree of accuracy is achieved.
RLHF is a state-of-the-art technique to fine-tune LLMs, such as ChatGPT. However, RLHF is a popular topic, with growing literature exploring other possibilities beyond NLP problems. Below you can find a list of other areas where RLHF has been applied successfully:
RLHF is a powerful and promising technique without which next-generation AI tools wouldn't be possible. Here are some of the benefits of RLHF:
However, RLHF is not bulletproof. This technique also poses certain risks and limitations. Below, you can see some of the most relevant:
RLHF is one of the backbones of modern generative AI tools, like ChatGPT and GPT-4. Despite its impressive results, RLHF is a relatively new technique, and there is still a wide margin for improvement. Future research on RLHF techniques is critical to make LLMs more efficient, reduce their environmental footprint, and address some of the risks and limitations of LLMs.
To stay tuned with the latest developments in generative AI, machine learning, and LLMs, we highly recommend you check out our curated learning materials:
Learn Topics Mentioned in this Article!
Course
Course
Course
blog
Ryan Ong
12 min
blog
Hesam Sheikh Hassani
5 min
blog
Javier Canales Luna
9 min
Tutorial
Bex Tuychiev
Tutorial
Matt Crabtree
Tutorial
Matt Crabtree


