
Cours
Introduction au Deep Learning en Python
4 h
263.6K
L'adoption massive d'outils comme le ChatGPT et d'autres outils d'IA générative a donné lieu à un énorme débat sur les avantages et les défis de l'IA et sur la manière dont elle va remodeler notre société. Pour mieux répondre à ces questions, il est important de savoir comment fonctionnent les "grands modèles de langage" (LLM) sur lesquels reposent les outils d'IA de la prochaine génération.
Cet article propose une introduction au Reinforcement Learning from Human Feedback (RLHF), une technique innovante qui combine des techniques d'apprentissage par renforcement et des conseils humains pour aider les LLMS comme ChatGPT à obtenir des résultats impressionnants. Nous verrons ce qu'est la RLHF, ses avantages, ses limites et sa pertinence pour le développement futur du domaine en pleine évolution de l'IA générative. Poursuivez votre lecture !
Pour comprendre le rôle de la RLHF, il faut d'abord parler du processus de formation des MFR.
La technologie sous-jacente des LLM les plus populaires est un transformateur. Depuis son développement par les chercheurs de Google, les transformateurs sont devenus le modèle de pointe dans le domaine de l'IA et de l'apprentissage profond, car ils fournissent une méthode plus efficace pour traiter les données séquentielles, comme les mots d'une phrase.
Pour une introduction plus détaillée aux LLM et aux transformateurs, consultez notre cours sur les concepts des grands modèles de langage (LLM).
Les transformateurs sont pré-entraînés à l'aide d'un vaste corpus de textes recueillis sur l'internet en utilisant l'apprentissage auto-supervisé, un type d'apprentissage innovant qui ne nécessite pas d'action humaine pour étiqueter les données. Les transformateurs préformés sont capables de résoudre un large éventail de problèmes de traitement du langage naturel (NLP).
Cependant, pour qu'un outil d'IA comme ChatGPT fournisse des réponses engageantes, précises et semblables à celles des humains, l'utilisation d'un LLM pré-entraîné ne sera pas suffisante. En fin de compte, la communication humaine est un processus créatif et subjectif. Ce qui rend un texte "bon" est profondément influencé par les valeurs et les préférences humaines, ce qui le rend très difficile à mesurer ou à appréhender à l'aide d'une solution algorithmique claire.
L'idée derrière ELF est d'utiliser le feedback humain pour mesurer et améliorer la performance du modèle. Ce qui rend la méthode RLHF unique par rapport aux autres techniques d'apprentissage par renforcement, c'est l'utilisation de la participation humaine pour optimiser le modèle au lieu d'une fonction statistiquement prédéfinie pour maximiser la récompense de l'agent.
Cette stratégie permet une expérience d'apprentissage plus adaptable et personnalisée, ce qui rend les masters en droit adaptés à toutes sortes d'applications sectorielles, telles que l'assistance au codage, la recherche juridique, la rédaction d'essais et la création de poèmes.
La RLHF est un processus difficile qui implique un processus de formation à plusieurs modèles et différentes étapes de déploiement. Essentiellement, elle peut être décomposée en trois étapes différentes.
La première étape consiste à sélectionner un LLM pré-entraîné qui sera ensuite affiné à l'aide de RLHF.
Vous pouvez également former votre LLM en partant de zéro, mais il s'agit d'un processus coûteux et fastidieux. C'est pourquoi nous vous recommandons vivement de choisir l'un des nombreux LLM pré-entraînés disponibles pour le public.
Si vous souhaitez en savoir plus sur la manière de former un LLM, notre tutoriel Comment former un LLM avec PyTorch fournit un exemple illustratif.
Notez que, pour répondre aux besoins spécifiques de votre modèle, avant d'entamer la phase d'affinage à l'aide du retour d'information humain, vous pourriez affiner votre modèle sur des textes ou des conditions supplémentaires.
Par exemple, si vous souhaitez développer un assistant juridique IA, vous pourriez affiner votre modèle avec un corpus de textes juridiques afin de rendre votre LLM particulièrement familier avec la formulation et les concepts juridiques.
Au lieu d'utiliser un modèle de récompense statistiquement prédéfini (qui serait très restrictif pour calibrer les préférences humaines), RLHF utilise le feedback humain pour aider le modèle à développer un modèle de récompense plus subtil. Le processus se déroule comme suit :
L'image suivante illustre l'ensemble du processus :
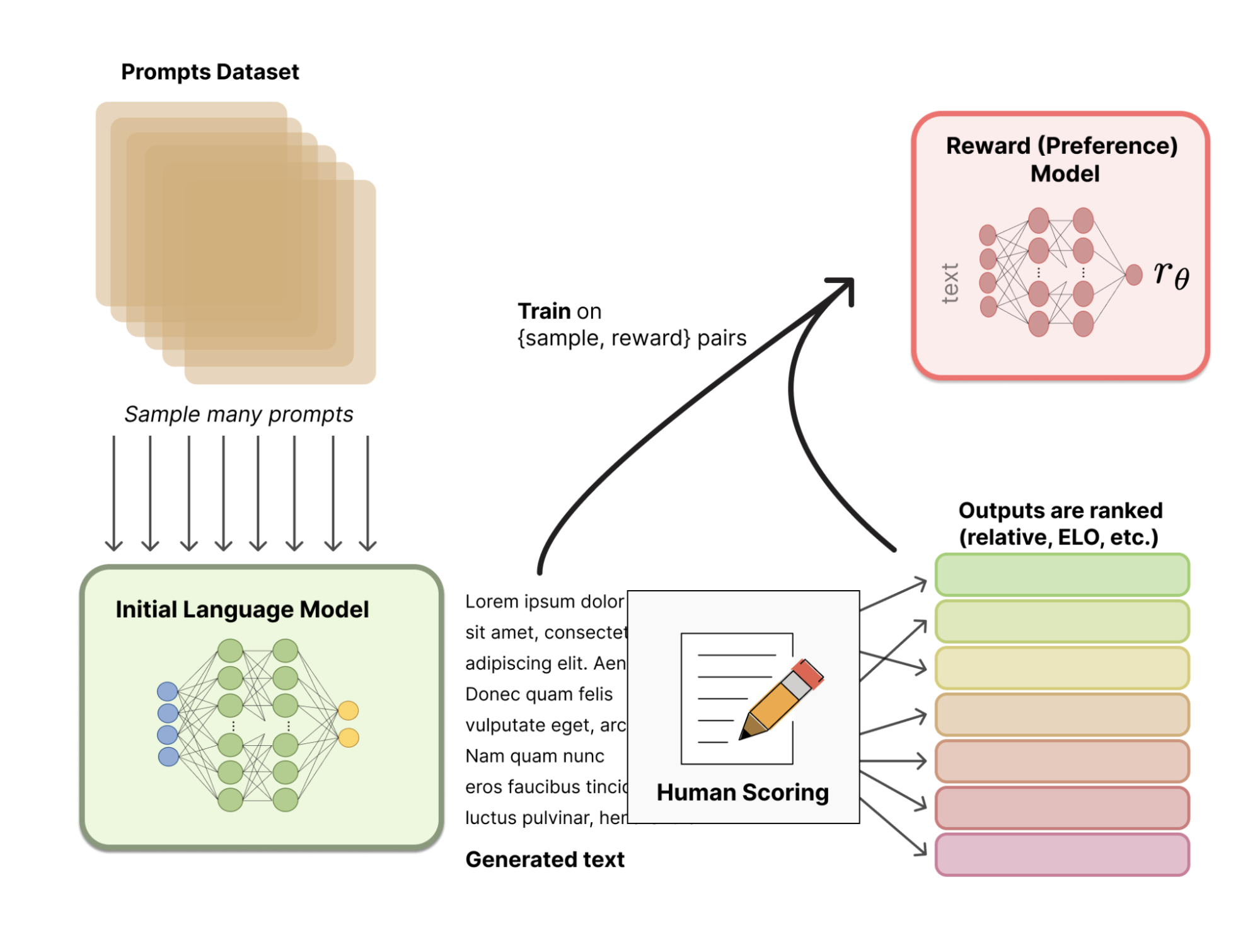
Source : Hugging Face
Dans la dernière étape, le LLM produit de nouveaux textes et utilise son modèle de récompense basé sur le feedback humain pour produire un score de qualité. Le score est ensuite utilisé par le modèle pour améliorer ses performances sur les invites suivantes.
Le retour d'information humain et le réglage fin à l'aide de techniques d'apprentissage par renforcement sont donc combinés dans un processus itératif qui se poursuit jusqu'à ce qu'un certain degré de précision soit atteint.
RLHF est une technique de pointe pour affiner les LLM, tels que ChatGPT. Cependant, la RLHF est un sujet populaire, avec une littérature croissante explorant d'autres possibilités au-delà des problèmes de NLP. Vous trouverez ci-dessous une liste d'autres domaines où la RLHF a été appliquée avec succès :
La RLHF est une technique puissante et prometteuse sans laquelle les outils d'IA de la prochaine génération ne seraient pas possibles. Voici quelques-uns des avantages de la RLHF :
Cependant, la RLHF n'est pas à l'épreuve des balles. Cette technique présente également certains risques et certaines limites. Vous trouverez ci-dessous quelques-unes des plus pertinentes :
La RLHF est l'un des piliers des outils modernes d'IA générative, tels que ChatGPT et GPT-4. Malgré ses résultats impressionnants, la RLHF est une technique relativement nouvelle et il existe encore une grande marge d'amélioration. La recherche future sur les techniques RLHF est essentielle pour rendre les MFR plus efficaces, réduire leur empreinte environnementale et traiter certains des risques et des limites des MFR.
Pour vous tenir au courant des derniers développements en matière d'IA générative, d'apprentissage automatique et de LLM, nous vous recommandons vivement de consulter nos supports d'apprentissage :
Apprenez les sujets mentionnés dans cet article !
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min