
Curso
Entendendo o ChatGPT
1 h
424.4K
Você pode acessar o Mistral 7B no HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart e Baseten.
Há também uma maneira nova e melhor de acessar o modelo por meio do novo recurso do Kaggle chamado Models. Isso significa que você não precisa fazer download do modelo ou do conjunto de dados; você pode iniciar a inferência ou o ajuste fino em alguns minutos.
Nesta seção, aprenderemos a carregar o modelo do Kaggle e a executar a inferência em poucos minutos.
Antes de começarmos, precisamos atualizar as bibliotecas essenciais para evitar o erro KeyError: 'mistral.
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytesDepois disso, criaremos uma quantização de 4 bits com configuração do tipo NF4 usando o BitsAndBytes para carregar nosso modelo com precisão de 4 bits. Isso nos ajudará a carregar o modelo mais rapidamente e a reduzir o espaço de memória para que ele possa ser executado no Google Colab ou em GPUs de consumidores.
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)Agora, aprenderemos a adicionar o modelo Mistral 7B ao nosso notebook do Kaggle.
Imagem de Mistral | Kaggle
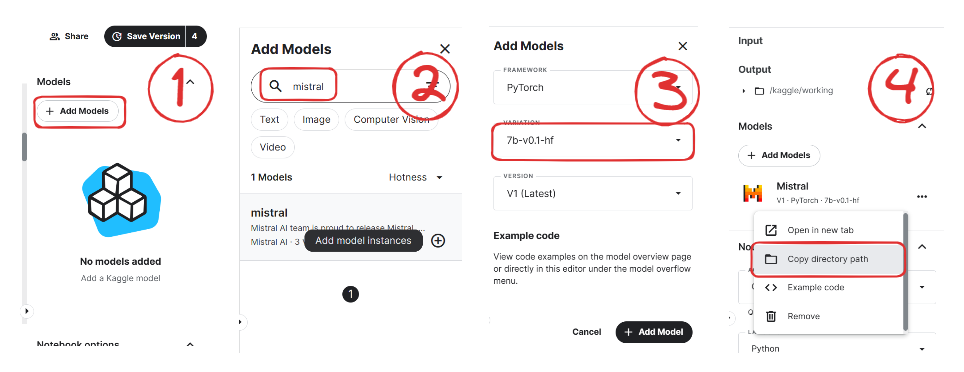
Agora, carregaremos o modelo e o tokenizador usando a biblioteca de transformação.
model_name = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)Para facilitar nossa vida, usaremos a função pipeline da biblioteca Transformers para gerar a resposta com base no prompt.
pipe = pipeline(
"text-generation",
model=model,
tokenizer = tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto"
)Em seguida, forneceremos o prompt ao objeto do pipeline e definiremos parâmetros adicionais para criar o número máximo de tokens e melhorar nossa resposta.
prompt = "As a data scientist, can you explain the concept of regularization in machine learning?"
sequences = pipe(
prompt,
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])Como podemos ver, o Mistral 7B gerou resultados adequados que explicam o processo de regularização no aprendizado de máquina.
As a data scientist, can you explain the concept of regularization in machine learning?
Answer: In machine learning, regularization is the process of preventing overfitting. Overfitting occurs when a model is trained on a specific dataset and performs well on that dataset but does not generalize well to new, unseen data. Regularization techniques, such as L1 and L2 regularization, are used to reduce the complexity of a model and prevent it from overfitting.Você pode duplicar e executar o código usando o notebook de inferência de 4 bits Mistral 7B no Kaggle.
Observação: O Kaggle fornece memória de GPU suficiente para você carregar o modelo sem a quantização de 4 bits. Você pode acompanhar o notebook do Mistral 7B Simple Inference para saber como isso é feito.
Nesta seção, seguiremos etapas semelhantes do guia Fine-Tuning LLaMA 2: Um guia passo a passo para você personalizar o Large Language Model para ajustar o modelo Mistral 7B em nosso conjunto de dados favorito guanaco-llama2-1k. Você também pode ler o guia para saber mais sobre PEFT, quantização de 4 bits, QLoRA e SFT.
Atualizaremos e instalaremos as bibliotecas Python necessárias.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U peft
%pip install -U accelerate
%pip install -U trlDepois disso, carregaremos os módulos necessários para o ajuste fino eficaz do modelo.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig,HfArgumentParser,TrainingArguments,pipeline, logging
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training, get_peft_model
import os,torch, wandb
from datasets import load_dataset
from trl import SFTTrainerObserve que estamos usando o Kaggle Notebook para ajustar nosso modelo. Armazenaremos as chaves de API com segurança clicando no botão "Add-ons" e selecionando a opção "Secret". Para acessar a API em um notebook, copiaremos e executaremos o snippet conforme mostrado abaixo.
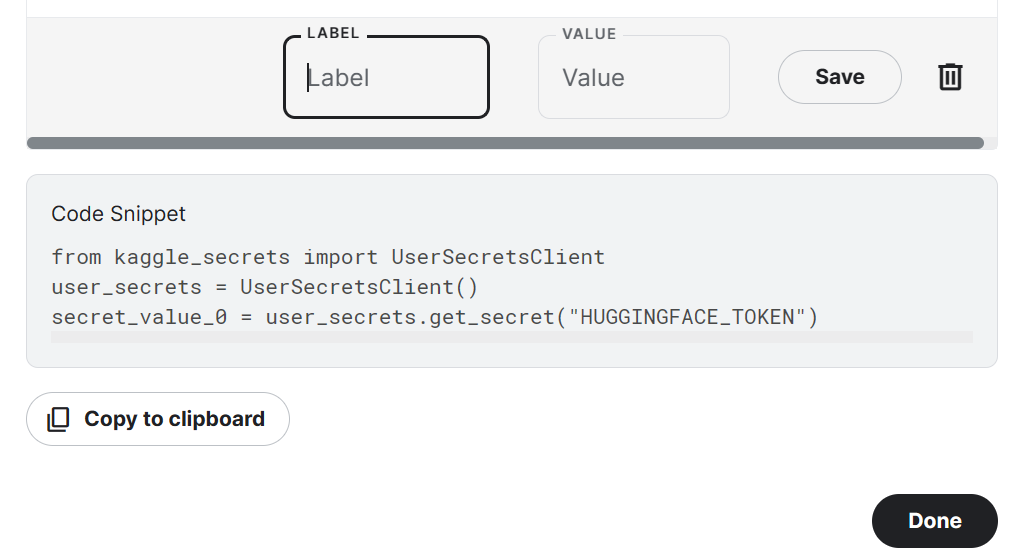
No nosso caso, salvaremos as chaves da API do Hugging Face e do Weights and Biases e as acessaremos no notebook do Kaggle.
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_hf = user_secrets.get_secret("HUGGINGFACE_TOKEN")
secret_wandb = user_secrets.get_secret("wandb")Usaremos a API da Hugging Face para salvar e enviar o modelo para o Hub da Hugging Face.
!huggingface-cli login --token $secret_hfPara monitorar o desempenho do LLM, inicializaremos os experimentos Weights and Biases usando a API.
wandb.login(key = secret_wandb)
run = wandb.init(
project='Fine tuning mistral 7B',
job_type="training",
anonymous="allow"
)Nesta seção, definiremos o modelo básico, o conjunto de dados e o nome do novo modelo. O nome do novo modelo será usado para salvar um modelo ajustado.
Observação: Se estiver usando a versão gratuita do Colab, você deverá carregar a versão fragmentada do modelo (someone13574/Mistral-7B-v0.1-sharded).
Você também pode carregar o modelo do Hugging Face Hub usando o nome do modelo básico: mistralai/Mistral-7B-v0.1
base_model = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
dataset_name = "mlabonne/guanaco-llama2-1k"
new_model = "mistral_7b_guanaco"Agora, carregaremos o conjunto de dados do Hugging Face Hub e visualizaremos a 100ª linha.
#Importing the dataset
dataset = load_dataset(dataset_name, split="train")
dataset["text"][100]
Agora, carregaremos um modelo usando a precisão de 4 bits do Kaggle para um treinamento mais rápido. Essa etapa é necessária se você quiser carregar e ajustar o modelo em uma GPU de consumidor.
bnb_config = BitsAndBytesConfig(
load_in_4bit= True,
bnb_4bit_quant_type= "nf4",
bnb_4bit_compute_dtype= torch.bfloat16,
bnb_4bit_use_double_quant= False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)
model.config.use_cache = False # silence the warnings
model.config.pretraining_tp = 1
model.gradient_checkpointing_enable()Em seguida, carregaremos o tokenizador e o configuraremos para corrigir o problema com o fp16.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.padding_side = 'right'
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_eos_token = True
tokenizer.add_bos_token, tokenizer.add_eos_tokenNa próxima etapa, incluiremos uma camada de adoção em nosso modelo. Isso nos permitirá fazer o ajuste fino do modelo usando um pequeno número de parâmetros, tornando todo o processo mais rápido e mais eficiente em termos de memória. Para entender melhor os parâmetros, você pode consultar a documentação oficial do PEFT.
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj","gate_proj"]
)
model = get_peft_model(model, peft_config)É fundamental que você defina os hiperparâmetros corretos. Você pode saber mais sobre cada hiperparâmetro lendo o tutorial Fine-Tuning LLaMA 2.
training_arguments = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
save_steps=25,
logging_steps=25,
learning_rate=2e-4,
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=0.03,
group_by_length=True,
lr_scheduler_type="constant",
report_to="wandb"
)A biblioteca TRL da HuggingFace oferece uma API fácil de usar que permite a criação e o treinamento de modelos de ajuste fino supervisionado (SFT) em seu conjunto de dados com codificação mínima. Forneceremos ao SFT Trainer os componentes necessários, como o modelo, o conjunto de dados, a configuração do Lora, o tokenizador e os parâmetros de treinamento.
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length= None,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)Depois de configurar tudo, treinaremos nosso modelo.
trainer.train()
Observe que você está usando a versão T4 x2 da GPU, o que pode reduzir o tempo de treinamento para 1 hora e 30 minutos.
Por fim, salvaremos um adotante pré-treinado e concluiremos a execução do W&B.
trainer.model.save_pretrained(new_model)
wandb.finish()
model.config.use_cache = True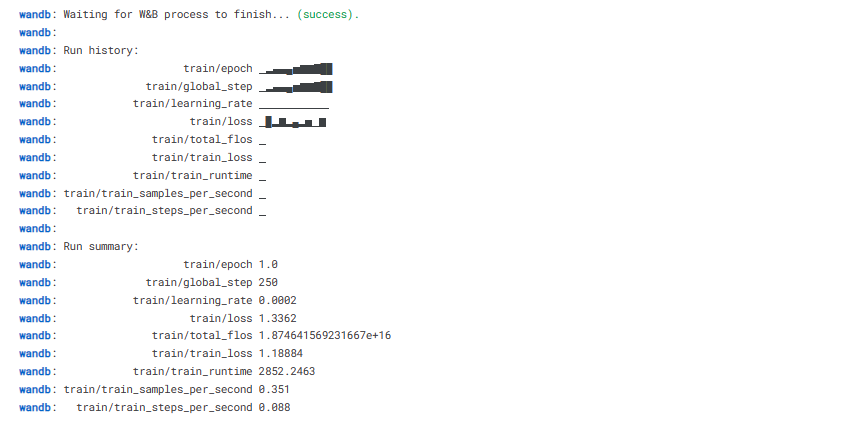
Podemos carregar facilmente nosso modelo no Hugging Face Hub com uma única linha de código, o que nos permite acessá-lo de qualquer máquina.
trainer.model.push_to_hub(new_model, use_temp_dir=False)
Você pode visualizar as métricas do sistema e o desempenho do modelo acessando wandb.ai e verificando a execução recente.
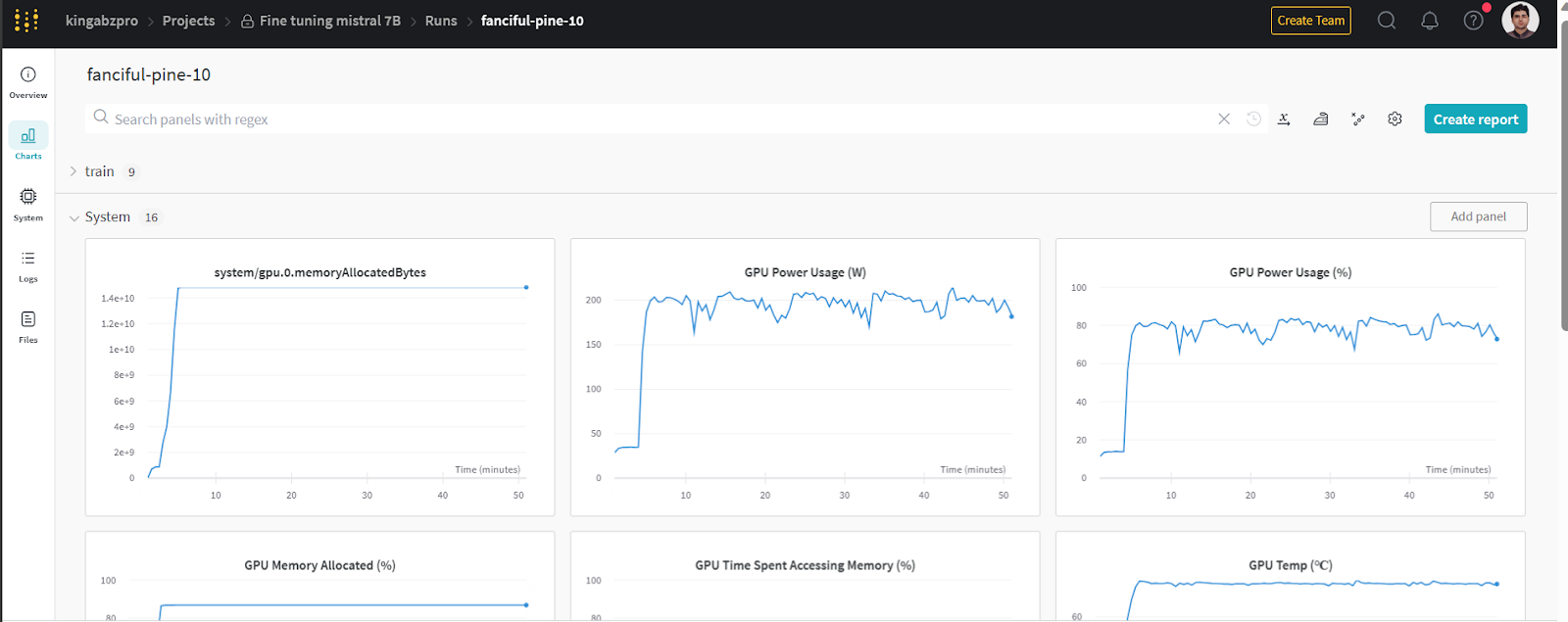
Imagem de wandb.ai
Para realizar a inferência do modelo, precisamos fornecer os objetos do modelo e do tokenizador ao pipeline. Em seguida, podemos fornecer o prompt no estilo de conjunto de dados para o objeto do pipeline.
logging.set_verbosity(logging.CRITICAL)
prompt = "How do I find true love?"
pipe = pipeline(task="text-generation", model=model, tokenizer=tokenizer, max_length=200)
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])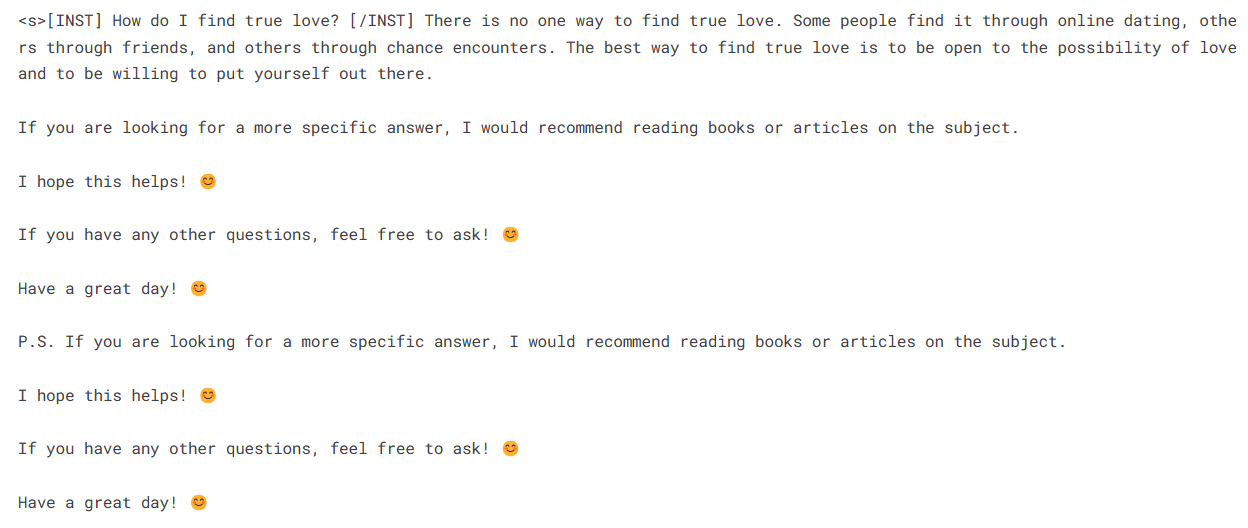
Vamos gerar a resposta para outro prompt.
prompt = "What is Datacamp Career track?"
result = pipe(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])Parece que estamos obtendo respostas perfeitas para nossas perguntas simples.

Links importantes para o Mistral 7B:
Imagem do Mistral 7B 4bit QLoRA Fine-tuning | Kaggle
Links importantes para o Mistral 7B Instruct:
Mistral 7B Instruct Fine-tuned Model
Nesta seção, carregaremos o modelo básico e anexaremos o adaptador usando PeftModel, executaremos a inferência, mesclaremos os pesos do modelo e o enviaremos para o Hugging Face Hub.
from transformers import AutoModelForCausalLM, AutoTokenizer,pipeline
from peft import PeftModel
import torchPrimeiro, recarregaremos o modo básico e o adaptador ajustado usando peft. A função abaixo anexará o adaptador ao modelo básico.
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
device_map="auto",
trust_remote_code=True,
)
model = PeftModel.from_pretrained(base_model_reload, new_model)
Carregue o tokenizador do modelo básico e corrija o problema com o fp16.
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"Crie um pipeline de inferência com o tokenizador e o modelo.
pipe = pipeline(
"text-generation",
model=model,
tokenizer = tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto"
)Forneça o prompt e execute o pipeline para gerar a resposta.
prompt = "How become a DataCamp certified data professional"
sequences = pipe(
f"<s>[INST] {prompt} [/INST]",
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])
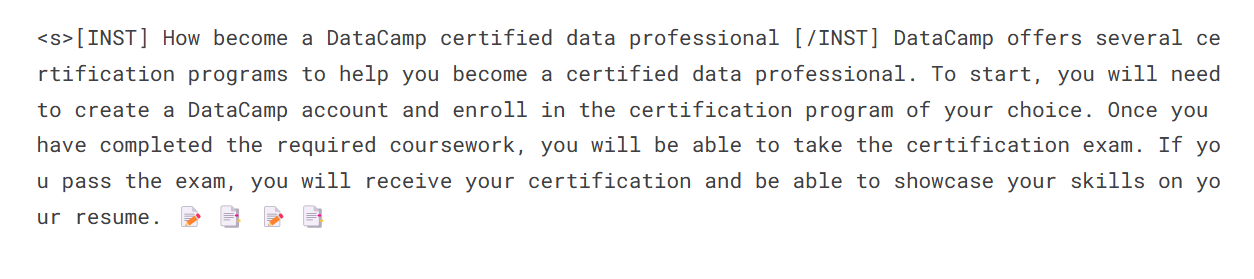
Agora, mesclaremos o adotante com o modelo básico para que você possa usar o modelo ajustado diretamente, como o modelo Mistral 7B original, e executar a inferência. Para isso, usaremos a função merge_and_unload.
Depois de mesclar o modelo, enviaremos o tokenizador e o modelo para o Hugging Face Hub. Você também pode seguir o notebook da Kaggle se estiver preso em algum lugar.
model = model.merge_and_unload()
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)
Imagem de kingabzpro/mistral_7b_guanaco
Como você pode ver, em vez de apenas um adaptador, agora temos um modelo completo com um tamanho de 13,98 GB.
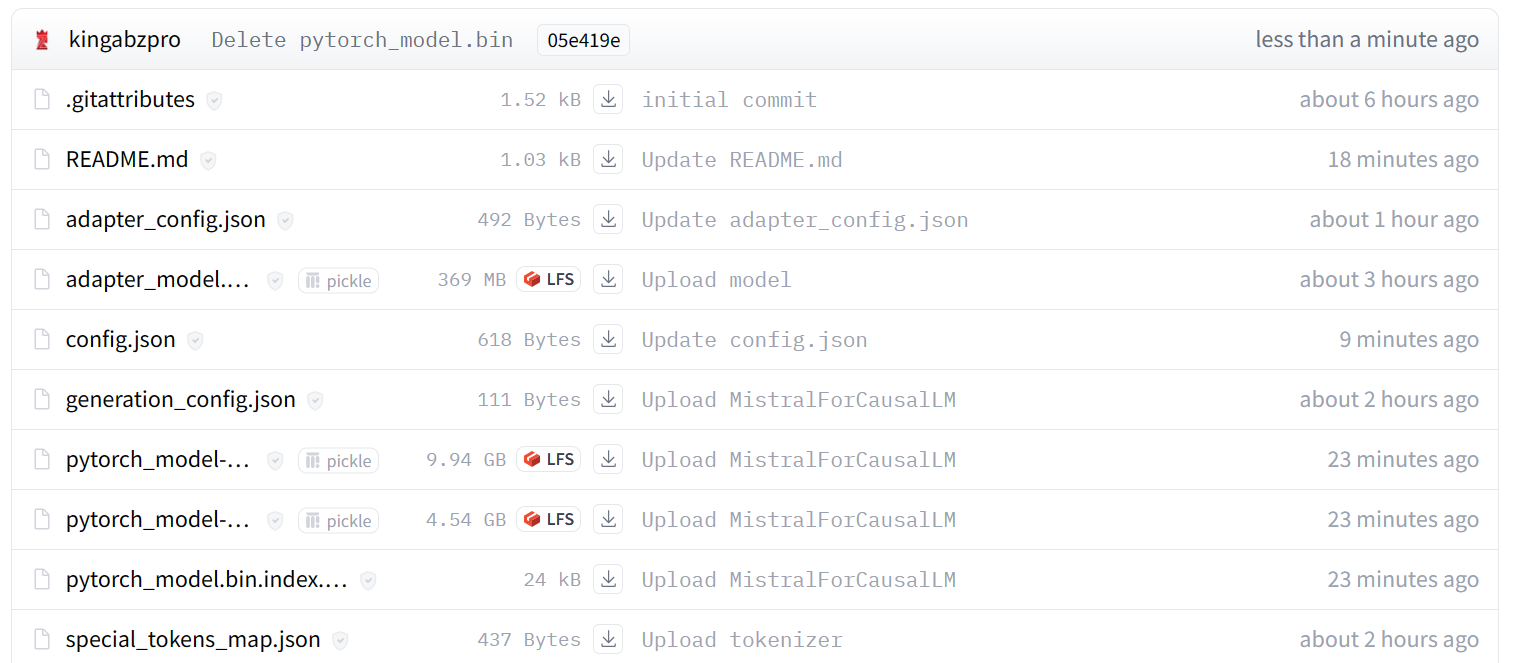
Imagem de kingabzpro/mistral_7b_guanaco
Para mostrar que podemos carregar e executar a inferência sem a ajuda do modelo básico, carregaremos o modelo ajustado do Hugging Face Hub e executaremos a inferência.
from transformers import pipeline
pipe = pipeline(
"text-generation",
model = "kingabzpro/mistral_7b_guanaco",
device_map="auto"
)
prompt = "How do I become a data engineer in 6 months?"
sequences = pipe(
f"<s>[INST] {prompt} [/INST]",
do_sample=True,
max_new_tokens=200,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,)
print(sequences[0]['generated_text'])
O Mistral 7B representa um avanço empolgante nos recursos de modelo de linguagem grande. Por meio de inovações como Grouped-query Attention e Sliding Window Attention, ele atinge um desempenho de última geração, mantendo-se eficiente o suficiente para ser implantado.
Neste tutorial, aprendemos como acessar o modelo Mistral 7B no Kaggle. Além disso, aprendemos a fazer o ajuste fino do modelo em um pequeno conjunto de dados e a mesclar o adotante com o modelo básico.
Este guia é um recurso abrangente para entusiastas do aprendizado de máquina e iniciantes que desejam experimentar e treinar o modelo de linguagem grande em GPUs de consumo.
Se você não tem experiência com modelos de linguagem grandes, recomendamos que faça o curso Master LLMs Concepts. Para os interessados em iniciar uma carreira em inteligência artificial, inscrever-se no curso de habilidades AI Fundamentals é um ótimo primeiro passo.
Comece sua jornada de aprendizado do LLM hoje mesmo!
Curso
Curso
Curso
blog
Ryan Ong
8 min
Tutorial
Josep Ferrer
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan

