Course
Machine Learning with caret in R
4 hr
60.7K
This is Part One of a three-part tutorial series in which you will use R to perform a variety of analytic tasks on a case study of musical lyrics by the legendary artist, Prince. The three tutorials cover the following:

Musical lyrics may represent an artist's perspective, but popular songs reveal what society wants to hear. Lyric analysis is no easy task. Because it is often structured so differently than prose, it requires caution with assumptions and a uniquely discriminant choice of analytic techniques. Musical lyrics permeate our lives and influence our thoughts with subtle ubiquity. The concept of Predictive Lyrics is beginning to buzz and is more prevalent as a subject of research papers and graduate theses. This case study will just touch on a few pieces of this emerging subject.
To celebrate the inspiring and diverse body of work left behind by Prince, you will explore the sometimes obvious, but often hidden, messages in his lyrics. However, you don't have to like Prince's music to appreciate the influence he had on the development of many genres globally. Rolling Stone magazine listed Prince as the 18th best songwriter of all time, just behind the likes of Bob Dylan, John Lennon, Paul Simon, Joni Mitchell and Stevie Wonder. Lyric analysis is slowly finding its way into data science communities as the possibility of predicting "Hit Songs" approaches reality.
Prince was a man bursting with music - a wildly prolific songwriter, a virtuoso on guitars, keyboards and drums and a master architect of funk, rock, R&B and pop, even as his music defied genres. - Jon Pareles (NY Times)
In this tutorial, Part One of the series, you'll utilize text mining techniques on a set of lyrics using the tidy text framework. Tidy datasets have a specific structure in which each variable is a column, each observation is a row, and each type of observational unit is a table. After cleaning and conditioning the dataset, you will create descriptive statistics and exploratory visualizations while looking at different aspects of Prince's lyrics.
Part One of this tutorial series requires a basic understanding of tidy data - specifically packages such as dplyr for data transformation, ggplot2 for visualizations, and the %>% pipe operator originally from the magrittr package. Each tutorial will describe the tools you can use for your analysis, but may not get into detail for every step. You will notice that several steps are typically combined using the %>% operator. As this is also a case study, it's important to remember that all inferences that you make are purely observational; hence, correlation does not imply causation.
Tip: for background on the tools used, two good resources are R for Data Science by Garrett Grolemund and Hadley Wickham; and Text Mining with R by Julia Silge and David Robinson.
Parts Two and Three
In a separate tutorial, Part Two, you will cover Sentiment Analysis and Topic Modeling to capture the overall mood and themes in Prince's music and their application to societal perspectives. You will work with a sentiment lexicon, assess binary and categorical sentiments, plot trends over time, and look at n-grams and word associations. You'll also use Natural Language Processing (NLP) and clustering techniques such as Latent Dirichlet Allocation (LDA) and K-Means to tease out motifs in the lyrics.
In yet another tutorial, Part Three, you will bring the work full circle by using your exploratory results to help predict what decade a song was released, and more interestingly, whether a song will hit the Billboard charts based on its lyrics. You'll use machine learning tools such as Decision Trees (rpart and C50), K-Nearest-Neighbors (class), and Naive Bayes (e1071) to produce a classifier that can accept text.
All three parts will utilize the same dataset of Prince lyrics, release year, and Billboard chart positions. The techniques in this study can be applied to many other types of text as well. In fact, results for standard prose are more easily interpreted because lyrics, in general, are often designed with an indirect message and subtle nuances.
In summary, there are many different methods for analyzing lyrics. These tutorials cover those highlighted in red in the graphic below. Note that this graphic is simply a high level representation of a very "fuzzy" picture. And no, I don't mean the image itself! The truth is that the different aspects of modeling and machine learning techniques are blurry now and don't necessarily fit into a single box as shown below. So put on some 3D glasses while looking at the image and it may make more sense!

In addition to learning and practicing new skills, this tutorial aims to address basic questions about the concept of lyric analysis. Recent studies show that "lyrical intelligence" could be declining in popular music. Some studies even suggest that words used in No.1 Hit Songs align with reading levels of US 3rd grade schoolchildren. Is it possible to utilize text mining, NLP, machine learning and other data science methods to shed insight on such a topic? Is it possible to identify themes that appeal to society based on how well a song is received? Is it possible to predict whether a song will do well based on lyrical analysis alone? In this first tutorial, you will examine the lyrical complexity of Prince's music as an exploratory exercise.
Before diving in, think about what you're trying to discover. What questions are of interest? You will first walk through an analysis of the dataset. What does it look like? How many songs are there? How are the lyrics structured? How much cleaning and wrangling needs to be done? What are the facts? What are the word frequencies and why is that important? From a technical perspective, you want to understand and prepare the data for sentiment analysis, NLP, and machine learning models.
Music has long been an effective way to communicate to the masses, and lyrics have played a massive role in delivering this communication. Yet the opportunity for research on the role lyrics play on the well-being [of society] is vastly underutilized. - Patricia Fox Ransom
A popular method for obtaining data for text mining is using the rvest package to scrape the content from the web. I was able to scrape Billboard Chart information and Prince lyrics from various sites and join them up on song title. There was a bit of wrangling involved because of inconsistent naming conventions for the titles. I then made a subjective decision to remove all songs that were not the original versions, that is, remixes, extended versions, club mixes, remakes, etc. I also removed albums that contained historical collections of his Hit Songs in order to avoid repetition. I did some minor cleaning and saved the result to a csv file that could be used for this tutorial.
Since Part One focuses on text mining, I have not included that code for this tutorial, but the dataset is available for you to download here if you'd like to follow along.
#most of the libraries needed library(dplyr) #data manipulation library(ggplot2) #visualizations library(gridExtra) #viewing multiple plots together library(tidytext) #text mining library(wordcloud2) #creative visualizations
There are several methods to read in data from a csv file, but I chose to use read.csv() to load a data frame with lyrics, release year, and Billboard chart positions. Note that by default, R converts all character strings into factors. This can cause problems downstream, but you can take care of that by setting the stringsAsFactors parameter to FALSE. Now to examine the data...
prince_orig <- read.csv("prince_raw_data.csv", stringsAsFactors = FALSE)
You can use the names() function to see the columns in the data frame:
names(prince_orig)
## [1] "X" "text" "artist" "song" ## [5] "year" "album" "Release.Date" "US.Pop" ## [9] "US.R.B" "CA" "UK" "IR" ## [13] "NL" "DE" "AT" "FR" ## [17] "JP" "AU" "NZ" "peak"
Because I created this file, I know that X is just a row number and text is the actual lyrics. The other needed fields include song, year, and peak (which shows its placement on the Billboard charts). US.Pop and US.R.B are peak chart positions for the US (Pop and R&B charts), so keep those around as well, and drop all the other fields for now.
Do this by taking the original dataset, prince_orig, and piping that into select() using %>%. This way you can read code from left to right.
Also, notice that select() allows you to rename the columns all in one step. So go ahead and set text to lyrics and rename the US columns to the tidyverse style using "_" instead of ".". Then store the results in prince, which you will use throughout the tutorials. dplyr provides a function called glimpse() that makes it easy to look at your data in a transposed view.
prince <- prince_orig %>%
select(lyrics = text, song, year, album, peak,
us_pop = US.Pop, us_rnb = US.R.B)
glimpse(prince[139,])
Observations: 1 Variables: 7 $ lyrics <chr> "I just can't believe all the things people say, controversy\nAm I ... $ song <chr> "controversy" $ year <int> 1981 $ album <chr> "Controversy" $ peak <int> 3 $ us_pop <chr> "70" $ us_rnb <chr> "3"
The first obvious question is how many observations and columns are there?
dim(prince)
[1] 824 7
Using the dim() function, you see that there are 7 columns and 824 observations. Each observation is a song. Like I said... prolific!
Looking at the lyrics column for one of the songs, you can see how they are structured.
str(prince[139, ]$lyrics, nchar.max = 300)
chr "I just can't believe all the things people say, controversy\nAm I Black or White? Am I straight or gay? Controversy\nDo I believe in God? Do I believe in me? Controversy\nControversy, controversy\nI can't understand human curiosity, controversy\nWas it good for you? Was I what you w"| __truncated__
There are plenty of opportunities to clean things up, so let's get started.
There are different methods you can use to condition the data. One option would be to convert the data frame to a Corpus and Document Term Matrix using the tm text mining package and then use the tm_map() function to do the cleaning, but this tutorial will stick to the basics for now and use gsub() and apply() functions to do the dirty work.
First, get rid of those pesky contractions by creating a little function that handles most scenarios using gsub(), and then apply that function across all lyrics.
# function to expand contractions in an English-language source
fix.contractions <- function(doc) {
# "won't" is a special case as it does not expand to "wo not"
doc <- gsub("won't", "will not", doc)
doc <- gsub("can't", "can not", doc)
doc <- gsub("n't", " not", doc)
doc <- gsub("'ll", " will", doc)
doc <- gsub("'re", " are", doc)
doc <- gsub("'ve", " have", doc)
doc <- gsub("'m", " am", doc)
doc <- gsub("'d", " would", doc)
# 's could be 'is' or could be possessive: it has no expansion
doc <- gsub("'s", "", doc)
return(doc)
}
# fix (expand) contractions
prince$lyrics <- sapply(prince$lyrics, fix.contractions)
You'll also notice special characters that muddy the text. You can remove those with the gsub() function and a simple regular expression. Notice it's critical to expand contractions before doing this step!
# function to remove special characters
removeSpecialChars <- function(x) gsub("[^a-zA-Z0-9 ]", " ", x)
# remove special characters
prince$lyrics <- sapply(prince$lyrics, removeSpecialChars)
To be consistent, go ahead and convert everything to lowercase with the handy tolower() function.
# convert everything to lower case prince$lyrics <- sapply(prince$lyrics, tolower)
Examining the lyrics now shows a nice, cleaner version of the original, raw text.
str(prince[139, ]$lyrics, nchar.max = 300)
chr "i just can not believe all the things people say controversy am i black or white
Another common step in conditioning data for text mining is called stemming, or breaking down words to their root meaning. That's a topic in itself which can be covered at a later time. For now, take a look at the summary of the prince data frame.
#get facts about the full dataset summary(prince)
lyrics song year album
Length:824 Length:824 Min. :1978 Length:824
Class :character Class :character 1st Qu.:1989 Class :character
Mode :character Mode :character Median :1996 Mode :character
Mean :1995
3rd Qu.:1999
Max. :2015
NA's :495
peak us_pop us_rnb
Min. : 0.00 Length:824 Length:824
1st Qu.: 2.00 Class :character Class :character
Median : 7.00 Mode :character Mode :character
Mean :15.48
3rd Qu.:19.00
Max. :88.00
NA's :751
As you can see, there are 37 years of songs, and the lowest charted song (that exists in the dataset) is at position 88. You can also see that there are quite a few NAs for year and peak. Since you'll be doing different types of analyses, keep the full dataset around in the prince data frame and just filter when needed.
Since one of your target questions is to look for song trends across time, and the dataset contains individual release years, you can create buckets and group the years into decades. Use dplyr's mutate() verb to create the new decade field. One way to create the buckets is by utilizing ifelse() along with the %in% operator to filter by year and bin the songs into decades. Then store the results back into prince (essentially adding a new field).
#create the decade column
prince <- prince %>%
mutate(decade =
ifelse(prince$year %in% 1978:1979, "1970s",
ifelse(prince$year %in% 1980:1989, "1980s",
ifelse(prince$year %in% 1990:1999, "1990s",
ifelse(prince$year %in% 2000:2009, "2000s",
ifelse(prince$year %in% 2010:2015, "2010s",
"NA"))))))
You can do the same thing for chart_level, which represents whether a song peaked in the Top 10, Top 100, or did not chart (that is, uncharted). These are mutually exclusive, so Top 100 does not include Top 10 songs.
#create the chart level column
prince <- prince %>%
mutate(chart_level =
ifelse(prince$peak %in% 1:10, "Top 10",
ifelse(prince$peak %in% 11:100, "Top 100", "Uncharted")))
In addition, create a binary field called charted indicating whether a song reached the Billboard charts or not (that is, a popular song). Use write.csv() to save for use in later tutorials.
#create binary field called charted showing if a song hit the charts at all
prince <- prince %>%
mutate(charted =
ifelse(prince$peak %in% 1:100, "Charted", "Uncharted"))
#save the new dataset to .csv for use in later tutorials
write.csv(prince, file = "prince_new.csv")
In order to customize graphs, I like to create a unique list of colors to keep the visuals consistent. There are plenty of places on the web to get distinct colors via their hexadecimal code representation as below. If you have a preference for your graphs, you can also create your own theme you can apply to ggplot() when needed.
#define some colors to use throughout
my_colors <- c("#E69F00", "#56B4E9", "#009E73", "#CC79A7", "#D55E00")
theme_lyrics <- function()
{
theme(plot.title = element_text(hjust = 0.5),
axis.text.x = element_blank(),
axis.ticks = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
legend.position = "none")
}
Before getting into text mining, start with a basic view of what your data holds at the song level. Now would be a good time to get a visual of how many songs Prince released per decade. As a reminder, his professional career started in 1978 and went all the way through 2015 (as shown in the summary() statistics above). But since we're looking at trends now, and the dataset has a large number of blank values for year, you'll want to filter out all the release year NAs for the first graph.
Using dplyr's filter(),group_by() and summarise() functions, you can group by decade and then count the number of songs. The function n() is one of several aggregate functions that is useful to employ with summarise() on grouped data. Then using ggplot() and geom_bar(), create a bar chart and fill the bars with the charted category.
prince %>%
filter(decade != "NA") %>%
group_by(decade, charted) %>%
summarise(number_of_songs = n()) %>%
ggplot() +
geom_bar(aes(x = decade, y = number_of_songs,
fill = charted), stat = "identity") +
theme(plot.title = element_text(hjust = 0.5),
legend.title = element_blank(),
panel.grid.minor = element_blank()) +
ggtitle("Released Songs") +
labs(x = NULL, y = "Song Count")
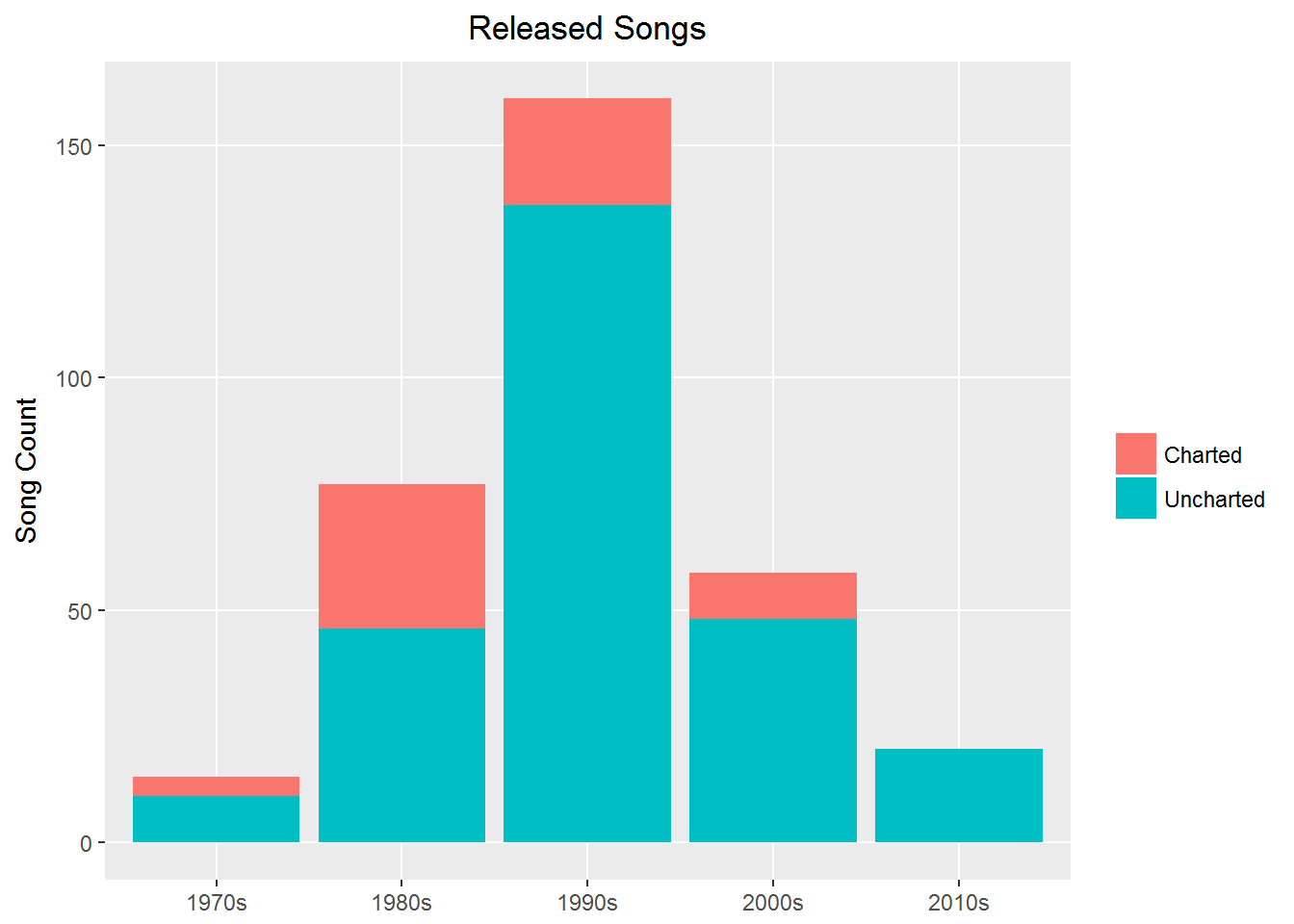
This clearly shows his most active decade was the 1990s.
Now create a similar graph with chart_level.
Remember to group_by() both decade and chart_level so you can see the trend.
In this graph, you'll only look at charted songs so filter out everything else using peak > 0. Pipe the group_by object into summarise() using n() to count the number of songs. As you store this in a variable, you can pipe that to ggplot() for a simple bar chart.
charted_songs_over_time <- prince %>%
filter(peak > 0) %>%
group_by(decade, chart_level) %>%
summarise(number_of_songs = n())
charted_songs_over_time %>%
ggplot() +
geom_bar(aes(x = decade, y = number_of_songs,
fill = chart_level), stat = "identity") +
theme(plot.title = element_text(hjust = 0.5),
legend.title = element_blank(),
panel.grid.minor = element_blank()) +
labs(x = NULL, y = "Song Count") +
ggtitle("Charted Songs")
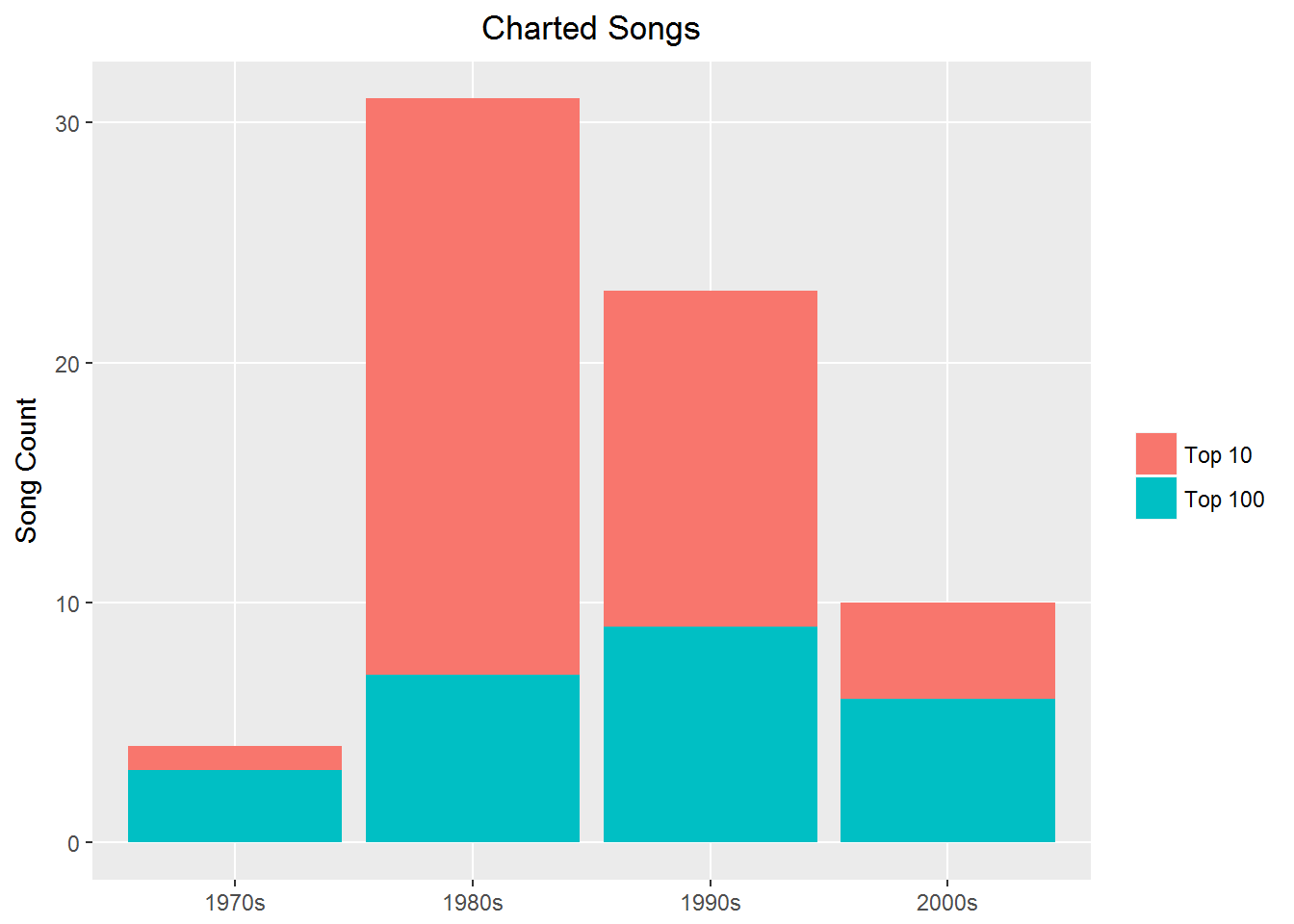
Notice that out of all Prince's charted songs, the majority reached Top 10. But what is even more interesting is that his most prolific decade for new songs was the 1990s, yet more chart hits occurred in the 1980s. Why is this the case? Keep this question in mind as you walk through the sections on text mining.
In order to use the power of the full dataset for lyrical analysis, you can remove references to chart level and release year and have a much larger set of songs to mine. Take a look:
#look at the full data set at your disposal
prince %>%
group_by(decade, chart_level) %>%
summarise(number_of_songs = n()) %>%
ggplot() +
geom_bar(aes(x = decade, y = number_of_songs,
fill = chart_level), stat = "identity") +
theme(plot.title = element_text(hjust = 0.5),
legend.title = element_blank(),
panel.grid.minor = element_blank()) +
labs(x = NULL, y = "Song Count") +
ggtitle("All Songs in Data")
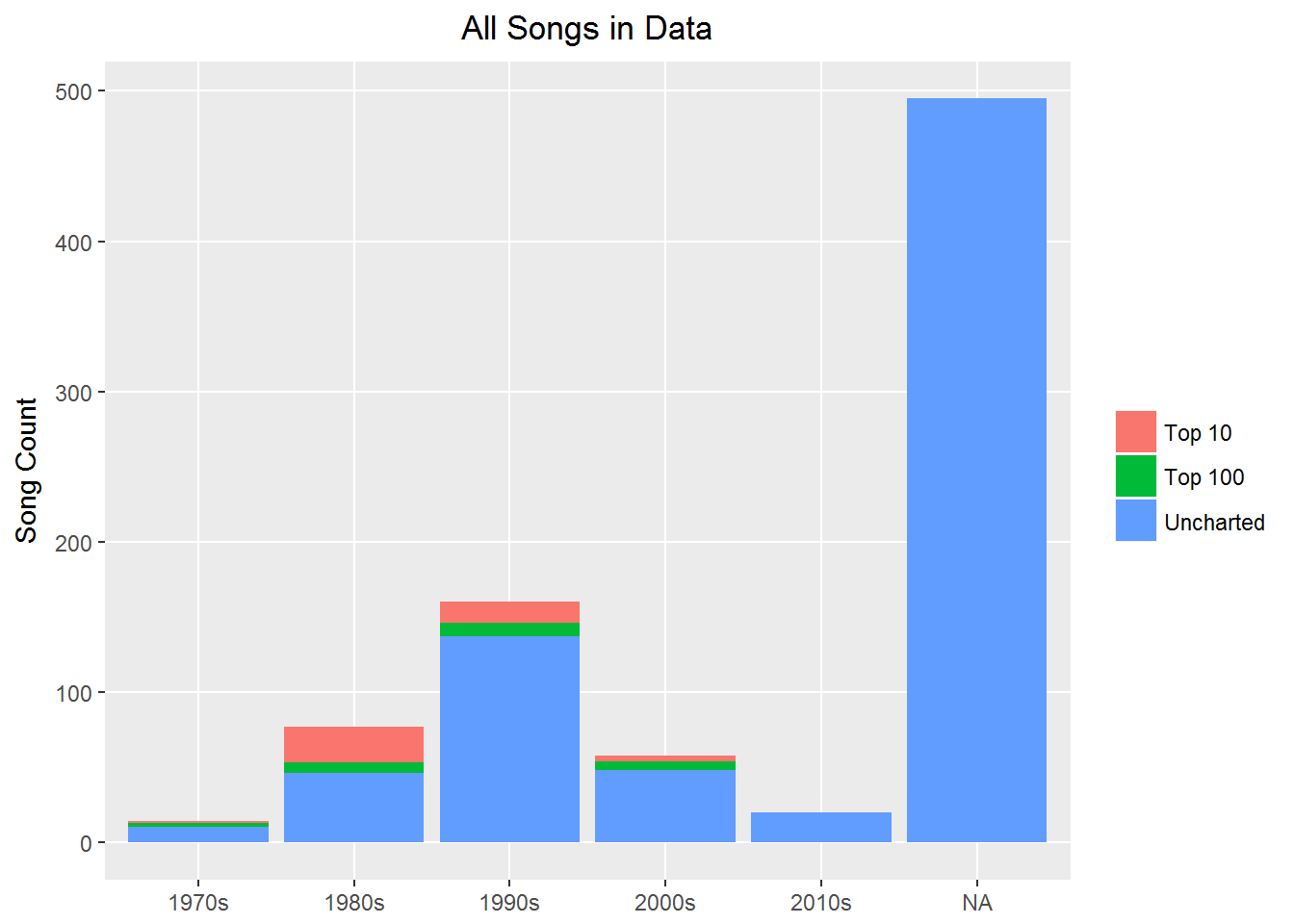
As you can see, Prince wrote hundreds of songs for which there is no release date in the data. For sentiment analysis or exploratory analysis you can use all the data, but for trends over time you have a much smaller set to work with. This is OK - just something to keep in mind.
For those avid Prince fans, below is a quick peek of the songs that hit No. 1 on the charts. (Notice you can use kable() and kable_styling() from the knitr and kableExtra packages and color_tile() from formattable to create nicely formatted HTML output.)
library(knitr) # for dynamic reporting
library(kableExtra) # create a nicely formated HTML table
library(formattable) # for the color_tile function
prince %>%
filter(peak == "1") %>%
select(year, song, peak) %>%
arrange(year) %>%
mutate(year = color_tile("lightblue", "lightgreen")(year)) %>%
mutate(peak = color_tile("lightgreen", "lightgreen")(peak)) %>%
kable("html", escape = FALSE, align = "c", caption = "Prince's No. 1 Songs") %>%
kable_styling(bootstrap_options =
c("striped", "condensed", "bordered"),
full_width = FALSE)
| year | song | peak |
|---|---|---|
| 1979 | i wanna be your lover | 1 |
| 1984 | erotic city | 1 |
| 1984 | purple rain | 1 |
| 1984 | when doves cry | 1 |
| 1985 | around the world in a day | 1 |
| 1986 | kiss | 1 |
| 1988 | lovesexy | 1 |
| 1989 | batdance | 1 |
| 1990 | thieves in the temple | 1 |
| 1991 | diamonds and pearls | 1 |
| 1995 | the most beautiful girl in the world | 1 |
| 2006 | 3121 | 1 |
| 2007 | planet earth | 1 |
Text mining can also be thought of as text analytics. The goal is to discover relevant information that is possibly unknown or buried beneath the obvious. Natural Language Processing (NLP) is one methodology used in mining text. It tries to decipher the ambiguities in written language by tokenization, clustering, extracting entity and word relationships, and using algorithms to identify themes and quantify subjective information. You'll begin by breaking down the concept of lexical complexity.
Lexical complexity can mean different things in different contexts, but for now, assume that it can be described by a combination of these measures:
To begin the analysis, you need to break out the lyrics into individual words and begin mining for insights. This process is called tokenization.
Remember that there are different methods and data formats that can be used to mine text:
But before you tokenize anything, there is one more step in cleaning the data. Many lyrics, when transcribed, include phrases like "Repeat Chorus", or labels such as "Bridge" and "Verse". There are also a lot of other undesirable words that can muddy the results. Having done some prior analysis, I picked a few that I'd like to get out of the way.
Below is a list of superfluous words that need to be removed manually:
undesirable_words <- c("prince", "chorus", "repeat", "lyrics",
"theres", "bridge", "fe0f", "yeah", "baby",
"alright", "wanna", "gonna", "chorus", "verse",
"whoa", "gotta", "make", "miscellaneous", "2",
"4", "ooh", "uurh", "pheromone", "poompoom", "3121",
"matic", " ai ", " ca ", " la ", "hey", " na ",
" da ", " uh ", " tin ", " ll", "transcription",
"repeats")
To unnest the tokens, use the tidytext library, which has already been loaded. Now you can take advantage of dplyr's capabilities and join several steps together.
From the tidy text framework, you need to both break the text into individual tokens (tokenization) and transform it to a tidy data structure. To do this, use tidytext's unnest_tokens() function. unnest_tokens() requires at least two arguments: the output column name that will be created as the text is unnested into it ("word", in this case), and the input column that holds the current text (i.e. lyrics).
You can take the prince dataset and pipe it into unnest_tokens() and then remove stop words. What are stop words? You know them all too well. They are overly common words that may not add any meaning to our results. There are different lists to choose from, but here you'll use the lexicon called stop_words from the tidytext package.
Use sample() to show a random list of these stop words and head() to limit to 15 words.
head(sample(stop_words$word, 15), 15)
[1] "where" "sensible" "except" "wouldn't" "normally" "relatively" [7] "has" "said" "yet" "how" "this" "available" [13] "therein" "different" "followed"
So, after you tokenize the lyrics into words, you can then use dplyr's anti_join() to remove stop words. Next, get rid of the undesirable words that were defined earlier using dplyr's filter() verb with the %in% operator. Then use distinct() to get rid of any duplicate records as well. Lastly, you can remove all words with fewer than four characters. This is another subjective decision, but in lyrics, these are often interjections such as "yea and hey". Then store the results into prince_words_filtered.
Note: for future reference, prince_words_filtered is the tidy text version of the prince data frame without 1) stop words, 2) undesirable words, and 3) 1-3 character words. You will use this in some, but not all analyses.
#unnest and remove stop, undesirable and short words prince_words_filtered <- prince %>% unnest_tokens(word, lyrics) %>% anti_join(stop_words) %>% distinct() %>% filter(!word %in% undesirable_words) %>% filter(nchar(word) > 3)
Notice that stop_words has a word column, and a new column called word was created by the unnest_tokens() function, so anti_join() automatically joins on the column word.
Now you can examine the class and dimensions of your new tidy data structure:
class(prince_words_filtered)
[1] "data.frame"
dim(prince_words_filtered)
[1] 36916 10
prince_words_filtered is a data frame with 36916 total words (not unique words) and 10 columns. Here is a snapshot: (I just picked one word and limited its appearance in 10 songs and used select() to print the interesting fields in order, using knitr for formatting again). This shows you the tokenized, unsummarized, tidy data structure.
prince_words_filtered %>%
filter(word == "race") %>%
select(word, song, year, peak, decade, chart_level, charted) %>%
arrange() %>%
top_n(10,song) %>%
mutate(song = color_tile("lightblue","lightblue")(song)) %>%
mutate(word = color_tile("lightgreen","lightgreen")(word)) %>%
kable("html", escape = FALSE, align = "c", caption = "Tokenized Format Example") %>%
kable_styling(bootstrap_options =
c("striped", "condensed", "bordered"),
full_width = FALSE)
| word | song | year | peak | decade | chart_level | charted |
|---|---|---|---|---|---|---|
| race | lovesexy | 1988 | 1 | 1980s | Top 10 | Charted |
| race | my tree | NA | NA | NA | Uncharted | Uncharted |
| race | positivity | 1988 | NA | 1980s | Uncharted | Uncharted |
| race | race | 1994 | NA | 1990s | Uncharted | Uncharted |
| race | sexuality | 1981 | 88 | 1980s | Top 100 | Charted |
| race | slow love | 1987 | NA | 1980s | Uncharted | Uncharted |
| race | the rest of my life | 1999 | NA | 1990s | Uncharted | Uncharted |
| race | the undertaker | NA | NA | NA | Uncharted | Uncharted |
| race | u make my sun shine | NA | NA | NA | Uncharted | Uncharted |
| race | welcome 2 the rat race | NA | NA | NA | Uncharted | Uncharted |
You can see that each row contains an individual word which would be repeated for each song in which it appears.
In music, individual word frequencies carry a great deal of importance, whether it be repetition or rarity. Both affect memorability of the entire song itself. One question a songwriter may want to know is if there is a correlation between word frequency and hit songs. So now you want to take the tidy format one step further and get a summarized count of words per song.
To examine this format in Prince's lyrics, create a histogram showing the distribution of word counts, grouped by song, per placement on the Billboard Charts. Unnest the prince lyrics again without filtering any words to get a true count of word frequency across songs. Again use group_by() and summarise() to get counts. Then use the dplyr verb arrange() to sort by count. First, take a look at the highest counts, then use ggplot() for the histogram.
full_word_count <- prince %>%
unnest_tokens(word, lyrics) %>%
group_by(song,chart_level) %>%
summarise(num_words = n()) %>%
arrange(desc(num_words))
full_word_count[1:10,] %>%
ungroup(num_words, song) %>%
mutate(num_words = color_bar("lightblue")(num_words)) %>%
mutate(song = color_tile("lightpink","lightpink")(song)) %>%
kable("html", escape = FALSE, align = "c", caption = "Songs With Highest Word Count") %>%
kable_styling(bootstrap_options =
c("striped", "condensed", "bordered"),
full_width = FALSE)
| song | chart_level | num_words |
|---|---|---|
| johnny | Uncharted | 1349 |
| cloreen bacon skin | Uncharted | 1263 |
| push it up | Uncharted | 1240 |
| the exodus has begun | Uncharted | 1072 |
| wild and loose | Uncharted | 1031 |
| jughead | Uncharted | 940 |
| my name is prince | Top 10 | 916 |
| acknowledge me | Uncharted | 913 |
| the walk | Uncharted | 883 |
| the purple medley | Uncharted | 874 |
full_word_count %>%
ggplot() +
geom_histogram(aes(x = num_words, fill = chart_level )) +
ylab("Song Count") +
xlab("Word Count per Song") +
ggtitle("Word Count Distribution") +
theme(plot.title = element_text(hjust = 0.5),
legend.title = element_blank(),
panel.grid.minor.y = element_blank())
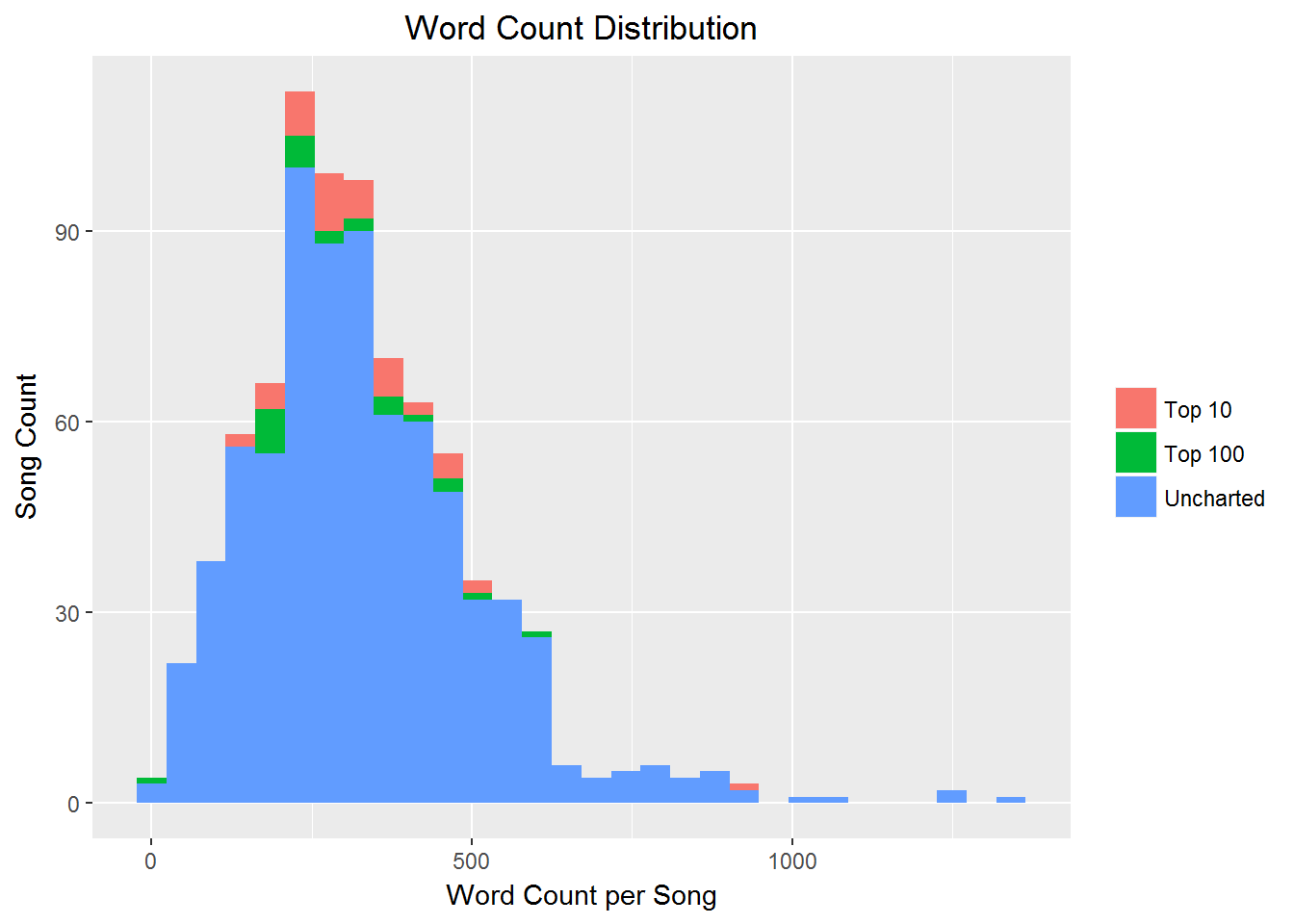
Notice it's right skewed. Given the nature of the lyric transcription, I'm skeptical about data entry errors. So, out of curiosity, take a look at that Top 10 song with over 800 words.
full_word_count %>%
filter(chart_level == 'Top 10' & num_words > 800) %>%
left_join(prince_orig, by = "song") %>%
select(Song = song,
"Word Count" = num_words,
"Peak Position" = peak,
"US Pop" = US.Pop,
"US R&B" = US.R.B,
Canada = CA,
Ireland = IR) %>%
kable("html", escape = FALSE) %>%
kable_styling(bootstrap_options = c("striped", "condensed", "bordered"))
| Song | Word Count | Peak Position | US Pop | US R&B | Canada | Ireland |
|---|---|---|---|---|---|---|
| my name is prince | 916 | 5 | 36 | 25 | 5 | 5 |
I did a little research and discovered that this particular song has a guest artist who performs a rap section. That certainly explains it! Remember, this dataset covers Pop and R&B charts globally, so genre and geography can greatly affect your assumptions. Notice the US Pop chart ranking was much lower than other charts, peaking at 5 in Canada, for example. Just something to keep in mind.
Challenge: If you're inspired to tackle music analysis on your own, you might want to check out The Million Song Dataset which has over 50 features (e.g. tempo, loudness, danceability, etc.) for almost 50,000 artists! Adding musical features to lyrics makes for a very comprehensive analysis.
In order to do a simple evaluation of the most frequently used words in the full set of lyrics, you can use count() and top_n() to get the n top words from your clean, filtered dataset. Then use reorder() to sort words according to the count and use dplyr's mutate() verb to reassign the ordered value to word. This allows ggplot() to display it nicely.
prince_words_filtered %>%
count(word, sort = TRUE) %>%
top_n(10) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot() +
geom_col(aes(word, n), fill = my_colors[4]) +
theme(legend.position = "none",
plot.title = element_text(hjust = 0.5),
panel.grid.major = element_blank()) +
xlab("") +
ylab("Song Count") +
ggtitle("Most Frequently Used Words in Prince Lyrics") +
coord_flip()
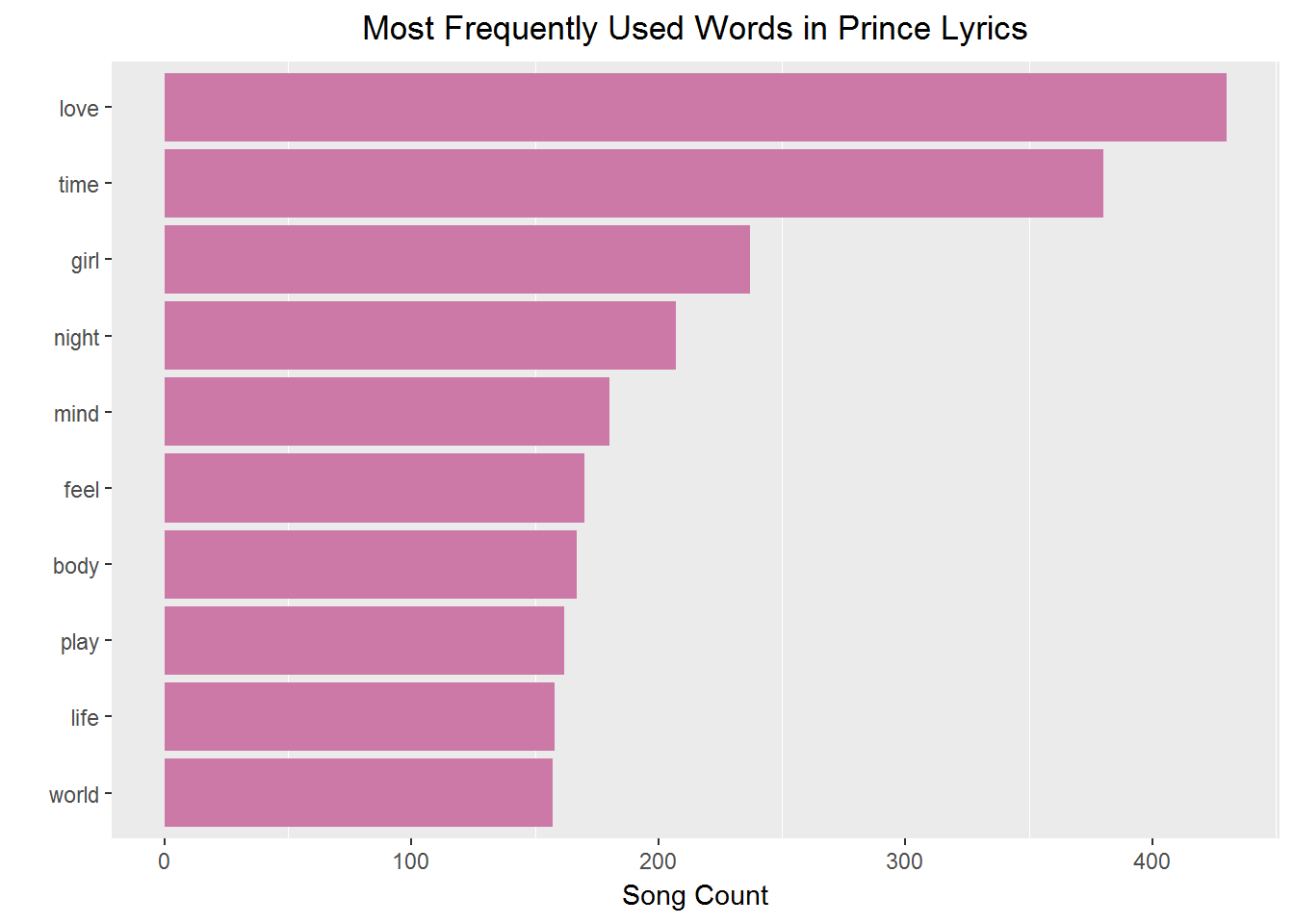
As in most popular music, love seems to be a common topic. I wouldn't make many assumptions given just these top words, but you can definitely get some insight into the artist's perspective, just not the whole picture. Before moving on to a deeper investigation, take a minute to have a little visual fun.
Word clouds get a bad rap in many circles, and if you're not careful with them, they can be used out of context where they are not appropriate. However, by nature, we are all very visual beings, and there are cases where real insight can be gained. See some examples by Sandy McKee here. Just use them with a grain of salt.
But for now, take a look at a new package called wordcloud2 for some cool stuff. This package gives you a creative collection of clouds that generate html widgets. You can actually hover over a word to see its frequency in the text. (This package can be slow to render in rMarkdown and is often picky about the browser it uses. Hopefully improvements will be made.)
prince_words_counts <- prince_words_filtered %>% count(word, sort = TRUE) wordcloud2(prince_words_counts[1:300, ], size = .5)
And for even more fun, you can add a little data art ...
wordcloud2(prince_words_counts[1:300, ], figPath = "guitar_icon.png",
color = "random-dark", size = 1.5)
letterCloud(prince_words_counts[1:300, ], word = "PRINCE", size = 2)


So far you've just viewed the top words across all songs. What happens if you break them up by chart level? Are some words more prevalent in songs that reached the charts verses uncharted songs? These are considered popular words by society.
Notice in the code below the use of slice(seq_len(n)) to grab the first n words in each chart_level. This works differently than top_n() and turns out to be a good choice when using faceting in your plot. (Always remember there are different ways to do tricks like this.) You can also use the row_number() function to make sure you can list the words in the right order on the graph. ggplot() by default would sort words alphabetically and it's good practice to do your sorting prior to graphing.
popular_words <- prince_words_filtered %>%
group_by(chart_level) %>%
count(word, chart_level, sort = TRUE) %>%
slice(seq_len(8)) %>%
ungroup() %>%
arrange(chart_level,n) %>%
mutate(row = row_number())
popular_words %>%
ggplot(aes(row, n, fill = chart_level)) +
geom_col(show.legend = NULL) +
labs(x = NULL, y = "Song Count") +
ggtitle("Popular Words by Chart Level") +
theme_lyrics() +
facet_wrap(~chart_level, scales = "free") +
scale_x_continuous( # This handles replacement of row
breaks = popular_words$row, # notice need to reuse data frame
labels = popular_words$word) +
coord_flip()
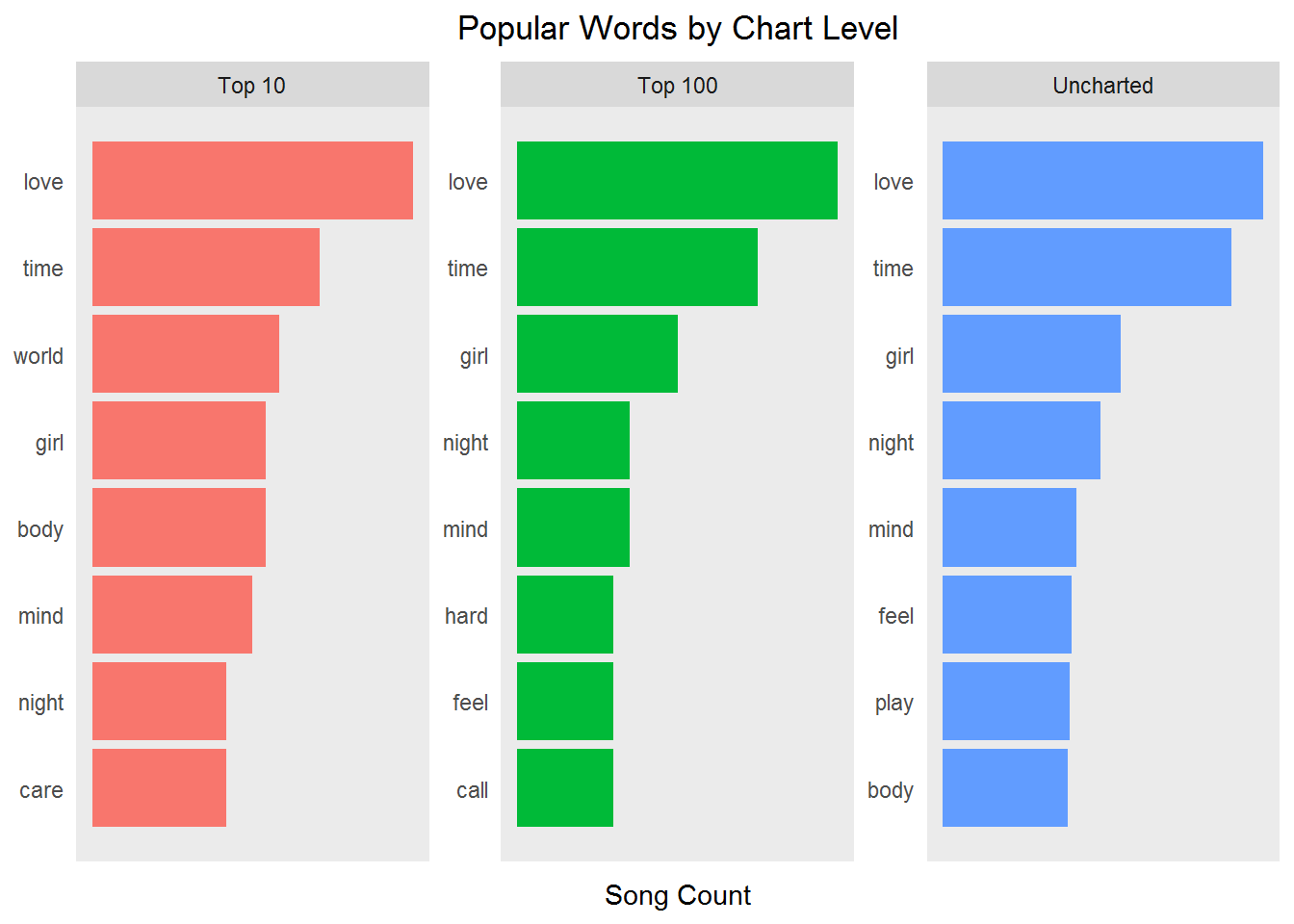
What are the insights that you now gather from the above?
Well, the top words across the chart levels are very, very similar. This doesn't look good for our hopes of predicting whether a song will succeed based on lyrics! But you've only touched the surface of what is possible with text mining, and eventually NLP and predictive modeling.
Some words in music are considered to be timeless. Timeless words persevere over time, appealing to a large audience. If you break down your analysis across decades, these words roll to the top. Use filtering, grouping, and aggregation to get the top words for each decade from Prince's lyrics and see what words can be considered timeless or trendy. You can use ggplot() with facet_wrap() to view by decade.
timeless_words <- prince_words_filtered %>%
filter(decade != 'NA') %>%
group_by(decade) %>%
count(word, decade, sort = TRUE) %>%
slice(seq_len(8)) %>%
ungroup() %>%
arrange(decade,n) %>%
mutate(row = row_number())
timeless_words %>%
ggplot(aes(row, n, fill = decade)) +
geom_col(show.legend = NULL) +
labs(x = NULL, y = "Song Count") +
ggtitle("Timeless Words") +
theme_lyrics() +
facet_wrap(~decade, scales = "free", ncol = 5) +
scale_x_continuous( # This handles replacement of row
breaks = timeless_words$row, # notice need to reuse data frame
labels = timeless_words$word) +
coord_flip()
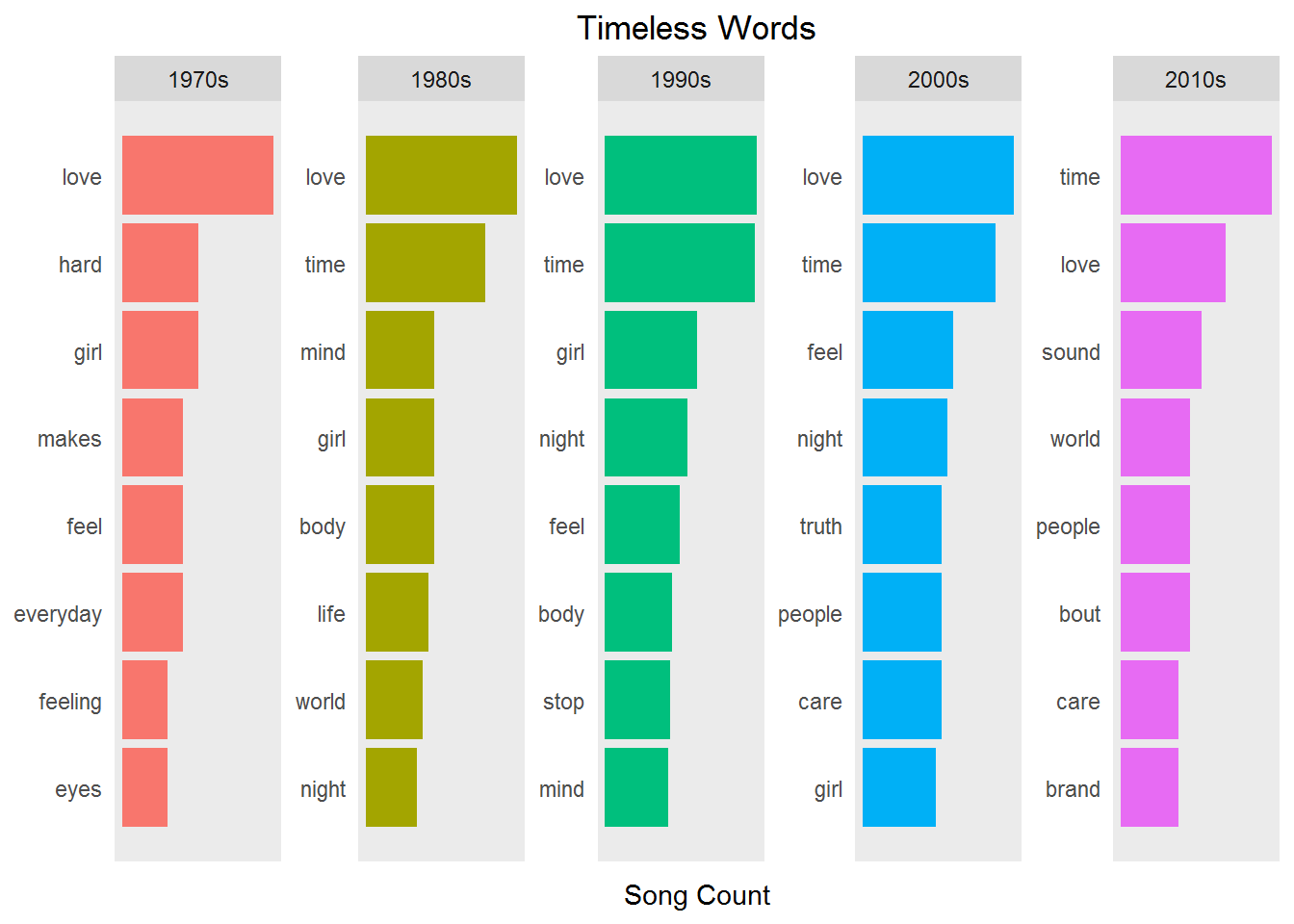
Clearly love, time, and girl are timeless. But how easy is it to spot trendy words? Was truth trending at the turn of the century? Could it simply be that something like it is just a highly repetitive word in certain songs? Does frequency actually identify themes? Does this work for lyrics in the same way it would other text mining tasks such as analyzing State of the Union speeches?
Word length is an interesting topic for songwriters. The longer the word, the harder it is to rhyme and squeeze into a pattern. This histogram of word lengths shown below is as you would expect, with a few incredibly long exceptions.
#unnest and remove undesirable words, but leave in stop and short words
prince_word_lengths <- prince %>%
unnest_tokens(word, lyrics) %>%
group_by(song,decade) %>%
distinct() %>%
filter(!word %in% undesirable_words) %>%
mutate(word_length = nchar(word))
prince_word_lengths %>%
count(word_length, sort = TRUE) %>%
ggplot(aes(word_length),
binwidth = 10) +
geom_histogram(aes(fill = ..count..),
breaks = seq(1,25, by = 2),
show.legend = FALSE) +
xlab("Word Length") +
ylab("Word Count") +
ggtitle("Word Length Distribution") +
theme(plot.title = element_text(hjust = 0.5),
panel.grid.minor = element_blank())
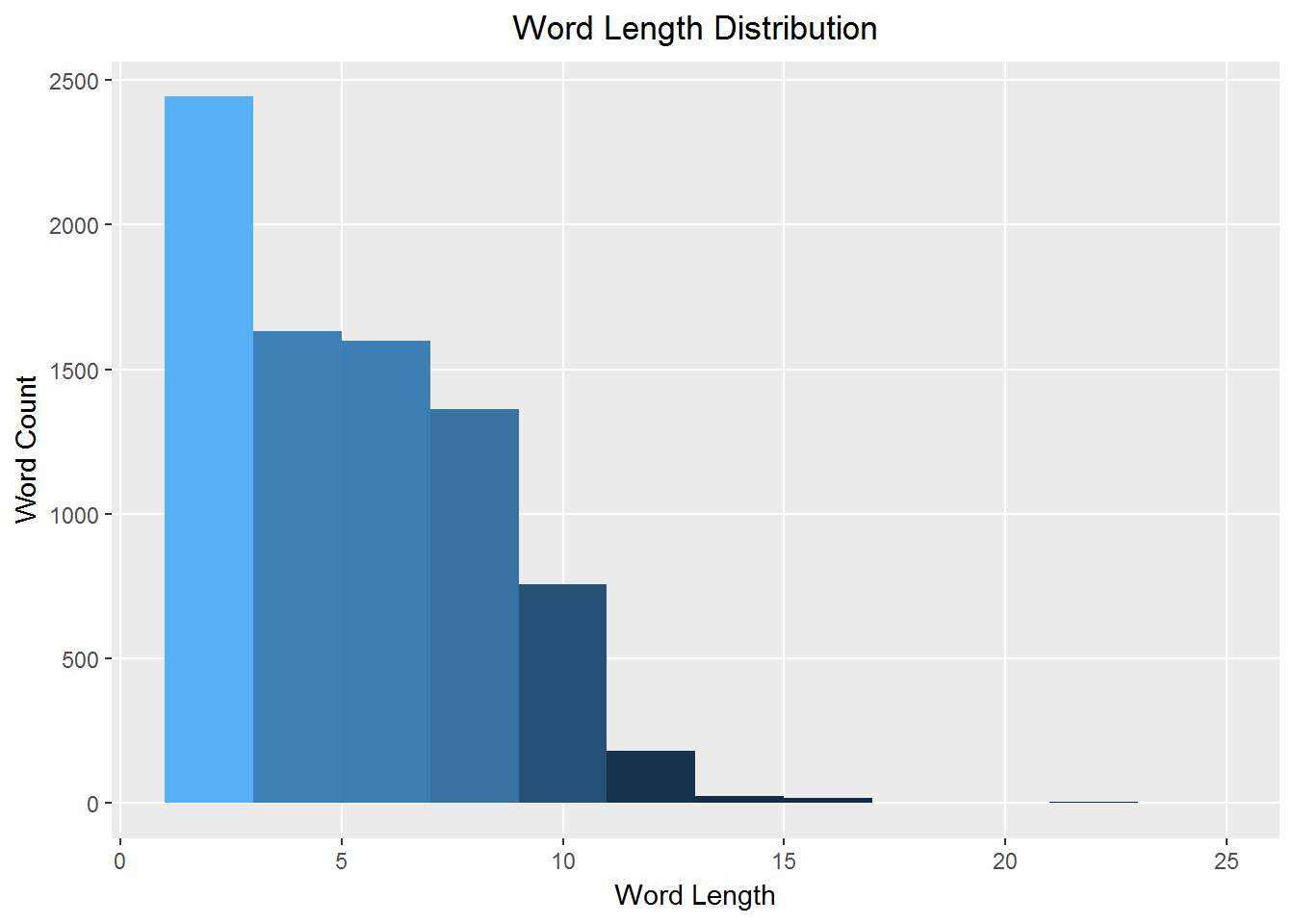
What are those crazy long words? I think this calls for a totally entertaining word cloud! This is based on word length rather than word frequency. Check it out:
wc <- prince_word_lengths %>%
ungroup() %>%
select(word, word_length) %>%
distinct() %>%
arrange(desc(word_length))
wordcloud2(wc[1:300, ],
size = .15,
minSize = .0005,
ellipticity = .3,
rotateRatio = 1,
fontWeight = "bold")
The more varied a vocabulary a text possesses, the higher its lexical diversity. Song Vocabulary is a representation of how many unique words are used in a song. This can be shown with a simple graph of the average unique words per song over the years. You'll want to tokenize the original dataset again but leave in all stop and short words since you're looking more at quantitative insights in this plot.
lex_diversity_per_year <- prince %>%
filter(decade != "NA") %>%
unnest_tokens(word, lyrics) %>%
group_by(song,year) %>%
summarise(lex_diversity = n_distinct(word)) %>%
arrange(desc(lex_diversity))
diversity_plot <- lex_diversity_per_year %>%
ggplot(aes(year, lex_diversity)) +
geom_point(color = my_colors[3],
alpha = .4,
size = 4,
position = "jitter") +
stat_smooth(color = "black", se = FALSE, method = "lm") +
geom_smooth(aes(x = year, y = lex_diversity), se = FALSE,
color = "blue", lwd = 2) +
ggtitle("Lexical Diversity") +
xlab("") +
ylab("") +
scale_color_manual(values = my_colors) +
theme_classic() +
theme_lyrics()
diversity_plot
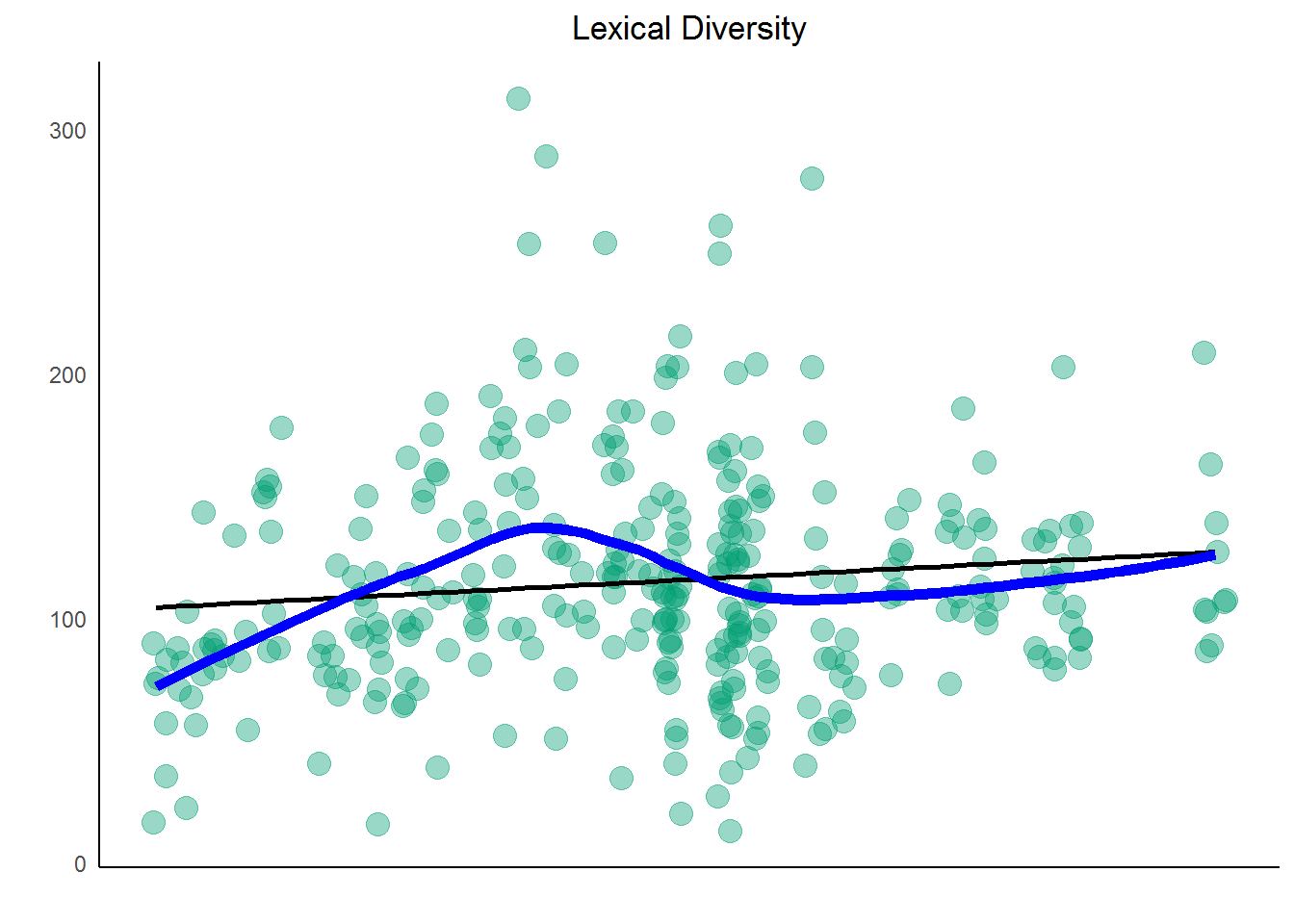
What does this mean? Over the past few decades, there was a slight upward trend in Prince's lyric diversity. How does this correlate to chart success? Hard to say, really, but go ahead and plot density and chart history for further comparison.
Recall that for this tutorial, lexical density is defined as the number of unique words divided by the total number of words. This is an indicator of word repetition, which is a critical songwriter's tool. As lexical density increases, repetition decreases. (Note: this does not imply sequential repetition, which is yet another songwriting trick.)
Take a look at Prince's lexical density over the years. For density, it's best to keep in all words, including stop words. So start with the original dataset and unnest the words. Group by song and year and use n_distinct() and n() to calculate the density. Pipe that into ggplot() with geom_smooth(). Add an additional stat_smooth() with method="lm" for a linear smooth model.
lex_density_per_year <- prince %>%
filter(decade != "NA") %>%
unnest_tokens(word, lyrics) %>%
group_by(song,year) %>%
summarise(lex_density = n_distinct(word)/n()) %>%
arrange(desc(lex_density))
density_plot <- lex_density_per_year %>%
ggplot(aes(year, lex_density)) +
geom_point(color = my_colors[4],
alpha = .4,
size = 4,
position = "jitter") +
stat_smooth(color = "black",
se = FALSE,
method = "lm") +
geom_smooth(aes(x = year, y = lex_density),
se = FALSE,
color = "blue",
lwd = 2) +
ggtitle("Lexical Density") +
xlab("") +
ylab("") +
scale_color_manual(values = my_colors) +
theme_classic() +
theme_lyrics()
density_plot
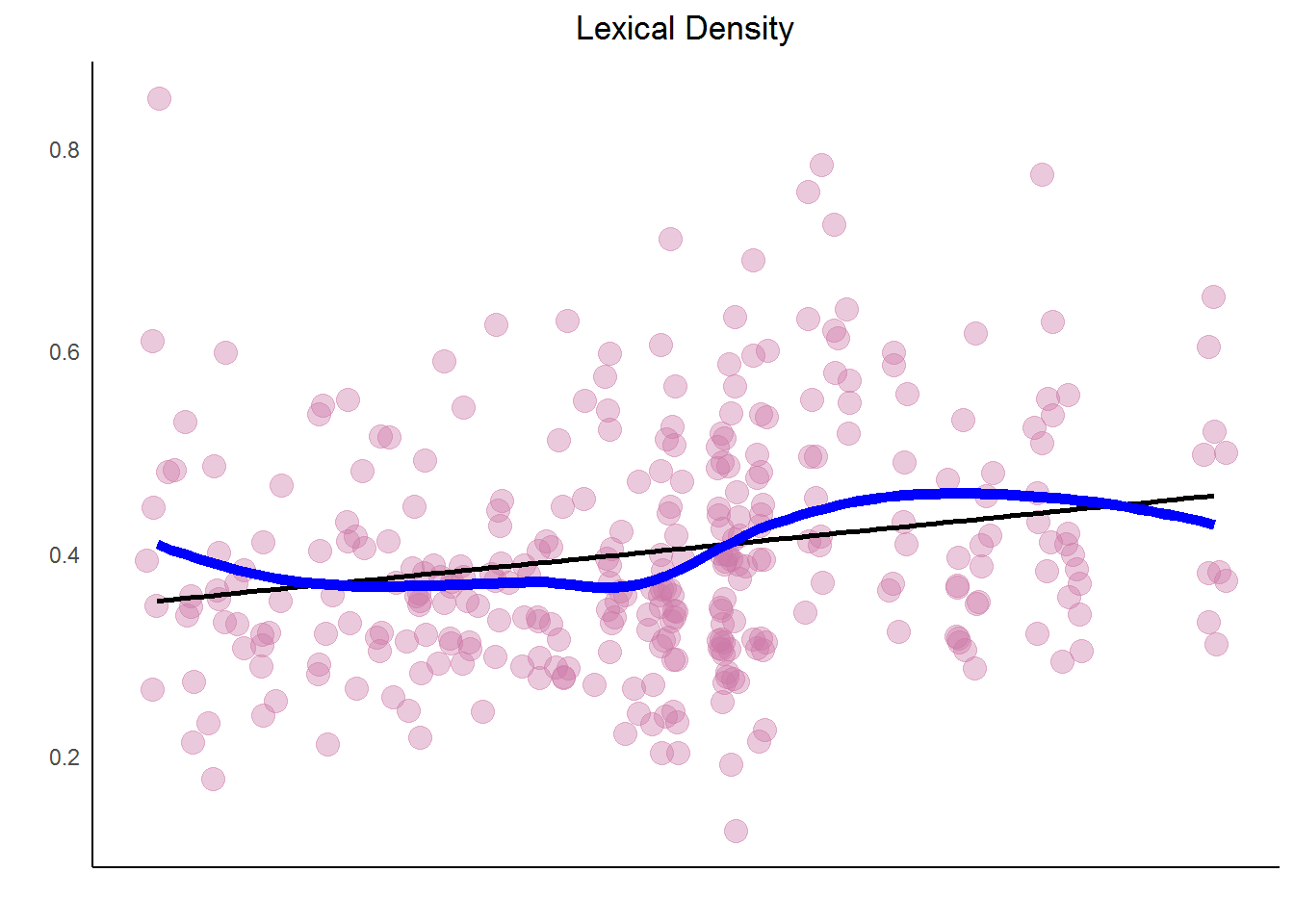
In order to compare the trends, create a plot for his chart history (i.e. successful songs that reached the charts) and compare it to diversity and density. Use grid.arrange() from gridExtra to plot them side by side.
chart_history <- prince %>%
filter(peak > 0) %>%
group_by(year, chart_level) %>%
summarise(number_of_songs = n()) %>%
ggplot(aes(year, number_of_songs)) +
geom_point(color = my_colors[5],
alpha = .4,
size = 4,
position = "jitter") +
geom_smooth(aes(x = year, y = number_of_songs),
se = FALSE,
method = "lm",
color = "black" ) +
geom_smooth(aes(x = year, y = number_of_songs),
se = FALSE,
color = "blue",
lwd = 2) +
ggtitle("Chart History") +
xlab("") +
ylab("") +
scale_color_manual(values = my_colors) +
theme_classic() +
theme_lyrics()
grid.arrange(diversity_plot, density_plot, chart_history, ncol = 3)
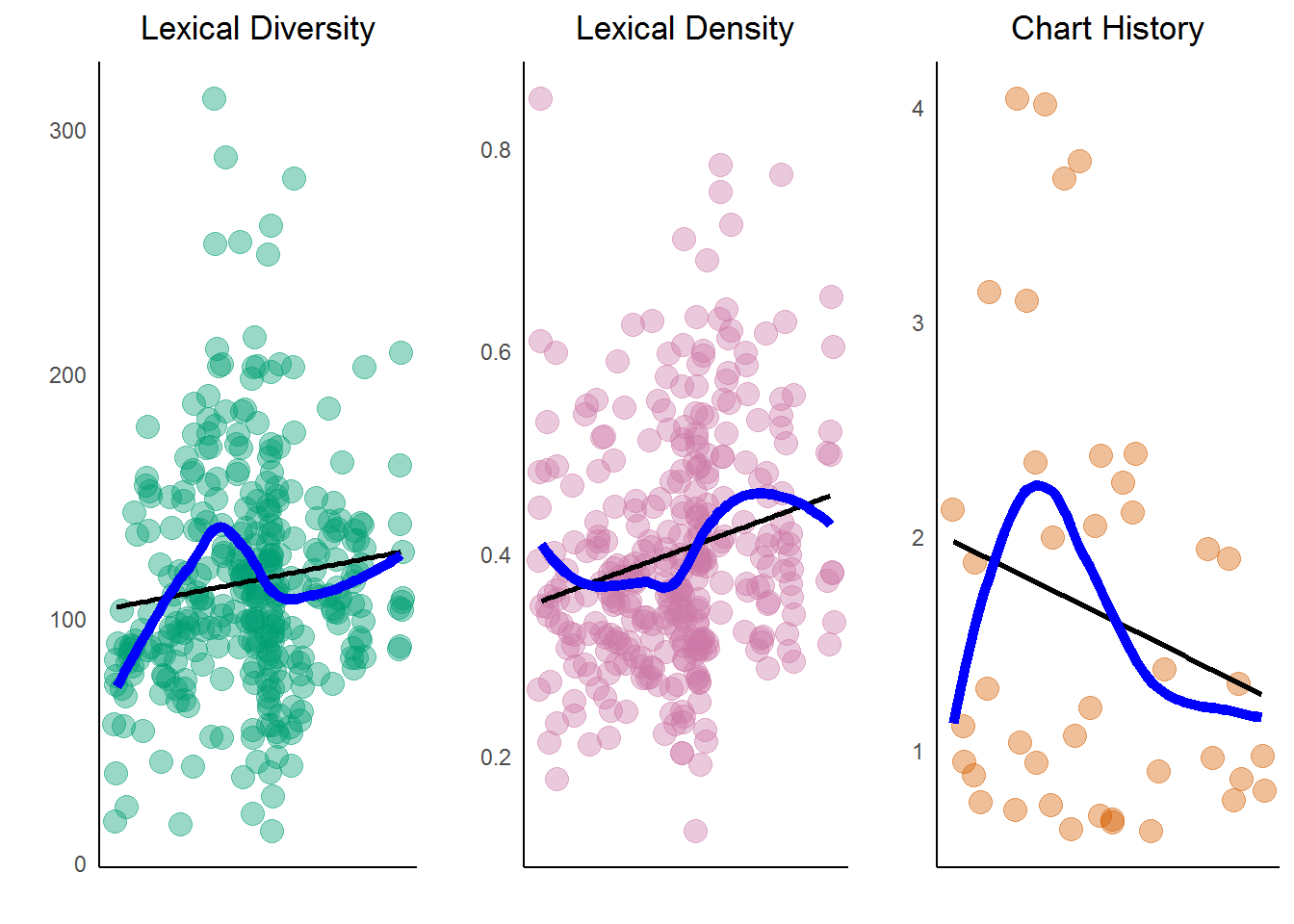
From the above, you see that there is a slight increase in Prince's lexical diversity and density over the years. How does this trend compare to all popular music? One study shows that Hit Songs have seen a declining lexical density, indicating increased repetition (i.e. "more words with less to say"). That is not what happened with Prince's songs. Another study reveals that across all popular music, diversity (unique words) has increased over time, which positively correlates with Prince's music. This is perhaps tied to greater genre diversity in chart rankings over history. Genre is a critical piece of data that does not exist in this dataset. Could it be that his chart history declines for popular music but increases for R&B/Rap?
Challenge: I'll leave you to consider these results and even encourage you to look for different datasets where you can leverage these skills on your own! Just remember, correlation doesn't imply causation.
The method that you've been using so far looks at the entire dataset, but it has not addressed how to quantify just how important various terms are in a document with respect to an entire collection. You have looked at term frequency, and removed stop words, but this may not be the most sophisticated approach.
Enter TF-IDF. TF is "term frequency". IDF is "inverse document frequency", which attaches a lower weight for commonly used words and a higher weight for words that are not used much in a collection of text. When you combine TF and IDF, a term's importance is adjusted for how rarely it is used. The assumption behind TF-IDF is that terms that appear more frequently in a document should be given a higher weight, unless it also appears in many documents. The formula can be summarized below:
The IDF of any term is therefore a higher number for words that occur in fewer of the documents in the collection. You can use this new approach to examine the most important words per chart level with the bind_tf_idf() function provided by tidytext. This function calculates and binds the TF and IDF, along with the TF*IDF product. It takes a tidy text dataset as input with one row per token (word), per document (song). You'll see the results in new columns.
So, take your original Prince data frame and unnest tokens to words, remove undesirable words, but leave in the stop words. Then use bind_tf_idf() to run the formulas and create new columns.
popular_tfidf_words <- prince %>% unnest_tokens(word, lyrics) %>% distinct() %>% filter(!word %in% undesirable_words) %>% filter(nchar(word) > 3) %>% count(chart_level, word, sort = TRUE) %>% ungroup() %>% bind_tf_idf(word, chart_level, n) head(popular_tfidf_words)
## # A tibble: 6 x 6 ## chart_level word n tf idf tf_idf ## <chr> <chr> <int> <dbl> <dbl> <dbl> ## 1 Uncharted that 622 0.010942420 0 0 ## 2 Uncharted your 529 0.009306335 0 0 ## 3 Uncharted what 496 0.008725789 0 0 ## 4 Uncharted will 481 0.008461904 0 0 ## 5 Uncharted this 464 0.008162834 0 0 ## 6 Uncharted know 441 0.007758211 0 0
Now you can see that IDF and TF-IDF are 0 for extremely common words. (Technically, the IDF term will be the natural log of 1 and thus would be zero for these words.) Pipe your results from above into arrange() and descend by tf-idf. Add a few more steps and you'll see a different way of looking at the words in Prince's lyrics.
top_popular_tfidf_words <- popular_tfidf_words %>%
arrange(desc(tf_idf)) %>%
mutate(word = factor(word, levels = rev(unique(word)))) %>%
group_by(chart_level) %>%
slice(seq_len(8)) %>%
ungroup() %>%
arrange(chart_level, tf_idf) %>%
mutate(row = row_number())
top_popular_tfidf_words %>%
ggplot(aes(x = row, tf_idf,
fill = chart_level)) +
geom_col(show.legend = NULL) +
labs(x = NULL, y = "TF-IDF") +
ggtitle("Important Words using TF-IDF by Chart Level") +
theme_lyrics() +
facet_wrap(~chart_level, ncol = 3, scales = "free") +
scale_x_continuous( # This handles replacement of row
breaks = top_popular_tfidf_words$row, # notice need to reuse data frame
labels = top_popular_tfidf_words$word) +
coord_flip()
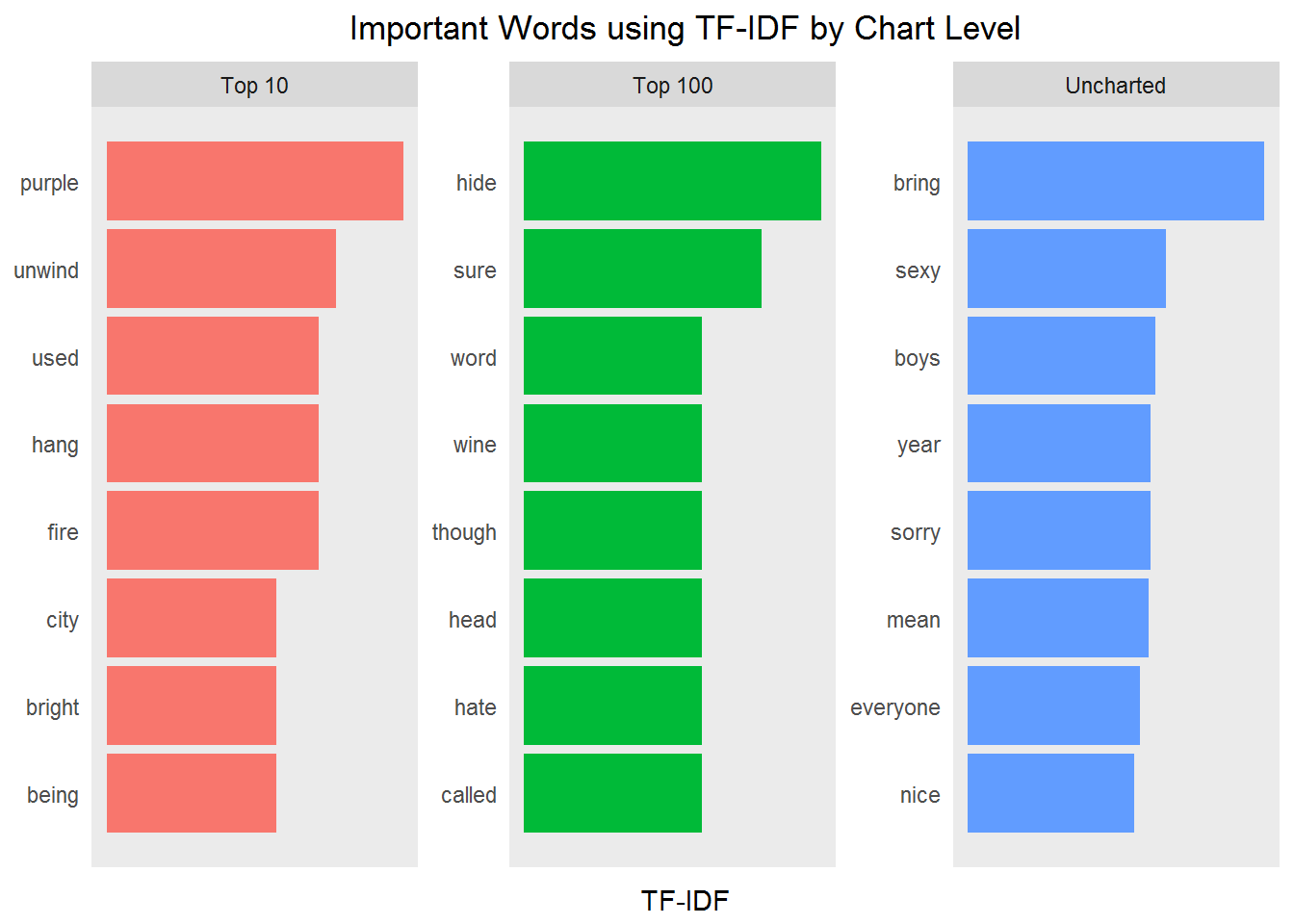
Wow, using TF-IDF certainly gives us a different perspective on potentially important words. Of course, the interpretation is purely subjective. Notice any patterns?
Next, take a look at the TF-IDF across time:
tfidf_words_decade <- prince %>%
unnest_tokens(word, lyrics) %>%
distinct() %>%
filter(!word %in% undesirable_words & decade != 'NA') %>%
filter(nchar(word) > 3) %>%
count(decade, word, sort = TRUE) %>%
ungroup() %>%
bind_tf_idf(word, decade, n) %>%
arrange(desc(tf_idf))
top_tfidf_words_decade <- tfidf_words_decade %>%
group_by(decade) %>%
slice(seq_len(8)) %>%
ungroup() %>%
arrange(decade, tf_idf) %>%
mutate(row = row_number())
top_tfidf_words_decade %>%
ggplot(aes(x = row, tf_idf, fill = decade)) +
geom_col(show.legend = NULL) +
labs(x = NULL, y = "TF-IDF") +
ggtitle("Important Words using TF-IDF by Decade") +
theme_lyrics() +
facet_wrap(~decade,
ncol = 3, nrow = 2,
scales = "free") +
scale_x_continuous( # this handles replacement of row
breaks = top_tfidf_words_decade$row, # notice need to reuse data frame
labels = top_tfidf_words_decade$word) +
coord_flip()
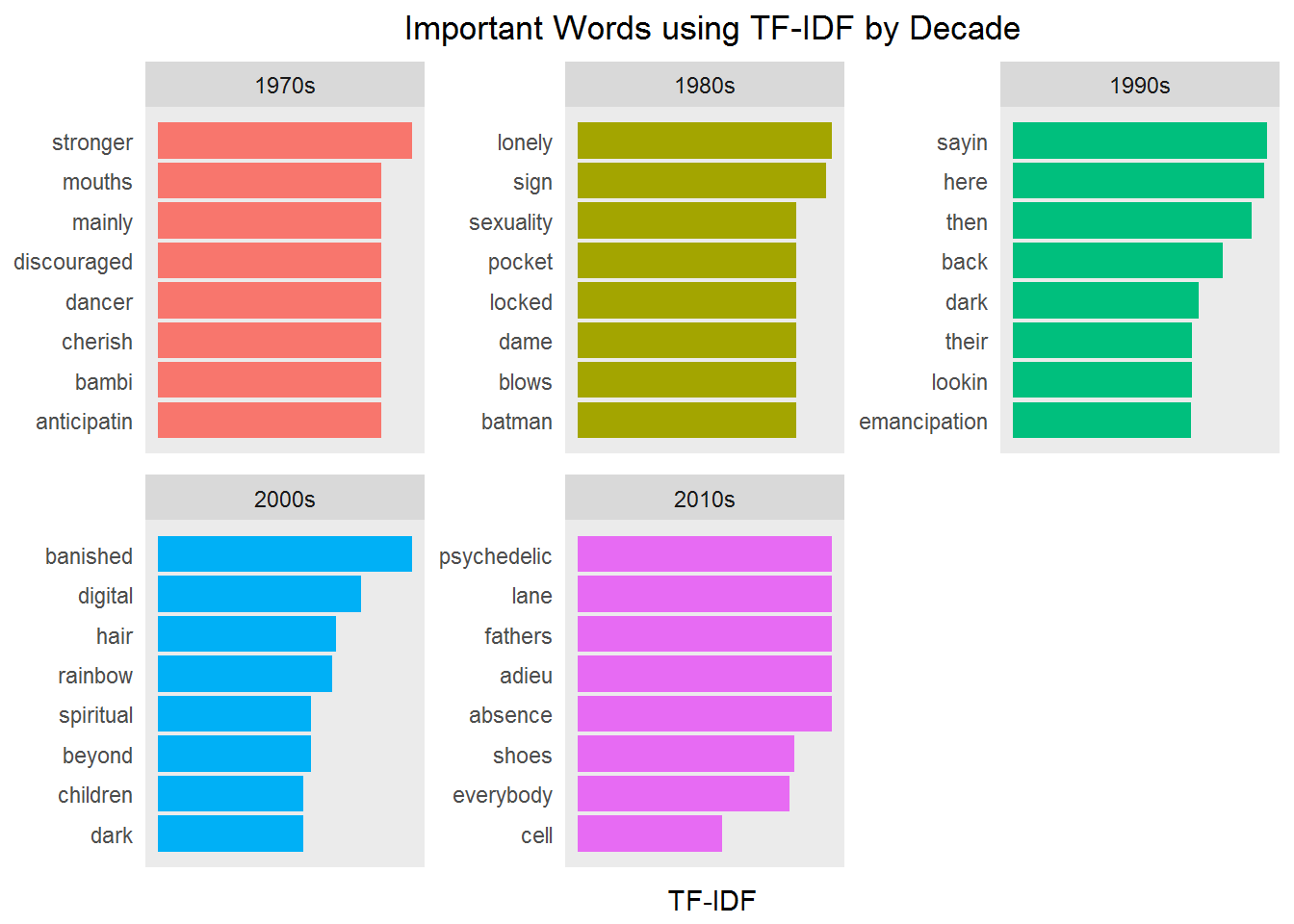
You are definitely getting a deeper level of insight now. The timeless words are no longer prevalent. Are you starting to see topics or themes emerge? Is that really possible with just a few words per group? You'll take this to new heights in the second tutorial (Part Two: Sentiment Analysis and Topic Modeling with NLP).
A quick wordcloud with this method shows a new perspective on important words in Prince's lyrics and is a bit more interesting...
wc <- tfidf_words_decade %>%
arrange(desc(tf_idf)) %>%
select(word, tf_idf)
wordcloud2(wc[1:300, ],
color = "random-dark",
minRotation = -pi / 6,
maxRotation = -pi / 3,
minSize = .002,
ellipticity = .3,
rotateRatio = 1,
size = .2,
fontWeight = "bold",
gridSize = 1.5 )
In this case study, you first took a glance into the actual data, looking only at the basics. After performing some conditioning such as data cleansing and removing uninformative words, you began an exploratory analysis at the song level.
Next, you delved deeper into text mining by unnesting lyrics into tokenized words so that you could look at lyrical complexity. The results provide critical insights for the next steps of sentiment analysis and topic modeling.
Finally, you used TF-IDF analysis to represent the information behind a word in a document relating to some outcome of interest. You may think that this is a good way to identify themes in music, but you really only have half the story. Part Two addresses an unsupervised learning method called Latent Dirichlet Allocation (LDA). As in all aspects of Data Science, there are many methods to choose from for gaining insight. And in Parts Two and Three of this case study, you'll address more of these options.
Hopefully you are as excited as I am to continue this journey from exploratory analysis on to sentiment analysis, topic modeling, and predictive insights.
Thanks for reading, and I hope to see you in the next tutorial!
Learn more about R and Machine Learning
Course
Course
Course
Tutorial
Debbie Liske
Tutorial
Debbie Liske
Tutorial
Debbie Liske
Tutorial
Hugo Bowne-Anderson
Tutorial
Karlijn Willems
code-along
Ishmael Rico
