
Course
Generative AI Concepts
2 hr
105.1K
Databricks has been one of the pioneers in building technologies and platforms that help deliver AI solutions at scale, including driving open-source projects such as Apache Spark and MLflow.
During the Databrick Data + AI Summit 2023, Lakehouse AI was announced as the world's first AI platform, built into the data layer — and many more new features were announced. With the launch of ChatGPT and giant leaps in generative AI technologies across the world, Lakehouse AI is Databrick’s answer to building generative AI applications through a data-centric approach.
In this tutorial, we will introduce the Databricks Lakehouse AI platform, ponder its significance, understand the new features launched, and how we could utilize them in our machine learning development lifecycle.
Wait, Lakehouse? We understand it may all be new terms to you.
Let’s break down the evolution of Databricks Lakehouse AI step by step. To understand Lakehouse AI — we need to fully understand Lakehouse architecture first.
A “Lakehouse” is a modern data management architecture that combines the flexibility and cost-effectiveness of a data lake with the data management features of a data warehouse.
We have an entire tutorial on the differences between the data lake and warehouse in detail, but in short, here’s what that means:
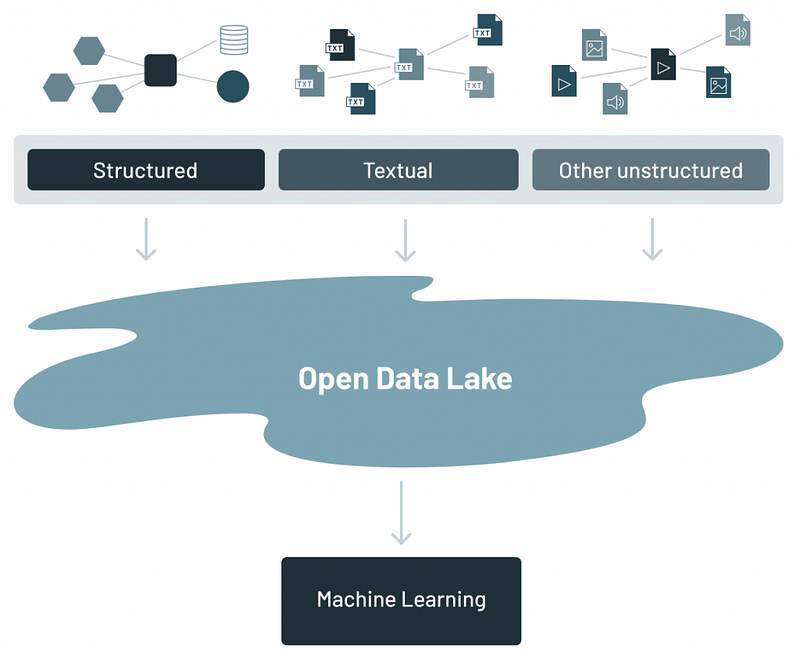
The data lake architecture (Source)
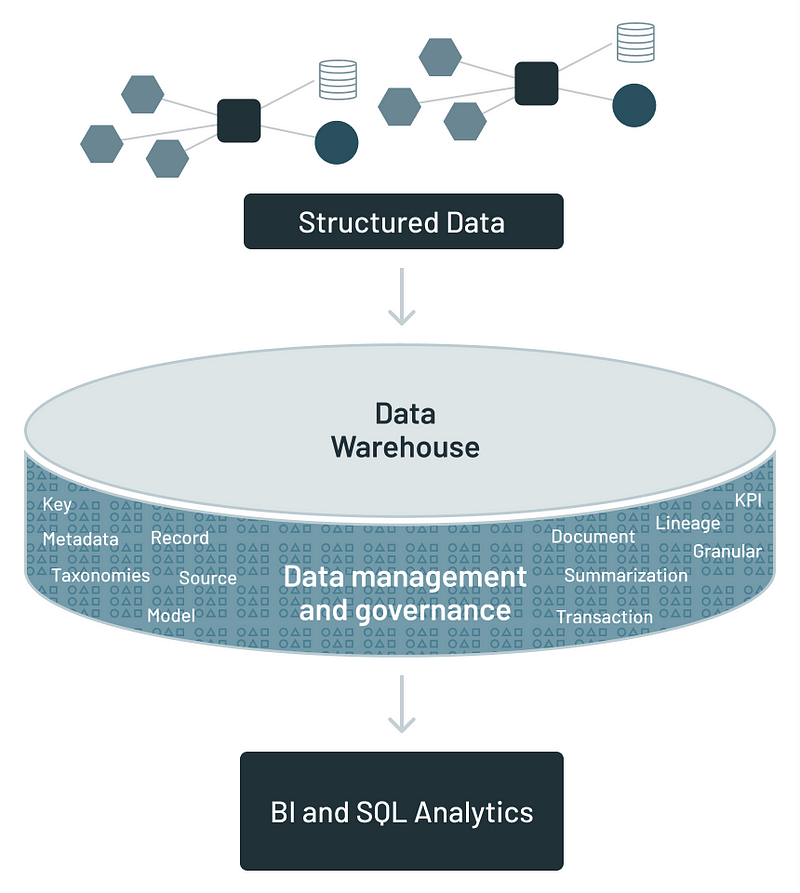
The data warehouse architecture (Source)
Data lakes often struggle with data management and governance due to their nature of storing vast amounts of raw, unstructured data, which can lead to “data swamps” where data is difficult to find, access, or trust. The lack of structure can also hinder the performance of complex analytical queries, and traditional data lakes usually don’t support transactional data operations well, lacking ACID transaction capabilities, which are crucial for ensuring data integrity.
Data warehouses, on the other hand, are optimized for structured data and analytics but can become cost-prohibitive to scale as data volumes increase. Their requirement for data to be structured and processed into a predefined schema can introduce rigidity, limiting the ability to quickly ingest and analyze new data types.
These limitations have driven the evolution of the Lakehouse architecture, which aims to bring the best of both worlds:
Here’s how the lakehouse architecture looks:
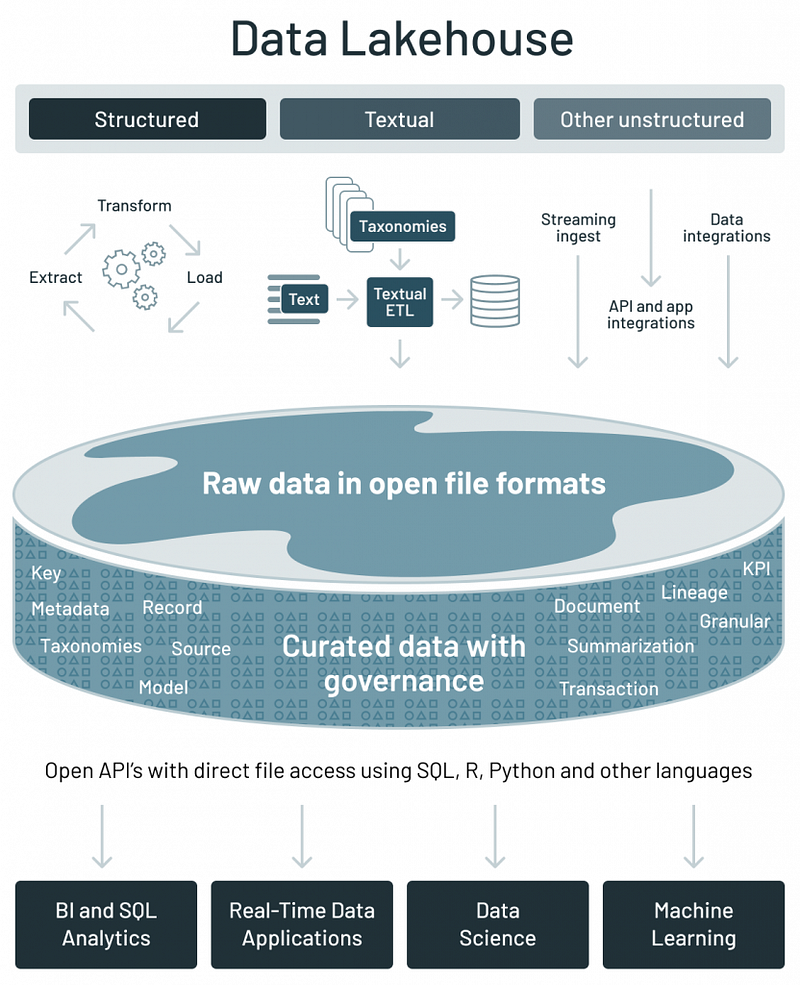
The data lakehouse architecture (Source)
Now that we understand the evolution of Databricks Lakehouse, we are brought to the final question.
Lakehouse AI is the integration of artificial intelligence and machine learning capabilities directly into the Lakehouse architecture. This means we can develop, train, and deploy AI models using the vast amounts of data stored in our data lake without needing to move or copy the data to a separate environment for processing.
The significance of this platform is:
These features explain why Databricks announced this platform as the world's first AI platform built into the data layer.
The transition to Lakehouse AI has been instrumental in driving businesses towards more data-driven and AI-integrated operations.
At the heart of this transformation are several core components that facilitate the development, deployment, and management of AI and machine learning models. Understanding why and when these components are needed can help organizations more effectively leverage their data for AI applications.
Vector Search in Databricks Lakehouse AI represents a significant advancement (also launched in the Data+AI Summit 2023) in handling and searching through massive datasets to find semantically similar information, rather than relying on traditional keyword matches.
Vector Search operates by converting data and queries into vectors in a multi-dimensional space called embeddings, which are derived from a Generative AI model. This method enables semantically similar words or concepts to be closer in the n-dimensional space, allowing for more relevant and context-aware search results.
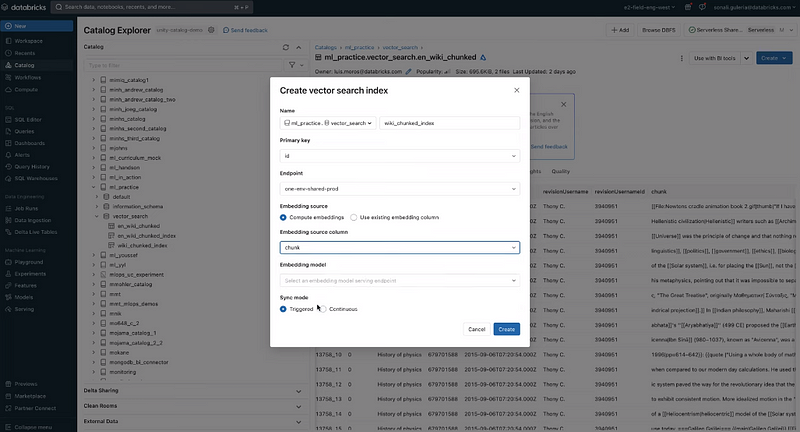
Vector search (Screenshot by author)
The process of using Vector Search (demo video by Databricks) is as follows:
Companies such as Lippert have already used Vector Search to empower agents to find answers to customer inquiries swiftly, by ingesting content from various sources into Vector Search.
These models, available within the Databricks Marketplace, are optimized for high performance and are designed to be easily integrated into the Lakehouse environment for a range of applications, from text analysis and generation to image processing.
Some of the curated Generative AI models include:
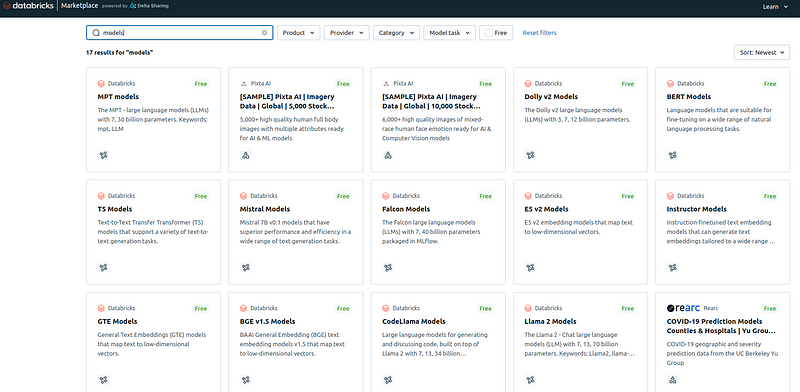
Models available in Databricks Marketplace (Screenshot by author)
These models are designed to work seamlessly with the broader set of Databricks Lakehouse AI features, including data management, analytics, and MLOps tools. We will see how these models can be used in machine learning development in a bit.
AutoML (Automated Machine Learning) features within Databricks Lakehouse AI are designed to streamline and automate the machine learning model development process, making advanced data science accessible to a broader range of users, including those with limited machine learning expertise.
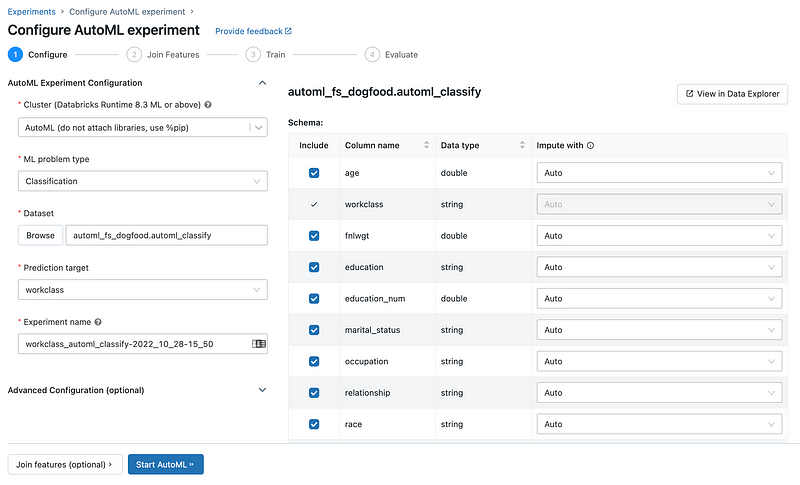
Databrick AutoML (Source)
When we provide the dataset and specify the prediction goal, AutoML takes care of getting the dataset ready for training a model. It then goes on to create, adjust, and evaluate multiple models through a series of trials.
Once the evaluation is complete, AutoML presents the results and offers a Python notebook containing the source code for each trial. This allows us to review, reproduce, and modify the code as needed. AutoML also calculates summary statistics about our dataset and saves this information in a notebook for future reference.
With the latest launch, AutoML now offers fine-tuning generative AI models for text classification and embedding models with customer’s own data. This means non-technical business users can now use AutoML to build generative AI applications with a few clicks.
Databricks Lakehouse Monitoring enables us to monitor the statistical properties and quality of our data tables and track the performance of machine learning models and their predictions. By examining the data flow within Databricks’ pipelines, this monitoring feature helps ensure the continuous monitoring of data quality and model effectiveness.
Here’s how the data flows through the Lakehouse monitoring to enable the continuous monitoring:
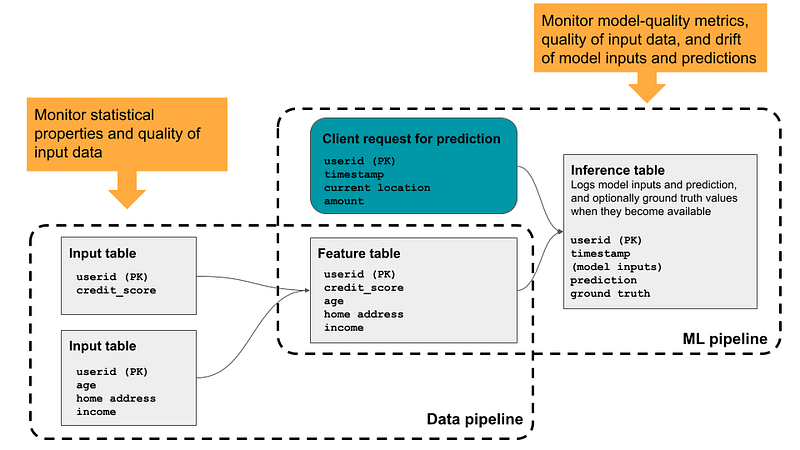
Lakehouse Monitoring flow (Source)
Instead of stopping at monitoring, this feature also provides actionable insights into various aspects such as data integrity, distribution, drift, and model performance over time.
Let us now see how all of these features come together as unified governance in Lakehouse AI.
The idea of unified governance is being able to access, control, collaborate, monitor, and act on the data, machine learning models, and other AI assets in one place. As any organization grows and matures in the AI transformation journey, being able to manage everything in one place is crucial.
Databricks Unity Catalog does just that, and unifying the approach to govern the AI assets essentially accelerates AI adoption while still ensuring regulatory compliance.
While there are useful features such as data explorer and the ability to add external systems, the standout feature is being able to see a bird’s eye view of the entire governance of these assets through a simple Unity Catalog Governance Portal as shown below:
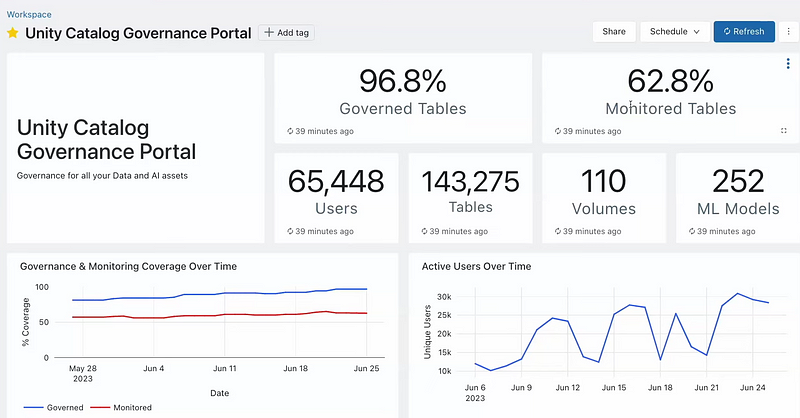
Unity catalog governance portal (Screenshot by author)
This portal displays key metrics like the percentage of governed and monitored tables, the number of active users, and the count of tables, volumes, and ML models. This high-level view helps in quickly assessing the governance status and active engagement with data assets.
The dashboard also shows the activity levels of users over time, which can help in understanding how data assets are utilized within the organization and identifying any bottlenecks or training needs.
Further, the portal lists potential governance risks by identifying issues like unmonitored tables or columns derived from PII (Personally Identifiable Information), providing a proactive approach to managing data securely, as seen below.
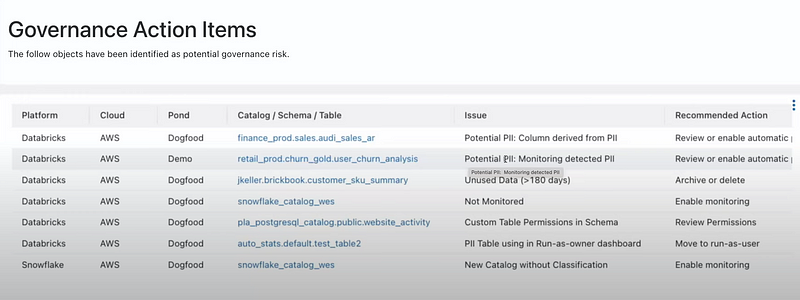
Governance action items view of the unity catalog dashboard (Screenshot by author)
Each identified issue comes with a recommended action, guiding users toward resolving potential governance concerns. This feature simplifies and unifies the often complex process of governance of AI and data assets across the platform.
Now that we understand the features of the platform and how they come together, let us dive into its application for end-to-end machine learning development.
For a refresher on the end-to-end machine learning development lifecycle, we encourage you to refer to our in-depth tutorial on the same. In this section, we will understand how the features of Databricks Lakehouse AI fit into the lifecycle.
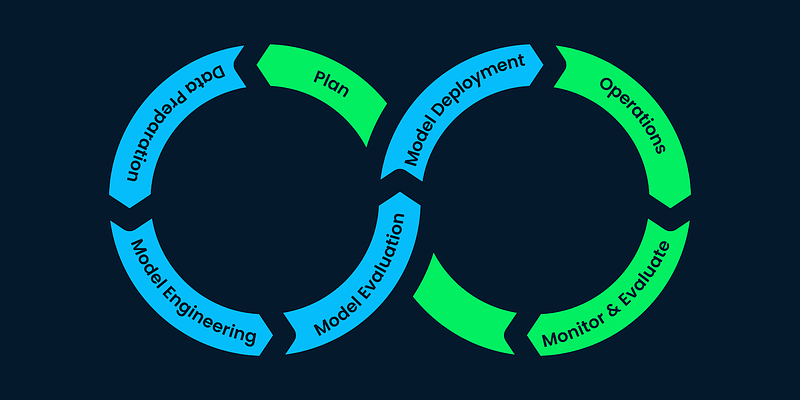
End-to-end Machine Learning Development (Source)
The foundational stone of machine learning within Databricks Lakehouse AI is the capability to train and build models efficiently.
We can use the Databricks ML runtime that comes with common packages such as pandas and PySpark for data preparation and cleaning. Databricks Feature Store is a centralized repository within the Databricks Lakehouse AI Platform — designed to store, share, and manage machine learning features.
This feature store ensures that features used for training machine learning models are consistent with those used during inference in production environments. We also need not waste computing resources by re-computing the features again and again for different use cases.
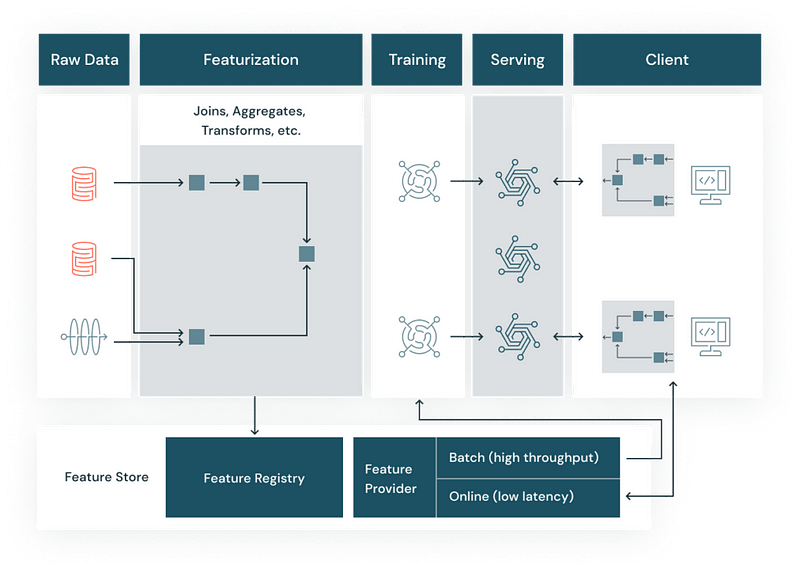
The function of a feature store (Source)
By centralizing feature definitions and storage, it eliminates the common problem of “training-serving skew,” where the data used for model training differs from what the model encounters in a live setting.
For model development, we have the flexibility to choose from either pre-built curated models available within the Databricks environment or opt to train a custom model tailored to their specific data and business requirements.
Databricks also have GPU-optimized clusters, meaning the training (and inference) can happen faster and in scale, which is often a crucial element when it comes to real-time insights, predictions, and recommendations at scale.
Databricks has developed an open-source tool called MLflow, natively available in the Databricks platform, which streamlines the complex process of tracking experiments, packaging code into reproducible runs, and sharing findings.
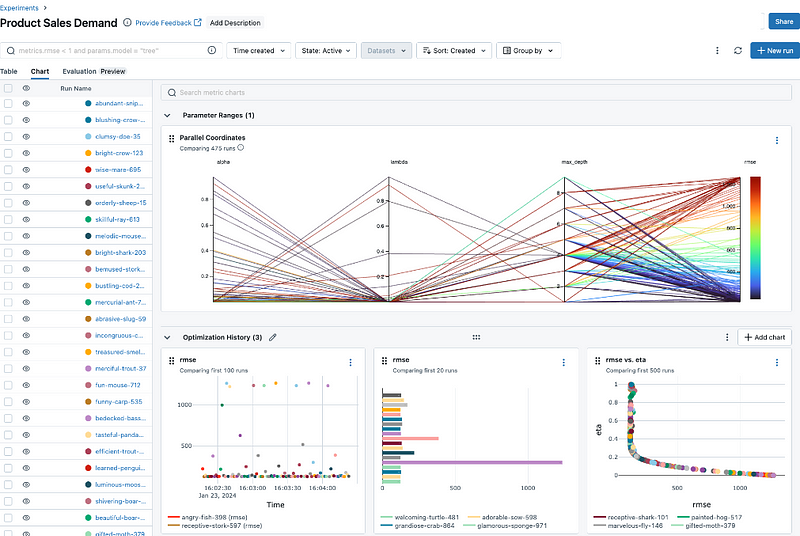
An example MLflow experiment (Screenshot by author)
The steps to creating an experimentation framework are as follows:
Once the framework is established, we’re able to rapidly iterate to arrive at the best model early.
Model Serving, another feature within Databricks Lakehouse AI streamlines the transition of machine learning models from the development stage to a production-ready state.
This functionality allows for models to be deployed as RESTful endpoints, which can be easily integrated into various applications and services for real-time predictions or batch inference.
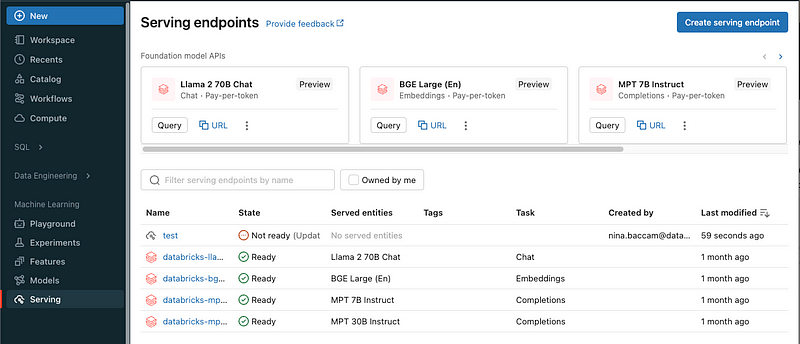
Model Serving endpoints (Source)
Once a model is trained, data scientists can deploy it with just a few clicks without the need for extensive setup or DevOps expertise. Here’s how to do this:
We encourage you to go through these detailed tutorial examples from Databricks to execute these steps with ease. This ease of deployment is crucial in modern data workflows, where the ability to rapidly iterate and deploy models can significantly drive business value.
Once our machine learning models are deployed into production, the last crucial phase in the AI lifecycle is monitoring and evaluation. This phase involves continuously tracking the model’s performance to ensure it remains effective and accurate over time.
Databricks Lakehouse AI facilitates this through Lakehouse Monitoring and Inference Tables, which are essential tools for maintaining the health and efficacy of our AI systems. Since we already saw the features of Lakehouse Monitoring earlier, in this section, we’ll focus on the inference tables.
Simply put, the Inference Table is an additional feature, which you need to enable using a tickbox, that enables us to capture the input data and the corresponding predictions from the Model Serving endpoints and log them into a delta table, which will be part of the Unity Catalog.
This logging mechanism has multiple benefits:
The machine learning development process is cycle in nature, which means we take the feedback from our first version of deployment and refine, retrain, and build models that are more accurate and efficient, thus reaching us to the first step over again.
This tutorial introduced the evolution of Databricks Lakehouse AI and its core features. We also looked at how these features come together through a unified governance. Further, we analyzed and understood how we can navigate through the end-to-end machine learning lifecycle using the Databricks Lakehouse AI platform.
To learn more about Databricks Lakehouse and its application in data engineering, machine learning development, and building large-scale applications in a hands-on fashion, we recommend looking at our Introduction to Databricks course as the next step.
Start Your AI Journey Today!
Course
Course
Course
blog
Josep Ferrer
blog
Moez Ali
15 min
podcast
Tutorial
Allan Ouko
Tutorial
Bex Tuychiev
Tutorial
Bex Tuychiev


