Natural Language Processing (NLP) is a subfield of linguistics, computer science, artificial intelligence, and information engineering concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data.
Sounds interesting? What would you say if we told you we asked an algorithm called GPT-3 to write this entire paragraph and it did it on the first try? We are not kidding! Check this out…
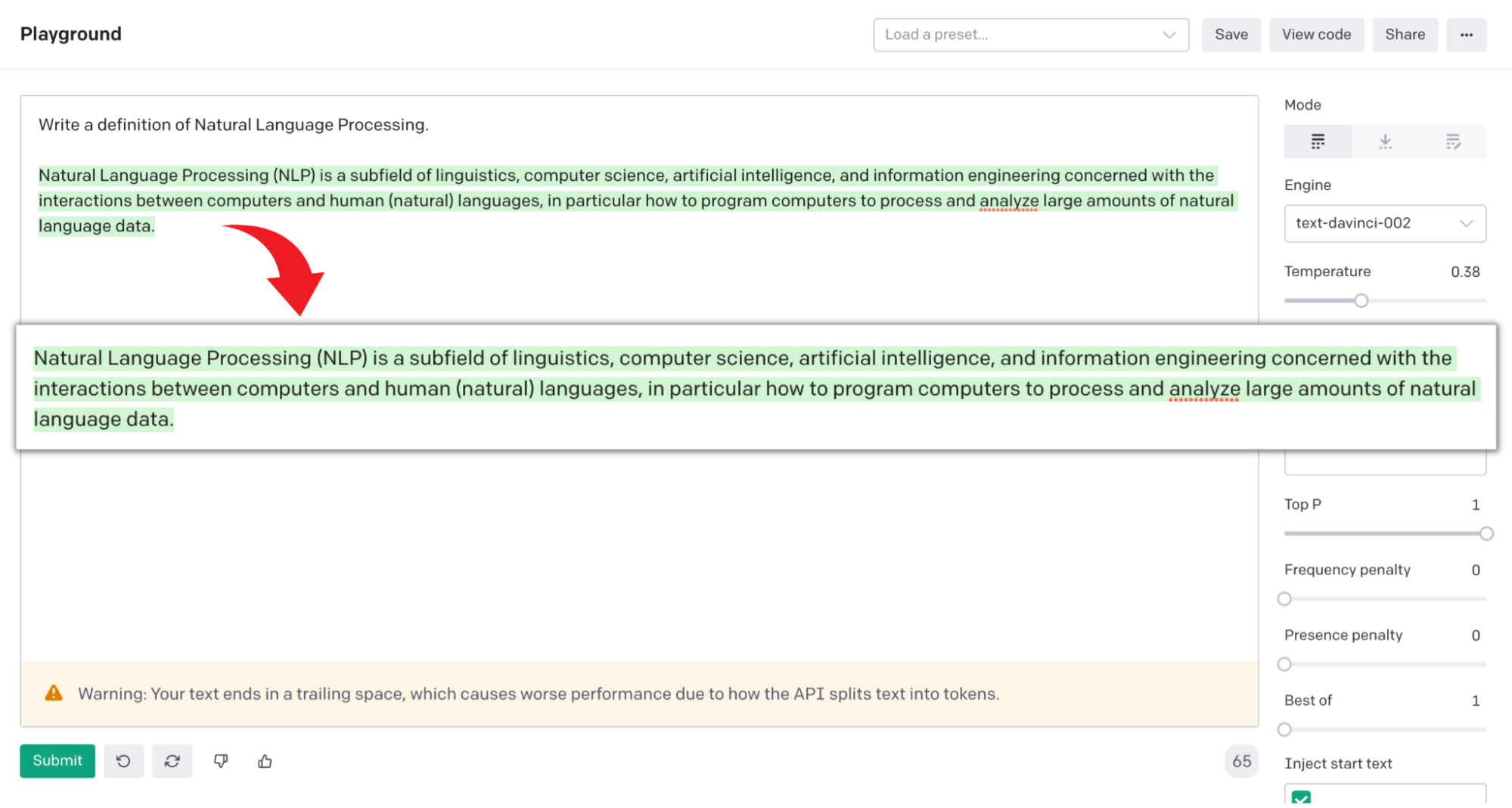
GPT-3 in Action
Pretty amazing, right?! So, coming back to NLP. It enables computers to process human language in the form of text or voice data and “understand” its full meaning, encompassing the speaker’s or writer’s intent and sentiment. NLP as a field has been the site of some of the most exciting AI discoveries and implementations of the past decade. For the past several years, the most exciting and prolific trend that can be seen in this area is large language models, to which the GPT-3 model belongs.
GPT-3 is considered as the first step by some in the quest for Artificial General Intelligence. It has captured more attention than any other AI model out there. Its sheer flexibility in performing a series of generalized tasks with near-human efficiency and accuracy is what makes it so exciting. It was released in the form of an API with the intention to give data scientists, developers, and people of all walks and professions around the world unprecedented access to one of the world’s most powerful language models.
The model was created by OpenAI, a company at the frontier of artificial intelligence R&D. Since its initial release in July 2020, developers around the world have already found hundreds of exciting applications for GPT-3 that have the potential to elevate the ways we communicate, learn, and play. It is capable of solving general language-based tasks with ease and can move freely between different text styles and purposes.
Before GPT-3, language models were designed to perform one specific NLP task, such as text generation, summarization, or classification. GPT-3 is the first-ever generalized language model in the history of natural language processing that can perform equally well on an array of NLP tasks. GPT-3 stands for “Generative Pre-trained Transformer,” and it’s OpenAI’s third iteration of the model. Let us break down these three terms:
- Generative: Generative models are a type of statistical model that are used to generate new data points. These models learn the underlying relationships between variables in a dataset in order to generate new data points similar to those in the dataset.
- Pre-trained: Pre-trained models are models that have already been trained on a large dataset. This allows them to be used for tasks where it would be difficult to train a model from scratch. A pre-trained model may not be 100% accurate, but it saves you from reinventing the wheel, saving time, and improving performance.
- Transformer: A transformer model is a famous artificial neural network invented in 2017. It is a deep learning model that is designed to handle sequential data, such as text. Transformer models are often used for tasks such as machine translation and text classification.
In the next section, we will look at the broader context of language models—what they are, how they work, and what they are used for. You can find out more about what we know about GPT-4 in a separate article, learn more about AI here or learn about the latest on OpenAI, Google AI, and what it means for data science.
What Are Large Language Models?
In recent years, there has been massive interest in the field of natural language processing (NLP) around building large language models, or LLMs. LLMs, which are trained on large amounts of text, can be used for a variety of language-based tasks, including text generation, machine translation, and question answering.
Language modeling is the task of using probability to understand how sentences come together in a given language. Simple language models can look at a word and predict the next word (or words) most likely to follow it, based on statistical analysis of existing text sequences. For example, the sentence "I love walking my ..." is more likely to end with the word "dog" than the word "refrigerator". It is important to train the language model with lots of data in order to make it accurate at predicting word sequences.
LLMs can be thought of as statistical prediction machines, where text is input and predictions are output. You’re probably familiar with this from the autocomplete feature on your phone. For instance, if you type “good”, autocomplete might come up with suggestions like “morning” or “luck.” Natural language processing applications such as autocomplete rely heavily on language models.
While language models have been around for a long time, it is only recently that they have become so successful. This is due to a number of factors, including the availability of large amounts of training data, the development of better training algorithms, and the use of GPUs to speed up training. With more data, the models can learn more about the relationships between words and the context in which they are used. This allows the models to better understand the meaning of text and generate more accurate predictions.
The success of LLMs is due to their ability to capture the dependencies between words in a text. For example, in the sentence "The cat sat on the mat," the word "cat" is dependent on the word "the," and the word "mat" is dependent on the word "on." In a large language model, these dependencies are captured in the model's parameters. While large language models have grown more advanced, the number of parameters they use has exploded, as you can see in the following graph published by Microsoft Research.
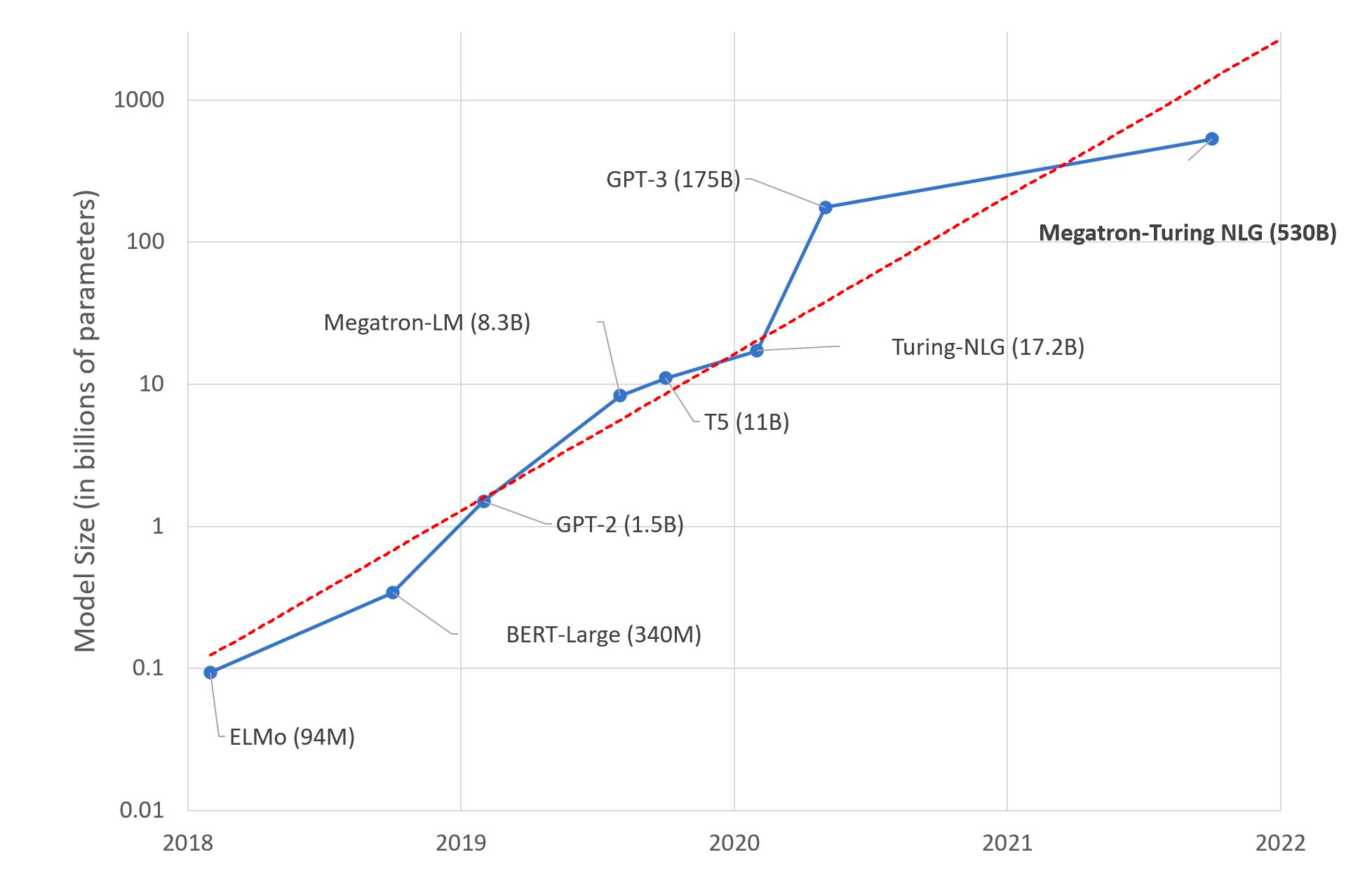
Trend of sizes of state-of-the-art NLP models over time on a logarithmic scale
Source: Microsoft Research blog post on 11th Oct 2021
Pre-training of large language models requires large amounts of computation, which is energy-intensive. The growing demand for these models requires more and more computational resources. This has significant environmental costs, such as unsustainable energy use and carbon emissions.
In a 2019 study, researchers at the University of Massachusetts estimated that training a large deep-learning model produces 626,000 pounds of planet-warming carbon dioxide, equal to the lifetime emissions of five cars. As models grow bigger, their computing needs are outpacing improvements in hardware efficiency. A 2021 study estimates that training of GPT-3 produced roughly 552 metric tons of carbon dioxide. This is about the amount that 120 cars would produce in a year of driving.
However, the 2019 Green AI paper notes “that the trend of releasing pre-trained models publicly is a green success,” and the authors encouraged organizations “to continue to release their models in order to save others the costs of retraining them.” Companies such as OpenAI that are releasing pre-trained large language models are continuously researching and developing techniques to reduce the carbon footprint of training the models.
GPT-3 is highly accurate while performing various NLP tasks due to the huge size of the dataset it has been trained on and its large architecture consisting of 175 billion parameters, which enables it to understand the logical relationships in that data. GPT-3 is pre-trained on a corpus of text from five large datasets that include Common Crawl, WebText2, Books1, Books2, and Wikipedia. This corpus altogether includes nearly a trillion words allowing GPT-3 to successfully perform a surprising number of NLP tasks in a zero-shot setting, or without providing any example data.
In the next section, we will explore transformers, the famous architecture enabling models that have taken the language modeling field by storm and changed the definition of what is possible within the NLP space.
What Are Transformer Models?
The transformer is a type of neural network architecture that is particularly well-suited for language modeling tasks. It was first introduced in the paper "Attention is All You Need" in 2017. The paper explains transformers as a type of neural network architecture that is designed to efficiently perform sequence-to-sequence tasks while handling long-range dependencies with ease. Transformer models have quickly become the go-to architecture for natural language processing tasks, currently dominating the NLP space.
Sequence-to-Sequence is a mechanism that is the backbone of transformer models. Otherwise known as Seq2Seq, the architecture transforms a given sequence of elements, such as words in a sentence, into another sequence, such as a sentence in a different language, which makes the architecture particularly well suited to translation tasks. Google Translate started using a similar architecture in production in late 2016.

Source: “The Illustrated Transformer” blog post by Jay Alammar
Seq2Seq models consist of two parts: an encoder and a decoder. The encoder and decoder can be thought of as human translators who can speak only two languages. Each has a different mother tongue; for our example, we’ll say the encoder is a native Chinese speaker and the decoder is a native English speaker. The two have a second language in common; let’s say it’s Japanese. To translate Chinese into English, the encoder converts the Chinese sentence into Japanese. That Japanese sentence, known as context, is passed to the decoder. Since the decoder understands Japanese and is able to read that language, it can now translate from Japanese into English.
Another key component of transformer architecture is a mechanism called “attention”. It is a technique that mimics cognitive attention. Cognitive attention is a technique that mirrors how our brains pay attention to the significant parts of a sentence, helping us understand its overall meaning. For example, as you are reading this sentence, you are always focused on the word you are reading, but at the same time, your memory holds the most important keywords of the sentence to provide context.
The attention mechanism looks at an input sequence piece by piece and decides at each step which other parts of the sequence are important. This helps the transformer filter out noise and focus on what’s relevant by connecting related words that in themselves do not carry any obvious markers pointing to one another.
Transformer models benefit from larger architectures and being fed larger quantities of data. This makes them better at understanding the context of words in a sentence than any other kind of neural network, which explains their major impact on the field of machine learning. As they continue to evolve, they are likely to have an even bigger impact in the years to come, and you can begin your experimentation with LLMs in a few easy steps.
Getting Started with GPT-3
Navigating The OpenAI API
Even though GPT-3 is arguably one of the most sophisticated and complex language models in the world, its capabilities are accessible via a simple "text-in-text-out" user interface. The first thing you need to get started with GPT-3 is getting access to the OpenAI API. You can apply for it here and in a matter of minutes, your account will be set up.
Once you have access to an OpenAI developer account, we will look at the Playground, a private web-based sandbox environment that allows you to experiment with the API and learn how its different components work together.
Components of the OpenAI API
Here is an overview of the different API components and their functionalities:
- Execution Engine: It determines the language model used for execution. Choosing the right engine is the key to determining your model’s capabilities and in turn getting the right output.
- Response Length: The response length sets a limit on how much text the API includes in its completion. Because OpenAI charges by the length of text generated per API call, response length is a crucial parameter for anyone on a budget. A higher response length will cost more.
- Temperature: The temperature controls the randomness of the response, represented as a range from 0 to 1. A lower value of temperature means the API will respond with the first thing that the model sees; a higher value means the model evaluates possible responses that could fit into the context before spitting out the result.
- Top P: Top P controls how many random results the model should consider for completion, as suggested by the temperature dial, thus determining the scope of randomness. Top P’s range is from 0 to 1. A lower value limits creativity, while a higher value expands its horizons.
- Frequency and Presence Penalty: The frequency penalty decreases the likelihood that the model will repeat the same line verbatim by “punishing” it. The presence penalty increases the likelihood that it will talk about new topics.
- Best of: This parameter lets you specify the number of completions (n) to generate on the server-side and returns the best of “n” completions.
- Stop Sequence: A stop sequence is a set of characters that signals the API to stop generating completions.
- Inject Start & Restart Text: The inject start text and inject restart text parameters allow you to insert text at the beginning or end of the completion, respectively.
- Show Probabilities: This option lets you debug the text prompt by showing the probability of tokens that the model can generate for a given input.
The OpenAI API offers four different execution engines that differ in the number of parameters used, performance capabilities, and price. The primary engines in increasing order of their capabilities and size are Ada (named after Ada Lovelace), Babbage (named after Charles Babbage), Curie (named after Madame Marie Curie) and Davinci (named after Leonardo da Vinci).
Based on the above four primary models, OpenAI has launched a series of improved models called InstructGPT, that are better at understanding the instructions and following them to produce the specific output as per your need. All you have to do is to tell the model what you want it to do and it will do its best to fulfill your instructions. The process of providing instructions to the GPT-3 model is called prompt engineering.
Prompt Engineering
GPT-3 is designed to be task agnostic. This means that it can potentially perform any number of tasks, given the specific training prompt. Creating AI solutions has never been easy but with GPT-3 all you need is a sensible training prompt in plain English language.

Source: Tweeted by Andrej Karpathy on June 18, 2020
The first and foremost thing to consider when creating a GPT-3 application is the design and content of the training prompt. Prompt design is the most significant process in priming the GPT-3 model to give a favorable and contextual response.
The prompt is the text input you give the model in order for it to generate the output you want. To design a good prompt is to give the model enough context on the task in the text input. GPT-3 looks at the input and attempts to respond with what text it thinks best completes the input.
In a way, prompt design is like playing a game of charades!
The secret to writing good prompts is understanding what GPT-3 knows about the world and how to get the model to use that information to generate useful results. In a game of charades, our goal is to give players just enough information to figure out the right word using their intelligence. In the same way, we must give GPT-3 just enough context in the form of a training prompt for the model to figure out the patterns and perform the task. We don't want to interrupt the natural intelligence flow of the model by overloading it with information, but giving it too little can lead to inaccurate results.
As a rule of thumb, when designing the training prompt you should aim towards getting a zero-shot response from the model. If that isn’t possible, move forward with a few examples rather than providing it with an entire corpus. The standard flow for training prompt design should look like:
Zero-Shot → Few Shots → Corpus-based Priming
If in your text input the model sees the letter “Q” and a question, it will attempt to write a response, but not necessarily the response you expect. Without sufficient context, it might assume for example that you’re writing a list of questions and wrong answers. If you want to get the best answer, you need to let GPT-3 know what kind of answers to provide.
Instead of asking GPT-3 to complete this input:
Q:
A:In which the first completion for us was:
Q:
A:
Q:
A:
You will majorly improve your output for questions by using a prompt like this (or some variation, depending on what type of questions you want the model to generate):
Write a few trivia questions.
Q:
A:
Where we get the following completion on the first try:
What is the name of the longest river in Africa?
The Nile
What are the top 5 most spoken languages in the world?
Mandarin, Spanish, English, Hindi, ArabicSimple instructions such as the above are enough to get GPT-3 to understand that it needs to give answers that are more in line with what you’re looking for; in this case, several trivia questions. You can also use a phrase like “Factual answer:” instead of “A:” to improve the result.
Write a few trivia questions.
Question:
Factual answer:To this input we got the following completion:
1. What is the world’s largest desert?
The Sahara desert.
2. What is the world’s deepest Ocean?
The Pacific Ocean.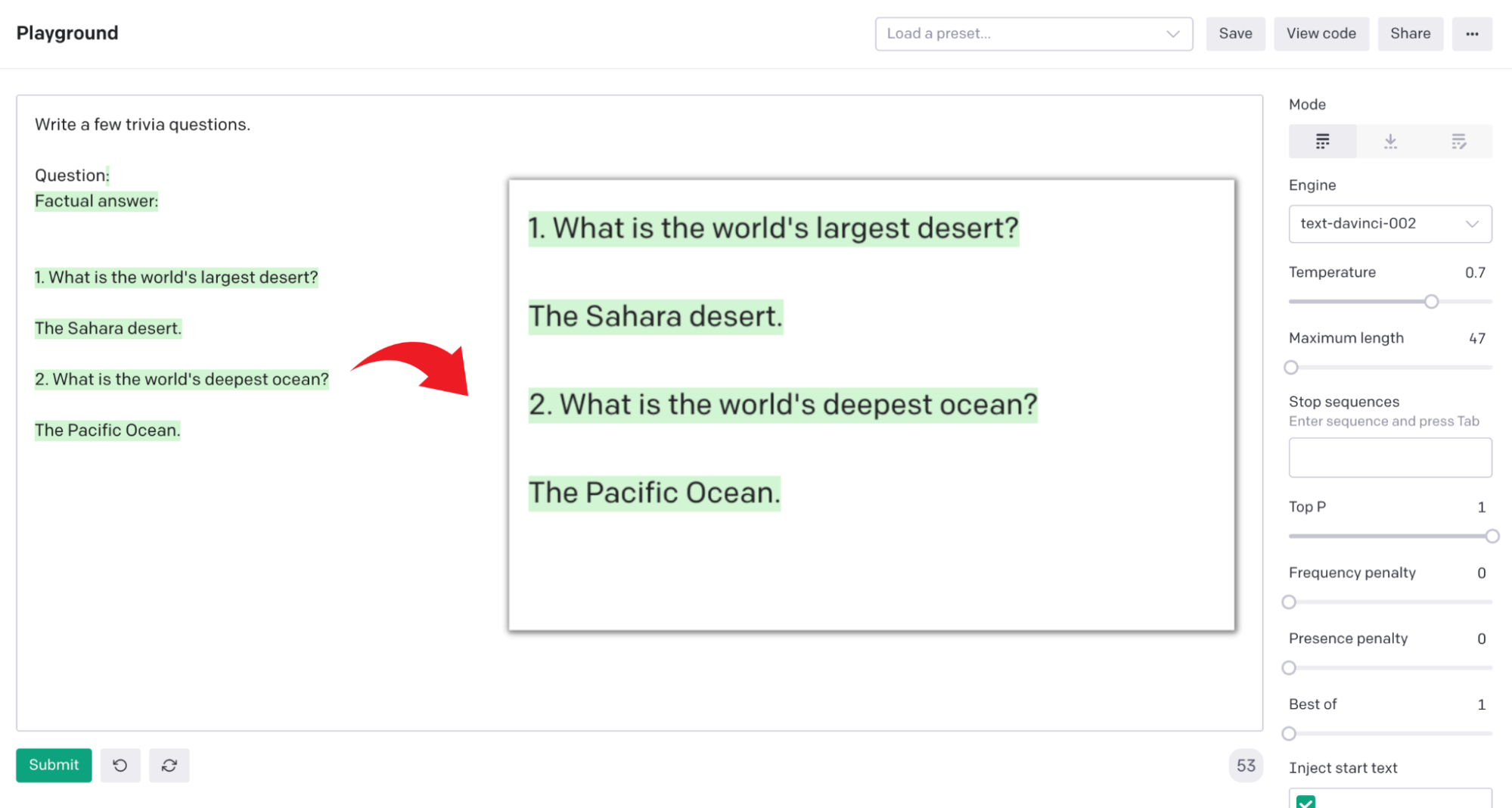
GPT-3 Sandbox—Using OpenAI API with Python
In this section, we will walk you through the GPT-3 Sandbox, an open-source tool to turn your ideas into reality with just a few lines of Python code. We’ll show you how to use it and how to customize it for your specific application. The goal of this sandbox is to empower you to create cool web applications, no matter what your technical background.
Follow this interactive video series for a step-by-step walkthrough about creating and deploying a GPT-3 application. You will need the following technical stack to use the GPT-3 sandbox:
- Python 3.7+
- An IDE, like VS Code
Clone the code from this repository by opening a new terminal in your IDE and using the following command:
git clone https://github.com/Shubhamsaboo/kairos_gpt3Everything you need to create and deploy a web application is already present in the code. You just need to tweak a few files to customize the sandbox for your specific use case. Now, create a Python virtual environment to get started. After creating the virtual environment, you can install the required dependencies using the following command:
pip install -r requirements.txtNow you can start customizing the sandbox code. The first file that you need to look at is training_data.py. Open that file and replace the default prompt with the training prompt you want to use. You can use the GPT-3 playground to experiment with different training prompts (see chapter 2 of the book and the following video for more on customizing the sandbox).
You’re now ready to tweak the API parameters (Maximum tokens, Execution Engine, Temperature, Top-p, Frequency Penalty, Stop Sequence). We recommend experimenting with different values of API parameters for a given training prompt in the playground to determine what values will work best for your use case. Once you get satisfactory results then you can alter the values in the training_service.py file.
That’s it! Your GPT-3 based web application is now ready. You can run it locally using the following command:
streamlit run gpt_app.pyYou can use Streamlit sharing to deploy the application and share it to a wider audience. Follow this video for a full walkthrough of deploying your application.
What Can You Build with GPT-3?
Before the release of GPT-3, most people’s interaction with AI was limited to certain specific tasks, like asking Alexa to play your favorite song or using Google Translate to converse in different languages. With the development of LLMs, we are looking at a significant paradigm shift. LLMs have shown us that by increasing the size of models, AI applications can perform creative and complex tasks similar to humans.
GPT-3 is powering the next wave of startups by fueling the imaginations of creative entrepreneurs with the right technology. Soon after OpenAI released the API, the startup landscape filled with companies using it to solve problems. Let’s explore this dynamic ecosystem by looking at some of the top-performing startups using GPT-3 at the core of their product in areas such as the creative arts, data analysis, chatbots, copywriting, and developer tools.
1. Creative Applications of GPT-3: Fable Studio
One of GPT-3’s most exciting capabilities is storytelling. You can give the model a topic and ask it to write a story in a zero-shot setting. The possibilities have writers expanding their imaginations and coming up with extraordinary work. For instance, the play AI, directed by Jennifer Tang and developed with Chinonyerem Odimba and Nina Segal, depicts a unique collaboration between human and computer minds with the help of GPT-3.
Fable Studio is a company utilizing the creative storytelling capabilities of the model. They have adapted Neil Gaiman and Dave McKean’s children’s book Wolves in the Walls into an Emmy Award-winning VR film experience. Lucy, the film’s protagonist, can have natural conversations with people thanks to dialogue generated by GPT-3. The company believes that down the road with upcoming iterations of the model, it is possible to develop an AI storyteller as skilled and creative as the best human writers.
2. Data Analysis Applications of GPT-3: Viable
Viable is a feedback aggregation tool that identifies themes, emotions, and sentiments in surveys, help desk tickets, live chat logs, and customer reviews. It then provides a summary of the results in a matter of seconds. For example, if asked, “What’s frustrating our customers about the checkout experience?” Viable might respond: “Customers are frustrated with the checkout flow because it takes too long to load. They also want a way to edit their address in checkout and save multiple payment methods.”
As you might expect from customer-feedback specialists, Viable has thumbs up and thumbs down buttons next to every answer the software generates. They use this feedback in retraining. Humans are part of the process, too: Viable has an annotation team whose members are responsible for building training datasets, both for internal models and GPT-3 fine-tuning. They use the current iteration of that fine-tuned model to generate output, which humans then assess for quality. If the output doesn’t make sense or isn’t accurate, they rewrite it. And once they have a list of outputs they are satisfied with, they feed that list back into the next iteration of the training dataset.
3. Chatbot Applications of GPT-3: Quickchat
Emerson AI is the company Quickchat's chatbot persona and is known for its general world knowledge, support of multiple languages, and ability to carry on a conversation. Emerson AI is used to showcase the capabilities of GPT-3 powered chatbots and encourage users to work with Quickchat on implementing such a persona for their companies. Quickchat's product offering is a general-purpose conversational AI that can talk about any subject. Customers can customize the chatbot by adding extra information specific to their product. Quickchat has seen diverse applications, such as automating customer support and implementing an AI persona to help users search for an internal company knowledge base.
Unlike typical chatbot service providers, Quickchat does not build any conversation trees or rigid scenarios, nor does it need to teach the chatbot to answer questions in a given way. Instead, customers follow a simple process: you copy-paste text that contains all the information that you want your AI to be using and click on the retrain button, which takes a few seconds to absorb the knowledge, and that's it. Now trained on your data, the chatbot is ready to have a test conversation.
4. Marketing Applications of GPT-3: Copysmith
One of the most popular applications of GPT-3 is to generate creative content on the fly. Copysmith is one such example of a content generation platform. It uses GPT-3 for generating prompts that are then turned into copy for e-commerce businesses. GPT-3 seems to shine in the area of marketing, where it helps to generate, collaborate and launch quality content at lightning speed. Thanks to the model, online small and medium-size businesses can write better calls-to-action and product descriptions, and level up their marketing game to get it off the ground.
5. Coding Applications of GPT-3: Stenography
Bram Adams, an OpenAI Community Ambassador, created Stenography, a program that uses GPT-3 and Codex to automate the process of writing code documentation.
Stenography was an instant success, launching as the #1 product on ProductHunt. Adams sees documentation as a way for people to reach out to other people on their teams, their future selves, or just interested people who stumble across a dev project on GitHub. The goal of Stenography is to make a project understandable to others.
To learn more about the rising GPT-3 ecosystem, check out Chapter-4 (GPT-3 as a Launchpad for Next-Gen Startups) and Chapter-5 (GPT-3 for Corporations) of our upcoming O’Reilly book.
Conclusion
- GPT-3 marks an important milestone in the history of AI. It is also a part of a bigger LLM trend that will continue to grow forward in the future. The revolutionary step of providing API access has created the new model-as-a-service business model.
- GPT-3’s general language-based capabilities open the doors to building innovative products. It is especially good at solving tasks such as text generation, text summarization, classification, and conversation.
- There are a number of successful companies built largely or entirely on GPT-3. Our favorite use cases are creative storytelling, data analysis, chatbots, marketing copywriting, and developer tools.






