
Course
Foundations of Functional Programming with purrr
4 hr
11.3K
Good structure is a hallmark of well-written code. The nature of this structure is determined by the programming paradigm used. A programming paradigm is a coherent set of principles and techniques defining the approach taken when designing and coding computer programs.
There are many programming paradigms, such as procedural, imperative, declarative, object-oriented, and functional. Some languages are restricted to only a few paradigms. For example, SQL is a language that is a declarative language. However, many modern languages, including Python, support several programming paradigms, allowing for flexibility.
Practice writing pure functions with a hands-on exercise from our Introduction to Programming Paradigms course.
Many programmers default to a preferred programming paradigm, often the one they learned first. More advanced programmers understand the advantages and weaknesses of these programming paradigms and can leverage each of their strengths in different scenarios. Let’s go over two of the most commonly used programming paradigms in data science: functional programming and object-oriented programming.

In functional programming, code is constructed by defining and using functions that dictate how the program should operate. It is a subtype of the declarative programming paradigm.
Functions are lines of code that take in arguments and return outputs. A simple function may take a number list as an argument and return only the even values, for example.
def get_even_numbers(list):
return [num for num in list if num % 2 == 0]Check out these courses to learn the best practices for writing functions in Python and R.
Functional programming stands out because of its traceability and predictability. This is because the functions used are immutable, meaning they can’t be altered. Functions are defined, often in a separate section of the code (or sometimes in a different file), and then used throughout the code as needed. This attribute makes it easy to determine what is happening in a section of code, as the function performs the same way and is called in the same way everywhere.
The concept of immutability extends to data structures in functional programming. In FP, it is preferred to create a copy of the data when changing its state. This establishes a virtual paper trail of all transformations applied to the data, enhancing traceability and simplifying the identification of issues. However, it's important to note that this approach often results in increased memory consumption, as each state change involves copying the entire dataset.
A subset of functions used in functional programming are higher-order functions. These are functions that take in a function as an argument or return a function as a result. For example, you may have a higher-order function that runs a function multiple times, such as the one shown below, or one that chooses the correct function to use in a specific scenario.
def run_function_multiple_times(function, num_times):
for i in range(num_times):
function()Functional programming provides a structure for reducing duplication in your code. The goal of functional programming is to make it easy to express repeated actions using high-level verbs.
For example, say you need to modify strings to fit a particular format in several different places in your code. This format requires you to remove spaces, punctuation, and numbers and make everything lowercase. You could copy and paste several lines of code in different parts of your program as needed. But this duplication would bloat your code. Instead, you can simply define a function to modify your strings and call that function in the appropriate places. This streamlines your code to make it slimmer, more readable, and faster to type.
def clean_string(string):
exclude = set(string.punctuation + string.digits + " ")
return ''.join(ch.lower() for ch in string if ch not in exclude)
my_string = "Hello, World! 123"
new_string = clean_string(my_string)
print(new_string)Functional programming is useful when working with large datasets or data pipelines because it allows us to break down complex data processing tasks into smaller, more manageable steps. Often, at least one function will be created for each step along the pipeline. If you have written down a flow chart of the steps you need in your pipeline, you will have a rough idea of which functions you will need. Broadly speaking, you will need at least one function for each step.
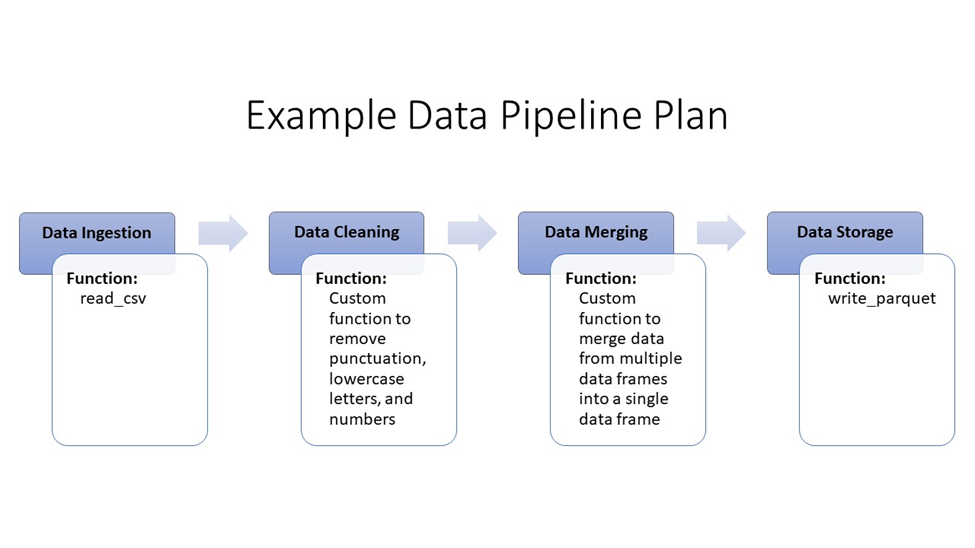
Most languages also have many built-in functions and downloadable libraries of extra functions. The purr package in R is a great example. This makes it easier to quickly build a pipeline while minimizing the number of custom functions you need to create.
Functional programming aims to make very readable code. There are a few guidelines to building expressive and readable code using functional programming:
Object-oriented programming is a paradigm that focuses on objects. Objects are self-contained entities that consist of both data and methods that operate on that data. It’s a way of keeping the data and their operations near each other, unlike functional programming, where they are often separated. This can make it easier to follow what is happening to your data.
In object-oriented programming, data and methods are organized into objects that are defined by their class. Classes are designed to dictate how each object should behave, and then objects are designed within that class. Check out DataCamp’s tutorial for more details on how classes work in Python.
For example, you may have a class called BankAccount that describes how each account should behave. This class can have attributes such as balance, ID number, and customer name. It can also have methods that describe how information within that class can be affected, such as withdrawal, deposit, and check balance.
Once this class has been defined, you can create an object, in this case, an account for someone. Once this object has been created, you can populate it with the data for each property and use the methods to modify the account. See the example below.
# Define a class representing a bank account
class BankAccount:
def __init__(self, account_id, customer_name, initial_balance=0.0):
# Initialize account properties
self.account_id = account_id
self.customer_name = customer_name
self.balance = initial_balance
# Method to deposit money into the account
def deposit(self, amount):
"""Deposit money into the account."""
if amount > 0:
# Update balance and print deposit information
self.balance += amount
print(f"Deposited ${amount}. New balance: ${self.balance}")
else:
# Print message for invalid deposit amount
print("Invalid deposit amount. Please deposit a positive amount.")
# Method to withdraw money from the account
def withdraw(self, amount):
"""Withdraw money from the account."""
if 0 < amount <= self.balance:
# Update balance and print withdrawal information
self.balance -= amount
print(f"Withdrew ${amount}. New balance: ${self.balance}")
elif amount > self.balance:
# Print message for insufficient funds
print("Insufficient funds. Withdrawal canceled.")
else:
# Print message for invalid withdrawal amount
print("Invalid withdrawal amount. Please withdraw a positive amount.")
# Method to check the current balance of the account
def check_balance(self):
"""Check the current balance of the account."""
print(f"Current balance for {self.customer_name}'s account (ID: {self.account_id}): ${self.balance}")This process of bundling your data and behavior into an object defined by a class is called encapsulation. It allows you to create a well-defined structure that allows the rest of the code to easily interact with the object. The variables that are stored within the object are called attributes, and the functions that determine the behavior of the object are called methods.
One way to reduce code duplication is to use inheritance when creating new classes. This is a way of creating new classes that retain the functionality of parent classes. In our bank account example, you could have a parent class generalized for all accounts and child classes with specifics for savings accounts and checking accounts.
Polymorphism is a concept that allows you to use the same name for different methods that have different behaviors depending on the input. This is commonly used with inheritance.
For example, say we have a parent class called Shape that has a method to calculate the area of the shape. You may have two child classes, Circle and Square. While each will have the method called Area, the definition of that method will be different for each shape. Compare the methods for area for the different shapes in the code block below.
# Define the parent class Shape
class Shape:
# Initialize the attributes for the shape
def __init__(self, name):
self.name = name
# Define a generic method for calculating the area
def area(self):
print(f"The area of {self.name} is unknown.")
# Define the child class Circle that inherits from Shape
class Circle(Shape):
# Initialize the attributes for the circle
def __init__(self, name, radius):
# Call the parent class constructor
super().__init__(name)
self.radius = radius
# Override the area method for the circle
def area(self):
# Use the formula pi * r^2
area = 3.14 * self.radius ** 2
print(f"The area of {self.name} is {area}.")
# Define the child class Square that inherits from Shape
class Square(Shape):
# Initialize the attributes for the square
def __init__(self, name, side):
# Call the parent class constructor
super().__init__(name)
self.side = side
# Override the area method for the square
def area(self):
# Use the formula s^2
area = self.side ** 2
print(f"The area of {self.name} is {area}.")There are several resources for learning how to use object-oriented programming including DataCamp’s OOP in Python course, OOP in R course, and OOP in Python tutorial.
Object-Oriented Programming can offer several advantages to data analysis:
There are many factors to consider when choosing to use either OOP or FP for your data project. Some data teams may strongly prefer one paradigm over the other, in which case, matching your paradigm with that of your team is preferred. In other cases, the nature of your data or applications may tip the scales in one direction or the other.
Object-oriented programming is excellent for applications where you need to model entities. Great examples include designing a system for managing a library or creating a system to score every company in an investment portfolio. The process of creating encapsulated objects makes it easy to keep track of these entities. OOP is also preferred when you have limited memory, as FP tends to require much more memory than OOP.
Functional programming excels at data analysis tasks that require parallel processing. The focus on immutability and avoiding side effects makes it easier to parallelize operations on a dataset. Functions can be applied concurrently on different parts of the data without interference.
FP’s focus on immutability also makes it ideal for data transformation pipelines. Functions can be composed to create a series of transformations without mutating state, leading to more readable and maintainable code.
FP is also generally preferred by scientists and academics as it maintains more of a pure mathematics focus.
In some practical applications, OOP and FP can be combined in a program. This allows developers to leverage the strengths of each paradigm. The encapsulation of OOP and the expressiveness of FP can both be leveraged to build a machine learning pipeline or web application.
However, combining paradigms like this can pose challenges and must be done with caution. It can be harder to decipher code that jumps between multiple paradigms. It can also be challenging to ensure smooth integration of the components.
Consider the example below. This python code combines OOP and FP, to perform mathematical operations on a list of numbers. The MathOperation class acts like a container for a specific math operation created using FP. The functions filter_odd_numbers and square_operation help filter odd numbers and calculate the square of a number, respectively. By using these components together, the code efficiently filters odd numbers from a given list and then squares them, demonstrating how OOP and FP can work together to simplify and organize data analysis tasks.
# Object-Oriented Programming (OOP) - Class Definition
class MathOperation:
def __init__(self, operation):
self.operation = operation
def apply_operation(self, number):
return self.operation(number)
# Functional Programming (FP) - Higher-Order Functions
def filter_odd_numbers(numbers):
return list(filter(lambda x: x % 2 != 0, numbers))
def square_operation(number):
return number ** 2
def process_numbers(numbers, operation_function):
return list(map(operation_function, numbers))
# Example Usage:
# Define an OOP class representing a mathematical operation (square in this case)
square_operation_instance = MathOperation(square_operation)
# Sample list of numbers
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# Use FP to filter odd numbers
odd_numbers = filter_odd_numbers(numbers)
# Use OOP to apply the square operation to odd numbers
result = process_numbers(odd_numbers, square_operation_instance.apply_operation)
# Display the result
print(result)For another example of using both OOP and FP together, check out this github repository.
There is no definitive answer to which programming paradigm is the best choice, as it depends on the context, the goal, the language, and the programmer’s preference. However, there are some general guidelines you can follow to determine which paradigm will work best for your situation.
Use OOP when you need to model complex systems with multiple entities and interactions, and when you need to encapsulate data and behavior into reusable components. Use FP when you need to perform pure calculations with simple inputs and outputs, and when you need to avoid side effects or state changes. Use a mixed approach when you need to leverage the strengths of both paradigms, and when you need to adapt to the features and limitations of the language.
The best programmers aren’t restricted to one paradigm or the other; they can move between paradigms as necessary to accomplish their goals. Explore a range of paradigms in-depth with the Introduction to Programming Paradigms course. Try working on a data project and use both OOP and FP to solve the project. Practicing each paradigm will give you a good intuition for which will work best for your project.
Start Your Programming Paradigms Journey Today!
Course
Course
Course
blog
Samuel Shaibu
12 min
blog
Bex Tuychiev
12 min
blog
Javier Canales Luna
13 min
Tutorial
Olivia Smith
Tutorial
Aditya Sharma
Tutorial
Théo Vanderheyden
