Tracks
Cơ bản về Trợ lý Trí tuệ Nhân tạo
6 giờ
AI agents are no longer limited to chat. Today, they can plan tasks, call tools, navigate repositories, and execute multi-step workflows across your codebase and infrastructure. As these systems grow more capable, the underlying model increasingly determines how reliable and scalable your agents will be.
Choosing the wrong model for an agent workflow can cost you performance, money, infrastructure overhead, and developer time.
In February 2026, two major models launched within days of each other. GLM-5 and GPT-5.3-Codex, both designed for autonomous agents but built around very different architectures, openness, and deployment.
In this article, I compare GLM-5 and GPT-5.3-Codex across architecture, benchmarks, and deployment trade-offs to help you decide which model fits your agent workflows.
If you’re new to autonomous agents, our AI Agent Fundamentals skill track introduces the core ideas behind planning loops, tool use, and agent orchestration.
GLM-5 and GPT-5.3-Codex both target long-running AI agents, but follow different design philosophies. GLM-5 prioritizes open-weight scalability and flexible deployment, while GPT-5.3-Codex runs through OpenAI’s managed cloud infrastructure and developer tooling.
GLM-5 is Zhipu AI’s (Z.ai) fifth-generation General Language Model (GLM) built for agents that plan tasks, call tools, and operate across large codebases and datasets.
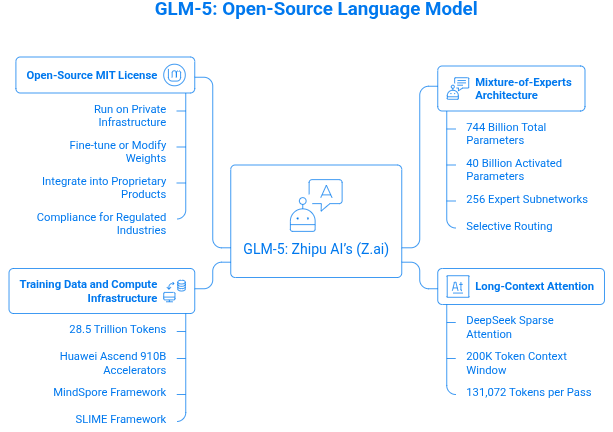
Snapshot of GLM-5 spec: Designed with Napkin AI
GLM-5 uses a Mixture-of-Experts (MoE) architecture with 744 billion total parameters, but only about 40 billion are activated during inference. Each token is routed through 8 of the model’s 256 expert subnetworks, allowing the model to scale its capacity without running the full parameter set every time.
Selective routing is the key efficiency trick. Instead of processing every parameter on every token, the model activates only the specialists needed for the task. The result is a system that behaves like a massive model while keeping compute resources manageable and reasoning performance strong.
GLM-5 also integrates DeepSeek Sparse Attention (DSA). It prioritizes the most relevant tokens instead of processing the full sequence uniformly. That enables it to handle a 200K token context window with outputs of up to 131,072 tokens per pass, large enough to analyze full repositories, research papers, or enterprise document archives without chunking.
GLM-5 was pre-trained on 28.5 trillion tokens across web, code, math, and scientific datasets.
Overall training pipeline of GLM-5
Training ran on Huawei Ascend 910B accelerators using the MindSpore framework, making it one of the largest frontier models trained without NVIDIA hardware.
For post-training, Zhipu AI introduced SLIME, an asynchronous reinforcement learning framework. Instead of tightly coupling rollout generation with model updates, SLIME runs these steps in parallel, significantly increasing training throughput and iteration speed.
This setup allows GLM-5 to learn reliable tool use and sustained multi-step planning behaviors, rather than single-prompt tasks.
GLM-5 is released under the MIT license, which makes the weights fully usable in commercial systems. This means you can:
For teams in regulated industries like healthcare, finance, or legal systems, this removes the core compliance objection to frontier AI. Sensitive data can stay inside your own infrastructure instead of passing through an external API.
Model weights are available on Hugging Face and ModelScope. You can follow our tutorial on how to run GLM-5 locally on a single GPU with llama.cpp.
At launch, GPT-5.3-Codex was OpenAI's most advanced model for agent-driven engineering tasks. It merges the coding performance of GPT-5.2-Codex with the broader reasoning capabilities of GPT-5.2, creating a single model designed to plan, execute, and iterate across long-running development tasks.
Snapshot of GPT-5.3-Codex spec: Designed in Napkin AI
The shift is subtle but important. Earlier Codex models focused on generating code snippets. GPT-5.3-Codex is built to operate more like a software agent. It can research problems, edit files, run tools, and iterate on solutions across extended execution loops.
For a deeper technical overview, see our hands-on breakdown of GPT-5.3-Codex.
GPT-5.3-Codex supports a 400K token context window, allowing it to reason across large repositories or long development sessions without repeatedly reloading context.
For agent workflows, this changes how the model operates. Instead of focusing on isolated files, it can maintain awareness across an entire project, enabling it to perform tasks like:
The model can treat an entire codebase as a working context rather than a sequence of fragmented prompts.
GPT-5.3-Codex also accepts both text and image inputs, allowing you to combine source code with screenshots, diagrams, and terminal output in a single reasoning loop. This capability becomes particularly useful when diagnosing issues that span several layers of a system.
For instance, a frontend issue might appear visually in the interface while the root cause sits in backend logic. Instead of translating that problem into text, you can provide the screenshot alongside logs and source files.
That additional context often shortens the debugging cycle because the model sees the same signals you would as a developer.
OpenAI also improved the model’s inference pipeline, making GPT-5.3-Codex roughly 25 percent faster than GPT-5.2-Codex.
In long agent sessions where the model may read files, run tests, edit code, and debug repeatedly, that speed is crucial.
Faster responses keep the feedback loop tight and reduce idle time while supervising the agent. You can see progress sooner, catch issues earlier, and the whole iteration feels more like working with a colleague than waiting on a batch job.
One of the model’s most distinctive features of GPT-5.3-Codex is its interactive steering.
You can intervene while the model is working, ask questions, redirect its approach, or introduce new constraints, without resetting its reasoning state.
Instead of waiting for a final answer, the system continuously reports progress and surfaces decisions as it works. The workflow becomes a collaborative loop rather than a single request and response.
You can learn about its live steering feature and see it in action on our hands-on exploration of GPT-5.3-Codex.
A model's architecture tells you how it's built. Benchmarks tell you how they behave in real agent workflows. In this section, I'll walk you through the benchmarks that matter most for agentic use cases.
Recent agent benchmarks increasingly evaluate whether a model can sustain reasoning across dozens or hundreds of steps, not just produce a correct answer in one pass.
That difference matters. Real systems require planning, tool use, and iteration under uncertainty.
GDPVal-AA evaluates how well models perform on economically valuable professional tasks when given tool access.
At launch, GLM-5 earned an ELO score of 1412, becoming the first open-weight model to enter the top tier of this agentic ranking, ahead of many large closed systems.
It ranked behind only frontier closed models like Claude Opus 4.6 and GPT-5.2 as per Artificial Analysis.
GLM-5's GDPval value of 1412 on Artificial Analysis
GPT-5.3-Codex posted 70.9% wins or ties on GDPval as posted on OpenAI's launch appendix.
Vending Bench 2 evaluates a model's ability to sustain business decisions across hundreds of sequential steps without human assistance.
On this benchmark:
That difference suggests stronger long-horizon operational consistency, where the model must track strategy and resource allocation over extended decision chains.
SWE-bench evaluates whether a model can resolve real GitHub issues in production codebases, requiring code comprehension, editing, and validation across an entire repository. The SWE-bench Pro variant raises the difficulty ceiling with harder, less-saturated issues.
On SWE-bench Pro, GPT-5.3-Codex scored 56.8%. That value shows the model's ability to hold a coherent understanding of a large, unfamiliar codebase across an hours-long task, track how one change affects another, and avoid introducing regressions mid-fix.
That capability is more like how you would work when you step into a large, unfamiliar codebase, keeping track of how one change affects another while maintaining the whole system.
At release, GLM-5 scored 77.8% on SWE-bench Verified, a separate benchmark that evaluates a smaller, human-validated subset of tasks. Because it differs from SWE-Bench Pro, the scores are not directly comparable. On SWE-Bench Verified, GLM-5 recorded the strongest reported result among open-weight models.
Terminal-Bench 2.0 stress-tests whether a model can operate autonomously inside a command-line environment.
Tasks involve multi-step terminal sessions like installing dependencies, running scripts, debugging failures, and iterating until the objective is complete.
GLM-5 had 56.2%, depending on the evaluation configuration, the strongest result any open-source model has posted on this benchmark.
Terminal-Bench 2.0 value of GLM-5 from Z.ai's official documentation
From the official OpenAI numbers, GPT-5.3-Codex scores 77.3%. A significant jump from GPT-5.2-Codex's 64.0% and well above GLM-5's score, demonstrating a strong ability to operate in a command‑line environment.
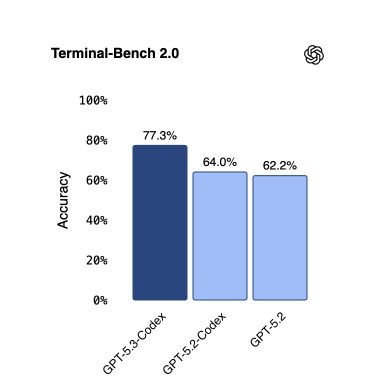
GPT-5.3-Codex Terminal-Bench 2.0 score from OpenAI
In agent pipelines, hallucinations, like fabricating facts like API endpoints or file paths, can silently break workflows. How a model deals with uncertainty is critical.
According to Artificial Analysis, GLM-5 scores -1 on the AA-Omniscience Index, a 35-point improvement over its predecessor GLM-4.7 (which scored -36), driven by a 56 percentage-point reduction in hallucination rate.
The AA-Omniscience benchmark scores models from -100 to 100, rewarding correct answers, penalizing hallucinations, and applying no penalty for abstention.
The model accomplishes one of the lowest hallucination rates among models tested by abstaining when unsure rather than producing incorrect outputs, a reliability advantage in unknown or proprietary environments.
Snapshot of Omniscience Index and Hallucination rate
For agent workflows operating against undocumented internal APIs or domain-specific systems, this abstention over fabrication behavior is a critical reliability advantage.
GPT-5.3-Codex implements self-correction. When it goes wrong, it knows, and it iterates through test-debug-revise cycles. OpenAI demonstrated this during development itself, where early versions root-caused failures in their own training pipelines.
The choice between these two approaches is a function of your pipeline's risk profile. Unknown territory, undocumented endpoints, proprietary systems, domain-specific edge cases favor GLM-5's abstention-first behavior.
Well-defined technical environments where autonomous recovery matters more than conservative caution favor GPT-5.3-Codex's self-correction loop.
How expensive it is to run a model and how easily it integrates with an existing stack are crucial points to consider when building real agentic systems.
In this section, I'll compare the actual costs of running these models at scale.
At the API level, the two models sit in very different pricing tiers.
According to Z.AI's official pricing documentation and OpenRouter, here is the current cost comparison:
GPT-5.3-Codex output is approximately 4.4 times more expensive per token compared to GLM-5. For agent systems that generate large volumes of intermediate reasoning, logs, and code edits, this gap compounds quickly as workloads scale.
GLM-5 can be self-hosted, eliminating per-token API costs once the infrastructure is in place. The trade-off is the scale of hardware required.
The BF16 checkpoint alone is roughly 1.5 TB, which puts local deployment far beyond typical consumer hardware. Production inference requires multiple high-end GPUs, such as NVIDIA B200-class accelerators or comparable clusters, to load and serve the model efficiently.
For a practical walkthrough on how to run it locally, see our guide on running GLM-5 locally using a 2-bit GGUF quant on an NVIDIA H200 pod and serving it through llama.cpp.
GPT-5.3-Codex is strictly API-based. No self-hosting option exists. You can access it through OpenAI’s cloud infrastructure and accessible through ChatGPT paid tiers or the OpenAI developer APIs. You do not manage GPUs, inference pipelines, or model updates.
If you need ultra-fast response times, you can also explore lightweight variants such as GPT-5.3-Instant, which prioritize latency over maximum reasoning depth.
Both models integrate into modern AI development workflows, but they reach the ecosystem through different paths. GLM-5 focuses on API compatibility, while GPT-5.3-Codex integrates directly into OpenAI’s native tooling environment.
GLM-5 fits easily into the current AI development ecosystem because it exposes an OpenAI-compatible API.
You can use the same request formats and SDKs already in your stack. In some cases, integrating it requires little more than updating the base endpoint to https://api.z.ai/api/paas/v4 (for general use) or https://api.z.ai/api/coding/paas/v4 (for coding) and setting the model name to glm-5.
Z.AI endpoint for use with GLM-5 model
Since the interface mirrors the OpenAI API, GLM-5 plugs directly into many existing agent frameworks.
For instance, OpenClaw supports GLM models through the Z.AI provider. After configuring a Z.AI API key, you can reference the GLM-5 as zai/glm-5.
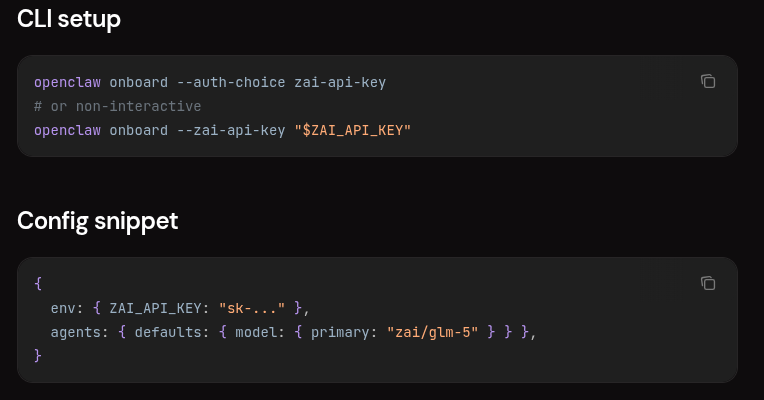
OpenClaw support for GLM-5 model
The same compatibility makes GLM-5 straightforward to integrate into application frameworks. For instance, if you have built pipelines with the Vercel AI SDK that already target the OpenAI interface, you can route requests to the Z.AI endpoint with minimal changes.
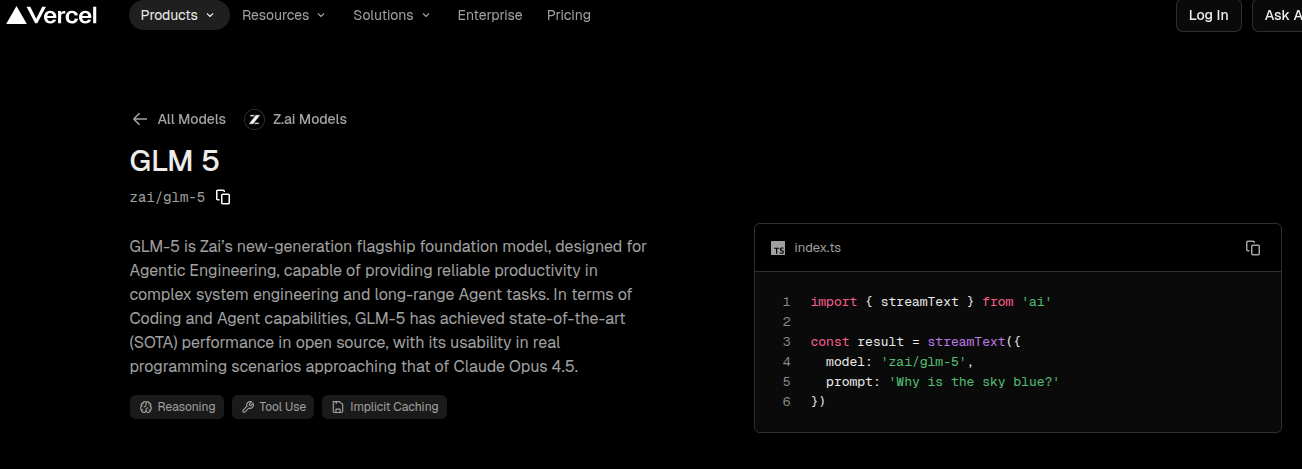
Vercel support for GLM-5 model
If you use AI coding editors like Cursor you can configure a custom OpenAI-style endpoint. This lets you experiment with GLM-5 inside the same development environment you already use for other models.
GPT-5.3-Codex does not rely on API compatibility layers. It integrates directly into OpenAI's development ecosystem. The model powers native workflows through tools such as the Codex CLI, the Codex desktop application, and official extensions for VS Code and JetBrains IDEs.
The model, tools, and execution environment are designed to operate together as a single system, which reduces setup complexity but keeps the workflow fully tied to OpenAI's platform.
GPT-5.3-Codex-Spark runs on Cerebras Wafer-Scale Engine hardware, capable of generating over 1,000 tokens per second with a smaller 128K context window. Its goal is to give near-instant responses during active coding sessions.
GLM-5 does not currently ship with a dedicated ultra-low-latency variant similar to Codex-Spark. Inference speed depends on the infrastructure serving the model. Artificial Analysis shows a FP8 median output rate of around 62.2 tokens per second across providers.
The following table summarizes the key differences between the two models.
|
Feature |
GLM-5 |
GPT-5.3-Codex |
|
Provider |
Zhipu AI (Z.AI) |
OpenAI |
|
Release Date |
February 11, 2026 |
February 5, 2026 |
|
Architecture |
744B MoE (40B active) |
Proprietary dense transformer (undisclosed) |
|
Context Window |
200K tokens |
400K tokens |
|
Max Output |
128K tokens |
128K tokens |
|
Multimodal Input |
Text only |
Text + Image |
|
License |
MIT (open weights) |
Proprietary (API only) |
|
Self-Hosting |
Yes |
No |
|
API Input Price |
$1.00/M tokens |
$1.75/M tokens |
|
API Output Price |
$3.20/M tokens |
$14.00/M tokens |
|
SWE-Bench |
77.8% |
56.8% (SOTA) |
|
Terminal-Bench 2.0 |
56.2% |
77.3% (SOTA) |
|
Vending Bench 2 |
$4,432 |
$5,940 |
|
AA-Omniscience Index |
-1 (lowest hallucination tested) |
Not published |
|
Interaction Mode |
Autonomous / API-driven |
Interactive steering (real-time) |
|
Ultra-Fast Variant |
FP8 ~60 t/s via Artificial Analysis |
GPT-5.3-Codex-Spark (1,000+ t/s) |
After walking through architectures, benchmarks, deployment, and costs, the key question is simple. When should you pick one model over the other for autonomous agent workflows?
Your choice hinges not on brand but on what matters most for your use case, whether that's cost, data control, interaction style, or workflow complexity.

GLM-5 versus GPT-5.3-Codex at a glance. Designed with Napkin AI.
Both models are legitimate frontier choices for agent work in 2026. The decision is not "open or proprietary?" It is the tradeoffs your specific workflow can and cannot absorb.
If you want control, lower operating costs, and cautious behavior in unknown environments, GLM‑5 is the more practical foundation for your agents.
There’s no universal “better” model, only the model that matches your workflow trade‑offs.
The decision is rarely “open vs proprietary.” It’s more often “what trade‑offs matter most for your agents?” Whether that’s cost and control or developer productivity and execution coherence, one of these models will fit your needs.
If you’re interested in building AI agentic workflows, I recommend our Building Agentic Workflows with LlamaIndex course to learn how to build AI agentic workflows that can plan, search, and remember. You can also explore the concepts and capabilities of agentic tools in our AI Agent Fundamentals skill track.
Top DataCamp Courses
Tracks
Courses
Courses
blogs
Derrick Mwiti
9 phút
blogs
Tom Farnschläder
9 phút
blogs
Josef Waples
10 phút
blogs
Vinod Chugani
10 phút
blogs
Alex Olteanu
8 phút
Tutorials
Abid Ali Awan