Introduction to Machine Learning Inference
Imagine you have trained an amazing machine learning model to help the business team attract more clients by making relevant recommendations. The most logical next step is to incorporate the trained model into the company’s infrastructure so that it can be used by the business to make predictions on new clients’ information. The process of using such an existing model is known as inference.
Machine learning inference is crucial because it allows the model to be used for real-world use cases such as predictions, classifications, or recommendations.
At the end of this blog, you will have a better understanding of how machine learning inference works, how it differentiates from traditional machine learning training, and an overview of the existing inference approaches, along with their benefits, challenges, and some applications in real life.
Machine Learning Inference vs Training
The first thing to keep in mind is that machine learning inference and machine learning training are not the same, and each concept is applied in two different phases of any machine learning project. This section provides an intuitive explanation to highlight their differences through the restaurant analogy by Cassie Kozyrkov.
She mentioned that making a good pizza (a valuable product) requires a recipe (model or formula) that tells how to prepare the ingredients (quality data) with what appliances (algorithms).
There would be no service if no food came from the kitchen. Also, the kitchen (Data Science Team) will not be valuable if clients constantly don’t appreciate the food.
For a good customer experience and better return on investment, both teams work together.
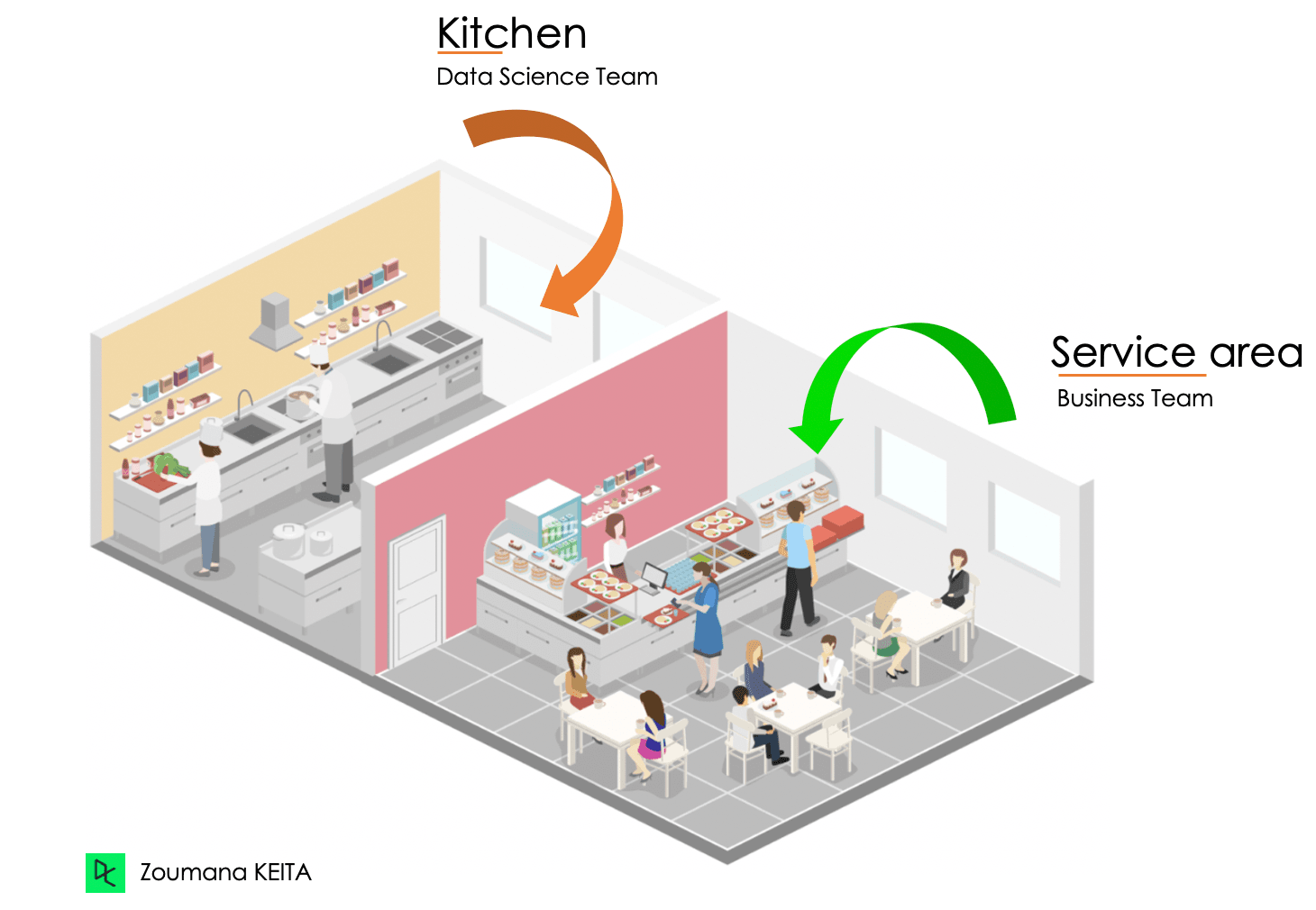
Kitchen (Data Science Team) & Service Area (Business Team)
Machine learning training
Training a machine learning model requires the use of training and validation data. The training data is used to develop the model, whereas the validation data is used to fine-tune the model’s parameters and make it as robust as possible. This means that at the end of the training phase, the model should be able to predict new data with fewer errors. We can consider this phase as the kitchen side.
From our comprehensive guide, What is Machine Learning, you will learn what machine learning is and how it differs from AI and deep learning, and why it is one of the most exciting fields in data science.
Machine learning inference
Dishes can only be served when they are ready to be consumed, just as the machine learning model needs to be trained and validated before it can be used to make predictions. Machine learning inference is similar to the scenario of a restaurant. Both need attention for better and more accurate results, hence customer and business satisfaction.
Importance of Understanding the Differences
Knowing the difference between machine learning inference and training is crucial because it can help better allocate the computation resources for both training and inference once deployed into the production environment.
The model performance usually decreases in the production environment. A proper understanding of the difference can help in adopting the right industrialization strategies of the models and maintaining them over time.
Key Considerations when choosing between Inference and Training
Using an inference model or training a brand new model depends on the type of problem, the end goal, and the existing resources.
The key considerations include, but are not limited to time to market, resources constraint or development cost, model performance, and team expertise.
- Time to market. It is important to consider how much is available when choosing between training and using an existing model. Sometimes, using a pre-trained model requires less time and may provide a business team with a competitive advantage.
- Resources constraints or development cost. Depending on the use case, training a model can require a significant amount of data and training resources. However, using an inference model most of the time requires fewer resources, which makes it easier to obtain even better performance in a short amount of time.
- Model performance. Training a machine learning model is an iterative process, and does not always guarantee a robust model. Using an inference model can provide better performance compared to an in-house model. Nowadays, model explainability and bias mitigation are crucial, and inference models may need to be updated to consider those capabilities.
- Team expertise. Building a robust machine learning model requires strong expertise for both model training and industrialization. It can be challenging to have that expertise already available; hence relying on inference models can be the best alternative.
Bayesian Inference in Machine Learning
Bayesian inference is a technique in machine learning that enables algorithms to make predictions by updating their prior knowledge based on new evidence using Bayes' theorem.
But what is Bayes' theorem?
It describes the probabilities of event A, given that another event, B, has occurred. The formula is given below:
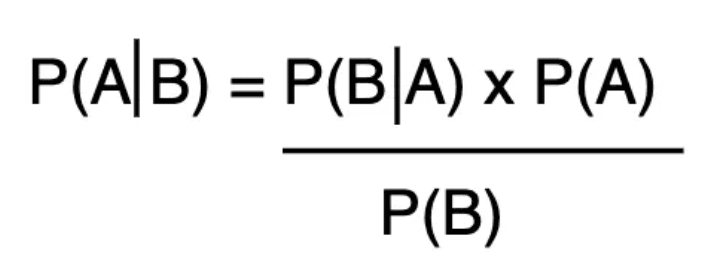
Bayes Theorem
P(A): prior → the probability that event A occurs without any knowledge of other events.
P(B): the normalizing constant that allows the computation of the posterior event B.
P(A|B): posterior → the probability of event A occurring, given another event B occurs.
P(B|A): likelihood → the probability of event B occurring if A occurs.
With this information, let’s explore the advantages of Bayesian inference and some applications in real life.
From our Naive Bayes Classification Tutorial using Scikit-learn, you will learn how to build and evaluate a Naive Bayes classifier using Python’s Scikit-learn package.
Advantages of Bayesian Inference
Bayesian inference has multiple advantages, and not limited to:
- Flexibility. Bayesian inference can be applied to both linear and non-linear models and various machine learning problems such as regression, classification, clustering, natural language processing and more.
- More intuitive. The transition from prior to posterior knowledge using new data is similar to the way human beings update their beliefs using new information, which is more intuitive. For instance, if someone has the prior knowledge that it will snow tomorrow, and checks the weather information, that person will change that belief accordingly.
- Interpretable. The probability distributions generated over the possible values of the model predictions can be easily interpreted, which can help decision-makers make decisions with respect to their tolerance for risk.
Applications of Bayesian Inference in Machine Learning
Below are some of the real-world applications of Bayes inference in machine learning:
- Credit card fraud detection. Bayes inference can be applied to detect fraudulent activities. The process begins with a prior belief about the probability of a transaction being fraudulent based on historical data. Then, as new data becomes available, such as the transaction amount, or the customer's purchase history, the prior information is updated using Bayes' theorem to obtain a posterior probability of a transaction; to determine whether it is fraudulent or not.
- Medical diagnosis. In medical diagnoses, Bayes' theorem is utilized to analyze data from previous cases and estimate the likelihood of a patient having a given disease. Bayesian can consider various factors that could influence the result and generate probabilistic estimates that are more explainable than just binary results.
- Image processing. Bayesian inference has multiple applications in image processing. For instance, it can be used to remove noise from images by applying techniques such as the Markov Chain Monte Carlo and Bayes theorem.
- Speech processing. Bayesian nonparametric clustering (BNC) is used in the nonparametric hierarchical neural network to perform speech and emotion recognition. This process outperforms other state-of-the-art models on similar tasks.
Causal Inference in Machine Learning
Causal inference is a statistical approach used in AI and machine learning to understand cause-and-effect relationships between attributes.
For instance, in marketing, decision-makers may want to understand which campaign generates the highest conversion rate. Using causal inference can assist in identifying the causal relationship between the conversion rate and the marketing campaign to maximize the conversions.
Our Statistical inference with R course can help you familiarize yourself with the core set of skills in statistical inference necessary to understand, interpret and tune your statistical and machine learning models.
Importance of Causal Inference in Machine Learning
Causal inference is important in machine learning for multiple reasons, including efficient predictions and fairness. Let’s have a quick look at each one of them.
- Efficient prediction. In many machine learning use cases, correlation analysis is not enough, because it does not necessarily imply causation. Causal inference allows Machine Learning Engineers identify the underlying causal relationships between variables, which leads to more accurate predictions.
- Fairness. Using causal inference machine learning can help identify the underlying causes of bias in a given data. This can help decision-makers adopt appropriate actions to make the data mitigate the bias issue, hence developing better machine learning models.
Challenges in Implementing Causal Inference in Machine Learning
Like other techniques in machine learning, the implementation of causal inference in machine learning comes with its own set of challenges, but not limited to the ones illustrated below:
- Large quality data. Making a valid causal inference requires large quality data. However, real-world data is messy, and it can be challenging to find the perfect approach to make the data error-free.
- Interpretability. The methods involved in the estimation of the causality are often complex and require both strong statistical expertise and advanced domain knowledge of the field being studied for a better interpretation of the results.
- Confounding variables. These variables are related to both the independent and dependent variables. This factor can bias the true causal effect of the independent ones; hence making it challenging to make an accurate estimation of the causal effect.
Conclusion
This article has covered what machine learning inference is, how it differs from machine learning training, and some key recommendations to consider when choosing one of the other. In addition to highlighting bayesian and causal inferences, it has also illustrated their importance and their challenges in machine learning.
It is important to keep in mind that inference is mandatory for any machine learning model to be useful in real-life. Only through inference models can be integrated into existing applications and be used by businesses and different stakeholders for a better business impact.