
Course
Advanced NLP with spaCy
5 hr
21.7K
Working with artificial intelligence (AI) or machine learning (ML) with a need for a text-to-speech engine? In that case, you're going to need an open-source solution. Let's explore how text-to-speech (TTS) engines work and some of the best open-source options.
In this simple guide, I'll share more about TTS engines and list down some of the best options available.
Before we get started with the list, let's quickly define what a text-to-speech engine actually is.
A text-to-speech engine is a software that converts written text into spoken words. It utilizes natural language processing (NLP) to analyze and interpret written text and then uses a speech synthesizer to generate human-like speech.
TTS engines are commonly used in applications such as virtual assistants, navigation systems, and accessibility tools.
Interested in working with NLP? DataCamp’s Natural Language Processing in Python skill track will help you get your technical know-how up to speed.
Open-source Text-to-Speech (TTS) engines are valuable tools for converting written text into spoken words, enabling applications in accessibility, automated voice responses, and virtual assistants, among other areas.
They are usually developed by a community of developers and released under an open-source license, allowing anyone to use, modify, and distribute the software freely.
Here are some well-known open-source TTS engines:
A flexible, modular architecture for building TTS systems, including a voice-building tool for generating new voices from recorded audio data.
Here's an overview diagram of the architecture behind this engine:
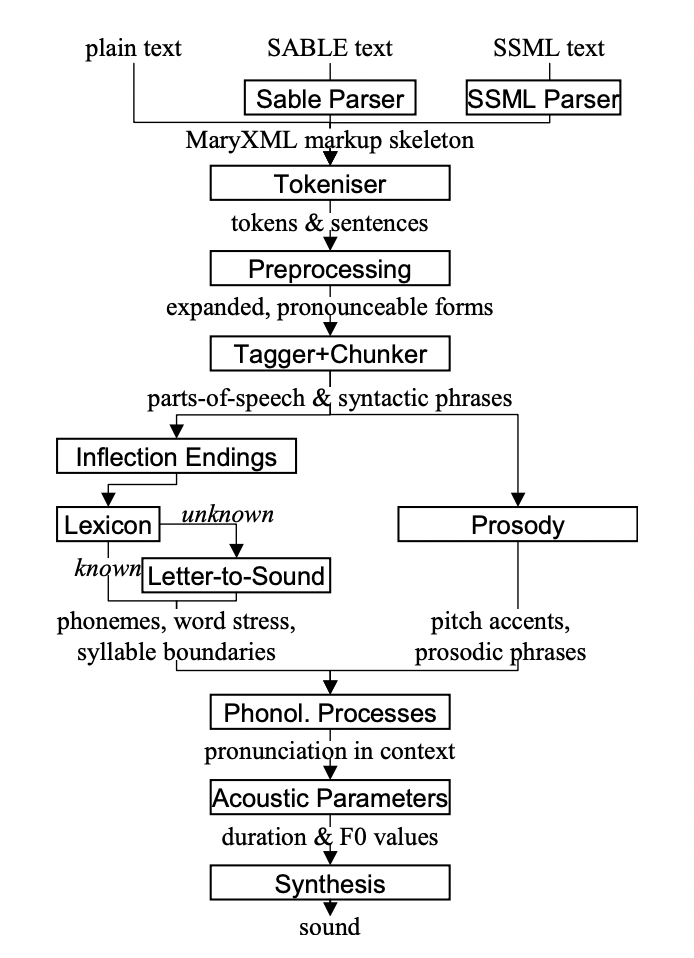
Source: MaryTTS GitHub
This architecture includes some basic components such as:
Pros: The MaryTTS architecture is highly customizable, allowing developers to create their own parsers, processors, and synthesizers to fit their specific needs. This also allows for flexibility in integrating the software into different platforms and applications.
Cons: Due to its highly customizable nature, there may be a learning curve for developers who are unfamiliar with markup language and text-to-speech technology.
Link: GitHub
 A compact open-source software speech synthesizer for English and other languages, eSpeak produces clear and intelligible speech across a wide range of languages. It's known for its simplicity and small footprint.
A compact open-source software speech synthesizer for English and other languages, eSpeak produces clear and intelligible speech across a wide range of languages. It's known for its simplicity and small footprint.
eSpeak can be run on various platforms, including Windows, Linux, macOS, and Android.
Pros: Easy to use, supports many languages and voices.
Cons: Limited features and customization options, and written in C.
Link: GitHub
Developed by the University of Edinburgh, Festival offers a general framework for building speech synthesis systems as well as including examples of various modules. It's widely used for research and educational purposes.
The figure below shows the general utterance structure of Festival. It involves a tree shape with links between nodes showing a relation.
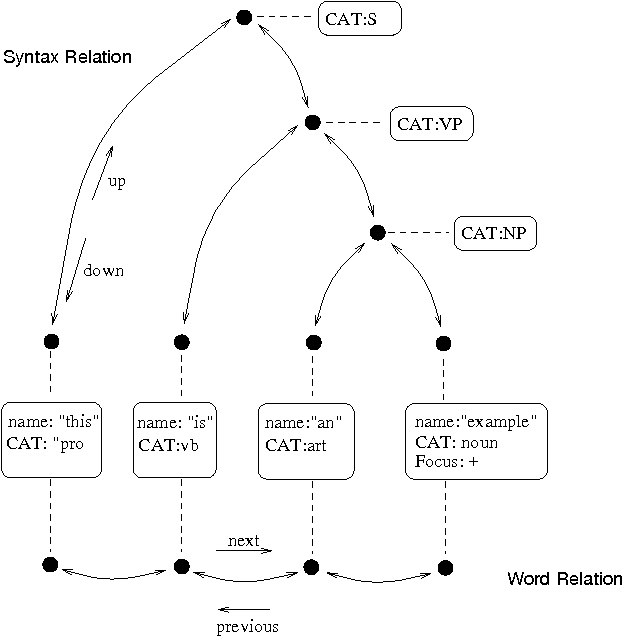
Source: Semanticscholar
Pros: Highly customizable, suitable for research purposes.
Cons: Difficult to use for beginners, requires some coding knowledge.
Link: GitHub
4. Mimic
Source: Mimic
Developed by Mycroft AI, Mimic is capable of producing highly natural-sounding speech. It includes Mimic 1, based on the Festival Speech Synthesis System, and Mimic 2, which uses deep neural networks for voice synthesis.
Pros: Offers both traditional and modern voice synthesis methods and supports multiple languages.
Cons: Limited documentation.
Link: GitHub
A deep learning-based TTS engine that aims to create more natural and human-like speech synthesis. It leverages modern neural network architectures, particularly sequence-to-sequence models.
Pros: Uses advanced technology for more natural speech and is free to use.
Cons: Limited language support.
Link: GitHub
Although not an engine per se, Tacotron 2 is a neural network model architecture for generating natural speech. Open-source implementations of Tacotron 2 are available, and it has inspired many developments in speech synthesis technology.
This system allows users to synthesize speech using raw transcripts without any additional prosody information.
Pros: Developed by NVIDIA, good to be used as a neural network model.
Cons: Requires some technical knowledge to implement.
Although this engine can be quite technically difficult to master, you can always familiarize yourself with related neural network models through online resources. One such place would be our neural networks guide or our tutorial on neural networks.
Link: GitHub
Part of the ESPnet project, this TTS engine is designed for end-to-end speech processing, including both speech recognition and synthesis. It uses modern deep-learning techniques to generate speech.
Pros: Modern and flexible, supports multiple languages.
Cons: Requires some technical knowledge to implement.
Link: GitHub
Coqui TTS is a modern open-source text-to-speech framework that provides an array of pre-trained models for various languages and accents. Built on top of TensorFlow, it supports neural network-based TTS models like Tacotron 2, FastSpeech, and more.
Pros:
Cons:
Link: GitHub
Larynx, developed by the Mycroft AI team, is an advanced TTS system that offers high-quality voice synthesis with support for multiple languages. It is based on Tacotron 2 and WaveGlow for natural-sounding speech generation.
Pros:
Produces realistic and human-like voice synthesis.
Supports a wide range of languages and voices out of the box.
Simple to set up and use compared to other neural TTS engines.
Cons:
Requires significant computational resources for training and inference.
Limited customization options compared to some other engines.
Link: GitHub
| TTS system | Architecture | Pros | Cons | Use cases |
|---|---|---|---|---|
| MaryTTS | Modular architecture | Highly customizable, flexible integration | Learning curve for developers | Ideal for developers and researchers creating customized TTS applications, especially in accessibility projects. |
| eSpeak | Compact open-source synthesizer | Simple, supports many languages | Limited features and customization | Suitable for applications requiring a wide range of language support and minimal system resources. |
| Festival | General framework with examples of modules | Highly customizable, suitable for research | Difficult for beginners, requires coding | Best for academic research and development projects needing deep customization and experimentation. |
| Mimic | Traditional and neural network synthesis | Natural-sounding speech, supports multiple languages | Limited documentation | Well-suited for high-quality voice synthesis projects, like virtual assistants or multimedia apps. |
| Mozilla TTS | Deep learning-based, seq-to-seq models | Advanced technology for natural speech, free to use | Limited language support | Ideal for developers using cutting-edge deep learning techniques for natural-sounding TTS. |
| Tacotron 2 | Neural network model for speech generation | Good as a neural network model | Technical knowledge required | Perfect for research and development in neural network-based speech synthesis. |
| ESPnet-TTS | End-to-end speech processing | Modern and flexible, supports multiple languages | Technical knowledge required | Aimed at developers and researchers working on advanced speech synthesis and recognition projects. |
| Coqui TTS | Neural TTS with pre-trained models | Pre-trained models, modular, strong community support | Requires familiarity with deep learning | Great for advanced customization, supporting accents and languages, suitable for ML practitioners. |
| Larynx | Tacotron 2 and WaveGlow | High-quality, human-like voice synthesis | Resource-intensive, limited customization | Ideal for natural-sounding voice assistants, voiceovers, or accessibility applications. |
Here are some ways the above TTS engines can be used:
Through the use of text-to-speech engines like the ones mentioned above, virtual assistants can be made. These virtual assistants can be similar to enterprise voice assistants such as Siri and Alexa.

Some of them can even be used for accessibility assistance for users with visual impairments, allowing them to hear written text instead of reading it.
TTS engines are also used in automated response systems, such as phone or chatbot assistants. These engines can read out responses based on specific prompts and interactions, providing a more human-like experience for users.
Text-to-speech technology can also generate voiceovers for videos or images, allowing for more dynamic and engaging content.
For example, the eSpeak engine can be used to add voiceovers to videos in different languages, making them more accessible and appealing to a wider audience.
This is especially useful for applications in marketing, e-learning, and entertainment industries.
Using an open-source option can be cost-effective and offers more flexibility for customization. However, there are some challenges that come with using these engines:
Many open-source TTS engines have limited language support compared to commercial solutions.
This limitation may be a barrier for users who need TTS in less commonly used languages.
Most open-source TTS engines require some coding knowledge to customize and implement. This makes it hard for regular business stakeholders to use them without technical support.
This may be a challenge for individuals or organizations without technical expertise.
While open-source engines are free to use, they may require additional resources and time for customization and implementation.
Additionally, an engineer or analyst with the relevant know-how of TTS engines has to be hired or trained.
Therefore, in some cases, commercial solutions may be more cost-effective in the long run.
Having limited resources and being community-driven, open-source projects may not always have extensive support and documentation available.
Source: ESPnet Documentation
This can make it challenging for users to troubleshoot issues or learn how to use the engine effectively.
However, as these engines continue to gain popularity and more developers contribute to them, this challenge may diminish over time.
Since open-source engines are developed and maintained by a community, there may be concerns about security and performance.
However, these risks can be mitigated through proper vetting and monitoring of the engine's code and updates.
Additionally, choosing reliable and reputable open-source projects can help alleviate these concerns.
Let's now discuss how to go about selecting the right engine for your text-to-speech model.
Here are some factors to consider:
Start by identifying your specific use case and the purpose of using TTS. Understand what features and customization options are necessary for your project, and then choose an engine accordingly.
If you require support for a particular language or multiple languages, make sure to select an engine that offers such capabilities.

In that case, going for the eSpeak engine may be a better option for you.
Consider your budget and resources before selecting an engine. While open-source options may be cost-effective in the long run, they may require additional resources for customization and implementation.
Evaluate the skill level of your team or yourself when working with TTS engines. If you do not have technical expertise, consider opting for a commercial solution that offers user-friendly interfaces and support.
Ensure that the engine you choose provides high-quality, natural-sounding speech output. You may also want to test different engines to see which one best matches your desired level of performance.
Text-to-speech technology has come a long way in providing more natural and human-like speech output. With numerous open-source options available, it’s now more accessible and cost-effective to integrate TTS into various applications.
However, you'll also have to expect some limitations and challenges that come with using open-source engines before making a decision. I hope this guide has provided a greater understanding of TTS engines and helped you in selecting the best one for your needs.
Looking for ways to do this process in reverse? Check out our Spoken Language Processing in Python course.
Learn more about NLP with these courses!
Course
Course
Course
blog
Abid Ali Awan
13 min
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
8 min
Tutorial
Kurtis Pykes
Tutorial
Stanislav Karzhev
Tutorial
Abid Ali Awan



