

Track
AI Business Fundamentals
12 hr
Reasoning models are becoming more important and common, and we can see why. If you look at the graph below, you’ll notice that 37.2% of users rely on Claude for coding and math questions, according to the Anthropic Economic Index. That tells us one thing—strong reasoning models can bring real business value, especially as AI adoption in enterprise settings remains low.
Source: Antrophic Economic Index
At the same time, Claude 3.7 isn’t just a reasoning model—it’s a hybrid. We can switch between Thinking Mode (for structured reasoning tasks) and a standard chat mode for general conversation, writing, and summarization.
Claude 3.7 Sonnet is a much bigger upgrade than the version number suggests. The benchmark data confirms that it outperforms Claude 3.5 Sonnet in reasoning, coding, and real-world task execution.
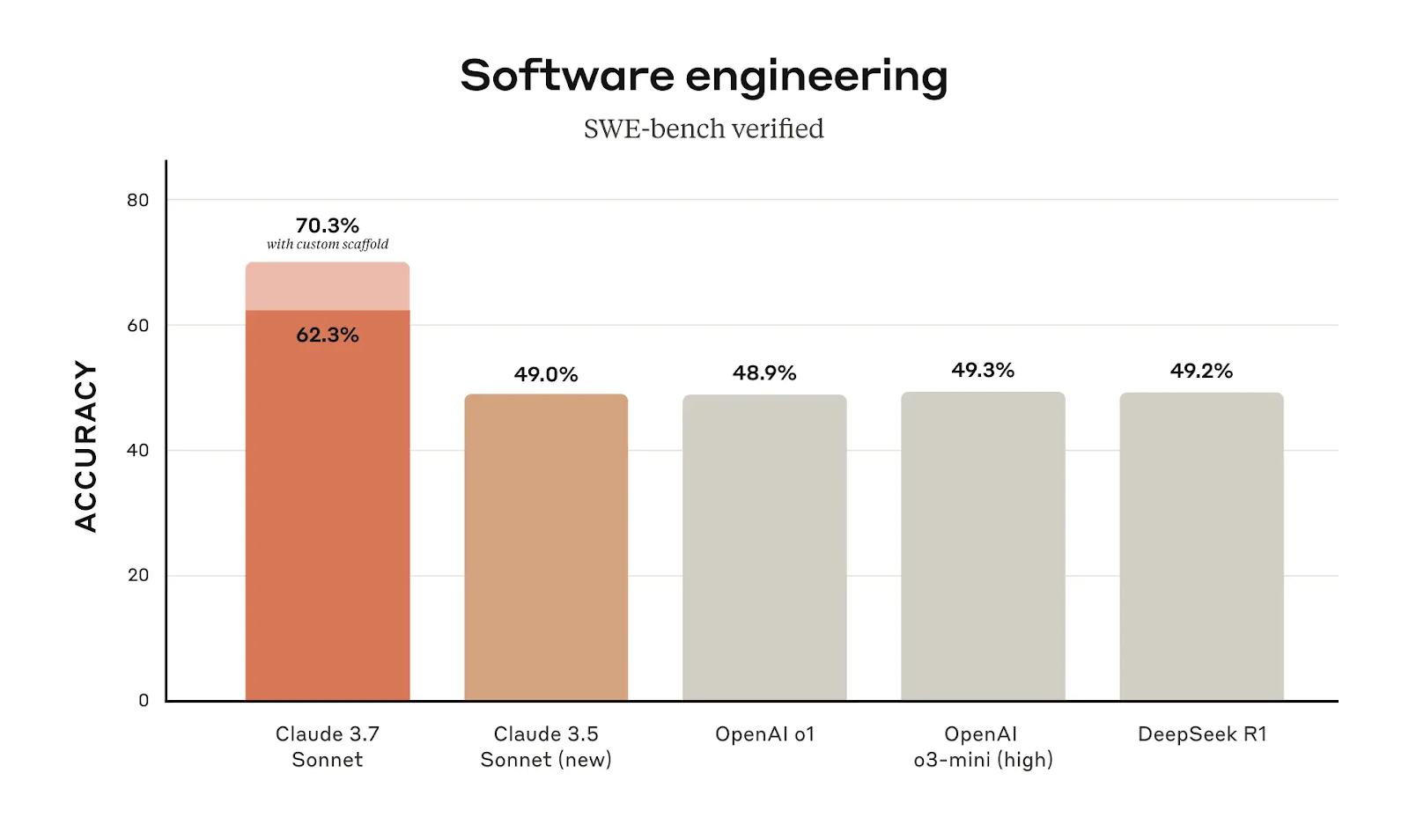
Claude 3.7 Sonnet shows a clear advantage in software engineering, with a 62.3% accuracy score in SWE-bench Verified, a significant jump from Claude 3.5 Sonnet’s 49.0%. When using a custom scaffold (a structured prompt or additional context that helps guide the model’s response toward a more accurate solution), that accuracy increases to 70.3%, making it the best-performing model in this category.
Source: Anthropic
A nearly 13% improvement in accuracy between model versions is not just a small refinement. It suggests that Claude 3.7 Sonnet has been optimized for better understanding and execution of programming-related tasks. For users who rely on Claude for software engineering, debugging, or automation, the upgrade makes a tangible difference.
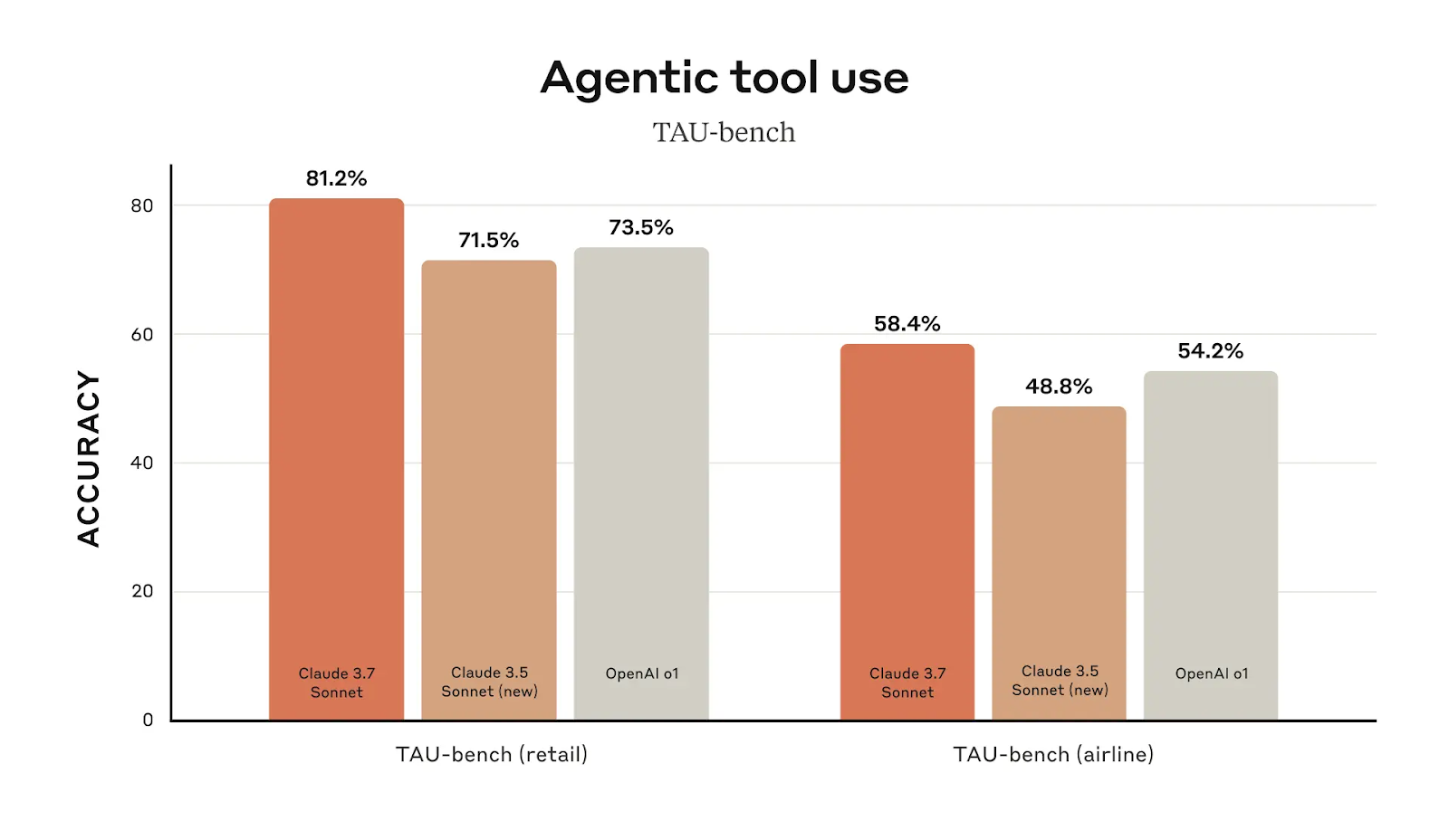
Performance in agentic tool use is another area where Claude 3.7 Sonnet surpasses its predecessor. In retail-related tasks, it achieves 81.2% accuracy, up from Claude 3.5 Sonnet’s 71.5%. In airline-related tasks, it scores 58.4%, an almost ten-point improvement over the previous version.
Source: Anthropic
Across all benchmarks, the largest gains come from extended thinking mode, which allows Claude 3.7 to perform at a much higher level in complex reasoning tasks. Users who rely on AI for structured workflows, coding, or problem-solving will see a clear difference between Claude 3.5 and Claude 3.7, especially when using extended thinking.
Source: Anthropic
Most of this progress comes from Claude’s extended thinking, so let’s find out more about this.
When enabled, extended thinking mode increases the number of reasoning steps Claude takes before finalizing an answer. Developers can fine-tune this process by setting a thinking budget, which defines how many tokens the model can use while working through a problem. As shown in the AIME 2024 performance graph below, accuracy improves as more tokens are allocated, following a logarithmic trend.
Source: Anthropic
This approach mirrors human cognitive effort: for simple tasks, quick answers suffice, but for complex ones, deeper analysis leads to better results. Claude can now decide when to pause, re-evaluate, and refine its reasoning rather than defaulting to immediate responses.
One of the most interesting aspects of extended thinking mode is that Claude’s reasoning process is visible to the user. However, this feature raises some challenges. While it provides insight into AI reasoning, the displayed thought process might not always perfectly align with how the model actually makes decisions. The “faithfulness problem”—whether an AI’s self-reported thoughts accurately represent its internal mechanics—is still an open research question.
Claude 3.7 Sonnet’s ability to engage in long-term, iterative reasoning is tested in evaluations like OSWorld and Pokémon Red gameplay. In Pokémon Red, for instance, Claude 3.7 Sonnet achieves far greater in-game progression than previous versions, making it through multiple milestones while earlier models get stuck early in the game.
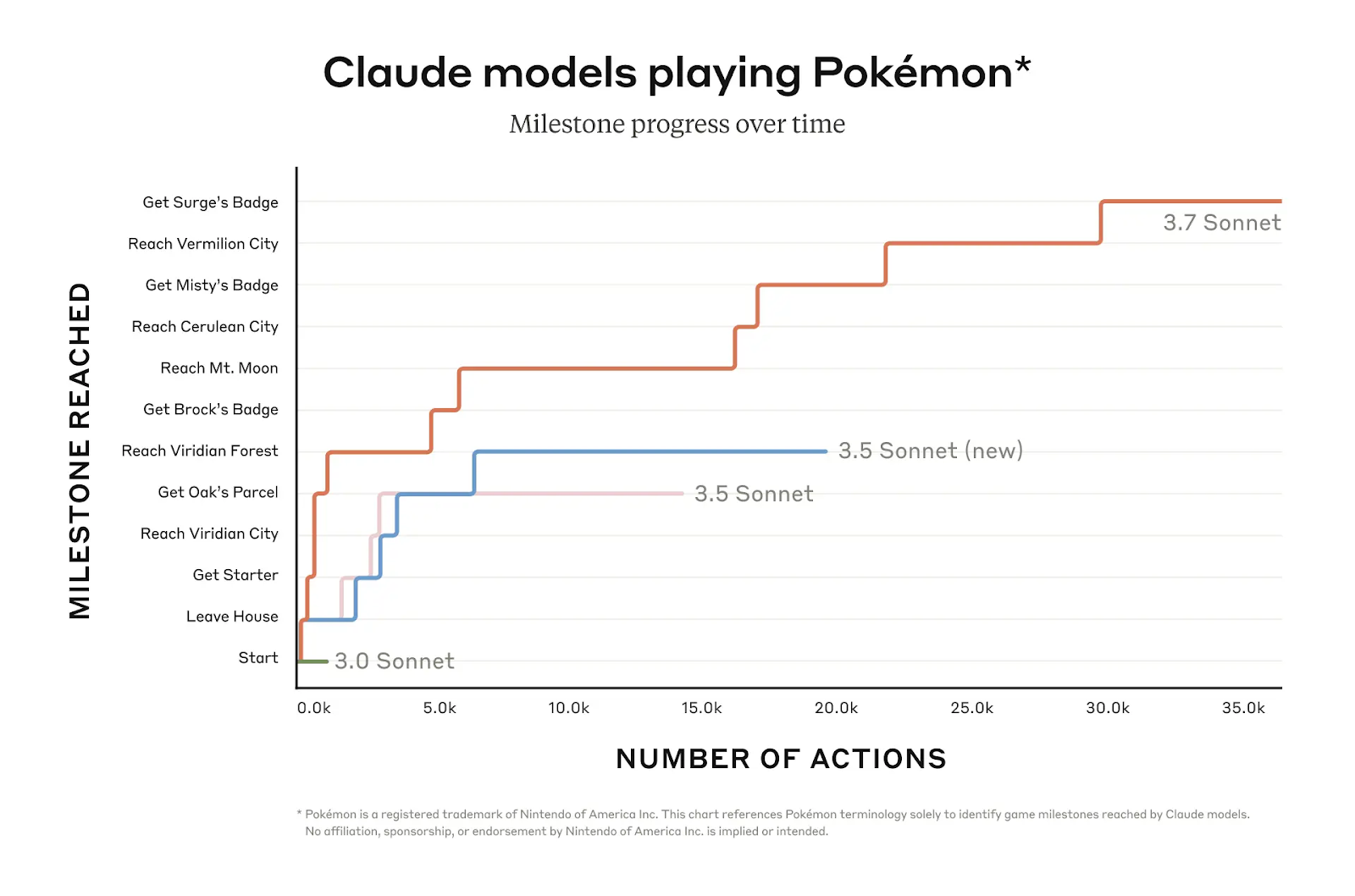
Source: Anthropic
We’ve seen how Claude 3.7 Sonnet performs against its earlier version, but how does it compare to OpenAI’s o3-mini, DeepSeek-R1, or Grok 3?
Looking at the updated benchmarks, Claude 3.7 Sonnet has positioned itself as one of the top-performing models, especially in reasoning-heavy tasks, coding, and agentic tool use.
In graduate-level reasoning (GPQA Diamond), Claude 3.7 Sonnet scores 68.0% in standard mode and 84.8% in extended thinking mode, making it one of the strongest models in this category. It outperforms OpenAI’s o1 (78.0%) and DeepSeek-R1 (71.5%) by a significant amount and Grok 3 Beta (84.6%) by only a small margin.
|
Benchmark |
Claude 3.7 Sonnet (Standard) |
Claude 3.7 Sonnet (Extended Thinking) |
OpenAI o1 |
OpenAI o3-mini (high) |
DeepSeek R1 |
Grok 3 Beta |
|
GPQA Diamond (Graduate-level reasoning) |
68.0% |
84.8% |
78.0% |
79.7% |
71.5% |
84.6% |
|
AIME 2024 (High school math competition) |
23.3% |
80.0% |
83.3% |
87.3% |
79.8% |
93.3% |
|
Math Problem-Solving (MATH 500) |
82.2% |
96.2% |
96.4% |
97.9% |
97.3% |
- |
The AIME 2024 benchmark, which tests high school math competition problems, shows a similar trend. Claude 3.7 Sonnet makes a huge leap from previous versions, scoring 80.0% with extended thinking enabled. While it beats DeepSeek-R1 (79.8%) by a small margin, it still lags behind OpenAI’s o3-mini (87.3%) and Grok 3 Beta (93.3%).
In math problem-solving (MATH 500), Claude 3.7 Sonnet achieves 96.2%, closely matching OpenAI’s o3-mini (97.9%) and DeepSeek R1 (97.3%).
Claude 3.7 Sonnet makes its biggest gains in coding benchmarks. On SWE-bench Verified (which evaluates AI models on software engineering tasks), Claude 3.7 Sonnet scores 62.3%, rising to 70.3% with a custom scaffold. This puts it far ahead of OpenAI’s o1 (48.9%) and o3-mini (49.3%), as well as DeepSeek R1 (49.2%), which was designed with coding in mind. This confirms that Claude 3.7 is now one of the best AI models for programming-related tasks.
|
Benchmark |
Claude 3.7 Sonnet (Standard) |
Claude 3.7 Sonnet (Custom Scaffold) |
OpenAI o1 |
OpenAI o3-mini (high) |
DeepSeek R1 |
|
SWE-bench Verified (Coding) |
62.3% |
70.3% |
48.9% |
49.3% |
49.2% |
|
TAU-bench Retail (Tool Use) |
81.2% |
- |
73.5% |
- |
- |
|
TAU-bench Airline (Tool Use) |
58.4% |
- |
54.2% |
- |
- |
Beyond coding, Claude 3.7 Sonnet leads in agentic tool use, making it a strong choice for automation and workflow execution. On TAU-bench (which tests AI’s ability to interact with external tools in structured environments), Claude 3.7 scores 81.2% in retail-related tasks, surpassing OpenAI o1 (73.5%). In airline-related tasks, Claude 3.7 reaches 58.4%, again outperforming OpenAI o1 (54.2%).
This suggests that Claude 3.7 is well-suited for business applications and structured workflows, making it a strong choice for enterprise users looking to integrate AI into their decision-making and operational processes.
Claude 3.7 Sonnet is available through multiple channels, including Anthropic’s web interface, Claude’s integration in various apps, and API access for developers. While the model is a significant upgrade, its availability comes with some limitations—especially if you want to use Thinking Mode, which is currently locked behind a paid tier.
For general users, Claude 3.7 Sonnet is accessible through Anthropic’s official website (claude.ai) and the Claude app. It is available in the free tier, but with restrictions:
To enable Thinking Mode, you need to click on Extended from the model dropdown menu:
Developers can integrate Claude 3.7 Sonnet into their applications using Anthropic’s API, which is accessible via Anthropic’s developer portal. The API supports a pay-as-you-go pricing model based on token usage.
Here’s an overview of Anthropic’s API offerings:
|
Feature |
Claude 3.7 Sonnet |
Claude 3.5 Sonnet |
Claude 3.5 Haiku |
Claude 3 Opus |
Claude 3 Haiku |
|
Description |
Our most intelligent model |
Our previous most intelligent model |
Our fastest model |
Powerful model for complex tasks |
Fastest and most compact model for near-instant responsiveness |
|
Strengths |
Highest level of intelligence and capability with toggleable extended thinking |
High level of intelligence and capability |
Intelligence at blazing speeds |
Top-level intelligence, fluency, and understanding |
Quick and accurate targeted performance |
|
Multilingual |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Vision |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Yes |
No |
No |
No |
No |
|
|
API model name |
claude-3-7-sonnet-20250219 |
Upgraded version: claude-3-5-sonnet-20241022 Previous version: claude-3-5-sonnet-20240620 |
claude-3-5-haiku-20241022 |
claude-3-opus-20240229 |
claude-3-haiku-20240307 |
|
Comparative latency |
Fast |
Fast |
Fastest |
Moderately fast |
Fastest |
|
Context window |
200K |
200K |
200K |
200K |
200K |
|
Max output |
Normal: 8192 tokens Extended thinking:64000 tokens |
8192 tokens |
8192 tokens |
4096 tokens |
4096 tokens |
|
Cost (Input / Output per MTok) |
$3.00 / $15.00 |
$3.00 / $15.00 |
$0.80 / $4.00 |
$15.00 / $75.00 |
$0.25 / $1.25 |
|
Training data cut-off |
Oct 2024 |
Apr 2024 |
July 2024 |
Aug 2023 |
Aug 2023 |
Source: Anthropic
Make sure to always check the latest API pricing.
Anthropic just made its biggest move in a while with Claude 3.7 Sonnet, a model that finally brings it into the reasoning AI space. Based on the benchmarks, we can see that it’s a legitimate competitor to OpenAI’s o3-mini, DeepSeek-R1, and Grok 3, with strong performance in coding, structured problem-solving, and agentic tool use.
The ability to switch between generalist and reasoning modes makes it more versatile, but locking Thinking Mode behind a paywall feels like a misstep, especially with free alternatives available. Still, Claude 3.7 is a major step forward.
Are you ready for the next step? Tune in to our Claude 3.7 Sonnet API video where we will show you how you can build your very own multimodal research assistant.
Learn AI with these courses!
Track
Track
Course
blog
Matt Crabtree
8 min
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
blog
Srujana Maddula
10 min
Tutorial
Aashi Dutt
Tutorial
Bex Tuychiev


