
Kurs
KI-Agenten mit dem Google ADK entwickeln
1 Std.
6.5K
Nachdem wir monatelang auf Grok 3.5 gewartet hatten, hat xAI es einfach übersprungen und ist direkt zu Grok 4.
Ist der Sprung durch die Leistung des Modells gerechtfertigt?
Ja, wenn du nach den Benchmarks gehst. Im Moment ist Grok 4 wahrscheinlich das beste Modell der Welt auf dem Papier.
Aber mit einem Kontextfenster von 128.000 in der App und 256.000 in der API könnte es in der echten Produktion zu Problemen kommen. Es ist nicht so nachsichtig wie Gemini 2.5 Pro, das dir eine Million Tokens gibt. Wenn du Grok 4 für mehr als nur einen kurzen Chat nutzen willst, brauchst du ein paar ernsthafte Kontext-Engineering, damit es funktioniert.
In diesem Blog werde ich den üblichen Hype beiseite lassen und dir einen ausgewogenen Überblick geben, indem ich die wichtigsten Stärken und Schwächen von Grok 4 erkläre und meine eigenen Testergebnisse vorstelle.
Wir halten unsere Leser über die neuesten Entwicklungen im Bereich KI auf dem Laufenden, indem wir ihnen jeden Freitag unseren kostenlosen Newsletter „The Median“ schicken, der die wichtigsten Meldungen der Woche zusammenfasst. Abonniere unseren Newsletter und bleib in nur wenigen Minuten pro Woche auf dem Laufenden:
Die Grok 4-Familie umfasst nur Grok 4 und Grok 4 Heavy. Es gibt keine Mini-Version, die wir für schnelles Denken verwenden können.
Grok 4 ist das neueste Single-Agent-Modell von xAI (im Gegensatz zu Grok 4 Heavy, das mehrere Agenten nutzt – dazu mehr im nächsten Abschnitt). Basierend auf dem Livestreamgibt es technisch nichts wirklich Neues. Die Verbesserungen scheinen von einer Reihe kleinerer Optimierungen und einer deutlichen Steigerung der Rechenleistung zu kommen, die ungefähr zehnmal so hoch ist wie bei Grok 3.

Quelle: xAI
Das Unternehmen behauptet, es sei das intelligenteste Modell, das es derzeit gibt, und die Benchmark-Ergebnisse zeigen auch, dass das stimmt. Das auffälligste Ergebnis kam von„ Humanity’s Last Exam“, einem Test mit 2.500 handverlesenen Fragen auf Doktoranden-Niveau aus den Bereichen Mathe, Physik, Chemie, Linguistik und Ingenieurwesen. Grok 4 (mit Tools) hat etwa 38,6 % der Probleme gelöst.

Quelle: xAI
Das Kontextfenster hat in der App 128.000 Tokens und in der API 256.000, was etwas Spielraum für längere Erklärungen lässt, aber nach aktuellen Standards nicht besonders großzügig ist. Gemini 2.5 Pro hat zum Beispiel 1 Million. Wenn du mit Grok arbeitest, musst du wahrscheinlich etwas Zeit investieren, um deinen Kontext sorgfältig zu strukturieren und zu bereinigen.
Nur um das klarzustellen: Grok 4 ist nicht das richtige Modell für alltägliche Fragen wie „Wird es dieses Wochenende regnen?“ oder „Finde ein Konzert in meiner Nähe“. Du solltest lieber Grok 3 – das ist schneller und für allgemeine Aufgaben gemacht. Grok 4 ist besser für Forschung, technische Fragen und knifflige Probleme in Mathe, Wissenschaft, Finanzen oder Entwickler-Workflows, die auf reinem logischem Denken basieren.
Es ist noch nicht so klar, wie gut es in größeren Arbeitsabläufen für Verbraucher funktioniert oder wie gut es die Sicherheit in großem Maßstab gewährleistet. Aber xAI sagt, dass es schon in Biomedizin-Labors, Finanzfirmen und bei ersten Unternehmenspartnern eingesetzt wird.
Grok 4 Heavy ist die Multi-Agenten-Version von Grok 4. Anstatt ein einzelnes Modell zu verwenden, werden mehrere Agenten parallel gestartet, die unabhängig voneinander an derselben Aufgabe arbeiten. Sobald sie Ergebnisse haben, schauen sie, was sie gefunden haben, vergleichen alles und finden eine gemeinsame Antwort.
Theoretisch ist das ähnlich wie bei einer Lerngruppe – Agenten können ihre Erkenntnisse austauschen oder auf die Schwachstellen der anderen eingehen. In der Praxis hilft diese Konfiguration bei komplexen Denkaufgaben, bei denen ein einziger Durchgang nicht ausreicht.
Die Vorteile zeigen sich in den Benchmarks. Bei der letzten Prüfung der Menschheit hat Grok 4 Heavy mit Werkzeuggebrauch 44,4 % erreicht und damit den Einzelagenten Grok 4 deutlich übertroffen. Die Architektur schien auch bei der ARC-AGI, wo Grok 4 als erstes Modell die 10 %-Marke knackte und 15,9 % erreichte – allerdings ist noch nicht ganz klar, wie viel von diesem Ergebnis speziell auf die Multi-Agenten-Konfiguration zurückzuführen ist.
Quelle: xAI
Der Kompromiss ist Geschwindigkeit und Kosten. Grok 4 Heavy läuft langsamer (viel langsamer!) und ist zehnmal so teuer im Betrieb – xAI bietet den Zugang über einen SuperGrok Heavy-Tarif für 300 US-Dollar pro Monat an.
Noch mal: Grok 4 Heavy ist nicht das Richtige für einfache Suchvorgänge oder schnelle Iterationen. Wenn Grok 4 schon eine Nische ist, dann ist Grok 4 Heavy erst recht eine. Es ist für Probleme gemacht, bei denen mehrere Denkansätze zu besseren Ergebnissen führen können – denk mal an wissenschaftliche Forschung, Finanzmodellierung oder alles, was mit langfristiger Planung zu tun hat. In den meisten Fällen ist das aber echt übertrieben.
Ich teste oft neue Modelle, deshalb benutze ich meistens ein paar Standardaufgaben, um zu sehen, wie sie sich vergleichen lassen. Ich mach das hier genauso und konzentriere mich auf Mathe und Programmieren. Das soll keine ausführliche Bewertung von Grok sein, sondern nur einen Eindruck davon vermitteln, wie es sich in einer typischen Chat-Umgebung verhält.
Ich will mit einer einfachen Rechnung anfangen: 9.11 - 9.9. Du findest das vielleicht albern, aber es verwirrt Sprachmodelle oft –Claude Sonnet 4hat das zum Beispiel falsch verstanden. Natürlich könnte ich einfach einen Taschenrechner nehmen, aber hier geht's darum, zu sehen, wie das Modell an das Problem rangeht und ob es bei Bedarf auf Hilfsmittel zurückgreifen oder es direkt durch logisches Denken lösen kann.
Schauen wir mal, wie Grok 4 geantwortet hat:
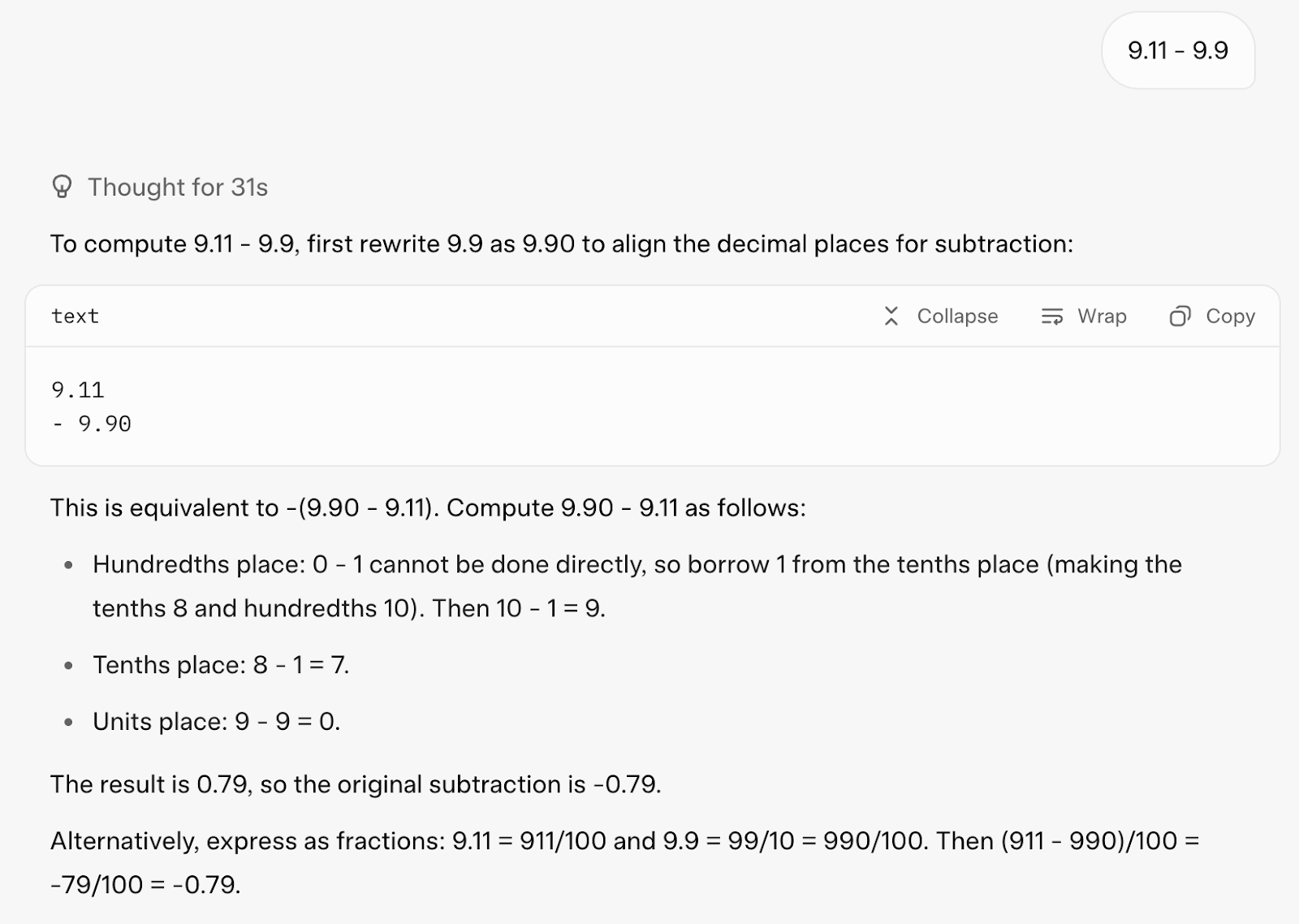
Es hat beim ersten Versuch richtig geantwortet. Die Antwort fand sie durch logisches Denken und hat sie mit einem Code-Tool überprüft (super!).

Allerdings hat die Antwort 31 Sekunden gedauert und war für so eine einfache Frage echt lang.
Als Nächstes wollte ich Grok 4 an einem komplexeren mathematischen Problem testen, das normalerweise das Kontextfenster eines Modells an seine Grenzen bringt:
Prompt: Nimm alle Ziffern von 0 bis 9 genau einmal, um drei Zahlen x, y, z zu bilden, sodass x + y = z ist.
Grok 4 hat das Problem clever angegangen. Zuerst hat es gemerkt, dass es mit Python alle 3.628.800 Permutationen der Zahlen 0 bis 9 in nur ein paar Sekunden machen kann. Dann hat es eine Konfiguration mit zwei dreistelligen Zahlen ausprobiert, die zusammen eine vierstellige Zahl ergeben, und einen Code gefunden, der tatsächlich 96 gültige Lösungen zurückgegeben hat!
from itertools import permutations
digits = range(10)
solutions = []
for p in permutations(digits):
x_digits = p[0:3]
if x_digits[0] == 0: continue
y_digits = p[3:6]
if y_digits[0] == 0: continue
z_digits = p[6:10]
if z_digits[0] == 0: continue
x = int(''.join(map(str, x_digits)))
y = int(''.join(map(str, y_digits)))
z = int(''.join(map(str, z_digits)))
if x + y == z:
solutions.append((x, y, z))
print(solutions)Dann hat es mit dem gleichen Ansatz andere Kombinationen ausprobiert (z. B. 4-stellige plus 2-stellige Zahlen, die zusammen eine 4-stellige Zahl ergeben). Am Ende hat es im Internet nach mehr Infos zu diesem Mathe-Rätsel gesucht und seine Antwort überprüft. Für diese Antwort haben wir insgesamt 157 Sekunden gebraucht:

Für die Codierungsaufgabe wollte ich sehen, wie es im Vergleich zu Gemini 2.5 Pro und Claude Opus 4 abschneidet:
Prompt: Mach mir ein fesselndes Endlos-Runner-Spiel. Wichtige Anweisungen auf dem Bildschirm. p5.js-Szene, kein HTML. Ich mag pixelige Dinosaurier und coole Hintergründe.
Hier ist das Ergebnis:
Ziemlich gut!
Zuletzt wollte ich wissen, wie gut Grok 4 mit multimodalen Aufgaben mit langem Kontext klarkommt. Ich habe ein PDF mit dem Generative AI Outlook Report der Europäischen Kommission hochgeladen. Bericht über die Aussichten für generative KI (43.087 Tokens) hochgeladen und Grok gebeten, Folgendes zu tun:
: Schau dir den ganzen Bericht an und finde die drei Diagramme, die am meisten Infos geben. Fasse jeden Punkt zusammen und sag mir, auf welcher Seite des PDFs du ihn findest.
Schauen wir uns erst mal die Antwort an und dann schauen wir genauer hin:

Mir ist aufgefallen, dass es überraschend schnell aufgehört hat, nach nur 25 Sekunden. Es hat (falsch) Diagramme von den Seiten 19, 20 und 44 empfohlen und den Rest des 167-seitigen Dokuments einfach ignoriert, nachdem es eine Antwort gefunden hatte, die ihm gut passte. Der Gedankengang fühlt sich irgendwie unvollständig an und zeigt auf eine ziemlich oberflächliche Herangehensweise:

Jetzt zu den Ergebnissen:
Wie Elon Musk im Livestream gesagt hat, ist das Verständnis und die Generierung von Bildern bei Grok 4 noch nicht so weit fortgeschritten. Wenn du konstante und zuverlässige Ergebnisse willst, kann man wohl sagen, dass Grok 4 im Moment ein reines Textmodell ist.
Grok 4 ist vor allem für seine Leistung in einer Vielzahl von Benchmarks bekannt, von akademischen Prüfungen bis hin zu Unternehmenssimulationen. Laut xAI ist das Modell viel besser als die alten Versionen, vor allem weil es mehr Rechenleistung hat – sowohl beim Training als auch bei der Inferenz – und nicht unbedingt wegen neuer architektonischer Durchbrüche.
Das Kernmuster hinter der Leistung von Grok 4 ist die Skalierbarkeit. Es profitiert von mehr Rechenleistung für das Training und, was noch interessanter ist, von mehr Test-Zeit-Rechen. Einfach gesagt: Je mehr Ressourcen du reinsteckst, desto besser läuft's. Das wird besonders deutlich bei den Aufgaben im Rahmen desWettbewerbs „ “ (HLE, „Die letzte Prüfung der Menschheit“).
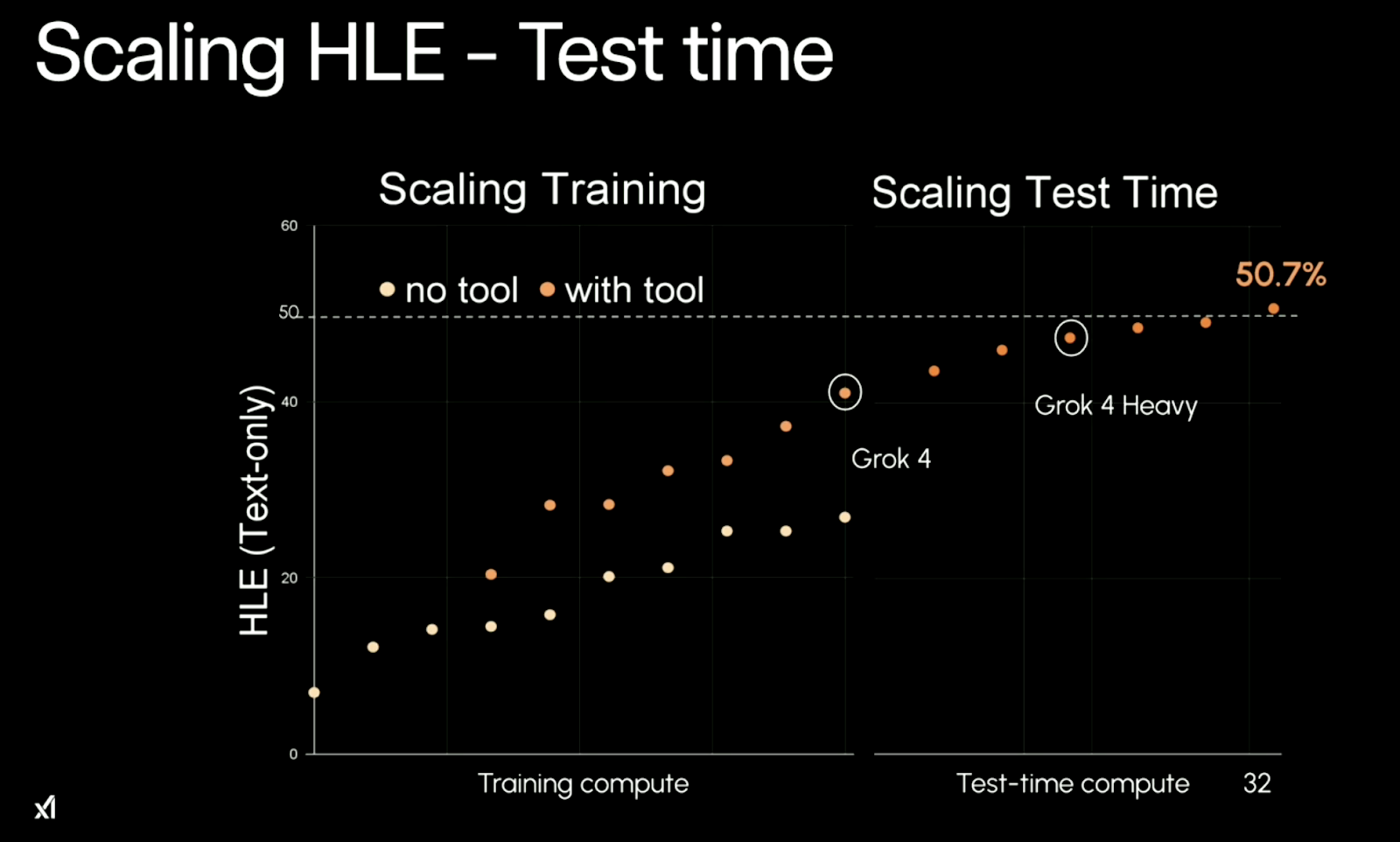
Quelle: xAI
Ohne Tools bleibt Grok 4 bei einer Genauigkeit von etwa 26,9 % beim „ ” stehen . Wenn Tools aktiviert sind (z. B. Codeausführung), kommt es zu einem Fehler„ “ 41,0 %. Und wenn es in seiner Multi-Agenten-Konfiguration „Heavy“ läuft, steigt es auf 50,7 %– ein großer Sprung, der mehr als doppelt so hoch ist wie die besten Ergebnisse des bisherigen Modells ohne Tools.
Grok 4 schneidet auch bei den eher klassischen STEM-orientierten Bewertungen gut ab, die oft zum Vergleich von leistungsstarken LLMs verwendet werden. Zu den Highlights gehören:
|
Benchmark |
Top-Konkurrenzmodelle |
Grok 4 (ohne Tools) |
Grok 4 Schwer |
|
GPQA |
79,6–86,4 % |
87,5 % |
88,9 % |
|
AIME25 |
75,5–98,8 % |
91,7 % |
100,0 % |
|
LCB (Jan–May) |
72,0–74,2 % |
79,0 % |
79,4 % |
|
HMMT25 |
58,3–82,5 % |
90,0 % |
96,7 % |
|
USAMO25 |
21,7–49,4 % |
37,5 % |
61,9 % |
Das sind echt gute Ergebnisse. Grok 4 ist in den meisten Kategorien besser als Claude Opus, Gemini 2.5 Pro und GPT-4 (o3), auch wenn einige Nutzer aber darauf hingewiesen, dass bei den Vergleichen vielleicht die besten Ergebnisse der Konkurrenzmodelle rausgesucht wurden.
Quelle: xAI
Einer der schwierigeren und undurchsichtigen Benchmarks ist ARC-AGI, der die Fähigkeit eines Modells testet, abstrakte Denkaufgaben zu verallgemeinern. Auf ARC-AGI v1 erreicht Grok 4 66,6 % und liegt damit vor allen bekannten Mitbewerbern. Bei„ “ ARC-AGI v2 erreicht es 15,9 %, verglichen mit 8,6 % von Claude 4 Opus.
Diese Tests sind nicht komplett öffentlich, also gelten die üblichen Vorbehalte. Aber wenn die Zahlen stimmen, zeigt Grok 4 echt gute Leistungen bei mehrschrittigen, logiklastigen Denkaufgaben.
xAI hat Grok 4 auch in einer echten Simulation namens „Vending-Bench”getestet . Die Idee ist, zu sehen, ob ein Modell ein kleines Unternehmen über einen längeren Zeitraum verwalten kann: Lagerbestände auffüllen, Preise anpassen, Lieferanten kontaktieren usw. Das ist ein ziemlich neuer Benchmark und macht überraschend viel Spaß. Wir haben bereits in unserem wöchentlichen Newsletter anhand einer Fallstudie zu Claude Sonnet 3.7 ausführlich erklärt, wie das funktioniert. „The Median“..
Ergebnisse (Durchschnitt aus fünf Durchläufen):
|
Rang |
Modell |
Nettovermögen |
Verkaufte Einheiten |
|
1 |
Grok 4 |
$4,694 |
4.569 |
|
2 |
Claude Opus 4 |
$2,077 |
1.412 |
|
3 |
Menschliche Basislinie |
$ 844 |
344 |
|
4 |
Gemini 2.5 Pro |
$ 789 |
356 |
|
5 |
GPT-4 (o3) |
$1,843 |
1.363 |
Grok 4 hat die Leistung seines nächsten Konkurrenten sowohl beim Umsatz als auch bei der Größe mehr als verdoppelt. Außerdem hat es seine Leistung über 300 Simulationsrunden hinweg konstant gehalten – was vielen Modellen bei der Planung mit langem Zeithorizont echt Probleme bereitet.
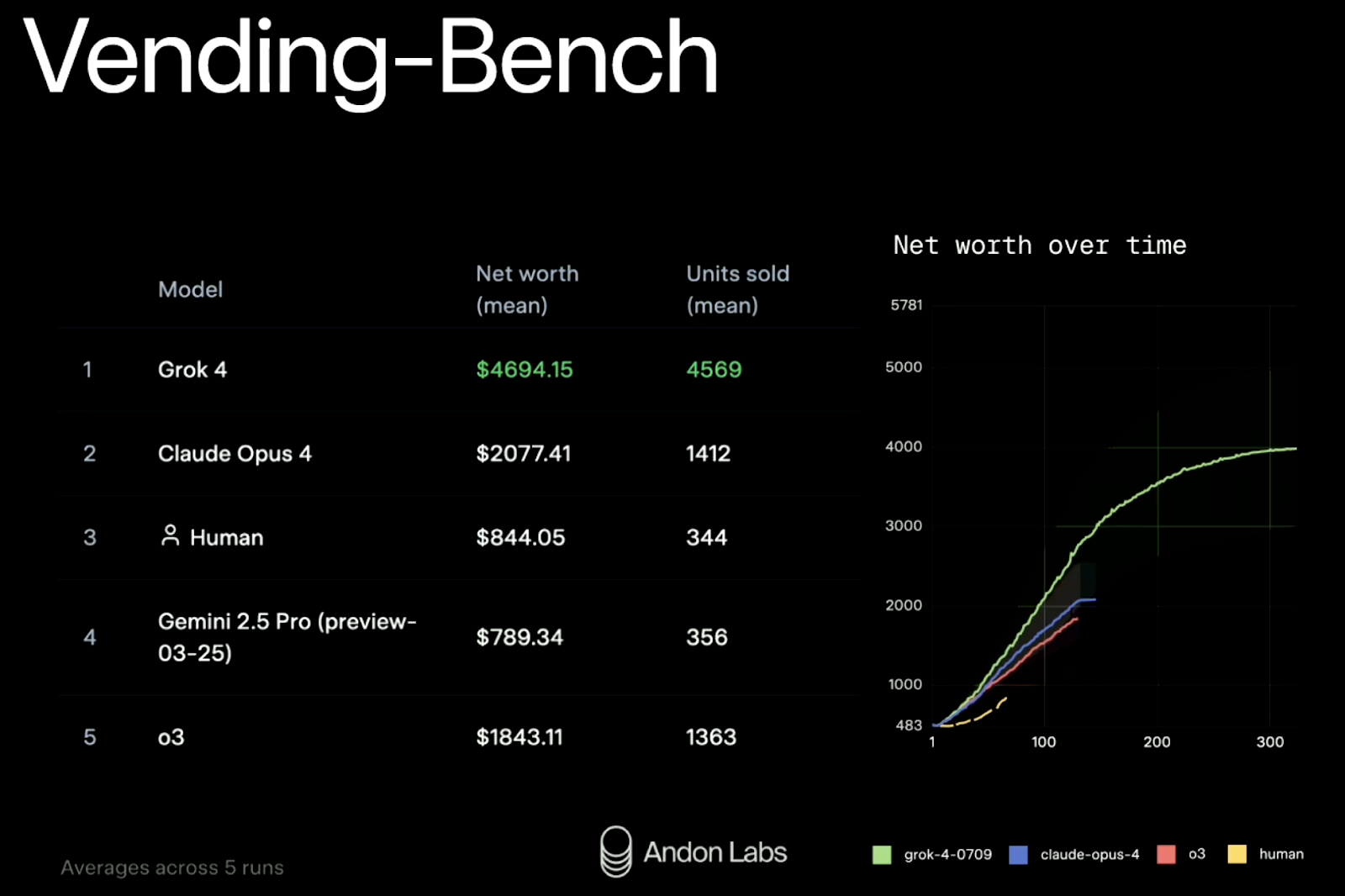
Quelle: xAI
Kurz gesagt: Grok 4 läuft gut, wo xAI es getestet hat. Aber wie immer solltest du über die Rangliste hinausschauen. Die Benchmarks sind vielversprechend, aber sie zeigen nicht alles – vor allem, wenn dein Anwendungsfall auf Bildverarbeitung, Codegenerierung oder Echtzeit-Interaktion in chaotischen Umgebungen ankommt.
Grok 4 ist jetzt über drei Hauptzugänge verfügbar: die X-App, die xAI-API und grok.com. Egal, ob du mit dem Modell chatten, damit bauen oder seine Denkfähigkeiten genauer testen willst – hier erfährst du, wie du loslegst.
Am einfachsten kannst du Grok 4 über die X-App (früher Twitter) ausprobieren. Damit kannst du Grok über eine Chat-Oberfläche nutzen, ähnlich wie ChatGPT oder Claude.
So geht's:
Du kannst Grok 4 auch direkt über grok.comnutzen, das eine übersichtlichere, eigenständige Oberfläche außerhalb der X-Plattform bietet. Es ist für Leute gedacht, die eine ablenkungsfreie Umgebung bevorzugen.
Wenn du Grok in deine eigene App oder deinen Workflow integrieren möchtest, kannst du die xAI APIverwenden.
Schritte:
Mit der Veröffentlichung von Grok 4 hat xAI einen klaren (und ehrgeizigen) Plan für den Rest des Jahres 2025 aufgestellt. Nach dem Zeitplan, der während des Livestreams gezeigt wurde, stehen in den nächsten drei Monaten vier große Releases an: ein Codierungsmodell im August, ein multimodaler Agent im September und ein Videogenerierungsmodell im Oktober.

Quelle: xAI
Der erste Folgebericht ist ein Modell mit Schwerpunkt auf der Kodierung, das für August erwartet wird. Anders als Grok 4, das ein Allrounder ist, wird das ein spezielles Modell sein, das Code schneller und genauer verarbeiten kann. xAI sagt, es sei „schnell und clever“ und wurde extra trainiert, um sowohl die Latenz als auch das Schlussfolgern in Softwareentwicklungs-Workflows zu verbessern.
Im September soll ein echt multimodaler Agent rauskommen. Im Moment kann Grok 4 Bilder und Videos technisch verarbeiten, aber es versteht noch nicht alles – während des Livestreams hat das Team das so beschrieben: „Es ist, als würde man durch ein mattes Glas starren.“
Die kommende Version soll das ändern und dafür sorgen, dass das Modell Bilder, Videos und Audio besser versteht. Das ist echt wichtig für Anwendungsfälle, die über Text hinausgehen, wie Robotik, Gaming, Video-QA oder das Befolgen visueller Anweisungen.
Die letzte Version in der aktuellen Zeitleiste ist ein Videogenerierungsmodell, das im Oktober rauskommen soll. xAI sagt, dass sie es auf über 100.000 GPUs trainieren werden. Nach dem, was sie gesagt haben, soll dieses System hochwertige, interaktive und bearbeitbare Videoinhalte produzieren.
Grok 4 ist ein echter Schritt nach vorn für xAI. Es ist besser als andere in ein paar echt schwierigen Tests, macht bei strukturierten Mathe- und Wissenschaftsbewertungen eine gute Figur und hat ein Multi-Agenten-System (Grok 4 Heavy) eingeführt, das für die Forschung und langfristiges Denken echt vielversprechend ist.
Allerdings ist es nicht dein alltäglicher Allzweck-Assistent. Es ist langsamer als Grok 3, das Verständnis von Bildern und Videos steckt noch in den Kinderschuhen und es fehlt noch ein wenig Feinschliff, was die Alltagstauglichkeit angeht. Aufgrund des relativ begrenzten Kontextfensters musst du deine Eingaben sorgfältig eingeben und kürzen. Und wenn du die beste Leistung willst – über Grok 4 Heavy – musst du dafür auch etwas mehr bezahlen.
Für Entwickler und Forscher lohnt es sich, das mal zu checken. Für Leute, die das nur ab und zu brauchen, sind die Geschwindigkeit und Reaktionsfähigkeit von Grok 3 oder anderen gängigen Modellen besser geeignet. Der Plan ist ziemlich ehrgeizig: Bis Oktober sollen ein Codierungsmodell, ein multimodaler Agent und ein Videogenerator fertig sein. Ob xAI das alles pünktlich hinbekommt, ist noch mal 'ne Frage. Aber mit Grok 4 haben sie zumindest überzeugend gezeigt, dass sie im Rennen sind.
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Tutorial
Matt Crabtree
Tutorial
Laiba Siddiqui
