
Cours
Créer des agents IA avec Google ADK
1 h
6.5K
Après avoir attendu plusieurs mois la sortie de Grok 3.5, xAI l'a complètement ignorée et est passée directement à la version Grok 4.
Cette augmentation est-elle justifiée par les performances du modèle ?
Oui, si l'on se fie aux tests de performance. À l'heure actuelle, Grok 4 est probablement le meilleur modèle au monde sur le papier.
Cependant, avec une fenêtre contextuelle de 128 000 dans l'application et de 256 000 dans l'API, vous pourriez rencontrer des difficultés dans un environnement de production réel. Il n'est pas aussi indulgent que le Gemini 2.5 Pro, qui vous offre un million de jetons. Si vous souhaitez utiliser Grok 4 pour plus qu'une simple conversation, vous aurez besoin d'une configuration contextuelle plus élaborée. compétences en ingénierie contextuelle pour le faire fonctionner.
Dans cet article, je vais aller au-delà du battage médiatique habituel et vous présenter un aperçu équilibré en vous expliquant les principaux points forts et points faibles de Grok 4, ainsi que les résultats obtenus lors de mes propres tests.
Nous tenons nos lecteurs informés des dernières actualités en matière d'IA en leur envoyant The Median, notre newsletter gratuite du vendredi qui résume les articles clés de la semaine. Abonnez-vous et restez informé en quelques minutes par semaine :
La famille Grok 4 comprend uniquement Grok 4 et Grok 4 Heavy. Il n'existe pas de version mini que nous pouvons utiliser pour un raisonnement rapide.
Grok 4 est le dernier modèle à agent unique de xAI (contrairement à Grok 4 Heavy, qui utilise plusieurs agents, nous y reviendrons dans la section suivante). D'après le diffusion en direct, il n'y a rien de particulièrement révolutionnaire en termes d'ingénierie. Les gains semblent provenir d'une série d'ajustements mineurs et d'une augmentation significative de la puissance de calcul, environ 10 fois supérieure à celle utilisée pour Grok 3.

Source : xAI
La société affirme qu'il s'agit du modèle le plus intelligent actuellement disponible, et les résultats des tests comparatifs vont dans ce sens. Le résultat le plus remarquable a été obtenu par Humanity’s Last Exam, un test de référence composé de 2 500 questions sélectionnées à la main, de niveau doctoral, couvrant les mathématiques, la physique, la chimie, la linguistique et l'ingénierie. Grok 4 (avec outils) a réussi à résoudre environ 38,6 % des problèmes.

Source : xAI
La fenêtre contextuelle contient 128 000 jetons dans l'application et 256 000 dans l'API, ce qui offre une certaine marge pour les raisonnements longs, mais n'est pas particulièrement généreux selon les normes actuelles. Gemini 2.5 Pro, par exemple, en propose un million. Si vous utilisez Grok, vous devrez probablement consacrer du temps à structurer et à épurer soigneusement votre contexte.
Pour être clair, Grok 4 n'est pas le modèle idéal pour les questions quotidiennes telles que « Va-t-il pleuvoir ce week-end ? » ou « Trouvez-moi un concert à proximité ». Il est préférable d'utiliser Grok 3 pour cela : il est plus rapide et conçu pour des tâches générales. Grok 4 est plus adapté à la recherche, aux questions techniques et aux questions complexes en mathématiques, en sciences, en finance ou dans les processus de développement qui reposent sur un raisonnement brut.
Ses performances dans des flux de travail grand public plus larges ou sa capacité à garantir la sécurité à grande échelle sont moins claires. Cependant, xAI indique que cette technologie est déjà utilisée dans des laboratoires biomédicaux, des sociétés financières et par ses premiers partenaires commerciaux.
Grok 4 Heavy est la version multi-agents de Grok 4. Au lieu d'exécuter un seul modèle, il lance plusieurs agents en parallèle, chacun travaillant indépendamment sur la même tâche. Une fois qu'ils ont généré des résultats, ils comparent leurs conclusions et se mettent d'accord sur une réponse.
En théorie, cela s'apparente à un groupe d'étude : les agents peuvent partager leurs connaissances ou combler leurs lacunes respectives. En pratique, cette configuration facilite les tâches de raisonnement complexes pour lesquelles un seul passage pourrait s'avérer insuffisant.
Les gains sont visibles dans les indices de référence. Lors du dernier examen de l'humanité, Grok 4 Heavy, qui utilise des outils, a obtenu un score de 44,4 %, surpassant ainsi de manière significative Grok 4, qui n'utilise qu'un seul agent. L'architecture semblait également contribuer à l'ARC-AGI, où Grok 4 a été le premier modèle à dépasser les 10 % et à atteindre 15,9 %, bien qu'il soit difficile de déterminer dans quelle mesure ce résultat est spécifiquement dû à la configuration multi-agents.
Source : xAI
Le compromis réside dans la rapidité et le coût. Grok 4 Heavy fonctionne plus lentement (beaucoup plus lentement !) et son coût d'exploitation est dix fois plus élevé. xAI propose un accès via une formule SuperGrok Heavy à 300 dollars par mois.
Encore une fois, Grok 4 Heavy n'est pas un outil que vous souhaiteriez utiliser pour des recherches basiques ou des itérations rapides. Si Grok 4 est déjà un produit de niche, Grok 4 Heavy l'est encore plus. Il est conçu pour les types de problèmes où plusieurs cheminements de raisonnement peuvent mener à de meilleurs résultats, comme la recherche scientifique, la modélisation financière ou tout ce qui implique une planification à long terme. Dans la plupart des cas, cependant, cela est excessif.
Je teste fréquemment de nouveaux modèles, donc j'ai tendance à réutiliser quelques tâches standard afin de les comparer. Je vais procéder de la même manière ici, en me concentrant sur les mathématiques et le codage. Ceci n'est pas une évaluation approfondie de Grok, mais simplement un moyen de se faire une idée de son comportement dans une configuration de chat classique.
Je souhaiterais commencer par un calcul simple : 9.11 - 9.9. Vous trouverez peut-être cela ridicule, mais cela perturbe souvent les modèles linguistiques :Claude Sonnet 4, par exemple, s'est trompé. Évidemment, je pourrais simplement utiliser une calculatrice, mais l'objectif ici est de voir comment le modèle aborde le problème et s'il peut s'appuyer sur des outils si nécessaire ou le résoudre directement par un raisonnement en chaîne.
Voyons comment Grok 4 a répondu :
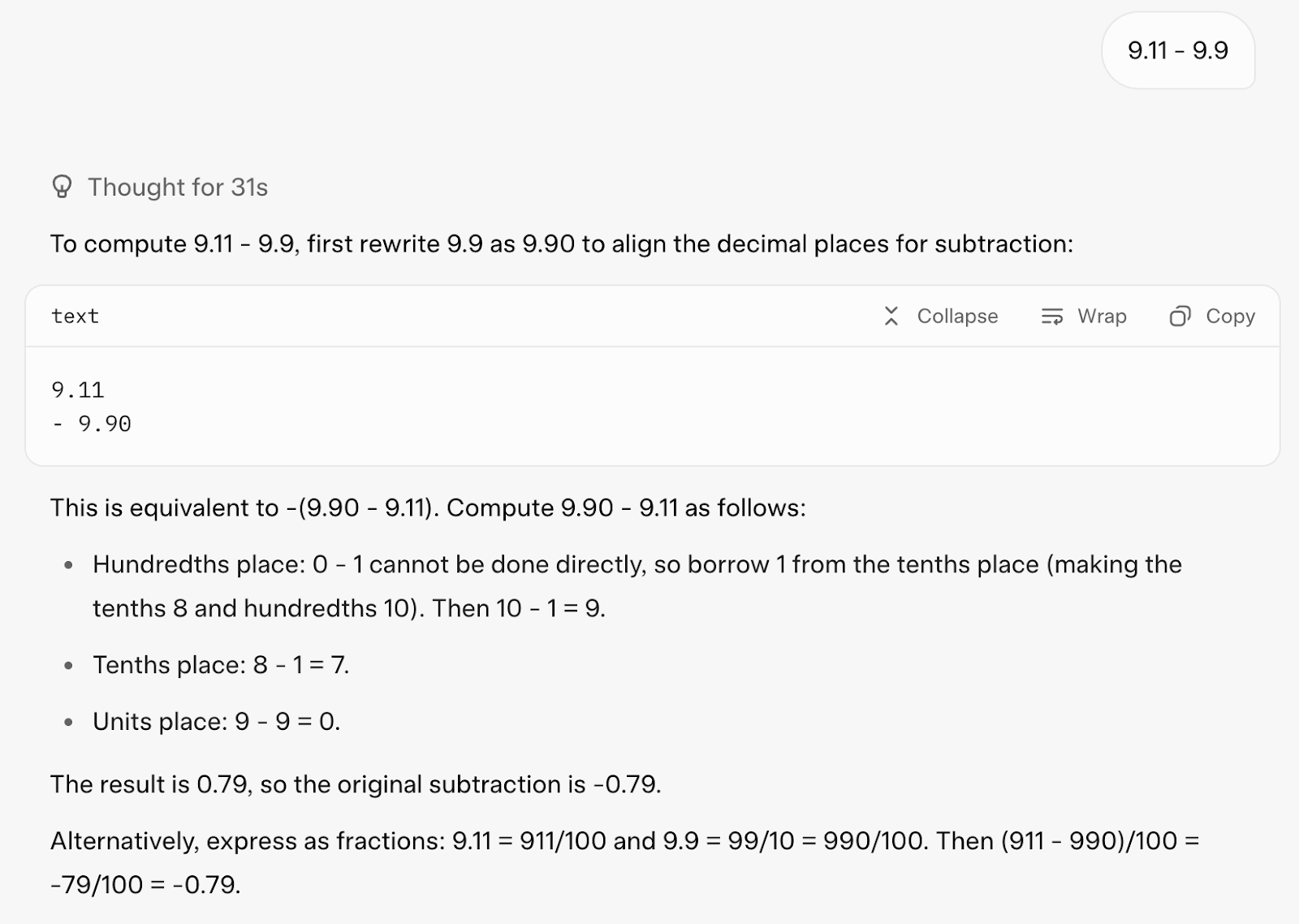
Il a répondu correctement dès la première tentative. Il a trouvé la réponse grâce à son raisonnement logique et a également utilisé un outil de codage pour confirmer sa réponse (ce qui est remarquable !).

Cependant, la réponse a pris 31 secondes et le résultat était excessivement long pour une requête aussi simple.
Ensuite, j'ai souhaité tester Grok 4 sur un problème mathématique plus complexe, susceptible de repousser les limites de la fenêtre contextuelle d'un modèle :
Invite : Utilisez tous les chiffres de 0 à 9 exactement une fois pour former trois nombres x, y, z tels que x + y = z.
Grok 4 a abordé le problème de manière intelligente. Tout d'abord, il s'est rendu compte qu'il pouvait générer les 3 628 800 permutations des chiffres 0 à 9 en quelques secondes à l'aide de Python. Il a ensuite essayé une configuration impliquant deux nombres à trois chiffres dont la somme donne un nombre à quatre chiffres, et a généré un code qui a effectivement renvoyé 96 solutions valides.
from itertools import permutations
digits = range(10)
solutions = []
for p in permutations(digits):
x_digits = p[0:3]
if x_digits[0] == 0: continue
y_digits = p[3:6]
if y_digits[0] == 0: continue
z_digits = p[6:10]
if z_digits[0] == 0: continue
x = int(''.join(map(str, x_digits)))
y = int(''.join(map(str, y_digits)))
z = int(''.join(map(str, z_digits)))
if x + y == z:
solutions.append((x, y, z))
print(solutions)Ensuite, il a essayé d'autres combinaisons (telles que 4 chiffres plus 2 chiffres équivalant à un nombre à 4 chiffres) en utilisant la même approche. À la fin, il a effectué des recherches sur Internet pour en savoir plus sur ce casse-tête mathématique et pour confirmer sa réponse. Il a fallu un total de 157 secondes pour fournir cette réponse :

Pour la tâche de codage, j'ai souhaité comparer les performances de Gemini 2.5 Pro et Claude Opus 4 sur cette tâche :
Invite : Veuillez me créer un jeu de course sans fin captivant. Instructions importantes à l'écran. Scène p5.js, pas de HTML. J'apprécie les dinosaures pixélisés et les arrière-plans intéressants.
Voici le résultat :
Très bien !
Enfin, j'ai souhaité évaluer la capacité de Grok 4 à traiter des tâches multimodales à contexte long. J'ai téléchargé un PDF contenant le rapport de la Commission européenne intitulé « sur les perspectives de l'IA générative (43 087 tokens) et j'ai demandé à Grok de :
s rapides: Veuillez analyser l'intégralité de ce rapport et identifier les trois graphiques les plus informatifs. Veuillez résumer chacun d'entre eux et m'indiquer à quelle page du PDF ils apparaissent.
Voyons d'abord la réponse, puis nous l'analyserons :

J'ai remarqué que cela s'est arrêté étonnamment rapidement, après seulement 25 secondes. Il a recommandé les graphiques des pages 19, 20 et 44 (à tort) et a semblé ignorer le reste du document de 167 pages une fois qu'il a trouvé ce qui semblait être une réponse satisfaisante. Le raisonnement semble incomplet et témoigne d'une approche assez superficielle :

Passons maintenant aux résultats :
Comme l'a souligné Elon Musk lors de la diffusion en direct, la compréhension et la génération d'images de Grok 4 ne sont pas encore très avancées. Si vous recherchez des résultats constants et fiables, je pense qu'il est juste de dire que Grok 4 est actuellement un modèle uniquement textuel.
Grok 4 se distingue principalement par ses performances dans un large éventail de tests de référence, allant des examens universitaires aux simulations commerciales. Selon xAI, le modèle a été considérablement amélioré par rapport aux versions précédentes, principalement grâce à une puissance de calcul accrue, tant pendant l'entraînement que pendant l'inférence, et pas nécessairement grâce à de nouvelles avancées architecturales.
Le modèle central qui sous-tend les performances de Grok 4 est la scalabilité. Il bénéficie d'une plus grande puissance de calcul pour l'entraînement et, plus intéressant encore, d'une plus grandepuissance de calcul pour l' lors des tests.. En termes simples : plus vous y consacrez de ressources, plus il est performant. Cela est particulièrement évident dans ses performances lors des tâches« Humanity's Last Exam » (HLE) de l' .
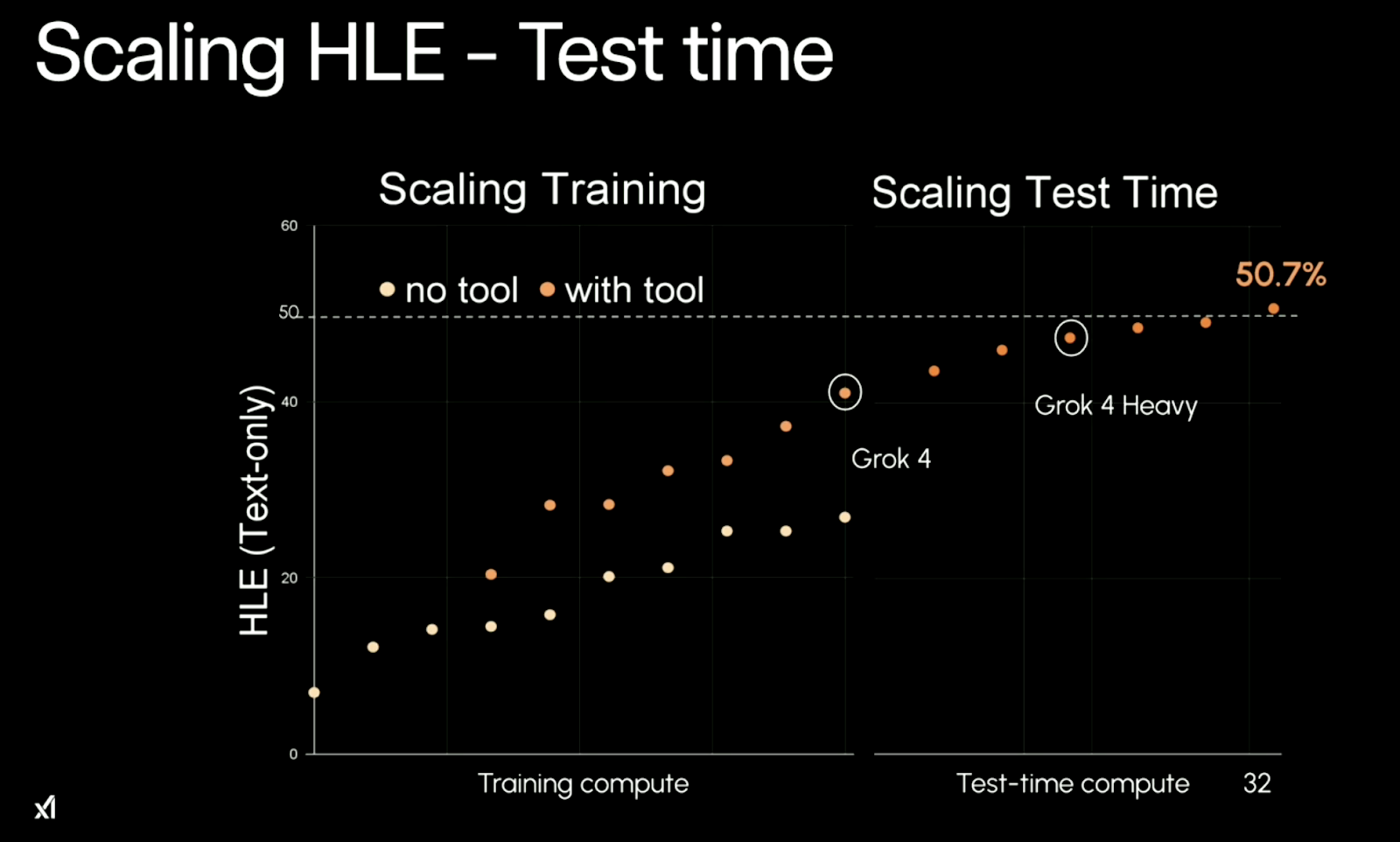
Source : xAI
Sans utilisation d'outils, Grok 4 atteint un plateau à environ 26,9 % de précision en matière d'. Lorsque les outils sont activés (par exemple, l'exécution de code), il atteint 41,0 %. Et lorsqu'il est exécuté dans sa configuration multi-agents « Heavy », il atteint 50,7 %, soit une augmentation considérable qui représente plus du double des meilleurs scores obtenus précédemment sans outil.
Grok 4 obtient également de bons résultats lors d'évaluations plus traditionnelles axées sur les STEM, dont beaucoup sont utilisées dans ce domaine pour comparer les LLM les plus performants. Les points saillants comprennent :
|
Référence |
Modèles concurrents les plus performants |
Grok 4 (sans outils) |
Grok 4 lourd |
|
GPQA |
79.6–86.4% |
87,5 |
88,9 |
|
AIME25 |
75.5–98.8% |
91,7 |
100,0 |
|
LCB (janvier-mai) |
72.0–74.2% |
79,0 |
79,4 |
|
HMMT25 |
58.3–82.5% |
90,0 |
96,7 |
|
USAMO25 |
21.7–49.4% |
37,5 |
61,9 |
Ce sont des résultats solides. Grok 4 surpasse Claude Opus, Gemini 2.5 Pro et GPT-4 (o3) dans la plupart des catégories, bien que certains utilisateurs ont toutefois souligné que les comparaisons pouvaient impliquer une sélection sélective des scores de référence des modèles concurrents.
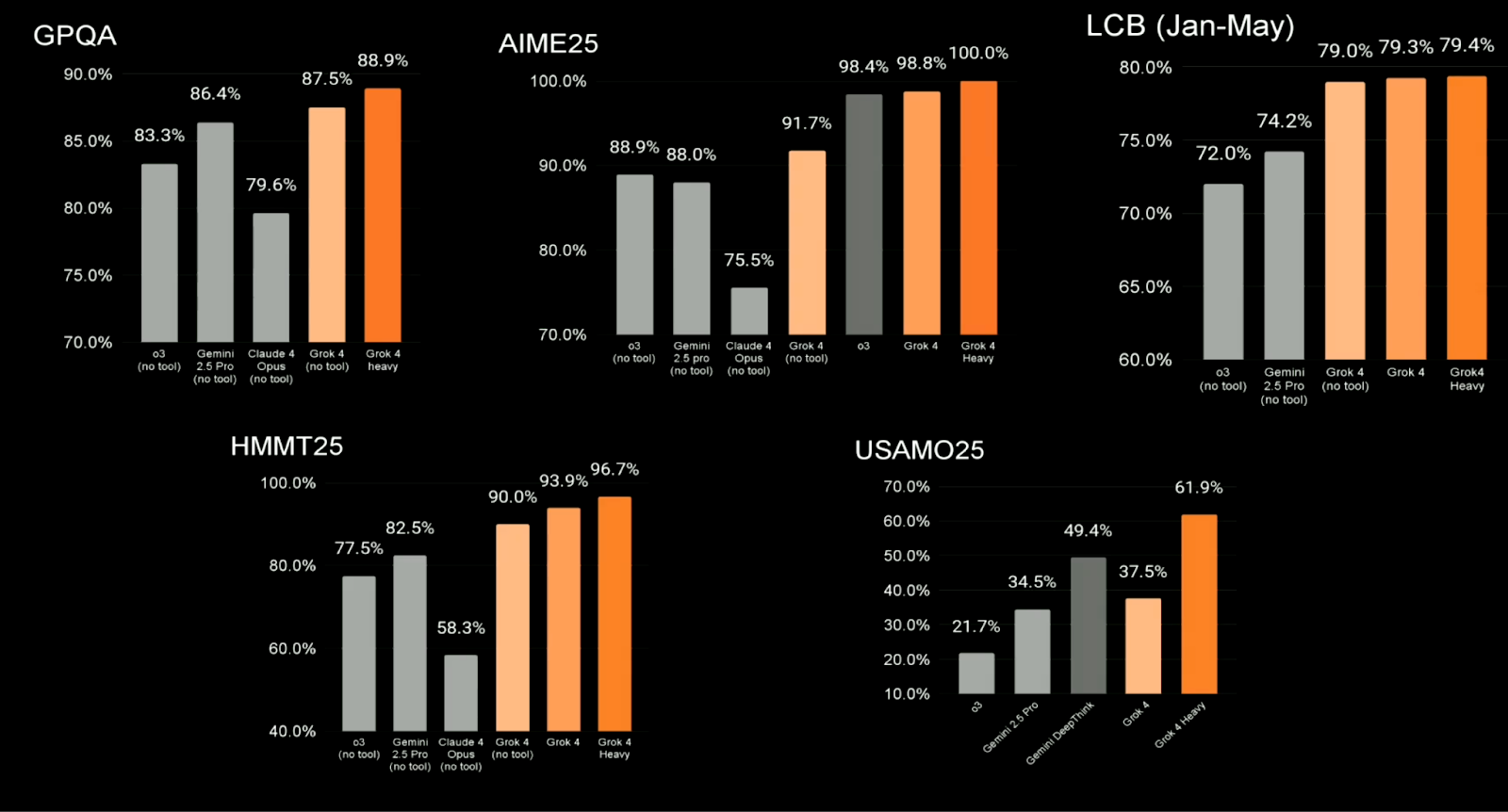
Source : xAI
L'un des critères de référence les plus complexes et les plus opaques est l'ARC-AGI, qui teste la capacité d'un modèle à généraliser à partir de tâches de raisonnement abstrait. Surl'ARC-AGI v1 de l' , Grok 4 obtient un score de 66,6 % (), devançant tous ses concurrents connus. Surl' , ARC-AGI v2 obtient un score de 15,9 %, contre 8,6 % pour Claude 4 Opus.
Ces tests ne sont pas entièrement publics, donc les mises en garde habituelles s'appliquent. Cependant, si les chiffres se confirment, Grok 4 affiche de solides performances dans les tâches de raisonnement en plusieurs étapes et nécessitant une logique poussée.
xAI a également testé Grok 4 dans une simulation en conditions réelles appelée Vending-Bench. L'objectif est de déterminer si un modèle est capable de gérer une petite entreprise sur le long terme : réapprovisionnement des stocks, ajustement des prix, contact avec les fournisseurs, etc. Il s'agit d'un benchmark relativement récent et étonnamment divertissant. Nous avons déjà expliqué en détail son fonctionnement dans une étude de cas consacrée à Claude Sonnet 3.7 dans notre newsletter hebdomadaire. The Median.
Résultats (moyenne sur cinq essais) :
|
Rang |
Modèle |
Valeur nette |
Unités vendues |
|
1 |
Grok 4 |
4 694 $ |
4 569 |
|
2 |
Claude, œuvre n° 4 |
2 077 $ |
1 412 |
|
3 |
Référence humaine |
$ 844 |
344 |
|
4 |
Gemini 2.5 Pro |
$ 789 |
356 |
|
5 |
GPT-4 (o3) |
1 843 $ |
1 363 |
Grok 4 a plus que doublé les performances de son concurrent le plus proche, tant en termes de chiffre d'affaires que d'échelle. Il a également maintenu ses performances de manière constante au cours de 300 cycles de simulation, ce qui représente un défi pour de nombreux modèles confrontés à une planification à long terme.
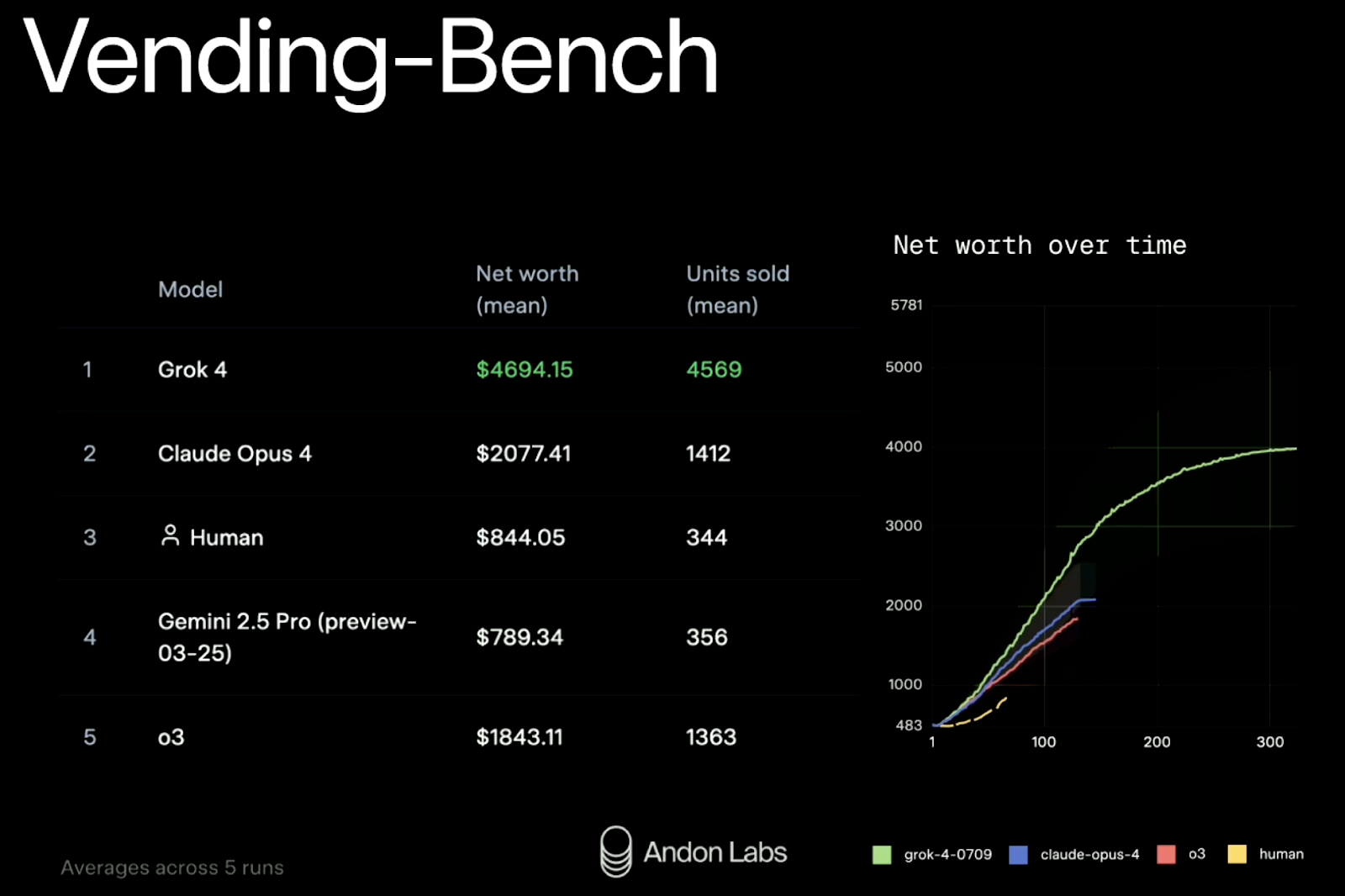
Source : xAI
En résumé : Grok 4 affiche de bonnes performances dans les tests effectués par xAI. Cependant, comme toujours, il est important de ne pas se limiter au classement. Les résultats sont prometteurs, mais ils ne reflètent pas entièrement la réalité, en particulier si votre cas d'utilisation dépend de la vision, de la génération de code ou de l'interaction en temps réel dans des environnements complexes.
Grok 4 est désormais accessible via trois points d'entrée principaux : l'application X, l'API xAI et le site web plateforme grok.com. Que vous souhaitiez discuter avec le modèle, créer avec lui ou tester ses capacités de raisonnement de manière plus formelle, voici comment commencer.
La manière la plus simple d'essayer Grok 4 est d'utiliser l'application X (anciennement Twitter). Cela vous donne accès à Grok dans une interface de chat, similaire à ChatGPT ou Claude.
Pour l'utiliser :
Vous pouvez également utiliser Grok 4 directement via grok.com, qui propose une interface plus claire et autonome en dehors de la plateforme X. Il est destiné aux utilisateurs qui préfèrent une configuration sans distraction.
Si vous souhaitez intégrer Grok à votre propre application ou flux de travail, vous pouvez utiliser l' API xAI.
Étapes :
Avec la sortie de Grok 4, xAI a défini une feuille de route claire (et ambitieuse) pour le reste de l'année 2025. Selon le calendrier présenté lors de la diffusion en direct, quatre lancements majeurs sont prévus au cours des trois prochains mois : un modèle de codage en août, un agent multimodal en septembre et un modèle de génération vidéo en octobre.

Source : xAI
Le premier suivi est un modèle axé sur le codage, prévu pour le mois d'août. Contrairement à Grok 4, qui est un modèle généraliste, celui-ci sera spécialisé et conçu pour traiter le code avec plus de rapidité et de précision. xAI le décrit comme « rapide et intelligent », spécialement formé pour améliorer à la fois la latence et le raisonnement dans les workflows de développement logiciel.
En septembre, nous prévoyons de lancer un agent véritablement multimodal. À l'heure actuelle, Grok 4 prend techniquement en charge les images et les entrées vidéo, mais sa compréhension est limitée. Lors de la diffusion en direct, l'équipe a décrit ce phénomène comme « regarder à travers une vitre givrée ».
La prochaine version vise à corriger cela, en améliorant la perception du modèle à travers les images, les vidéos et les fichiers audio. Ceci sera essentiel pour les cas d'utilisation qui vont au-delà du texte : pensez à la robotique, aux jeux vidéo, au contrôle qualité vidéo ou au suivi d'instructions visuelles.
La dernière version prévue dans le calendrier actuel est un modèle de génération vidéo qui devrait sortir en octobre. xAI indique qu'il sera entraîné sur plus de 100 000 processeurs graphiques. D'après leurs remarques, ce système visera à produire des contenus vidéo de haute qualité, interactifs et modifiables.
Grok 4 représente une avancée significative pour xAI. Il surpasse ses concurrents sur plusieurs benchmarks très difficiles, obtient de bons résultats dans les évaluations mathématiques et scientifiques structurées, et introduit un système multi-agents (Grok 4 Heavy) qui semble prometteur pour la recherche et la réflexion à long terme.
Cela dit, il ne s'agit pas d'un assistant polyvalent pour votre usage quotidien. Il est plus lent que Grok 3, sa compréhension des images et des vidéos en est encore à ses débuts et il manque encore de finesse en termes d'ergonomie au quotidien. Vous devrez formuler vos questions avec soin et raccourcir vos réponses en raison de la fenêtre contextuelle relativement limitée. Et si vous souhaitez bénéficier des meilleures performances, via Grok 4 Heavy, vous devrez payer un supplément.
Pour les développeurs et les chercheurs, cela mérite d'être exploré. Pour les utilisateurs occasionnels, la vitesse et la réactivité du Grok 3 ou d'autres modèles grand public sont plus adaptées. Le calendrier est ambitieux, avec un modèle de codage, un agent multimodal et un générateur de vidéos prévus pour octobre. La question de savoir si xAI sera en mesure de les fournir dans les délais impartis reste toutefois en suspens. Cependant, avec Grok 4, ils ont au moins démontré de manière convaincante qu'ils sont dans la course.
Apprenez l'IA grâce à ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Tutoriel
Samuel Shaibu
Tutoriel
Matt Crabtree
Tutoriel
Mark Pedigo
