
Curso
Building AI Agents with Google ADK
1 h
6.5K
Depois de esperar meses pelo Grok 3.5, a xAI pulou essa versão e foi direto para o Grok 4.
Esse salto tá justificado pelo desempenho do modelo?
Sim, se você julgar pelos benchmarks. No momento, o Grok 4 é provavelmente o melhor modelo do mundo no papel.
Mas com uma janela de contexto de 128.000 no aplicativo e 256.000 na API, você pode ter dificuldades com isso no trabalho real de produção. Não é tão flexível quanto o Gemini 2.5 Pro, que te dá um milhão de tokens. Se você quiser usar o Grok 4 pra mais do que só uma conversa rápida, vai precisar de uma boa habilidades de engenharia de contexto pra fazer isso funcionar.
Neste blog, vou deixar de lado o hype de sempre e dar uma visão geral equilibrada, explicando os principais pontos fortes e fracos do Grok 4, junto com o desempenho dele nos meus próprios testes.
A gente mantém nossos leitores por dentro das últimas novidades em IA com o The Median, nosso boletim informativo gratuito que sai toda sexta-feira e traz as principais notícias da semana. Inscreva-se e fique por dentro em só alguns minutos por semana:
A família Grok 4 inclui só o Grok 4 e o Grok 4 Heavy, e não tem nenhuma versão mini que a gente possa usar pra raciocinar rápido.
O Grok 4 é o mais recente modelo de agente único da xAI (diferente do Grok 4 Heavy, que usa vários agentes — vamos falar sobre isso na próxima seção). Com base na transmissão ao vivo, não tem nada de muito inovador em termos de engenharia. Os ganhos parecem vir de uma série de pequenos ajustes e um aumento significativo na computação, mais ou menos 10 vezes mais do que foi usado no Grok 3.

Fonte: xAI
A empresa diz que é o modelo mais inteligente que existe hoje em dia, e os resultados dos testes mostram isso mesmo. O resultado mais legal veio de Humanity’s Last Exam, um teste que tem 2.500 perguntas escolhidas a dedo, tipo de doutorado, que falam de matemática, física, química, linguística e engenharia. O Grok 4 (com ferramentas) conseguiu resolver cerca de 38,6% dos problemas.

Fonte: xAI
A janela de contexto tem 128.000 tokens no aplicativo e 256.000 na API, o que dá um pouco de espaço para raciocínios mais longos, mas não é muito generoso para os padrões atuais. O Gemini 2.5 Pro, por exemplo, oferece 1 milhão. Se você está construindo com o Grok, provavelmente vai precisar dedicar um tempo para estruturar e ajustar seu contexto com cuidado.
Só pra ficar claro, o Grok 4 não é o modelo ideal pra perguntas do dia a dia, tipo “Vai chover neste fim de semana?” ou “Me encontra um show por perto”. É melhor usar o Grok 3 pra isso — é mais rápido e feito pra tarefas gerais. O Grok 4 é mais adequado para pesquisa, instruções técnicas e perguntas difíceis em matemática, ciências, finanças ou fluxos de trabalho de desenvolvedores que dependem de raciocínio bruto.
Não tá muito claro como ele funciona em fluxos de trabalho mais amplos com consumidores ou como ele lida com a segurança em grande escala. Mas a xAI diz que já tá sendo usada em laboratórios biomédicos, empresas financeiras e parceiros empresariais iniciais.
O Grok 4 Heavy é a versão multiagente do Grok 4. Em vez de rodar um único modelo, ele ativa vários agentes ao mesmo tempo, cada um trabalhando de forma independente na mesma tarefa. Depois de gerar resultados, eles comparam e chegam a uma resposta.
Em teoria, é tipo um grupo de estudo — os agentes podem trocar ideias ou ajudar uns aos outros a ver o que não estão vendo. Na prática, essa configuração ajuda em tarefas de raciocínio complexas, nas quais uma única passagem pode não ser suficiente.
Os ganhos são visíveis nos benchmarks. No último teste da humanidade, o Grok 4 Heavy, que usa ferramentas, tirou 44,4%, superando o Grok 4, que é só um agente, por uma boa margem. A arquitetura também pareceu ajudar com a ARC-AGI, onde o Grok 4 foi o primeiro modelo a ultrapassar os 10% e atingir 15,9% — embora não esteja claro quanto desse resultado se deve especificamente à configuração multiagente.
Fonte: xAI
A troca é velocidade e custo. O Grok 4 Heavy é mais lento (muito mais lento!) e custa dez vezes mais pra funcionar — a xAI tá oferecendo acesso por meio de um plano SuperGrok Heavy de US$ 300 por mês.
Mais uma vez, o Grok 4 Heavy não é algo que você queira usar para pesquisas básicas ou iterações rápidas. Se o Grok 4 já é um produto de nicho, o Grok 4 Heavy é ainda mais. Ele foi feito pra resolver problemas em que várias formas de raciocínio podem levar a resultados melhores — tipo pesquisa científica, modelagem financeira ou qualquer coisa que envolva planejamento de longo prazo. Mas, pra maioria dos casos, isso é um exagero.
Eu testo novos modelos com frequência, então costumo reutilizar algumas tarefas padrão pra ver como elas se comparam. Vou fazer o mesmo aqui, focando em matemática e programação. Isso não é uma avaliação completa do Grok — é só pra gente ter uma ideia de como ele funciona numa conversa normal.
Quero começar com um cálculo simples: 9,11 - 9,9. Você pode achar isso bobo, mas isso costuma confundir os modelos de linguagem —Claude Sonnet 4, por exemplo, entendeu errado. Claro, eu poderia só usar uma calculadora, mas o objetivo aqui é ver como o modelo aborda o problema e se ele pode recorrer a ferramentas, se necessário, ou resolvê-lo diretamente por meio de um raciocínio em cadeia.
Vamos ver como o Grok 4 respondeu:
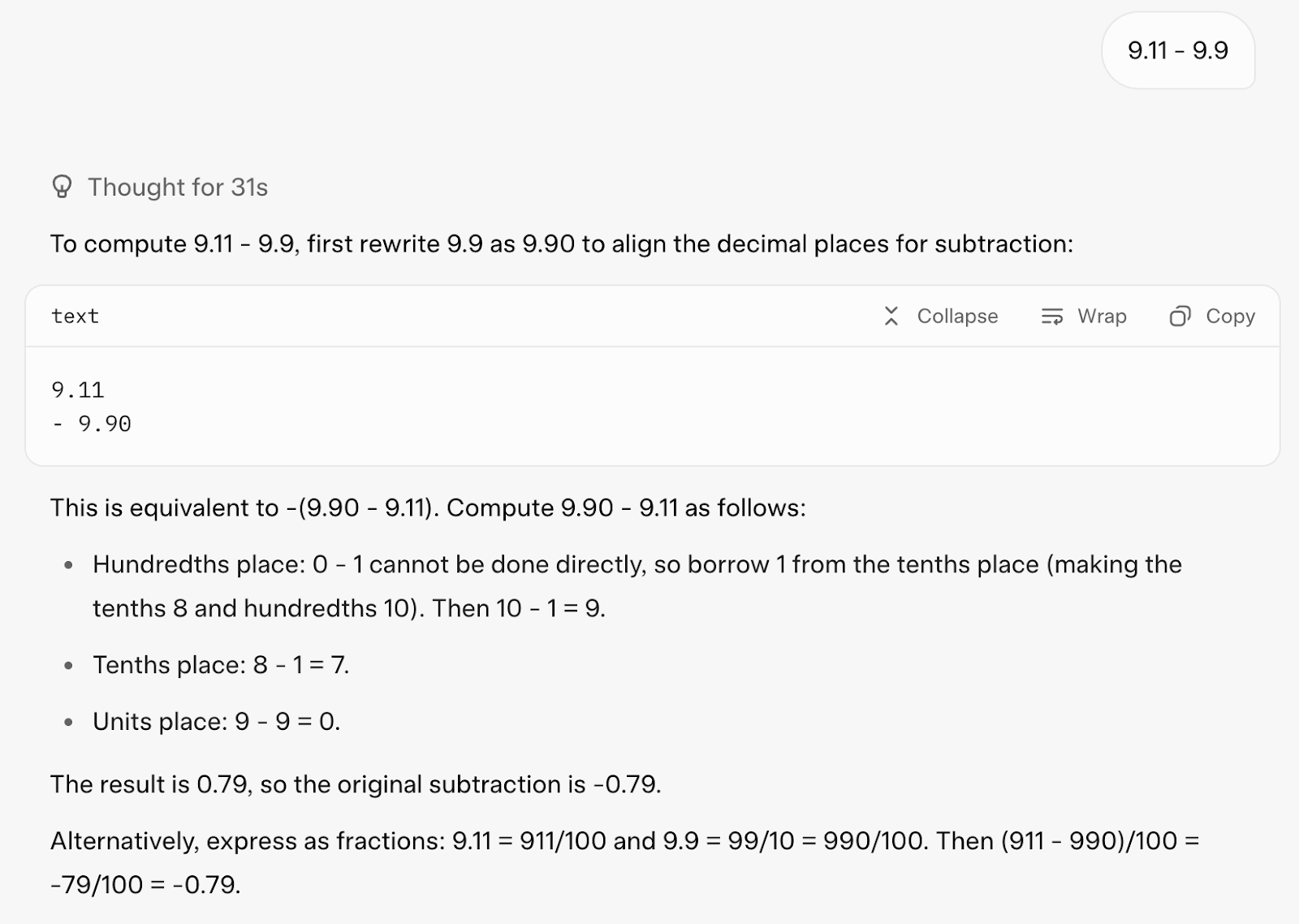
Respondeu certo na primeira tentativa. Ele achou a resposta usando o raciocínio em cadeia e também usou uma ferramenta de código pra confirmar a resposta (o que é ótimo!).

Mas, demorou 31 segundos pra responder e a resposta foi muito longa pra um comando tão simples.
Depois, eu quis testar o Grok 4 num problema matemático mais complicado, que normalmente pode forçar a janela de contexto de um modelo:
Prompt: Use todos os números de 0 a 9 só uma vez pra formar três números x, y, z de forma que x + y = z.
O Grok 4 abordou o problema de um jeito inteligente. Primeiro, percebeu que podia gerar todas as 3.628.800 permutações dos números de 0 a 9 em só alguns segundos usando Python. Depois, tentou uma configuração com dois números de três dígitos que somavam um número de quatro dígitos e conseguiu um código que realmente apresentou 96 soluções válidas!
from itertools import permutations
digits = range(10)
solutions = []
for p in permutations(digits):
x_digits = p[0:3]
if x_digits[0] == 0: continue
y_digits = p[3:6]
if y_digits[0] == 0: continue
z_digits = p[6:10]
if z_digits[0] == 0: continue
x = int(''.join(map(str, x_digits)))
y = int(''.join(map(str, y_digits)))
z = int(''.join(map(str, z_digits)))
if x + y == z:
solutions.append((x, y, z))
print(solutions)Depois, tentou outras combinações (como 4 dígitos mais 2 dígitos que somam um número de 4 dígitos) usando a mesma abordagem. No final, ele procurou na internet pra saber mais sobre esse quebra-cabeça matemático e confirmar a resposta. Demorou um total de 157 segundos para responder:

Pra tarefa de codificação, eu queria ver como ele se compara ao Gemini 2.5 Pro e ao Claude Opus 4 nessa tarefa:
Prompt: Crie um jogo de corrida infinita que seja super envolvente. Instruções importantes na tela. Cena p5.js, sem HTML. Eu curto dinossauros pixelados e fundos legais.
E aí tá o resultado:
Muito bom!
Por fim, eu queria ver como o Grok 4 se sai em tarefas multimodais com contexto longo. Eu carreguei um PDF com o Relatório de Perspectivas sobre IA Generativa da Comissão Europeia. Relatório sobre as perspetivas da IA generativa (43.087 tokens) e pedi ao Grok para:
: Dá uma olhada nesse relatório todo e vê quais são os três gráficos que te dão mais informação. Resuma cada um e me diga em que página do PDF eles aparecem.
Vamos ver a resposta primeiro e depois vamos analisá-la:

Uma coisa que notei é que ele parou bem rápido, só depois de 25 segundos. Recomendou gráficos das páginas 19, 20 e 44 (erroneamente) e pareceu ignorar o resto do documento de 167 páginas assim que encontrou o que parecia ser uma resposta satisfatória. A linha de raciocínio parece incompleta e aponta para uma abordagem meio superficial:

Agora, vamos aos resultados:
Como o Elon Musk falou na transmissão ao vivo, a compreensão e geração de imagens do Grok 4 ainda não estão muito avançadas. Se você quer resultados constantes e confiáveis, acho que dá pra dizer que o Grok 4 é um modelo só de texto no momento.
O principal motivo da fama do Grok 4 é o seu desempenho em vários tipos de testes, desde exames acadêmicos até simulações de negócios. De acordo com a xAI, o modelo melhorou bastante em relação às versões anteriores, principalmente por causa de mais poder de computação — tanto durante o treinamento quanto na inferência — e não necessariamente por causa de novos avanços na arquitetura.
O padrão central por trás do desempenho do Grok 4 é a escalabilidade. Ele aproveita mais poder de computação de treinamento e, o que é mais legal, maispoder de computação de teste e . Em termos simples: quanto mais recursos você investe, melhor ele funciona. Isso fica bem claro no desempenho dele nas tarefasdo Humanity’s Last Exam (HLE, ou Último Exame da Humanidade) do .
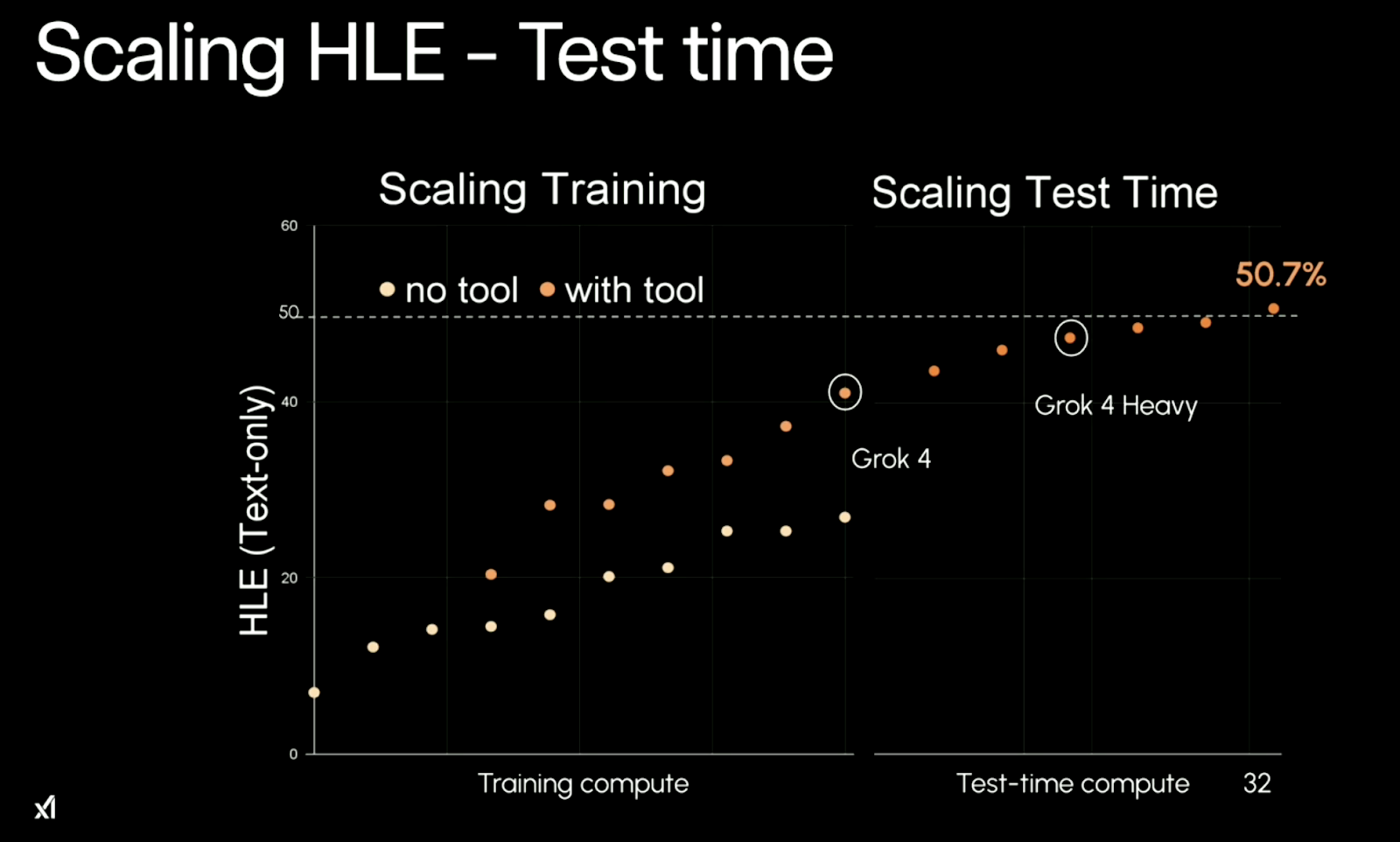
Fonte: xAI
Sem usar ferramentas, o Grok 4 fica estagnado em cerca de 26,9% de precisão no teste “ ”. Com as ferramentas ativadas (por exemplo, execução de código), ele atinge 41,0%. E quando rodado na configuração multiagente “Heavy”, ele chega a 50,7%— um salto enorme que é mais que o dobro das melhores pontuações anteriores de modelos sem ferramentas.
O Grok 4 também se sai bem em avaliações mais tradicionais focadas em STEM, muitas das quais são usadas em toda a área para comparar LLMs de alto desempenho. Os destaques incluem:
|
Benchmark |
Principais modelos concorrentes |
Grok 4 (Sem ferramentas) |
Grok 4 Pesado |
|
GPQA |
79,6–86,4% |
87,5% |
88,9% |
|
AIME25 |
75,5–98,8% |
91,7% |
100,0% |
|
LCB (janeiro–maio) |
72,0–74,2% |
79,0% |
79,4% |
|
HMMT25 |
58,3–82,5% |
90,0% |
96,7% |
|
USAMO25 |
21,7–49,4% |
37,5% |
61,9% |
São resultados bem legais. O Grok 4 está superando o Claude Opus, o Gemini 2.5 Pro e o GPT-4 (o3) na maioria das categorias, embora alguns usuários disseram que as comparações podem estar escolhendo as melhores pontuações dos modelos concorrentes.
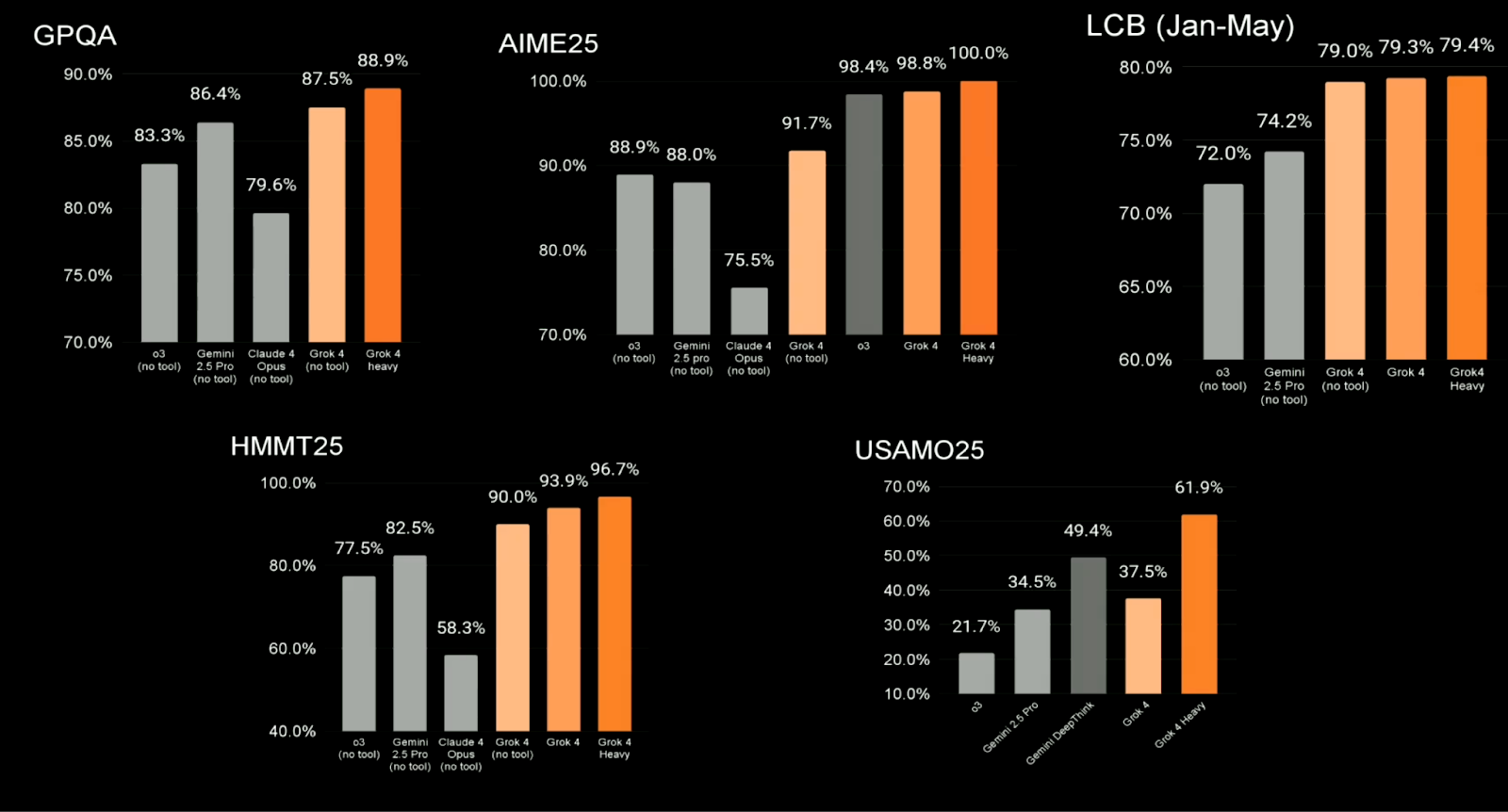
Fonte: xAI
Um dos benchmarks mais difíceis e obscuros é o ARC-AGI, que testa a capacidade de um modelo de generalizar tarefas de raciocínio abstrato. Emum ARC-AGI v1 d , o Grok 4 conseguiu 66,6%, ficando à frente de todos os outros conhecidos. Num teste de ARC-AGI v2, ele tirou 15,9%, comparado com os 8,6% do Claude 4 Opus.
Esses testes não são totalmente públicos, então vale as ressalvas de sempre. Mas, se os números continuarem assim, o Grok 4 tá mostrando um desempenho forte em tarefas de raciocínio com várias etapas e cheias de lógica.
A xAI também testou o Grok 4 numa simulação do mundo real chamada Vending-Bench. A ideia é ver se um modelo consegue gerir uma pequena empresa ao longo do tempo: reabastecer o estoque, ajustar preços, entrar em contato com fornecedores, etc. É um benchmark relativamente novo e surpreendentemente divertido. Já falamos sobre como isso funciona em detalhes através de um estudo de caso da Claude Sonnet 3.7 em nosso boletim informativo semanal, The Median.
Resultados (média de cinco execuções):
|
Classificação |
Modelo |
Patrimônio líquido |
Unidades vendidas |
|
1 |
Entender 4 |
$4,694 |
4.569 |
|
2 |
Claude Obra 4 |
$2,077 |
1.412 |
|
3 |
Linha de base humana |
$ 844 |
344 |
|
4 |
Gemini 2.5 Pro |
$ 789 |
356 |
|
5 |
GPT-4 (o3) |
$1,843 |
1.363 |
A Grok 4 mais do que dobrou o desempenho do seu concorrente mais próximo, tanto em receita quanto em escala. Ele também manteve seu desempenho consistente ao longo de 300 rodadas de simulação — algo que muitos modelos têm dificuldade quando enfrentam um planejamento de longo prazo.
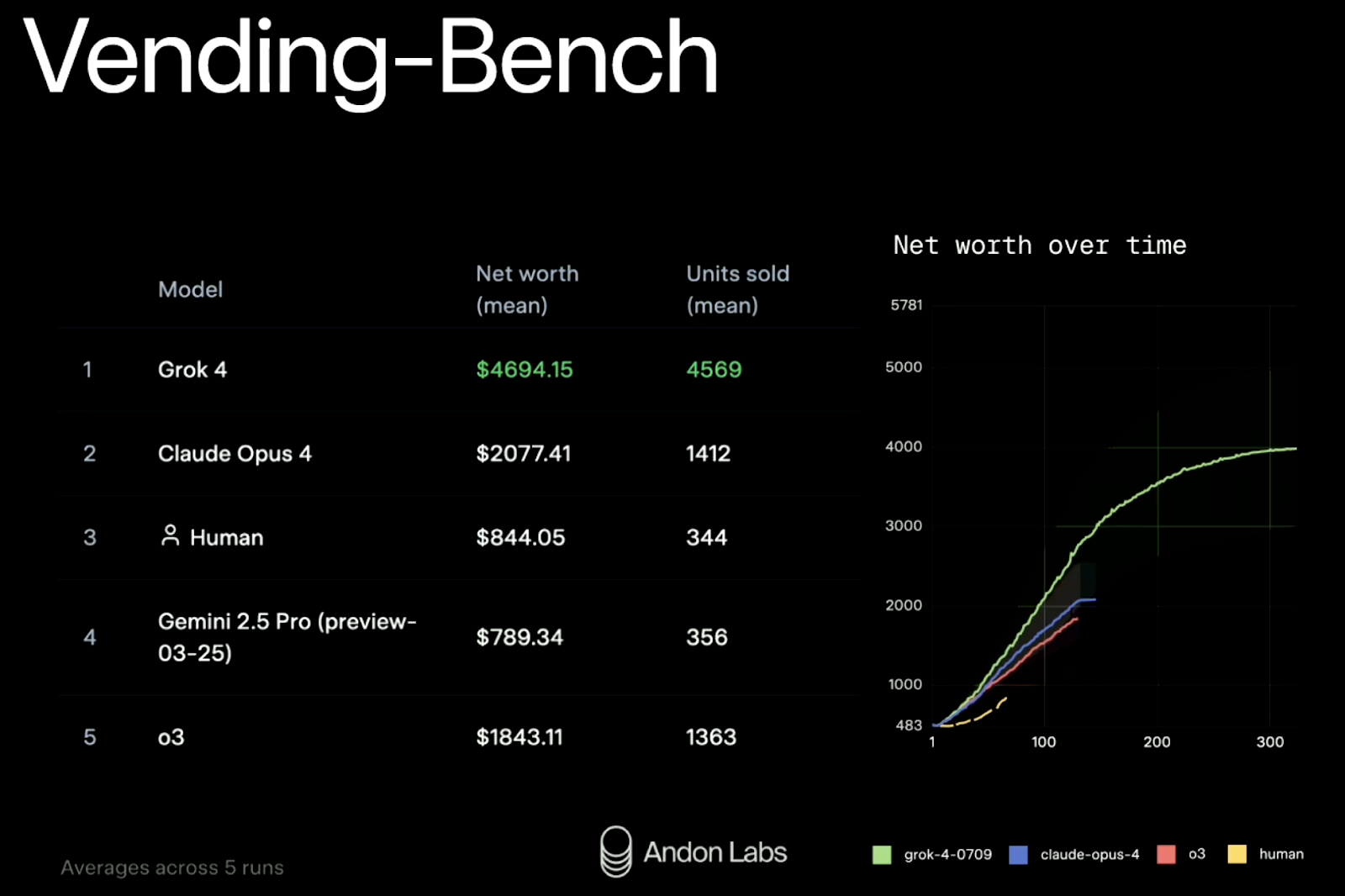
Fonte: xAI
Resumindo: O Grok 4 funciona bem onde a xAI testou. Mas, como sempre, você deve olhar além do quadro de líderes. Os benchmarks são promissores, mas não contam toda a história, especialmente se o seu caso de uso depende de visão, geração de código ou interação em tempo real em ambientes confusos.
O Grok 4 já está disponível através de três pontos de entrada principais: o aplicativo X, a API xAI e o plataforma grok.com. Quer você queira bater um papo com o modelo, construir algo com ele ou testar suas capacidades de raciocínio de forma mais formal, veja aqui como começar.
A maneira mais fácil de experimentar o Grok 4 é pelo app X (antigo Twitter). Isso te dá acesso ao Grok dentro de uma interface de chat, tipo o ChatGPT ou o Claude.
Como usar:
Você também pode usar o Grok 4 direto pelo grok.com, que tem uma interface mais simples e independente, fora da plataforma X. É feito pra quem curte uma configuração sem distrações.
Se você quiser integrar o Grok no seu próprio aplicativo ou fluxo de trabalho, pode usar a API xAI.
Passos:
Com o lançamento do Grok 4, a xAI traçou um plano claro (e ambicioso) para o resto de 2025. De acordo com o cronograma mostrado durante a transmissão ao vivo, quatro grandes lançamentos estão previstos para os próximos três meses: um modelo de codificação em agosto, um agente multimodal em setembro e um modelo de geração de vídeo em outubro.

Fonte: xAI
O primeiro acompanhamento é um modelo focado em codificação, previsto para agosto. Diferente do Grok 4, que é mais genérico, esse vai ser um modelo especializado, feito pra lidar com código de forma mais rápida e precisa. A xAI disse que ele é “rápido e inteligente”, treinado especialmente pra melhorar tanto a latência quanto o raciocínio nos fluxos de trabalho de desenvolvimento de software.
Em setembro, a ideia é lançar um agente que seja realmente multimodal. No momento, o Grok 4 suporta tecnicamente imagens e entradas de vídeo, mas sua compreensão é limitada — durante a transmissão ao vivo, a equipe descreveu isso como “olhar através de um vidro fosco”.
A próxima versão quer resolver isso, deixando o modelo mais forte na percepção de imagens, vídeos e áudio. Isso vai ser essencial pra casos de uso que vão além do texto: tipo robótica, jogos, controle de qualidade de vídeo ou seguir instruções visuais.
O lançamento final na linha do tempo atual é um modelo de geração de vídeo previsto para outubro. A xAI diz que vai treinar o modelo em mais de 100.000 GPUs. Pelo que eles falaram, esse sistema vai tentar criar conteúdo de vídeo de alta qualidade, interativo e que dá pra editar.
O Grok 4 é um grande passo pra frente pra xAI. Ele supera os concorrentes em vários benchmarks de alta dificuldade, se sai bem em avaliações estruturadas de matemática e ciências e traz um sistema multiagente (Grok 4 Heavy) que parece promissor para ambientes de pesquisa e pensamento de longo prazo.
Dito isso, não é um assistente geral pra usar todo dia. É mais lento que o Grok 3, a compreensão de imagens e vídeos ainda tá no começo e falta um pouco de acabamento na usabilidade no dia a dia. Você vai precisar pedir com cuidado e cortar suas entradas por causa da janela de contexto relativamente pequena. E se você quer o melhor desempenho — com o Grok 4 Heavy — vai ter que pagar um pouco mais por isso.
Para desenvolvedores e pesquisadores, vale a pena dar uma olhada. Para usuários casuais, a velocidade e a capacidade de resposta do Grok 3 ou de outros modelos convencionais são mais adequadas. O plano é bem ambicioso, com um modelo de codificação, um agente multimodal e um gerador de vídeo, tudo pronto até outubro. Se a xAI vai conseguir entregar tudo na hora certa é outra história. Mas com o Grok 4, eles pelo menos mostraram que estão na disputa.
Aprenda IA com esses cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Richie Cotton
7 min
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan
Tutorial
Dimitri Didmanidze
Tutorial
Josep Ferrer


