
Course
Building AI Agents with Google ADK
1 hr
6.5K
After we waited months for Grok 3.5, xAI skipped it altogether and jumped straight to Grok 4. (As of November 2025, Grok 4.1 has also launched).
Is the jump justified by the model’s performance?
Yes, if you judge by the benchmarks. Right now, Grok 4 is probably the best model in the world on paper.
But with a context window of 128,000 in the app and 256,000 in the API, you might struggle with it in real production work. It’s not as forgiving as Gemini 2.5 Pro, which gives you a full million tokens. If you want to use Grok 4 for more than just a short chat, you’ll need some serious context engineering skills to make it work.
In this blog, I’ll cut through the usual hype and give you a balanced overview by explaining the main strengths and weaknesses of Grok 4, along with how it performed in my own tests.
We keep our readers updated on the latest in AI by sending out The Median, our free Friday newsletter that breaks down the week’s key stories. Subscribe and stay sharp in just a few minutes a week:
The Grok 4 family includes only Grok 4 and Grok 4 Heavy, and there’s no mini version that we can use for fast reasoning.
Grok 4 is xAI’s latest single-agent model (unlike Grok 4 Heavy, which uses multiple agents—we’ll get to that in the next section). Based on the livestream, there’s nothing particularly groundbreaking in terms of engineering. The gains seem to come from a series of smaller tweaks and a significant increase in compute, roughly 10x more than what was used for Grok 3.

Source: xAI
The company claims it’s the most intelligent model available today, and benchmark results do point in that direction. The most notable result came from Humanity’s Last Exam, a benchmark made up of 2,500 hand-curated, PhD-level questions spanning math, physics, chemistry, linguistics, and engineering. Grok 4 (with tools) managed to solve about 38.6% of the problems.

Source: xAI
The context window is 128,000 tokens in the app and 256,000 in the API, which gives some room for long-form reasoning but isn’t especially generous by current standards. Gemini 2.5 Pro, for example, offers 1 million. If you’re building with Grok, you’ll likely need to spend time structuring and pruning your context carefully.
Just to be clear, Grok 4 isn’t your go-to model for everyday questions like “Is it going to rain this weekend?” or “Find me a concert nearby.” You’re better off using Grok 3 for that—it’s faster and built for general-purpose tasks. Grok 4 is better suited for research, technical prompts, and hard questions in math, science, finance, or developer workflows that rely on raw reasoning.
It’s less clear how it performs in broader consumer workflows or how well it handles safety at scale. But xAI says it’s already in use at biomedical labs, financial firms, and early enterprise partners.
Grok 4 Heavy is the multi-agent version of Grok 4. Instead of running a single model, it spins up several agents in parallel, each working independently on the same task. Once they’ve generated outputs, they compare results and converge on an answer.
In theory, it’s similar to a study group—agents can share insights or pick up on each other’s blind spots. In practice, this setup helps with complex reasoning tasks where a single pass might fall short.
The gains are visible in benchmarks. On Humanity’s Last Exam, Grok 4 Heavy with tool use scored 44.4%, outperforming the single-agent Grok 4 by a noticeable margin. The architecture also seemed to help with ARC-AGI, where Grok 4 was the first model to break 10% and reach 15.9%—though it’s unclear how much of that result was due to the multi-agent setup specifically.
Source: xAI
The trade-off is speed and cost. Grok 4 Heavy runs slower (much slower!), and it’s ten times more expensive to operate—xAI is offering access through a $300/month SuperGrok Heavy tier.
Again, Grok 4 Heavy is not something you’d want to use for basic lookups or fast iteration. If Grok 4 is already niche, Grok 4 Heavy is even more so. It’s built for the kinds of problems where multiple reasoning paths can lead to better outcomes—think scientific research, financial modeling, or anything involving long-horizon planning. For most use cases, though, it’s overkill.
For a visual demo of Grok 4, don’t miss our walkthrough video:
I test new models often, so I tend to reuse a few standard tasks to see how they compare. I’ll do the same here, focusing on math and coding. This isn’t meant to be a thorough evaluation of Grok—just a way to get a feel for how it behaves in a typical chat setup.
I want to start with a simple calculation: 9.11 - 9.9. You might find this silly, but it often confuses language models—Claude Sonnet 4, for example, got it wrong. Obviously, I could just use a calculator, but the goal here is to see how the model approaches the problem and whether it can fall back on tools if needed or solve it directly through chain-of-thought reasoning.
Let’s see how Grok 4 answered:
It answered correctly on the first attempt. It found the answer through its chain-of-thought reasoning, and also used a code tool to confirm the answer (which is great!).

However, it took 31 seconds to respond, and the output was overly long for such a simple prompt.
Next, I wanted to test Grok 4 on a more complex math problem that can typically push a model’s context window:
Prompt: Use all digits from 0 to 9 exactly once to make three numbers x, y, z such that x + y = z.
Grok 4 approached the problem intelligently. First, it realized it could generate all 3,628,800 permutations of the numbers 0–9 in just a few seconds using Python. Then it tried a setup involving two 3-digit numbers that sum to a 4-digit number, and came up with code that actually returned 96 valid solutions!
from itertools import permutations
digits = range(10)
solutions = []
for p in permutations(digits):
x_digits = p[0:3]
if x_digits[0] == 0: continue
y_digits = p[3:6]
if y_digits[0] == 0: continue
z_digits = p[6:10]
if z_digits[0] == 0: continue
x = int(''.join(map(str, x_digits)))
y = int(''.join(map(str, y_digits)))
z = int(''.join(map(str, z_digits)))
if x + y == z:
solutions.append((x, y, z))
print(solutions)Then, it tried other combinations (like 4-digit plus 2-digit equalling a 4-digit number) using the same approach. At the end, it searched the web to find more about this math puzzle and to confirm its answer. It took a total of 157 seconds to provide this answer:

For the coding task, I wanted to see how it compares to Gemini 2.5 Pro and Claude Opus 4 on this task:
Prompt: Make me a captivating endless runner game. Key instructions on the screen. p5.js scene, no HTML. I like pixelated dinosaurs and interesting backgrounds.
Here’s the result:
Pretty good!
Lastly, I wanted to see how well Grok 4 handles long-context multimodal tasks. I uploaded a PDF with the European Commission’s Generative AI Outlook Report (43,087 tokens) and asked Grok to:
Prompt: Analyze this entire report and identify the three most informative graphs. Summarize each one and let me know which page of the PDF they appear on.
Let’s see the answer first, and then we’ll unpack it:

One thing I noticed is that it stopped surprisingly quickly, after just 25 seconds. It recommended graphs from pages 19, 20, and 44 (wrongly), and seemed to ignore the rest of the 167-page document once it found what looked like a satisfactory answer. The chain-of-thought feels incomplete and points to a fairly shallow approach:

Now, on to the results:
As Elon Musk pointed out in the livestream, Grok 4’s image understanding and generation still isn’t very advanced. If you want constant and reliable results, I think it’s fair to say that Grok 4 is a text-only model at the moment.
Grok 4’s main claim to fame is its performance across a wide mix of benchmarks, from academic exams to business simulations. According to xAI, the model improves significantly over previous versions thanks mostly to more compute—both during training and inference—not necessarily because of new architectural breakthroughs.
The core pattern behind Grok 4’s performance is scaling. It benefits from more training compute and, more interestingly, from more test-time compute. In simple terms: the more resources you throw at it, the better it performs. This is particularly clear in its performance on Humanity’s Last Exam (HLE) tasks.
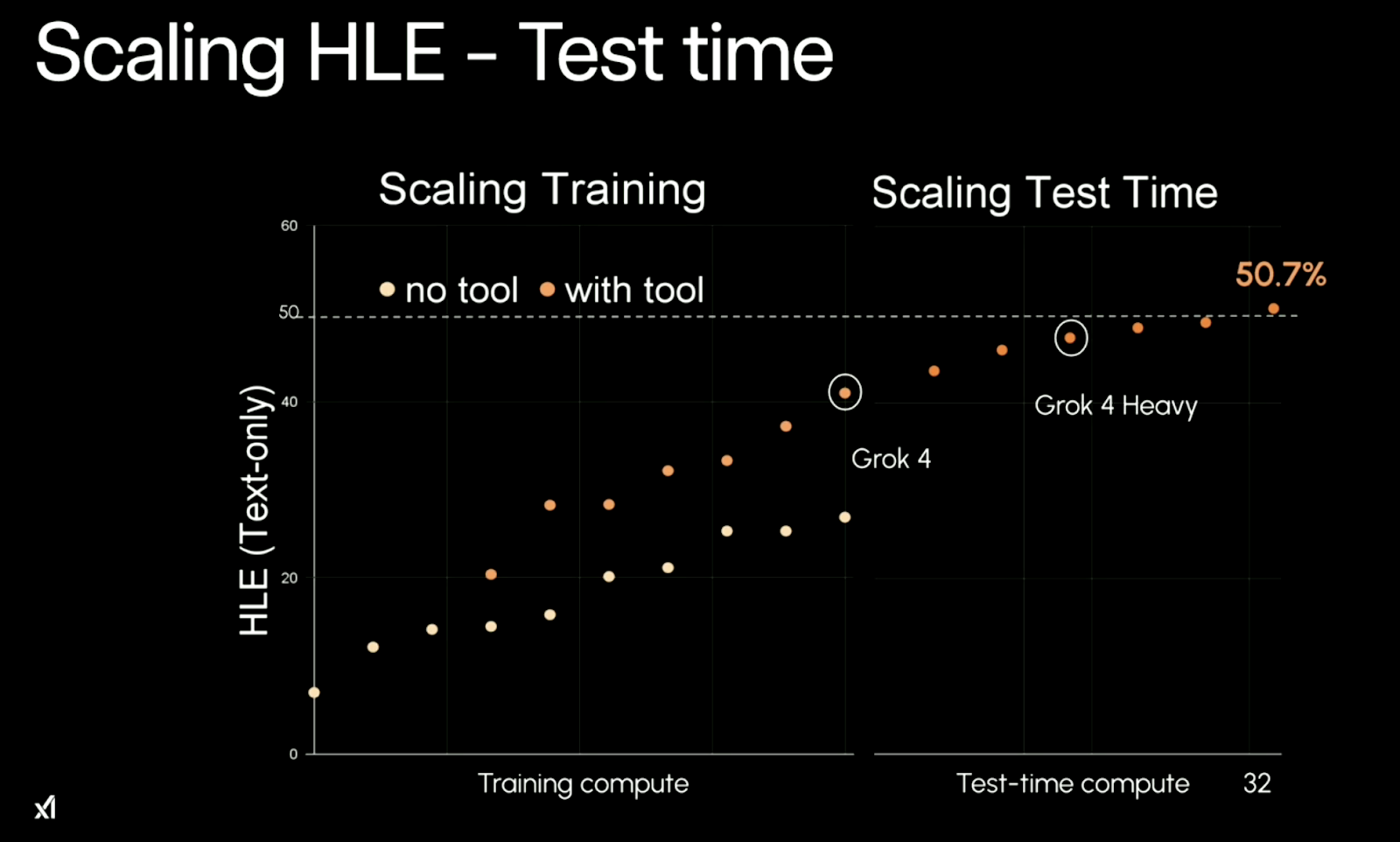
Source: xAI
With no tool use, Grok 4 plateaus at around 26.9% accuracy. With tools enabled (e.g., code execution), it hits 41.0%. And when run in its multi-agent “Heavy” configuration, it climbs to 50.7%—a major jump that’s over double the best prior tool-free model scores.
Grok 4 also does well on more traditional STEM-focused evaluations, many of which are used across the field for comparing high-performing LLMs. Highlights include:
|
Benchmark |
Top Competing Models |
Grok 4 (No Tools) |
Grok 4 Heavy |
|
GPQA |
79.6–86.4% |
87.5% |
88.9% |
|
AIME25 |
75.5–98.8% |
91.7% |
100.0% |
|
LCB (Jan–May) |
72.0–74.2% |
79.0% |
79.4% |
|
HMMT25 |
58.3–82.5% |
90.0% |
96.7% |
|
USAMO25 |
21.7–49.4% |
37.5% |
61.9% |
These are solid results. Grok 4 is outperforming Claude Opus, Gemini 2.5 Pro, and GPT-4 (o3) in most categories, though some users have pointed out that the comparisons may involve cherry-picking baseline scores from competing models.
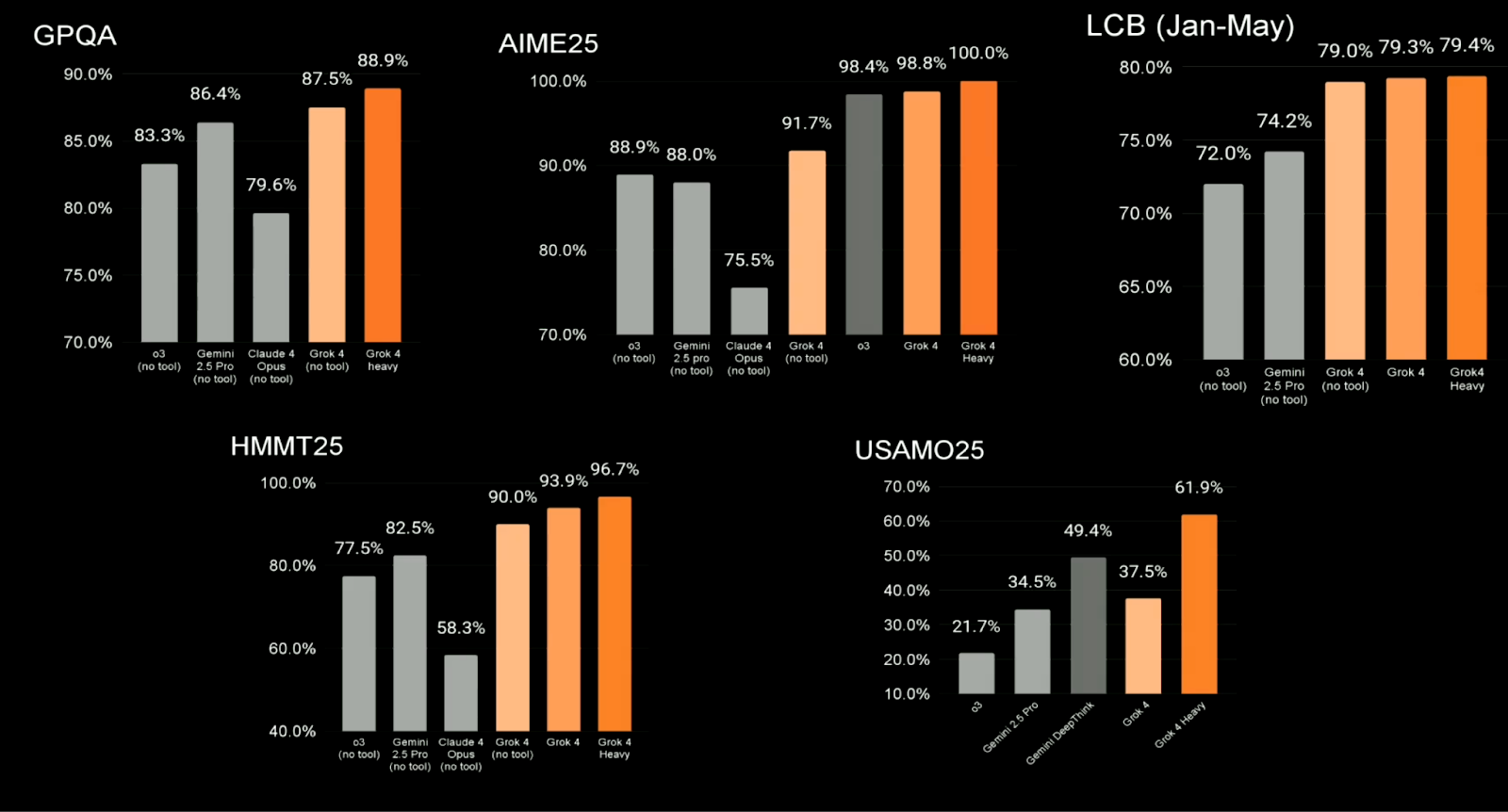
Source: xAI
One of the more difficult and opaque benchmarks is ARC-AGI, which tests a model’s ability to generalize across abstract reasoning tasks. On ARC-AGI v1, Grok 4 scores 66.6%, ahead of all known peers. On ARC-AGI v2, it scores 15.9%, compared to Claude 4 Opus’s 8.6%.
These tests aren’t fully public, so the usual caveats apply. But if the numbers hold, Grok 4 is showing strong performance in multi-step, logic-heavy reasoning tasks.
xAI also tested Grok 4 in a real-world simulation called Vending-Bench. The idea is to see whether a model can manage a small business over time: restocking inventory, adjusting prices, contacting suppliers, etc. It’s a fairly new benchmark and a surprisingly fun one. We previously covered how it works in detail through a Claude Sonnet 3.7 case study in our weekly newsletter, The Median.
Results (averaged across five runs):
|
Rank |
Model |
Net Worth |
Units Sold |
|
1 |
Grok 4 |
$4,694 |
4,569 |
|
2 |
Claude Opus 4 |
$2,077 |
1,412 |
|
3 |
Human baseline |
$ 844 |
344 |
|
4 |
Gemini 2.5 Pro |
$ 789 |
356 |
|
5 |
GPT-4 (o3) |
$1,843 |
1,363 |
Grok 4 more than doubled the performance of its closest competitor in both revenue and scale. It also maintained its performance consistently over 300 rounds of simulation—something many models struggle with when faced with long-horizon planning.
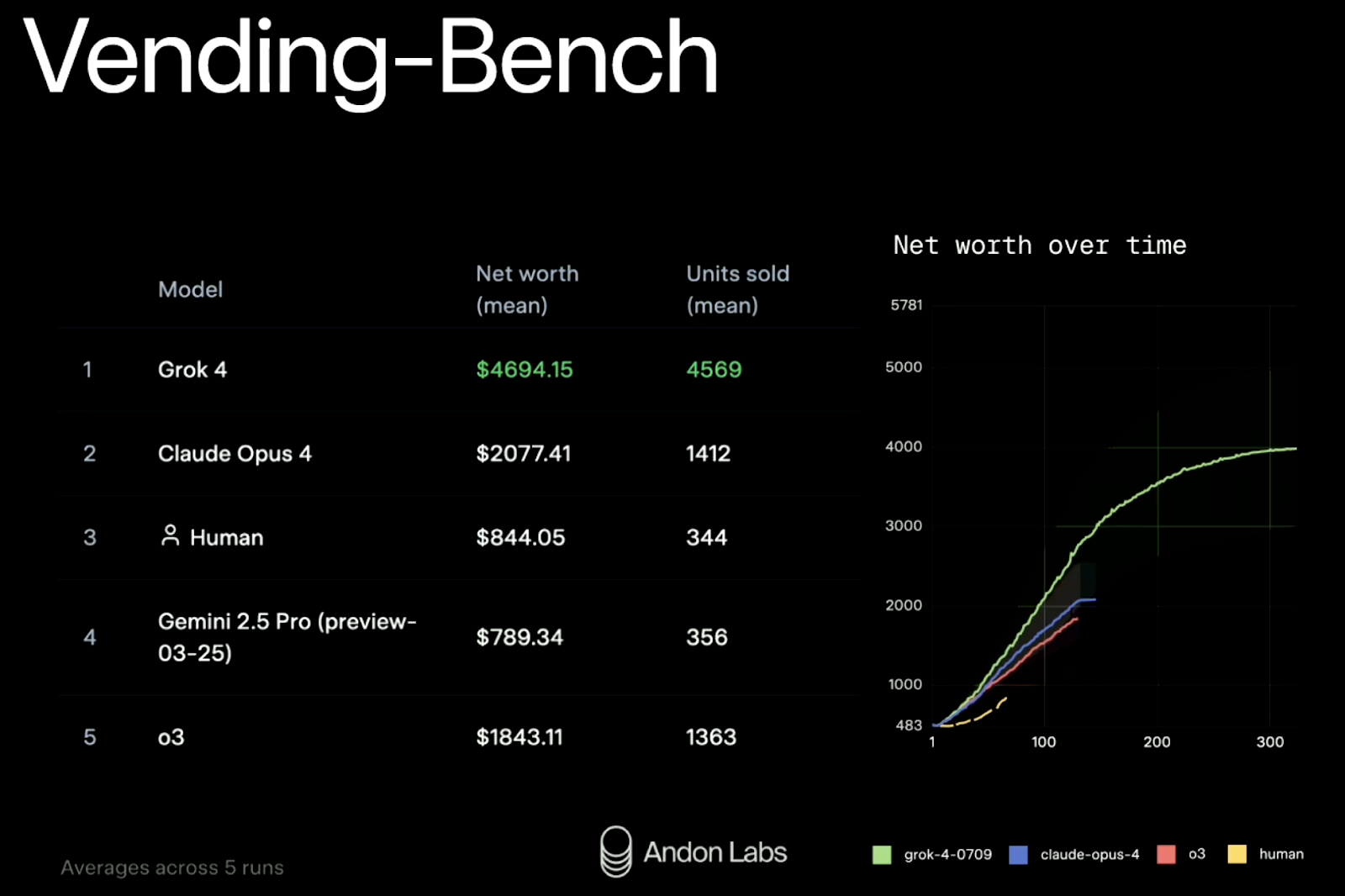
Source: xAI
In short: Grok 4 performs well where xAI has tested it. But as always, you should look beyond the leaderboard. The benchmarks are promising, but they don’t tell the whole story—especially if your use case depends on vision, code generation, or real-time interaction in messy environments.
Grok 4 is now available through three main entry points: the X app, the xAI API, and the grok.com platform. Whether you want to chat with the model, build with it, or test its reasoning capabilities more formally, here’s how to get started.
The easiest way to try Grok 4 is through the X app (formerly Twitter). This gives you access to Grok inside a chat interface, similar to ChatGPT or Claude.
To use it:
You can also use Grok 4 directly through grok.com, which offers a cleaner, standalone interface outside the X platform. It’s aimed at users who prefer a distraction-free setup.
If you want to integrate Grok into your own app or workflow, you can use the xAI API.
Steps:
With Grok 4 now released, xAI laid out a clear (and ambitious) roadmap for the rest of 2025. According to the timeline shown during the livestream, four major releases are lined up in the next three months: a coding model in August, a multi-modal agent in September, and a video generation model in October.

Source: xAI
The first follow-up is a coding-focused model expected in August. Unlike Grok 4, which is a generalist, this will be a specialized model designed to handle code with more speed and accuracy. xAI described it as “fast and smart,” trained specifically to improve both latency and reasoning in software development workflows.
In September, the plan is to release a truly multi-modal agent. Right now, Grok 4 technically supports images and video inputs, but its understanding is limited—during the livestream, the team described it as “squinting through frosted glass.”
The upcoming version aims to correct that, giving the model’s stronger perception across image, video, and audio. This will be key for use cases that go beyond text: think robotics, game playing, video QA, or visual instruction-following.
The final release in the current timeline is a video generation model due in October. xAI says they’ll be training it on over 100,000 GPUs. Based on their remarks, this system will aim to produce high-quality, interactive, and editable video content.
Grok 4 is a serious step forward for xAI. It outperforms competitors on several high-difficulty benchmarks, holds up well in structured math and science evaluations, and introduces a multi-agent system (Grok 4 Heavy) that shows promise for research settings and long-horizon thinking.
That said, it’s not your day-to-day general-purpose assistant. It’s slower than Grok 3, its image and video understanding are still early-stage, and it lacks some polish when it comes to everyday usability. You’ll need to prompt carefully and trim your inputs due to the relatively limited context window. And if you want the best performance—via Grok 4 Heavy—you’ll be paying a premium for it.
For developers and researchers, it’s worth exploring. For casual users, the speed and responsiveness of Grok 3 or other mainstream models are a better fit. The roadmap is ambitious, with a coding model, multimodal agent, and video generator all due by October. Whether xAI can deliver those on time is another question. But with Grok 4, they’ve at least made a compelling case that they’re in the race.
Learn AI with these courses!
Course
Course
Course
blog
Alex Olteanu
8 min
blog
Matt Crabtree
7 min
blog
Alex Olteanu
8 min
Tutorial
Tom Farnschläder
Tutorial
Tom Farnschläder
Tutorial
Aashi Dutt

