
Track
Developing Large Language Models
16 hr
Recently, the field of large language models (LLMs) has been changing quickly. Newer LLMs are being designed to be smaller and smarter, making them less expensive and easier to use compared to the larger models.
With the release of Llama 3.2, we now have access to smaller models, such as the 1B and 3B variants. While these smaller models may not match the accuracy of larger models in general tasks, they can be fine-tuned to perform exceptionally well in specific areas, such as emotion classification in customer support interactions. This capability allows them to potentially replace traditional models in these domains.
In this tutorial, we will explore the capabilities of Llama 3.2 vision and lightweight models. We will learn how to access the Llama 3.2 3B model, fine-tune it on a customer support dataset, and subsequently merge and export it to the Hugging Face hub. In the end, we will convert the model to GGUF format and use it locally using the Jan application.
If you are new to AI, it is highly recommended that you take the AI Fundamentals skill track and learn about the basics of ChatGPT, large language models, generative AI, and more.

Image by Author
The family of Llama 3.2 open-source models has two variations: the lightweight and vision models. The vision models excel in image reasoning and bridging vision with language, while the lightweight models are good at multilingual text generation and tool calling for edge devices.
The lightweight model has two smaller variants: 1B and 3B. These models are good at multilingual text generation and tool calling tasks. They are small, meaning they can run on a device to ensure that data never leaves the device and provide high-speed text generation at a low computing cost.
To create these efficient lightweight models, Llama 3.2 uses pruning and knowledge distillation techniques. Pruning reduces the model size while retaining performance, and knowledge distillation uses larger networks to share knowledge with smaller ones, enhancing their performance.
The 3B model outperforms other models like Gemma 2 (2.6B) and Phi 3.5-mini in tasks such as instruction following, summarization, prompt rewriting, and tool use.
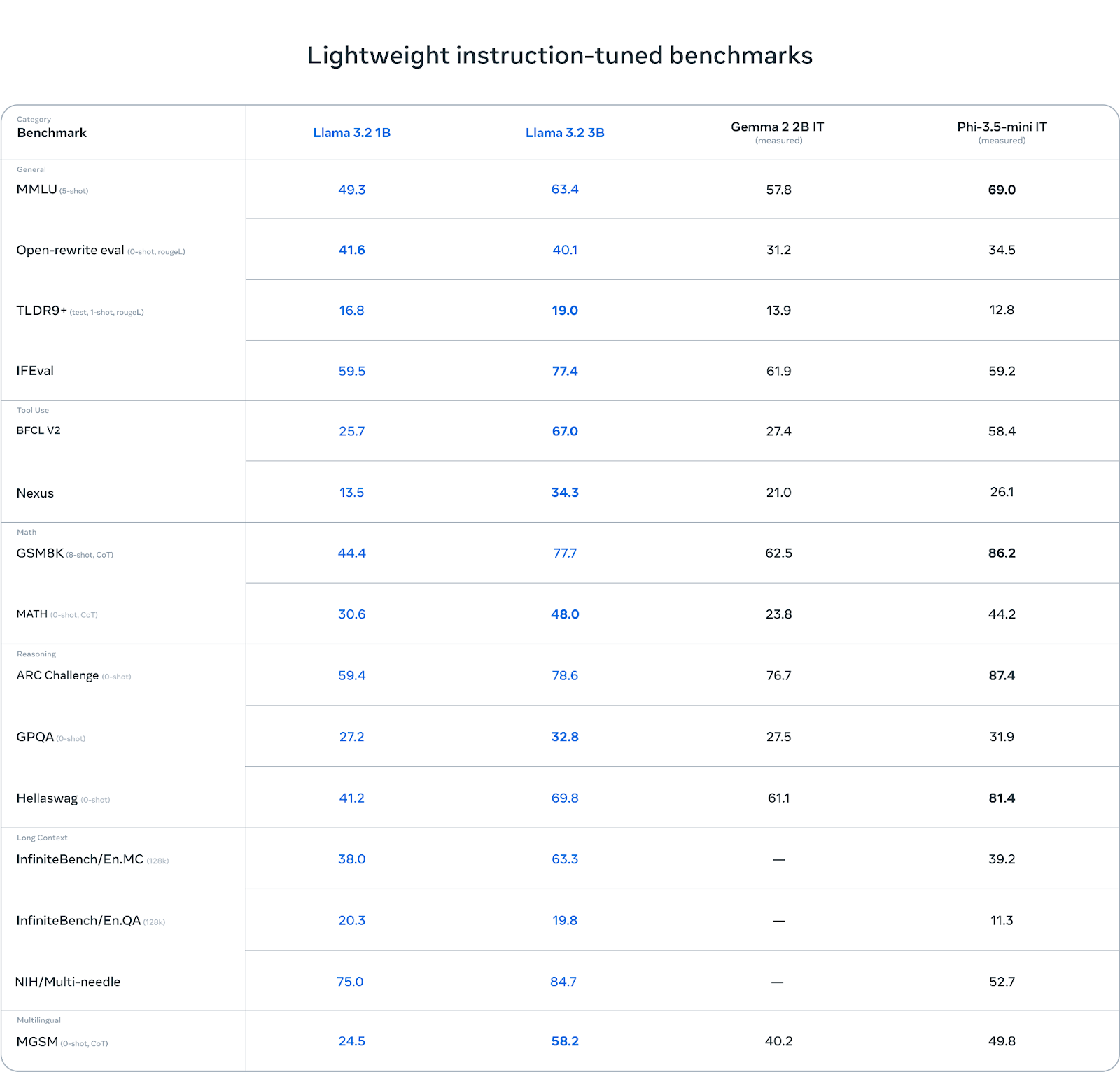
Source: Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
The vision models come in two variants: 11B and 90B. These models are designed to support image reasoning. The 11B and 90B can understand and interpret documents, charts, and graphs and perform tasks such as image captioning and visual grounding. These advanced vision capabilities were made possible by integrating pre-trained image encoders with language models using adapter weights consisting of cross-attention layers.
Compared to Claude 3 Haiku and GPT-4o mini, the Llama 3.2 vision models have excelled in image recognition and various visual understanding tasks, making them robust tools for multimodal AI applications.
Source: Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
You can learn more about Llama 3.2 use cases, benchmarks, Llama Guard 3, and model architecture by reading our latest blog, Llama 3.2 Guide: How It Works, Use Cases & More.
Even though the Llama 3.2 model is freely available and open source, you still need to accept the terms and conditions and fill out the form on the website.
To get access to the latest Llama 3.2 model on the Kaggle platform:
Source: Download Llama
Source: Meta | Llama 3.2 | Kaggle
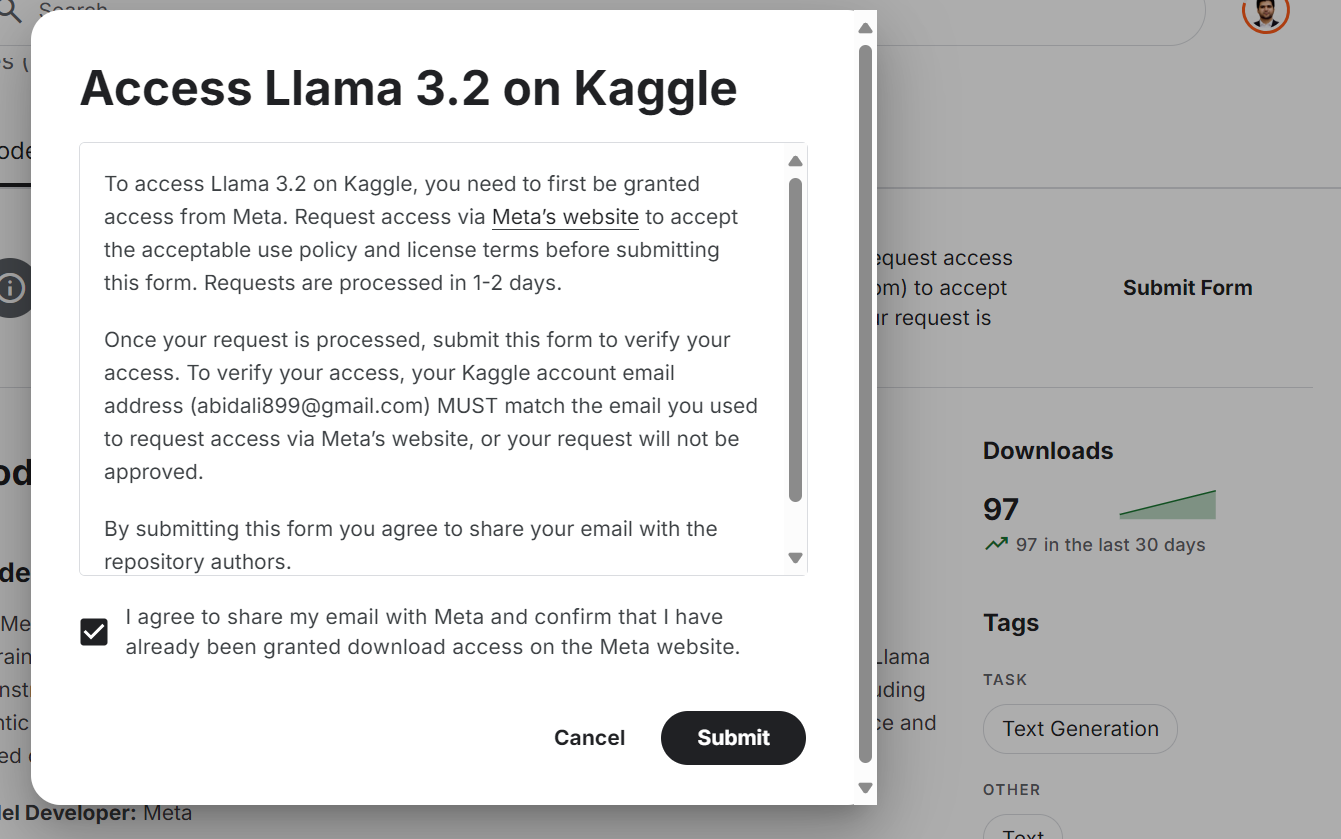
Source: Meta | Llama 3.2 | Kaggle
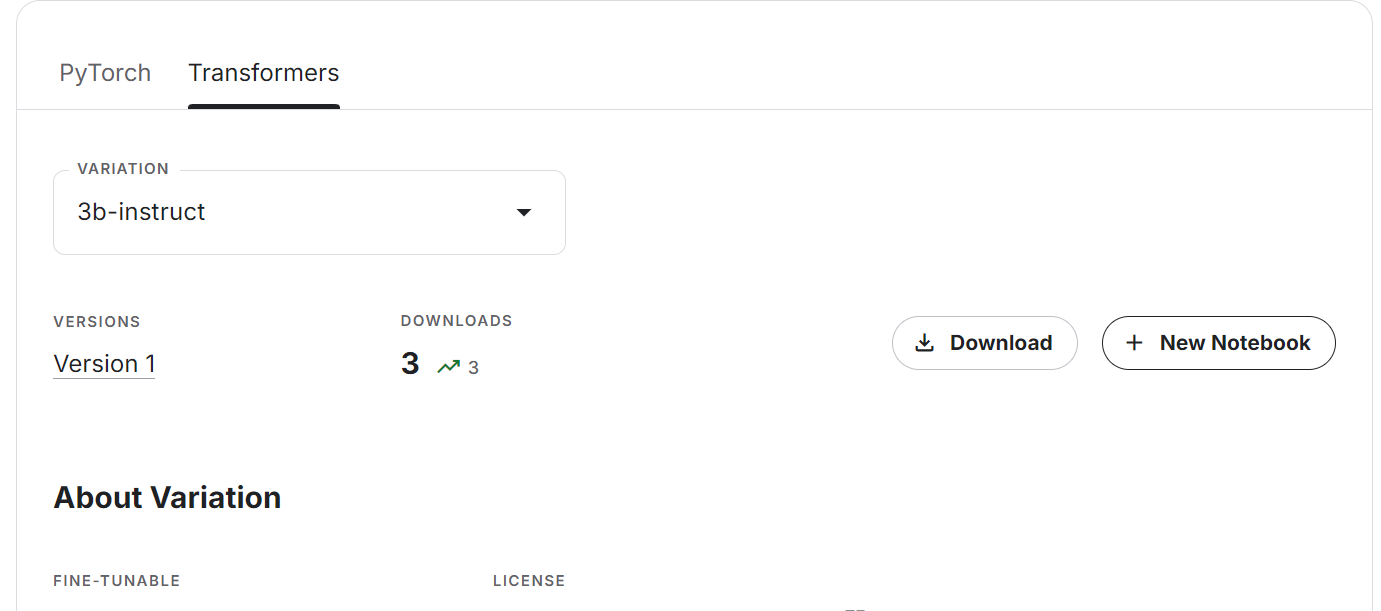
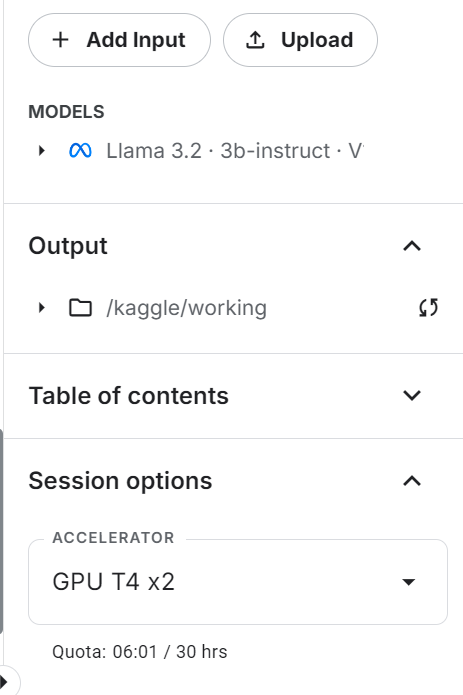
%%capture
%pip install -U transformers acceleratefrom transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, TextStreamer
import torch
base_model = "/kaggle/input/llama-3.2/transformers/3b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)pad_token_id to avoid receiving warning messages.if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
if model.config.pad_token_id is None:
model.config.pad_token_id = model.config.eos_token_idpipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)messages = [{"role": "user", "content": "Who is Vincent van Gogh?"}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])The answer is pretty accurate.

from IPython.display import Markdown, display
messages = [
{
"role": "system",
"content": "You are a skilled Python developer specializing in database management and optimization.",
},
{
"role": "user",
"content": "I'm experiencing a sorting issue in my database. Could you please provide Python code to help resolve this problem?",
},
]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
outputs = pipe(prompt, max_new_tokens=512, do_sample=True)
display(
Markdown(
outputs[0]["generated_text"].split(
"<|start_header_id|>assistant<|end_header_id|>"
)[1]
)
)The result is highly accurate. The model performs quite well despite having only 3 billion parameters.
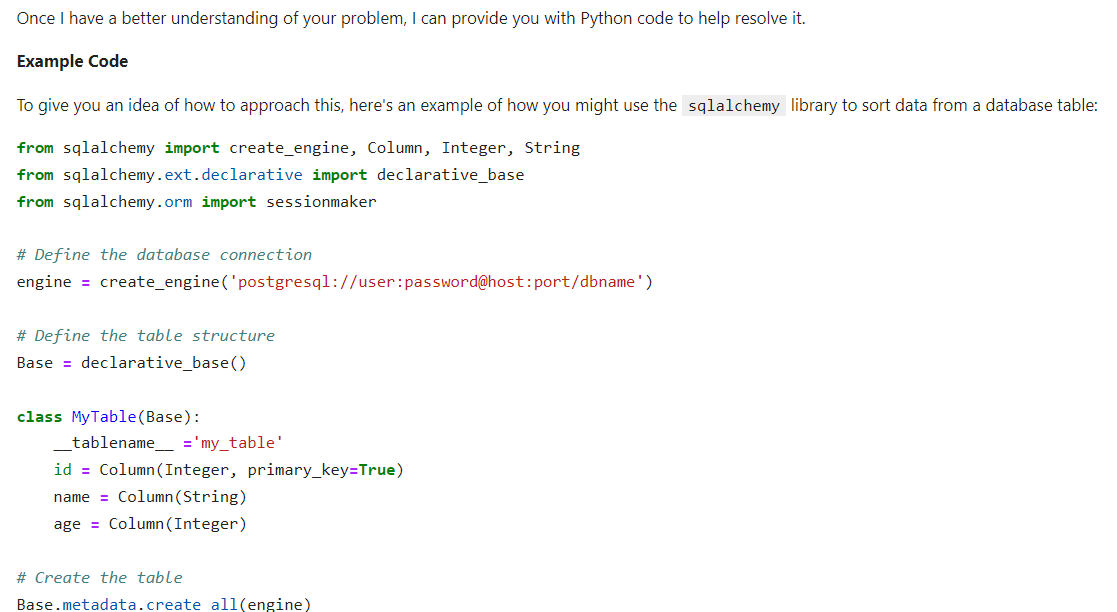
If you are experiencing difficulties accessing the Llama 3.2 lightweight models, please consult the notebook, Accessing the Llama 3.2 Lightweight Models.
Accessing the Vision model is simple, and you don't have to worry about GPU memory, as we will use multiple GPUs in this guide.
Source: Meta | Llama 3.2 Vision | Kaggle
Source: Meta | Llama 3.2 Vision | Kaggle
%%capture
%pip install -U transformers accelerateimport torch
from transformers import MllamaForConditionalGeneration, AutoProcessor
base_model = "/kaggle/input/llama-3.2-vision/transformers/11b-vision-instruct/1"
processor = AutoProcessor.from_pretrained(base_model)
model = MllamaForConditionalGeneration.from_pretrained(
base_model,
low_cpu_mem_usage=True,
torch_dtype=torch.bfloat16,
device_map="auto",
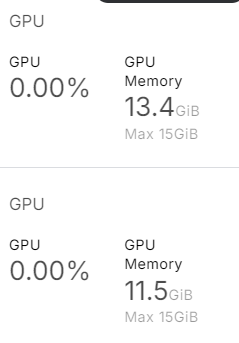
)As we can see, it uses almost 25 GB of GPU memory. This will be impossible to run on a laptop or the free version of Google Colab.
import requests
from PIL import Image
url = "https://media.datacamp.com/cms/google/ad_4nxcz-j3ir2begccslzay07rqfj5ttakp2emttn0x6nkygls5ywl0unospj2s0-mrwpdtmqjl1fagh6pvkkjekqey_kwzl6qnodf143yt66znq0epflvx6clfoqw41oeoymhpz6qrlb5ajer4aeniogbmtwtd.png"
image = Image.open(requests.get(url, stream=True).raw)
messages = [
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": "Describe the tutorial feature image."}
]}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(image, input_text, return_tensors="pt").to(model.device)
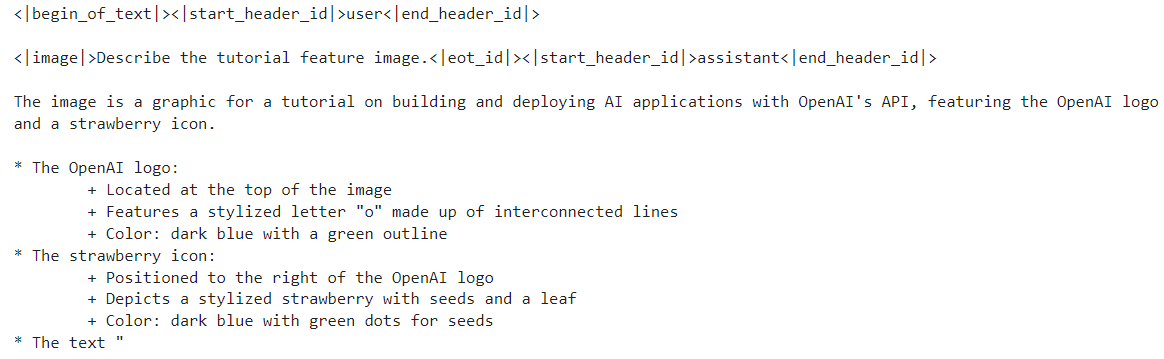
output = model.generate(**inputs, max_new_tokens=120)
print(processor.decode(output[0]))As a result, we get a detailed description of the image. It is pretty accurate.
If you encounter issues while running the code above, please refer to the Accessing the Llama 3.2 Vision Models Kaggle notebook.
In this section, we will learn how to fine-tune the Llama 3.2 3B Instruct model using the Transformers library on the customer support dataset. We will use Kaggle to access free GPUs and get higher RAM than Colab.
Launch the new notebook on Kaggle and set the environment variables. We will use the Hugging Face API to save the model and Weights & Biases to track its performance.
Install and update all the necessary Python packages.
%%capture
%pip install -U transformers
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U wandbLoad the Python packages and functions we will use throughout the fine-tuning and evaluation process.
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import (
LoraConfig,
PeftModel,
prepare_model_for_kbit_training,
get_peft_model,
)
import os, torch, wandb
from datasets import load_dataset
from trl import SFTTrainer, setup_chat_formatLog in to Hugging Face CLI using the API key.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Login to Weights & Biases using the API key and instantiate the new project.
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Llama 3.2 on Customer Support Dataset',
job_type="training",
anonymous="allow"
)Set the variables for base mode, dataset, and new model name. We will be using them in multiple places in this project, so it is better to set them at the start to avoid confusion.
base_model = "/kaggle/input/llama-3.2/transformers/3b-instruct/1"
new_model = "llama-3.2-3b-it-Ecommerce-ChatBot"
dataset_name = "bitext/Bitext-customer-support-llm-chatbot-training-dataset"Set the data type and attention implementation.
# Set torch dtype and attention implementation
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
torch_dtype = torch.bfloat16
attn_implementation = "flash_attention_2"
else:
torch_dtype = torch.float16
attn_implementation = "eager"Load the model and tokenizer by providing the local model directory. Even though our model is small, loading the full model and fine-tuning it will take some time. Instead, we will load the model in 4-bit quantization.
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)We will load the Bitext-customer-support-llm-chatbot dataset from the Hugging Face hub. It is a hybrid synthetic dataset that we will use to create our own customized customer support chatbot.
We will load, shuffle, and select only 1000 samples. We are fine-tuning the model on a small subset to reduce the training time, but you can always select the full model.
Next, we will create the "text" column using the system instructions, user queries, and assistant responses. Then, we will convert the JSON response into the chat format.
#Importing the dataset
dataset = load_dataset(dataset_name, split="train")
dataset = dataset.shuffle(seed=65).select(range(1000)) # Only use 1000 samples for quick demo
instruction = """You are a top-rated customer service agent named John.
Be polite to customers and answer all their questions.
"""
def format_chat_template(row):
row_json = [{"role": "system", "content": instruction },
{"role": "user", "content": row["instruction"]},
{"role": "assistant", "content": row["response"]}]
row["text"] = tokenizer.apply_chat_template(row_json, tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= 4,
)
As we can see, we have combined the customer query and assistant response in a chat format.
dataset['text'][3]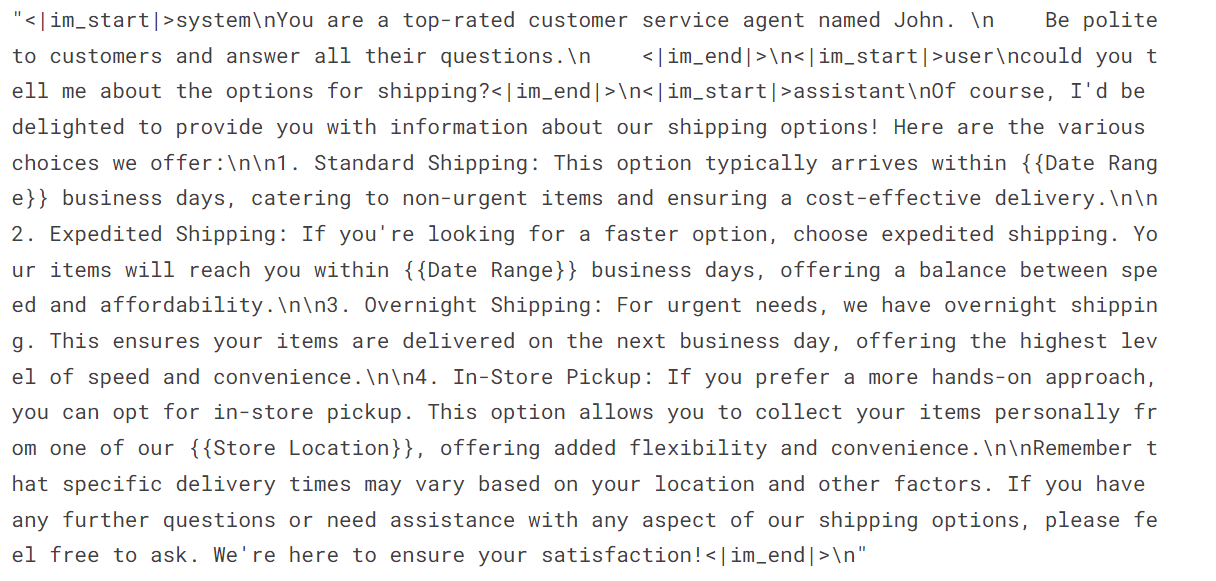
Extract the linear model name from the model.
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)Use the linear module name to create the LoRA adopter. We will only fine-tune the LoRA adopter and leave the rest of the model to save memory and for faster training time.
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = get_peft_model(model, peft_config)We are configuring the model hyperparameters to run it on the Kaggle environment. You can understand each hyperparameter by referring to the Fine-Tuning Llama 2 tutorial and changing it to optimize the training running on your system.
#Hyperparamter
training_arguments = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
eval_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="wandb"
)We will now set up a supervised fine-tuning (SFT) trainer and provide a train and evaluation dataset, LoRA configuration, training argument, tokenizer, and model.
# Setting sft parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
max_seq_length= 512,
dataset_text_field="text",
tokenizer=tokenizer,
args=training_arguments,
packing= False,
)Start the training process and monitor the training and validation loss metrics.
trainer.train()The training loss gradually reduced. Which is a good sign.
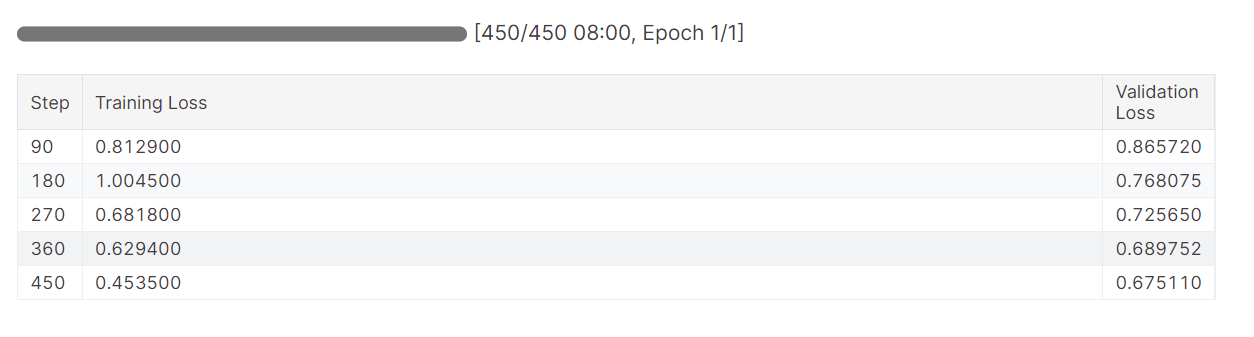
The detailed run history is generated when we finish the Weights & Biases run.
wandb.finish()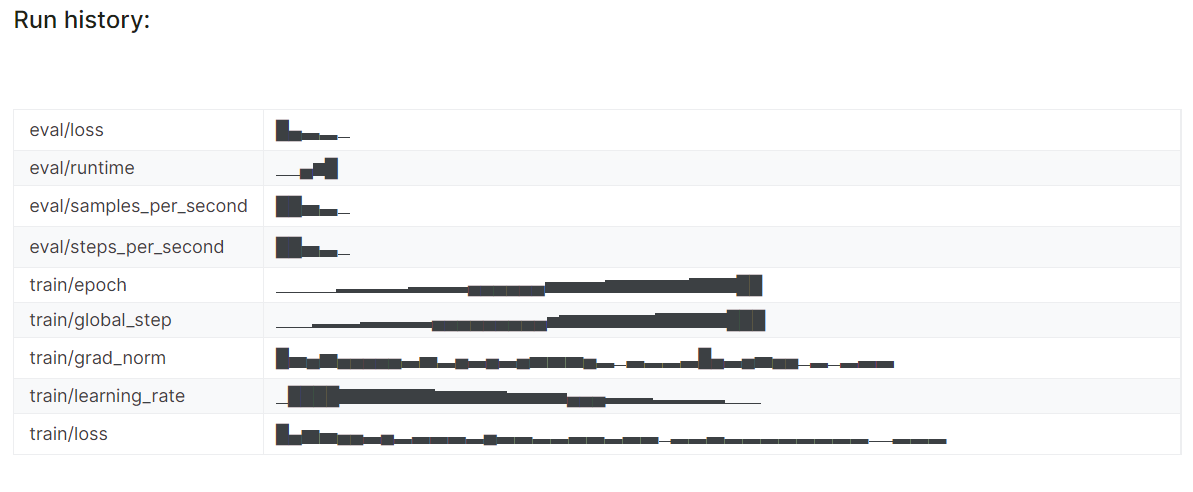
You can always visit the Weights & Biases dashboard to review the model metrics thoroughly.
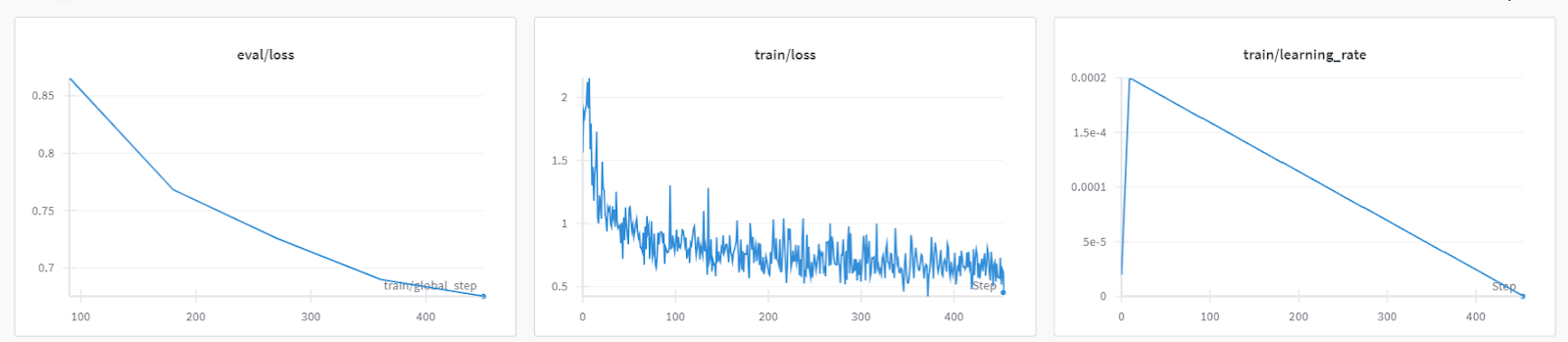
To test the fine-tuned model, we will provide it with the sample prompt from the dataset.
messages = [{"role": "system", "content": instruction},
{"role": "user", "content": "I bought the same item twice, cancel order {{Order Number}}"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=150, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])The fine-tuned model has adopted the style and provided an accurate response.

Save the fine-tuned model locally and also push it to the Hugging Face hub. The push_to_hub function will create a new model repository and push the model files to your Hugging Face repository.
# Save the fine-tuned model
trainer.model.save_pretrained(new_model)
trainer.model.push_to_hub(new_model, use_temp_dir=False)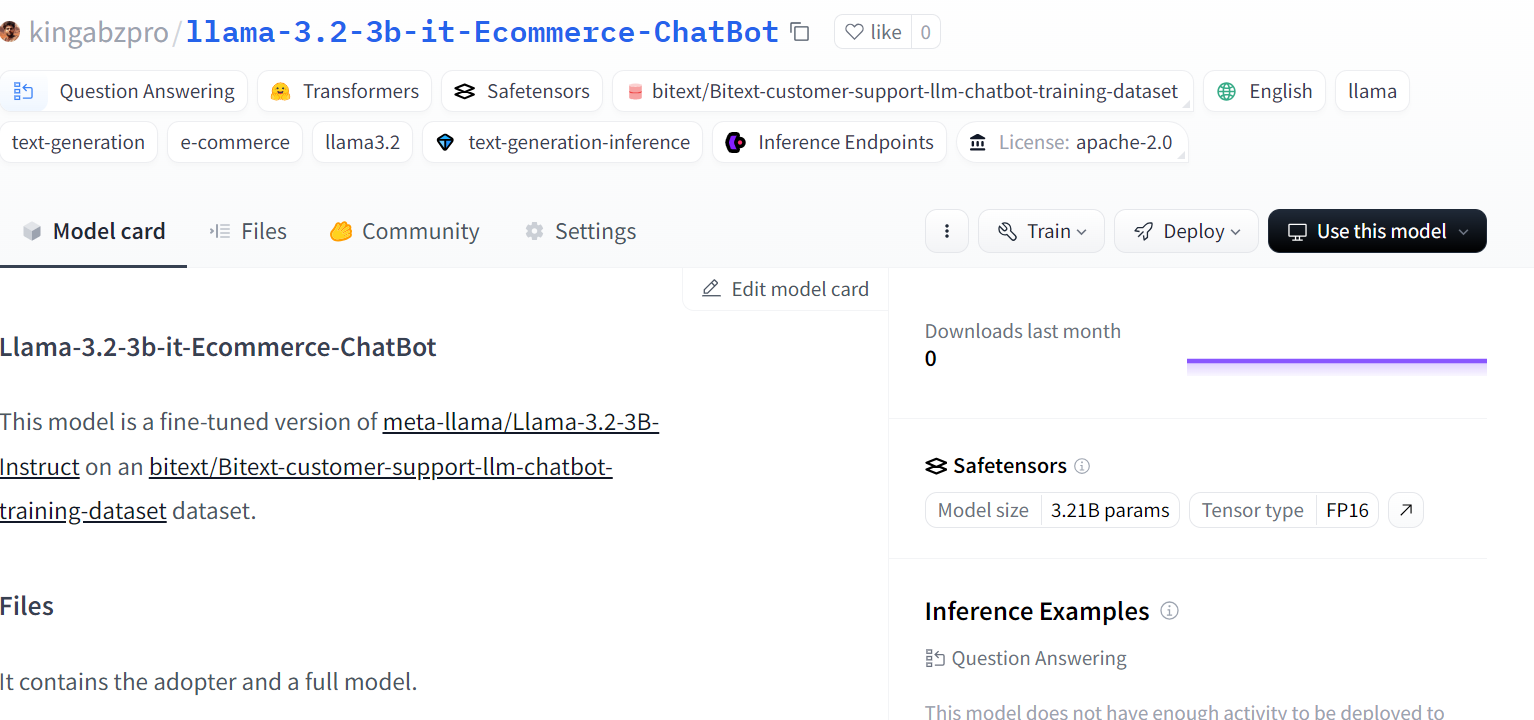
Source: kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot
To fine-tune the larger Llama 3 models, you should check out Fine-Tuning Llama 3.1 for the Text Classification tutorial. This tutorial is quite popular and will help you find the LLMs on the complete task.
Click on the "Save Version" button in the top right, select the quick save option, and change the save output option to save the model file and all of the code.
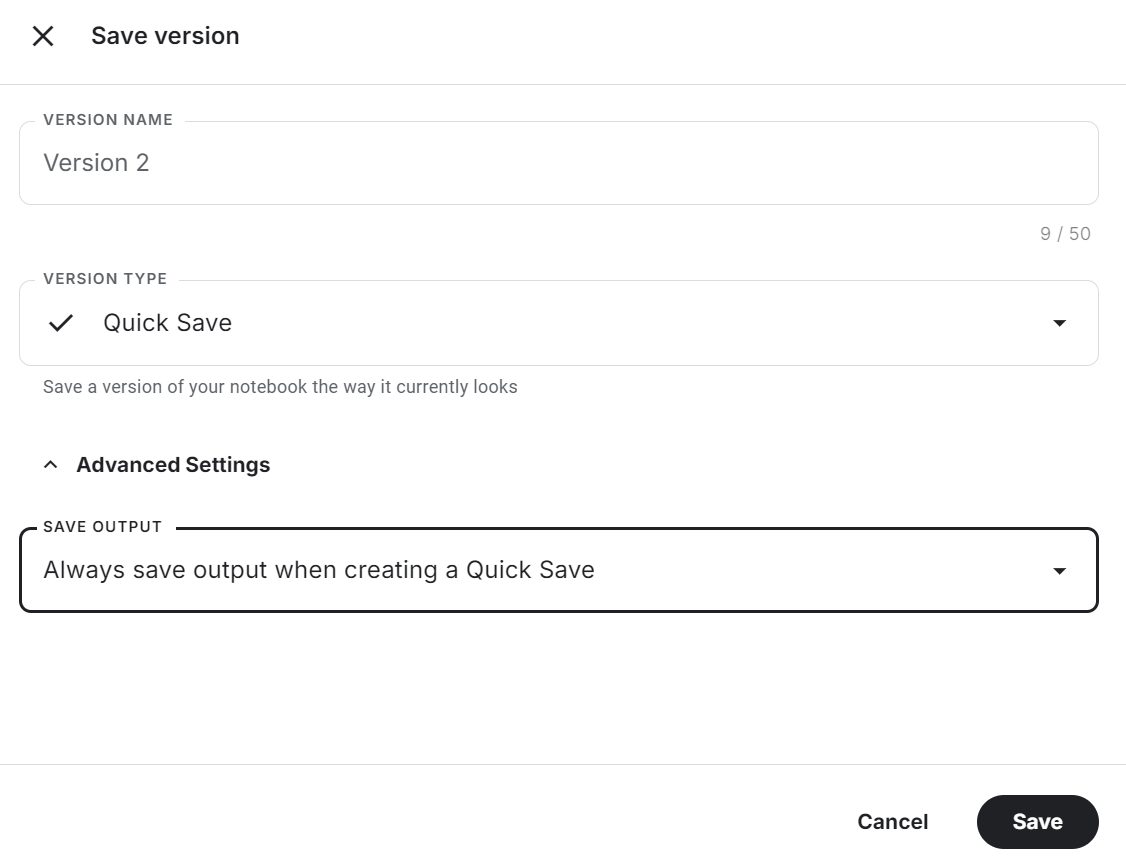
Check out the Fine-tune Llama 3.2 on Customer Support Kaggle notebook for code source, results, and output.
This is a heavy code-based guide. If you are looking for a no-code or low-code guide to fine-tuning the LLMs, check out the LlaMA-Factory WebUI Beginner's Guide: Fine-Tuning LLMs.
We will create a new notebook and add the previously saved notebook to access the fine-tuned LoRA adapter to avoid any memory issues.
Make sure that you have also added the base model "Llama 3.2 3B Instruct."
Install and update all the necessary Python packages.
%%capture
%pip install -U bitsandbytes
%pip install transformers==4.44.2
%pip install -U accelerate
%pip install -U peft
%pip install -U trlLogin to Hugging Face CLI to push the merged model to the Hugging Face hub.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Provide the location to the base model and fine-tune LoRA. We will use them to load the base model and merge it with the adapter.
# Model
base_model_url = "/kaggle/input/llama-3.2/transformers/3b-instruct/1"
new_model_url = "/kaggle/input/fine-tune-llama-3-2-on-customer-support/llama-3.2-3b-it-Ecommerce-ChatBot/"Load the tokenizer and full model.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, pipeline
from peft import PeftModel
import torch
from trl import setup_chat_format
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model_url)
base_model_reload= AutoModelForCausalLM.from_pretrained(
base_model_url,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="auto",
)Apply the chat format to the model and tokenizer. Then, merge the base model with the LoRA adapter.
# Merge adapter with base model
base_model_reload, tokenizer = setup_chat_format(base_model_reload, tokenizer)
model = PeftModel.from_pretrained(base_model_reload, new_model_url)
model = model.merge_and_unload()To check if the model has been successfully merged, provide it with the samples prompt and generate the repose.
instruction = """You are a top-rated customer service agent named John.
Be polite to customers and answer all their questions.
"""
messages = [{"role": "system", "content": instruction},
{"role": "user", "content": "I have to see what payment payment modalities are accepted"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=150, num_return_sequences=1)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(text.split("assistant")[1])As we can see, our fine-tuned model is working perfectly.

Save the tokenizer and model locally.
new_model = "llama-3.2-3b-it-Ecommerce-ChatBot"
model.save_pretrained(new_model)
tokenizer.save_pretrained(new_model)Push the tokenizer and merged model to the Hugging Face model repository.
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)After a few minutes, you can view all the model files with metadata files in your Hugging Face repository.
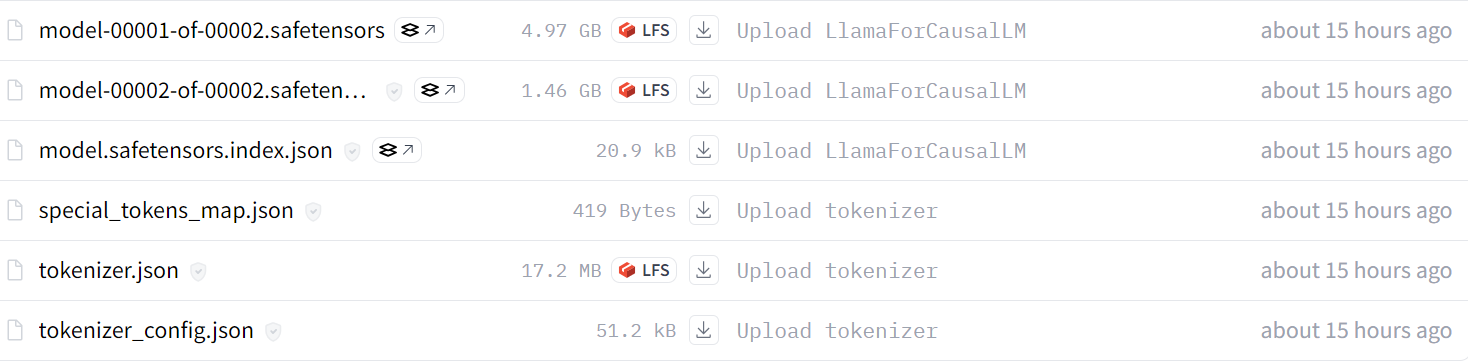
Source: kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot
You can also review the source code in the Merging and Exporting Fine-tuned Llama 3.2 Kaggle notebook to learn more about merging and uploading your model to the Hugging Face hub.
The next step in this project is to convert the full model into the GGUF format and then quantize it. After that, you can use it locally using your favorite chat app like Jan, Msty, or GPT4ALL. Follow the Fine-Tuning Llama 3 and Using It Locally guide to learn how to convert all LLM to GGUF format and use it locally on your laptop.
To use the fine-tuned model locally, we have first to convert it into GGUF format. Why? Because this is a llama.cpp format and accepted by all of the desktop chatbot applications.
Converting the merged model to llama.ccp format is quite easy. All we have to do is go to the GGUF My Repo Hugging Face Hub. Sign in with the Hugging Face account. Typing the fine-tuned model repository link “kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot” and press the “Submit” button.
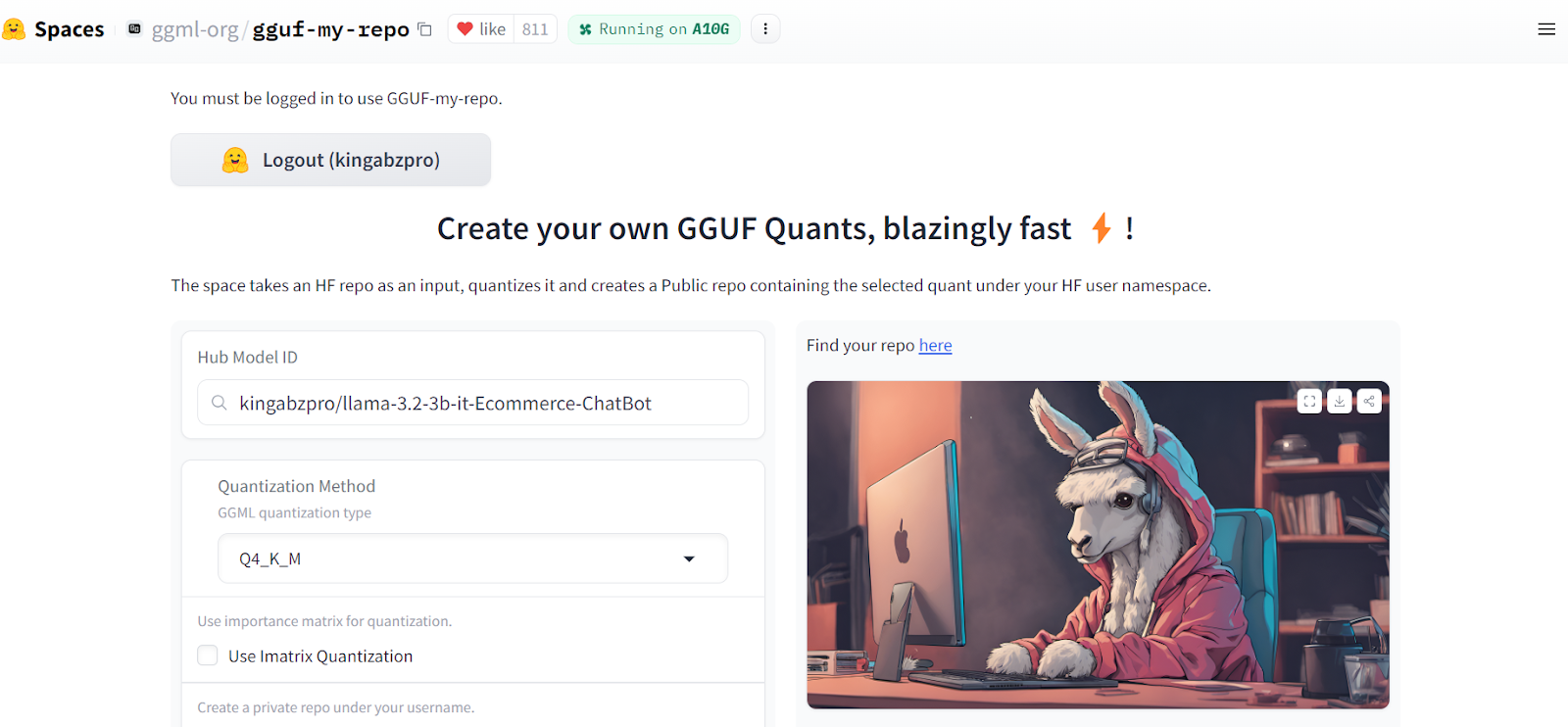
Source: GGUF My Repo
Within a few seconds, the quantized version of the model will be created in a new Hugging Face repository.
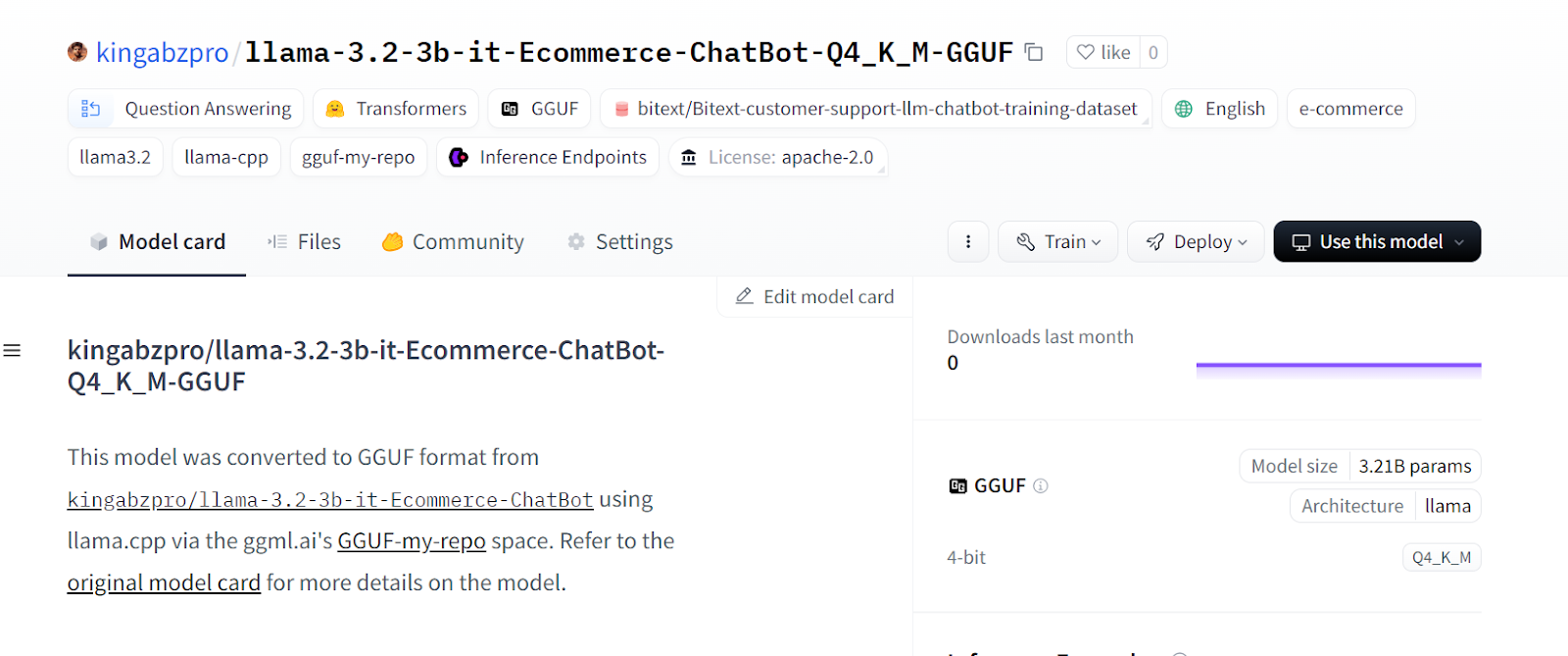
Source: kingabzpro/llama-3.2-3b-it-Ecommerce-ChatBot-Q4_K_M-GGUF
Click on the “Files” tab and download only the GGUF file.
Source: llama-3.2-3b-it-ecommerce-chatbot-q4_k_m.gguf
We will use the Jan chatbot application to use our fine-tuned model locally. Go to the official website, jan.ai, to download and install the application.
Source: Jan
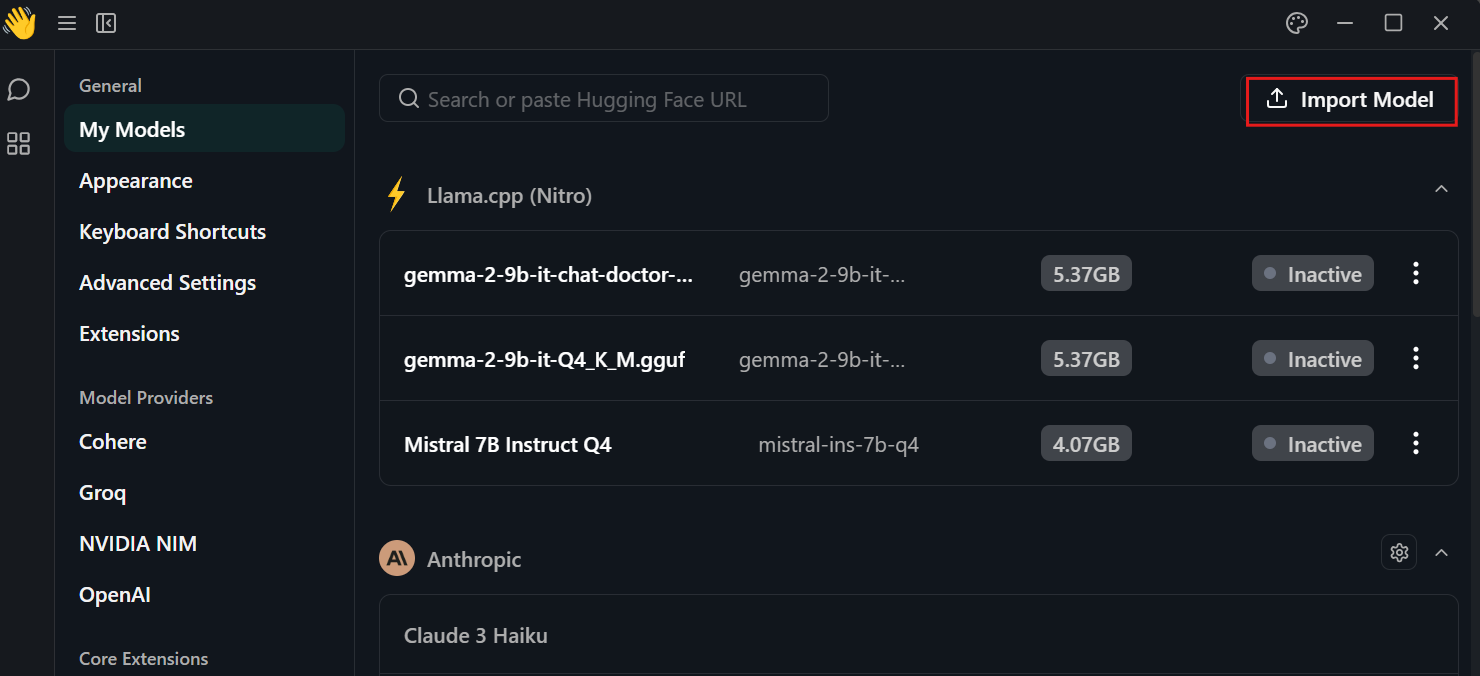
Click on the setting, select the “My Models” menu, and press the “Import Model” button. Then, provide it with the local directory of the model.
Go to the chat menu and select the fine-tuned model, as shown below.
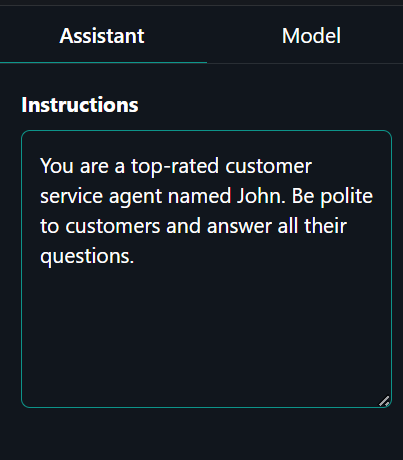
Click the “Assistant” tab on the right panel and type the system prompt.
System prompt: “You are a top-rated customer service agent named John. Be polite to customers and answer all their questions.”
Click on the “Model” tab, right beside the “Assistant” tab and change the stop token to “<|eot_id|>”
That’s it. All you have to do is ask the customer support AI about the issue you are facing.
Prompt: “How do I order multiple items from the same vendor?”
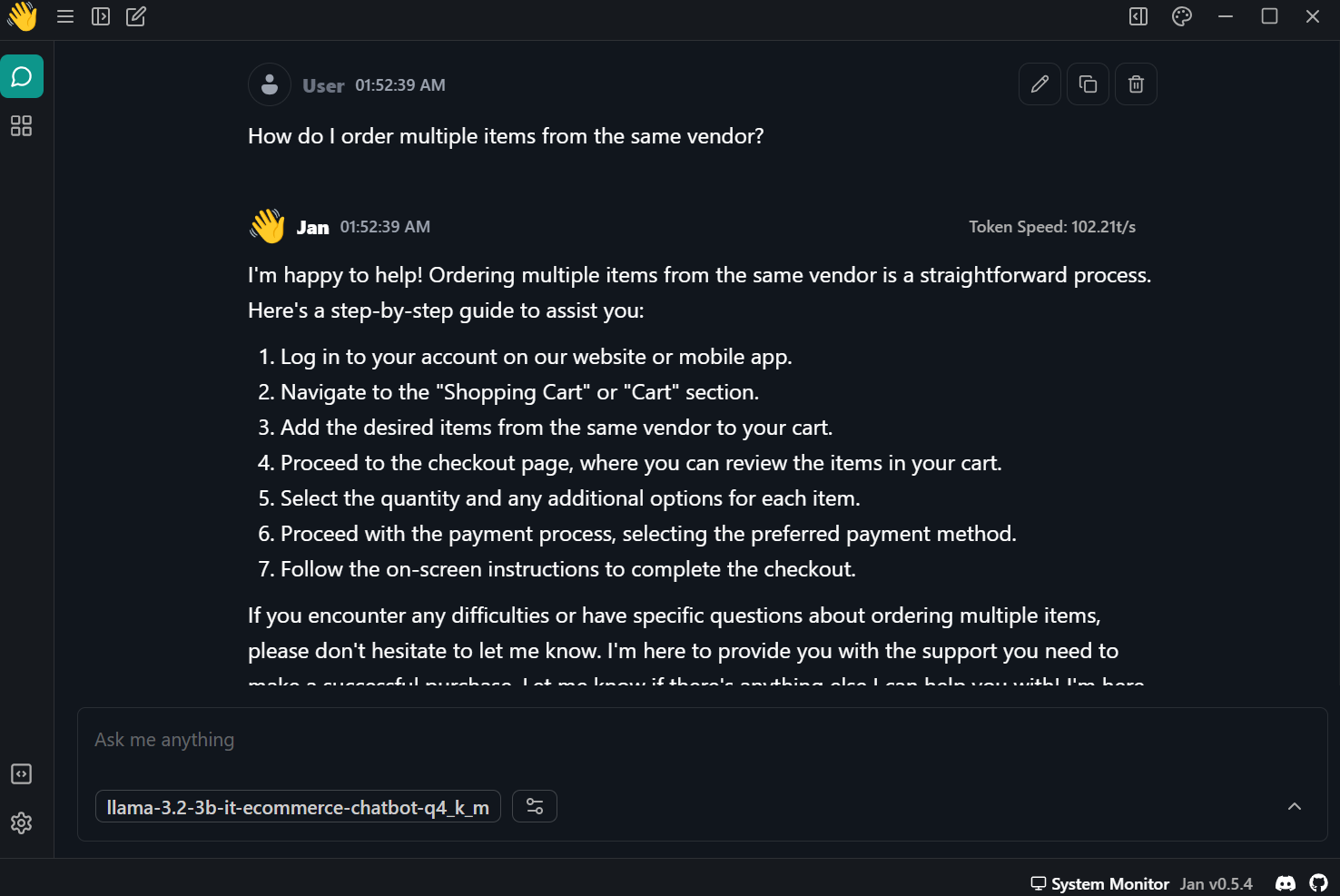
The response was accurate and super fast—almost 102 tokens per second.
Fine-tuning the smaller LLMs lets us save costs and improve the inference time. With enough data, you can improve the model performance on certain tasks close to GPT-4-mini. In short, the future of AI involves using multiple smaller LLMs in a grid with a master-slave relationship.
The master model will receive the initial prompt and decide which specialized model to use to generate the answers. This will reduce compute time, improve results, and reduce running costs.
In this tutorial, we have learned about Llama 3.2 and how to access it in Kaggle. We have also learned to fine-tune the lightweight Llama 3.2 model on the customer support dataset so that it learns to respond in a certain style and provide accurate domain-specific information. Then we merged the LoRA adapter with the base model and pushed the full model to the Hugging Face Hub. Finally, we converted the merged model to GGUF format and used it locally on the laptop with the Jan chatbot application.
Take our Working with Hugging Face interactive course to learn about using the tool and fine-tuning models.
Top LLM Courses
Track
Track
Course
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
code-along
Maxime Labonne
code-along
Maxime Labonne


