
Lernpfad
Entwicklung von großen Sprachmodellen
16 Std.
Stell dir vor, du erzählst einem Kumpel eine lange Geschichte und merkst dann, dass er den Anfang schon vergessen hat, bevor du zur Pointe kommst. Diese Frustration passiert genau dann, wenn einer KI das „Kurzzeitgedächtnis“ ausgeht und sie wichtige Details loswerden muss, um Platz für neue zu schaffen.
In der Welt der großen Sprachmodelle (LLMs) wird diese Aufmerksamkeitsspanne durch das Kontextfenster bestimmt.
Da Modelle immer leistungsfähiger werden und die Kontextgrößen zunehmen, ist es für den Aufbau zuverlässiger und skalierbarer KI-Systeme entscheidend, zu verstehen, wie diese Fenster funktionieren. In diesem Leitfaden schauen wir uns die Grundlagen von Kontextfenstern an, was man beim Vergrößern beachten sollte und wie man sie am besten nutzt.
Wenn du über die Theorie hinausgehen und lernen willst, wie man Kontextbeschränkungen in echten Python-Anwendungen handhabt, schau dir unseren Kurs „Entwickeln von LLM-Anwendungen mit LangChain” an.
Das Kontextfenster eines KI-Modells entscheidet, wie viel Text es im Arbeitsspeicher behalten kann, während es eine Antwort erstellt. Es begrenzt, wie lange man sich unterhalten kann, ohne Details aus früheren Gesprächen zu vergessen.
Du kannst es dir wie das Kurzzeitgedächtnis eines Menschen vorstellen. Es speichert Infos aus früheren Unterhaltungen vorübergehend, um sie für die aktuelle Aufgabe zu nutzen.

Kontextfenster beeinflussen verschiedene Sachen, wie die Qualität der Argumentation, die Tiefe der Unterhaltung und die Fähigkeit des Modells, Antworten effektiv anzupassen. Es legt auch fest, wie groß die Eingabe maximal sein darf, die es auf einmal verarbeiten kann. Wenn eine Eingabeaufforderung oder ein Gesprächskontext diese Grenze überschreitet, schneidet das Modell die ältesten Teile des Textes ab, um Platz zu schaffen.
Um besser zu verstehen, was das genau bedeutet, schauen wir uns ein paar grundlegende Konzepte an, die KI-Modellen und Kontextfenstern zugrunde liegen.
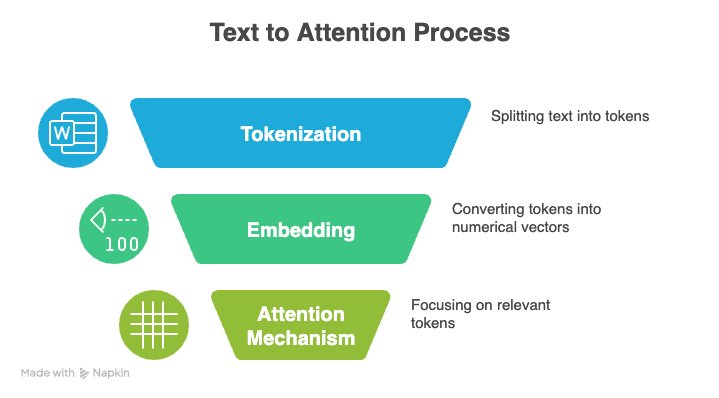
Drei Kernkonzepte sind die Basis von LLMs: Tokenisierung, der Aufmerksamkeitsmechanismus und Positionskodierung.
Tokenisierung ist der Prozess, bei dem man Rohtext in kleinere Einheiten, sogenannte Token, umwandelt, die ein LLM verarbeiten kann. Diese Zeichen können ganze Wörter, einzelne Buchstaben oder sogar Teile von Silben darstellen. Die Gesamtheit aller einzigartigen Token, die ein Modell erkennt, wird als sein Vokabular bezeichnet.
Zum Beispiel könnte der Satz „Hallo, Welt“ in „ [“Hello”, “,”, “ world”] “ zerlegt werden.
Beim Training oder bei der Inferenz wird jedes Token in eine eindeutige ganze Zahl umgewandelt, und das Modell liest diese Zahlen anstelle des ursprünglichen Textes. Es checkt die Zahlenfolge, lernt, wie die Zeichen zusammenhängen, und macht neuen Text, indem es das nächste mögliche Zeichen vorhersagt.
Effiziente Tokenisierung ist echt wichtig dafür, wie viele Infos in das Kontextfenster eines Modells passen. Wenn ein Tokenizer Text mit weniger Tokens darstellen kann, passt mehr Inhalt in dasselbe Fenster.
Tokenizer, die gängige Wörter oder Ausdrücke als einzelne Token darstellen, sind besonders effektiv, weil sie die Anzahl der Token reduzieren und es dem Modell so ermöglichen, längere Dokumente innerhalb seiner Kontextgrenzen zu verarbeiten.
Der sogenannte Aufmerksamkeitsmechanismus ist eine weitere Grundlage moderner LLMs. Es hilft einem Modell, sich bei der Erzeugung einer Ausgabe auf die wichtigsten Teile seiner Eingabe zu konzentrieren.
Anstatt jedes Token gleich zu behandeln, vergleicht das Modell die aktuelle Darstellung mit allen anderen Token-Darstellungen und gibt jedem Vergleich eine Punktzahl. Durch diese selektive Gewichtung kann das Modell lange Sequenzen verarbeiten und den Kontext besser verstehen.
Die Aufmerksamkeit dreht sich um drei Sachen: Abfragen, Schlüssel und Werte.
Fragen: Das Signal, das das aktuelle Token sendet, um im Rest der Sequenz nach relevanten Infos zu suchen.
Keys: Die Kennung für jedes Token in der Sequenz, die sagt, wie gut es zum Suchsignal passt.
Werte: Der eigentliche Info-Inhalt, der abgerufen und genutzt wird, wenn eine Übereinstimmung zwischen einer Abfrage und einem Schlüssel gefunden wird.
Das Modell berechnet Ähnlichkeitswerte zwischen Suchanfragen und Schlüsseln, wandelt diese Werte mithilfe der Softmax-Aktivierungsfunktion in Gewichte um und gibt dann die endgültige Ausgabe als gewichtete Summe der Werte aus.
Selbstaufmerksamkeit vergleicht das aktuelle Token mit jedem anderen Token in der Sequenz. Das führt zu quadratischen Rechenkosten: Wenn man das Kontextfenster verdoppelt, braucht man viermal so viel Rechenleistung und Speicher.
Wenn die Kontextfenster größer werden, wird das schnell teuer, deshalb nutzen Modelle Optimierungen wie Sparse Attention, Low-Rank-Approximation oder Chunking, um die Berechnungen überschaubar zu halten.
Transformatoren, die moderne Sprachmodelle antreiben, verstehen die Reihenfolge von Tokens nicht von selbst. Stattdessen nutzen sie Positionskodierung, um diese Infos einzubauen.
Die Positionskodierung fügt jedem Token ein kleines Signal hinzu, das dem Modell hilft, Abstände und relative Anordnungen zu verstehen.
Die Art, wie Positionsinfos erfasst werden, bestimmt auch, wie gut das Modell Beziehungen innerhalb einer Sequenz verfolgen kann, was wiederum die Größe und Effektivität seines Kontextfensters beeinflusst. Schauen wir uns mal ein paar beliebte Methoden an:
Absolute Positional Embeddings: Das Modell lernt einen eigenen Vektor für jede Position in der Sequenz, so als würde man jedem Token eine feste Adresse geben. Das klappt bei kürzeren Sequenzen, aber das Modell kann keine Positionen verarbeiten, die über das hinausgehen, worauf es trainiert wurde, was es schwierig macht, das Kontextfenster zu erweitern.
Sinusförmige Kodierungen: Die Positionen werden mit sich wiederholenden Sinus- und Kosinuswellen verschlüsselt, die jedem Token ein einzigartiges Muster je nach seiner Lage geben. Sie lassen sich besser auf unbekannte Längen verallgemeinern als absolute Einbettungen, werden aber bei extrem langen Sequenzen weniger stabil.
Relative Positionskodierungen: Anstatt genaue Positionen zu markieren, lernt das Modell den Abstand zwischen den Tokens. Das hilft bei der Verallgemeinerung auf längere Sequenzen, aber die Gesamtkontextgrenze hängt immer noch von der Architektur und dem Speicher des Modells ab.
Rotierende Positions-Einbettungen (RoPE): RoPE kodiert die Position, indem es die Vektordarstellung jedes Tokens basierend auf seiner absoluten Position dreht und den Abstand zu anderen Tokens berechnet. Diese Methode bleibt stabil, wenn die Sequenzen länger werden, und kann viel größere Kontextfenster verarbeiten.
ALiBi (Aufmerksamkeitslineare Verzerrungen): ALiBi nutzt eine einfache distanzbasierte Gewichtung im Aufmerksamkeitsmechanismus, sodass näher beieinander liegende Token automatisch mehr Gewicht bekommen. Es lässt sich gut auf lange Sequenzen anwenden.
Ich empfehle dir, dir dieses Tutorial über die Funktionsweise von Transformatoren anzuschauen, um einen detaillierten Überblick zu bekommen.
Wenn der Kontext über das Kontextfenster hinausgeht, kann das Modell die ersten Teile abschneiden oder ignorieren, wodurch möglicherweise wichtiger Kontext verloren geht. Deshalb probieren Forscher immer wieder neue Techniken aus, um diese Grenzen zu verschieben und längere Kontextfenster zu ermöglichen.
Bis 2022 haben die GPT-Modelle von OpenAI die Szene gerockt. Das erste GPT-Modell, das 2018 rausgebracht wurde, hat ein 512-Token-Fenster unterstützt. Die nächsten beiden Versionen in den Jahren 2019 und 2020 haben diese Grenze jeweils verdoppelt und erreichten 2.048 Token für GPT-3. Die nachfolgenden Modelle haben diese Grenzen immer weiter ausgebaut, bis zu einer Million Token (GPT-4.1).
In letzter Zeit hat OpenAI die Konkurrenz eingeholt oder sogar überholt. Die Versionen Gemini 2.5 und 3 Pro von Google passen zu dieser Fenstergröße von bis zu einer Million Tokens, sodass ganze Bücher, große Codebasen und Arbeitslasten mit mehreren Dokumenten in einem einzigen Durchgang verarbeitet werden können.
Die Claude Sonnet 4.5-Serie von Anthropic testet gerade die gleiche Kontextfenstergröße in der Beta-Version und geht über die ursprüngliche Größe von 200.000 Tokens hinaus.
Open-Source-Modellfamilien wie Llama und Mistral liegen normalerweise zwischen 100.000 und 200.000 und bieten eine gute Leistung bei langen Kontexten, während sie trotzdem einfach lokal einzusetzen oder fein abzustimmen sind.
Eine coole Ausnahme ist Llama Maverick, das ein Fenster von 1 Million Token hat, das für allgemeine Schlussfolgerungen in langen Dokumenten gedacht ist. Llama Scout geht noch einen Schritt weiter und bietet eine riesige Kapazität von 10 Millionen Tokens, die speziell dafür gemacht ist, ganze Codebasen oder juristische Archive in einem einzigen Durchgang zu verarbeiten.
Aber die Veröffentlichung von GPT-5.2 gerade diese Woche hat eine neue Richtung eingeschlagen. Anstatt nach unendlichem Kontext zu streben, hat OpenAI sein neuestes Flaggschiff auf ein Fenster von 400.000 Token beschränkt und dabei die reine Größe gegen „perfekte Erinnerung” und überlegene Schlussfolgerungsfähigkeiten eingetauscht, die die bei größeren Modellen häufig auftretenden Ablenkungsprobleme vermeiden.
Die Unterschiede in der Größe des Kontextfensters beeinflussen, wie jedes Modell in echten Arbeitsabläufen funktioniert. Erweiterte Kontextfenster-Power-Modelle sind super genau, konsistent und können weit vorausdenken, aber sie brauchen auch mehr Rechenleistung und eine sorgfältigere Kontextwahl.
Die Mittelklasse-Modelle sind immer noch effizient und können auch mit langen Dokumenten und ausgedehnten Chats umgehen, aber für richtig große Datenmengen brauchen sie die richtige Struktur.
Die folgenden Anwendungsfälle zeigen, wie die Stärken von Modellen mit großen Kontextfenstern in echten Anwendungen zum Tragen kommen.
Mit genug Platz, um ganze Berichte, Transkripte, Codebasen oder Forschungsarbeiten auf einmal zu speichern, kann ein Modell Muster verfolgen, weit entfernte Details miteinander verbinden und von Anfang bis Ende ein zusammenhängendes Verständnis aufrechterhalten. Das hat viele Anwendungsbereiche:
Recht: Mit großen Fenstern können Leute ganze Verträge checken, Klauseln in mehreren Dokumenten vergleichen und versteckte Verweise in langen Dokumenten finden.
Gesundheitswesen: Teams können lange klinische Leitlinien, Patientenakten oder Datensätze aus mehreren Studien durchgehen und dabei wichtige Zusammenhänge im Blick behalten, die in kleineren Fenstern verloren gehen würden.
Forschung: Ein Modell mit großem Fenster kann ganze Artikel und Literaturübersichten auf einen Blick lesen und Zusammenhänge erkennen, die nur sichtbar werden, wenn man das ganze Dokument im Blick hat.
Größere Kontextfenster machen die KI in Gesprächen natürlicher, weil das Modell sich mehr an die Unterhaltung erinnern kann, ohne frühere Nachrichten zu vergessen.
Im Kundenservice sorgt das für reibungslosere und persönlichere Interaktionen. Das Modell kann frühere Vorlieben und Gespräche nutzen, um genauere und passendere Antworten zu geben.
Erweiterte Kontextfenster machen komplexe Schlussfolgerungen über Text, Audio und Bilder möglich, indem sie dem Modell genug Platz geben, um alle Modalitäten zusammen zu halten, anstatt sie einzeln zu verarbeiten.
Wenn die ganze Abschrift, die Bilder und das dazugehörige schriftliche Material in ein einziges Fenster passen, kann das Modell Details über verschiedene Formate hinweg vergleichen, Beziehungen verfolgen und ein einheitliches Verständnis des Kontexts aufbauen.
Dadurch werden die Lücken beseitigt, die entstehen, wenn Infos in Teile zerlegt oder zusammengefasst werden müssen, und das Modell kann den gesamten Satz von Eingaben auf einmal verarbeiten.
Große Kontextfenster bieten leistungsstarke Modellfunktionen, bringen aber auch neue Herausforderungen für die Leistung mit sich, wenn die Eingabegrößen zunehmen. Selbst die besten Modelle haben Probleme, bei superlangen Sequenzen die volle Aufmerksamkeit zu behalten, sodass sie nicht immer alle Infos aus dem Kontext so zuverlässig nutzen, wie man es erwarten würde.
Ein häufiges Problem bei Modellen mit langem Kontext ist der „Lost in the Middle“-Effekt. Modelle merken sich den Anfang und das Ende einer langen Sequenz ziemlich gut, aber sie übersehen oder ignorieren oft wichtige Details, die in der Mitte versteckt sind. Das kann zu schwächeren Antworten führen, selbst wenn der ganze Kontext da ist.
Wenn du die Eingabe clever strukturierst, kannst du dieses Problem bei wichtigen Aufgaben vermeiden. Das heißt, man sollte es in klare Abschnitte aufteilen oder wichtige Punkte wiederholen, damit das Modell sie nicht übersieht.
Die Kosten können mit einer größeren Kontextfenstergröße schnell steigen. Jedes zusätzliche Token macht die Berechnung der Aufmerksamkeit größer, was die Inferenzzeit, die GPU-Speicheranforderungen und die Gesamtbelastung des Systems erhöht.
Um das hinzukriegen, brauchen wir bessere Methoden, um die Infos ins Modell reinzuziehen. Techniken wie selektives Abrufen, hierarchisches Chunking oder schnelle Zusammenfassungen helfen dabei, die Eingabe kleiner zu halten, damit das Modell nicht überlastet wird.
Große Fenster bringen auch Bedenken in Bezug auf Sicherheit und Privatsphäre mit sich. Wenn du dem Modell mehr Input gibst, ist die Wahrscheinlichkeit größer, dass sensible Daten offengelegt werden.
Deshalb brauchen Teams klare Regeln für den Umgang mit Daten, Schritte zur Schwärzung und Zugriffskontrollen, damit große Kontextfenster keine neuen Risiken schaffen.
Oftmals erhöhen unnötige oder nur lose zusammenhängende Infos die kognitive Belastung für das Modell, was das Risiko von Halluzinationen und falschen Mustern erhöht. Lange Eingaben bringen auch Störsignale mit sich, die das Verständnis des Modells für die Aufgabe beeinträchtigen können.
In der Praxis kommt gute Leistung oft von einem sorgfältig zusammengestellten Kontext, der dafür sorgt, dass das Modell die richtigen Infos sieht, anstatt einfach nur mit der größten Menge an Infos überhäuft zu werden.
Es gibt ein paar Methoden, um Kontextfenster optimal zu nutzen. Dazu gehören Retrieval Augmented Generation (RAG), Context Engineering, Chunking und Modellauswahl.
Retrieval Augmented Generation (RAG) holt sich zusätzliche Infos aus einer externen Datenbank und gibt sie an das Modell weiter, wenn der Kontext das erfordert.
Anstatt ganze Dokumente ins Kontextfenster zu packen, speichert RAG alles separat und holt nur die Teile raus, die für die aktuelle Frage wichtig sind. Dadurch bleibt der Kontext überschaubar, und das Modell kriegt trotzdem alle Infos, die es braucht.
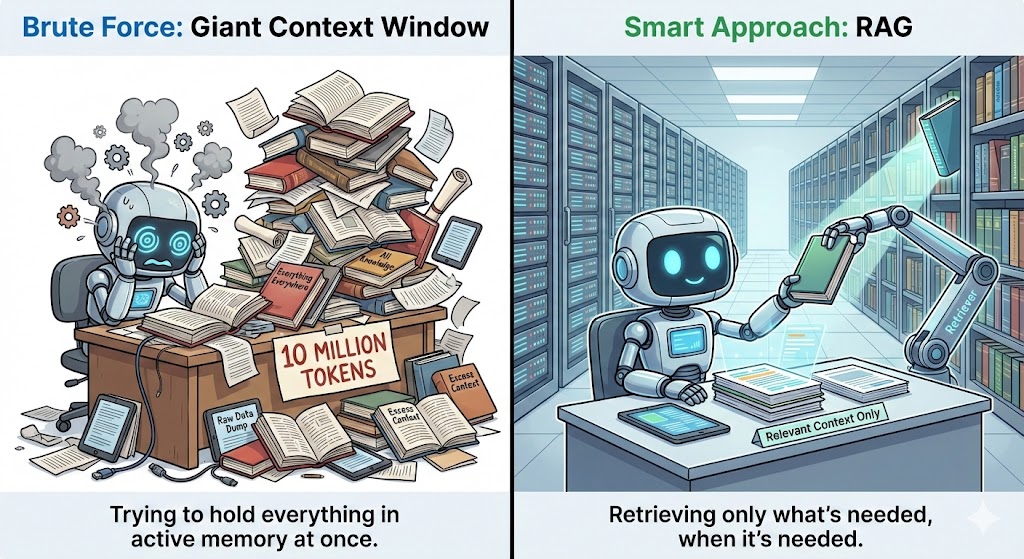
Dazu nutzt es Einbettungen oder Vektorsuche, um die relevantesten Teile zu finden, und schickt diese Teile auf übersichtliche, strukturierte Weise an das Modell. Das macht das Modell genauer, weil es so mehr relevante Infos nutzen kann, die über die Trainingsdaten hinausgehen.
Beim Context Engineering geht's darum, Modelle mit den richtigen Infos zu füttern, statt sie mit unnötigen Details zu überladen. Effektive Strategien sind zum Beispiel, lange Dokumente in Abschnitte zu teilen, weniger wichtige Teile zusammenzufassen und mit einfachen Vorverarbeitungsschritten die wichtigsten Punkte hervorzuheben.
Die semantische Suche hilft hier, indem sie den Text findet, der für die aktuelle Suche wichtig ist. Du kannst die Ergebnisse auch verbessern, indem du die wichtigsten Infos an den Anfang oder das Ende des Kontexts verschiebst, weil Modelle sich diese Stellen besser merken.
Chunking teilt lange Dokumente in kleinere, zusammenhängende Abschnitte auf. Die Idee ist, Inhalte nach ihrem Thema, ihrer Struktur oder der Aufgabe, die sie unterstützen, zu gruppieren.
Dadurch bleibt jeder Abschnitt zusammenhängend und das Modell kann sich besser konzentrieren, anstatt sich in einem riesigen Textblock zu verlieren. Wenn du mehr wissen willst, schau dir doch diesen Artikel über fortgeschrittene Chunking-Strategien an.
Semantisches Chunking gruppiert Sätze, die eine ähnliche Bedeutung haben, anstatt den Text nach willkürlichen Zeichenbegrenzungen zu zerschneiden. Es teilt den Inhalt an natürlichen Stellen wie Themenwechseln, Absatzübergängen oder Abschnittsüberschriften auf.
Das aufgabenbasierte Chunking geht noch einen Schritt weiter, indem es jeden Chunk um die spezifische Frage herum formt, die du beantworten möchtest. Jeder Abschnitt hat dann nur die Infos, die für diese Aufgabe wirklich wichtig sind.
Aufgaben, bei denen es um die Analyse ganzer Dokumente, das Verknüpfen mehrerer Dateien oder lange Unterhaltungen geht, funktionieren am besten mit Modellen, die zwischen 200.000 und 1 Million Fenster haben. Für Aufgaben wie Zusammenfassungen, Code-Reviews oder kurze Fragen bieten Modelle im Bereich von 100.000 bis 200.000 oft die beste Balance zwischen Geschwindigkeit, Kosten und Genauigkeit.
Kleinere Fenster können trotzdem gut funktionieren, wenn man sie mit starken Abrufsystemen kombiniert. Ein gutes RAG-System ( ) oder MCP (Model Context Protocol) kann die richtigenInfos bei Bedarf abrufen, sodass das Modell nicht alles im Speicher behalten muss.
Bevor wir zum Schluss kommen, schauen wir uns mal an, wie sich die Technologie in Sachen Kontextfenster entwickelt.
Zukünftige Modellarchitekturen gehen eher in Richtung dynamischer Kontextfenster statt Fenster mit fester Größe.
Forscher schauen sich Ansätze an, die die Stärken von Transformatoren mit neuen Langzeitgedächtnissystemen kombinieren. Das führt zu Modellen, die Infos speichern und abrufen können, ohne nur auf Aufmerksamkeitsmechanismen angewiesen zu sein.
Diese Architekturen machen Schluss mit den aktuellen Einschränkungen, indem sie von statischen Kontextfenstern zu dynamischen Speicherschichten wechseln, die mit der Aufgabe mitwachsen.
Speichersysteme sind ein weiterer Bereich, in dem es Innovationen gibt. Zukünftige Modelle werden wahrscheinlich mehr auf kontextbezogene Speichersysteme setzen, die über eine einzelne Sitzung hinausgehen und für Kontinuität sorgen.
Anstatt jedes Gespräch wie einen Neuanfang zu behandeln, speichern diese Systeme wichtige Präferenzen, frühere Entscheidungen und wiederkehrende Themen in einer strukturierten Speicherschicht, die bei Bedarf abgerufen werden kann.
Dadurch wird die Personalisierung von reaktiv zu proaktiv, sodass das Modell die Nutzer besser verstehen und langfristige Ziele mit viel mehr Beständigkeit unterstützen kann.
Auch die externe Abfrage entwickelt sich weiter. Im Moment funktioniert RAG wie eine Suchmaschine, die relevante Texte in die Eingabeaufforderung zieht. Fortgeschrittene Versionen wi , wie Corrective Retrieval-Augmented Generation (CRAG) , gibt's schon , aber das ist erst der Anfang.
In Zukunft wird das Abrufen von Daten sich mehr wie eine integrierte Funktion anfühlen, fast so, als hätte das Modell seinen eigenen externen Speicher. Sie sammeln, komprimieren und zeigen Infos automatisch an, ohne dass man viel machen muss.
Persistent Memory wird auch die Art und Weise verändern, wie wir mit KI interagieren. Anstatt nach dem Ende einer Sitzung alles zu vergessen, merkt sich das Modell wichtige Details über Tage, Wochen oder sogar Monate hinweg. Wenn es deinen Stil, deine Gewohnheiten und Prioritäten lernt, kann es dir passendere und hilfreichere Antworten geben, ohne dass du dich wiederholen musst.
Toolswie Mem0 sind schon da und machen den Anfang mit diesem Ansatz, indem sie als spezielle Speicherschicht zwischen Apps und LLMs fungieren. Für die Zukunft denken wir aber, dass diese Funktionen eher direkt in die Modellarchitekturen eingebaut werden, statt auf externe Schichten angewiesen zu sein.
Größere Fenster ermöglichen leistungsstarke neue Arbeitsabläufe, bringen aber auch Herausforderungen in Sachen Aufmerksamkeit, höhere Rechenkosten und Qualitätsrisiken mit sich, wenn der Kontext überladen ist. Deshalb ist strategisches Kontextmanagement echt wichtig.
Techniken wie Retrieval Augmentation, Semantic Chunking und Context Engineering helfen Modellen, fokussiert, effizient und zuverlässig zu bleiben, auch wenn ihre Kapazitäten wachsen.
In Zukunft werden die besten LLM-basierten Systeme clevere Tools mit einem guten Verständnis dafür verbinden, wie der Kontext das Denken beeinflusst. Wenn Teams diese Prinzipien anwenden, können sie die Vorteile von Modellen mit langem Kontext nutzen und sich gleichzeitig auf die nächste Generation von Architekturen vorbereiten, die die Grenzen des Kontexts noch weiter verschieben.
Bring deine Python-Grundkenntnisse auf die nächste Stufe mitden Skill Track „Entwicklung großer Sprachmodelle ”. Es soll dir helfen, dich von den Grundlagen des Programmierens bis hin zur Entwicklung und Feinabstimmung deiner eigenen leistungsstarken KI-Anwendungen zu begleiten.
LLM-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Allan Ouko

