
Lernpfad
Grundlagen der KI
10 Std.
Der Aufmerksamkeitsmechanismus ist das Herzstück von Transformermodellen. Alle gängigen Modellarchitekturen, wie GPT, LLaMAund Mixture of Experts (MoE)nutzen es, um Token zu verbinden und Bedeutung zu schaffen.
Aber Aufmerksamkeit kostet viel. Die Berechnung braucht große Matrixmultiplikationen und vor allem einen riesigen Datenaustausch zwischen dem GPU-Speicher und den Recheneinheiten. Wenn die Sequenzlängen länger werden, wird die Speicherbandbreite zum echten Engpass.
Die Optimierung der Aufmerksamkeit hat daher einen überproportionalen Einfluss auf die LLM-Leistung, und genau da kommt Flash Attention ins Spiel. In diesem Artikel erkläre ich dir, was Flash Attention ist, wie es funktioniert und wie du es mit PyTorch und Hugging Face Transformers nutzen kannst.
Wenn du nach einer Möglichkeit suchst, dich mit LLMs vertraut zu machen, empfehle ich dir unseren Einführungskurs zu LLM-Konzepte.
Flash Attention ist ein optimierter Transformer-Aufmerksamkeitsmechanismus Aufmerksamkeitsmechanismus, der auf GPUs deutlich schneller und speichereffizienter ist.
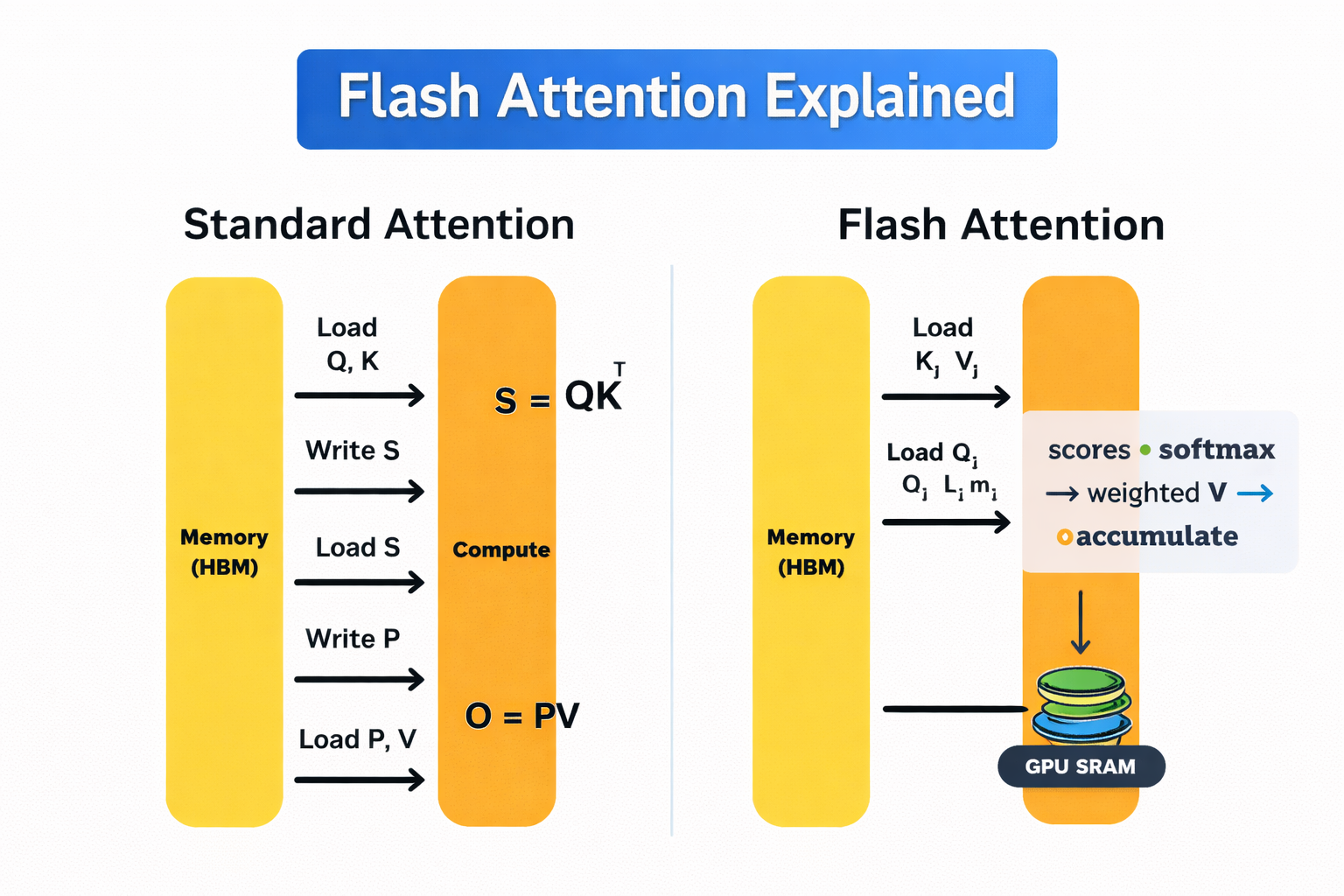
Normale Aufmerksamkeit vs. Flash-Aufmerksamkeit
GPUs haben zwei Hauptspeichertypen. High-Bandwidth Memory (HBM) ist groß, aber ziemlich langsam. On-Chip-SRAM ist mega schnell, hat aber echt wenig Speicherplatz.
Die Standard-Selbstaufmerksamkeit schickt ständig Daten zwischen diesen beiden hin und her. Dieses Hin und Her ist teuer und wird mit zunehmender Sequenzlänge zu einem erheblichen Kostenfaktor.
Flash Attention vermeidet das, indem es die Aufmerksamkeit in kleinen Kacheln berechnet, die komplett in den schnellen SRAM passen. Jede„ “-Kachel wird von Anfang bis Ende mit „ “ verarbeitet, wobei „softmax“ schrittweise angewendet wird, sodass Zwischenergebnisse nicht zurück in HBM geschrieben werden müssen. Deshalb wird die ganze Aufmerksamkeitsmatrix nie im Speicher abgelegt.
Im Gegensatz zu spärlichen oder linearen Aufmerksamkeitsmethoden ist Flash Attention keine Annäherung. Es liefert genau die gleichen mathematischen Ergebnisse wie die Standard-Selbstaufmerksamkeit, nur dass es speichereffizienter ist.
Flash Attention ist so effizient, weil es die Art und Weise, wie die Aufmerksamkeit auf der GPU berechnet wird, neu gestaltet hat. Es funktioniert ganz einfach: Mach so viel wie möglich im schnellen Speicher auf dem Chip und vermeide unnötige Bewegungen zum langsamen Speicher.
Eine gute Möglichkeit, sich das vorzustellen, ist eine Analogie zur Küche. Der On-Chip-SRAM der GPU ist wie eine kleine, schnelle Küchenzeile. Hier machst du alles fertig und kochst. GPU-HBM-Speicher (High Bandwidth Memory) ist wie ein großer Supermarkt um die Ecke. Du kannst alles, was du brauchst, darin verstauen, aber das Hin- und Herlaufen kostet Zeit.
Einfach gesagt, die Standardaufmerksamkeit rennt nach jedem Schritt zum Supermarkt. Im Gegensatz dazu plant Flash Attention das Kochen so, dass alles auf die Arbeitsfläche passt, während du kochst. Schauen wir uns das genauer an:
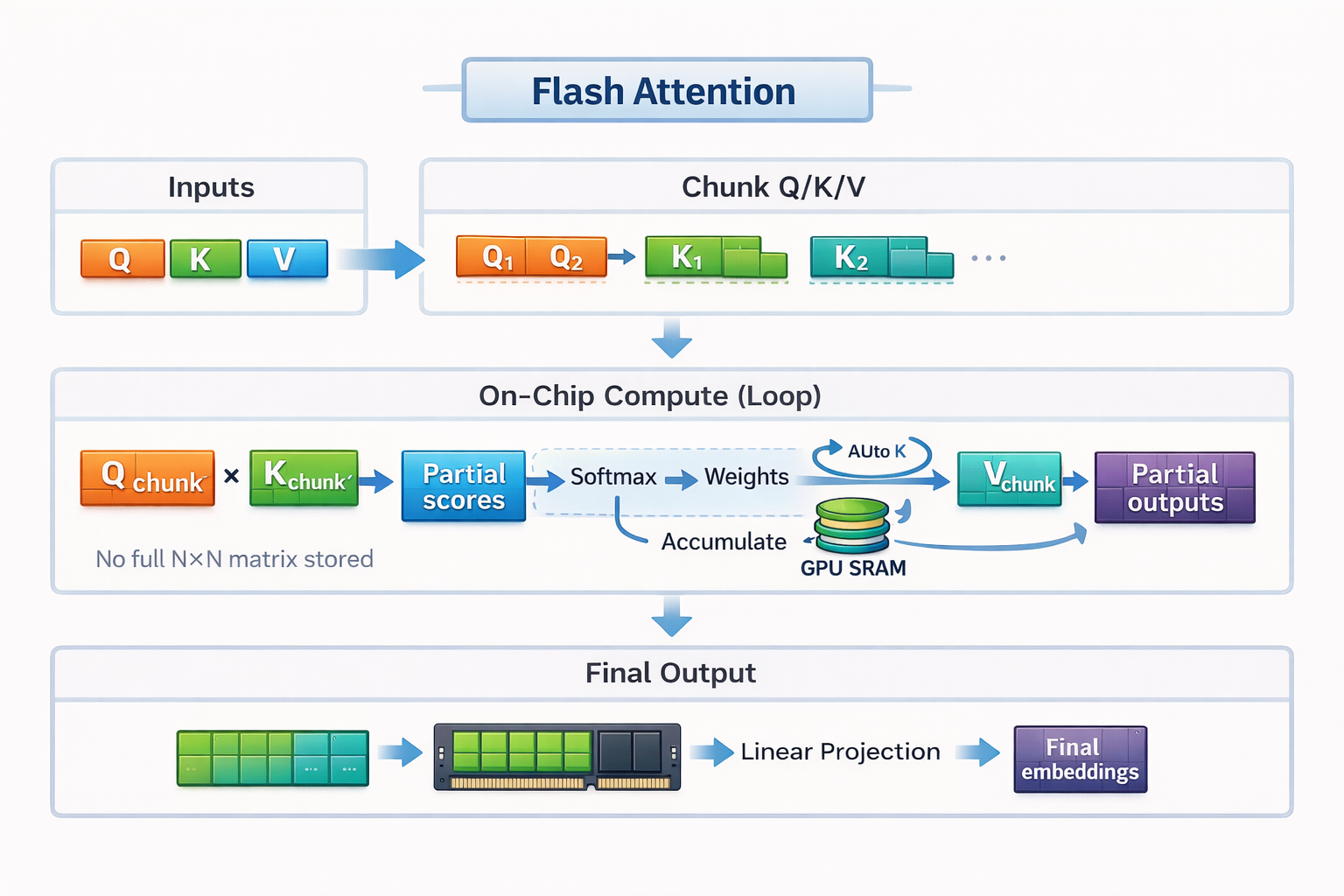
Flash Attention – Wie es funktioniert
Flash Attention basiert auf zwei Hauptideen: Kacheln und Neuberechnung.
Um bei unserem Kochbeispiel zu bleiben: Durch „Tiling“ passt Flash Attention die Aufmerksamkeitsberechnung auf den kleinen Zähler.
Anstatt die ganze Sequenz zu laden und eine komplette Aufmerksamkeitsmatrix zu erstellen, teilt Flash Attention die Eingaben in kleine Blöcke oder Kacheln auf. Jede Kachel passt komplett in den schnellen SRAM der GPU. Flash Attention berechnet die Aufmerksamkeit Kachel für Kachel, von Anfang bis Ende, bevor es zur nächsten Kachel weitergeht.
Wie in der Küche kannst du nicht alle Zutaten für ein ganzes Festessen auf einer kleinen Arbeitsplatte unterbringen. Also machst du alles in kleinen Portionen fertig und kochst sie. Du hackst ein paar Gemüsesorten, kochst sie, räumst den Platz auf und machst dann mit der nächsten Portion weiter. Wenn du so arbeitest, musst du nicht ständig zum Supermarkt laufen.
Durch diese blockweise Ausführung kann Flash Attention Daten lokal, schnell und effizient halten, ohne jemals die ganze Aufmerksamkeitsmatrix im langsamen Speicher zu materialisieren.
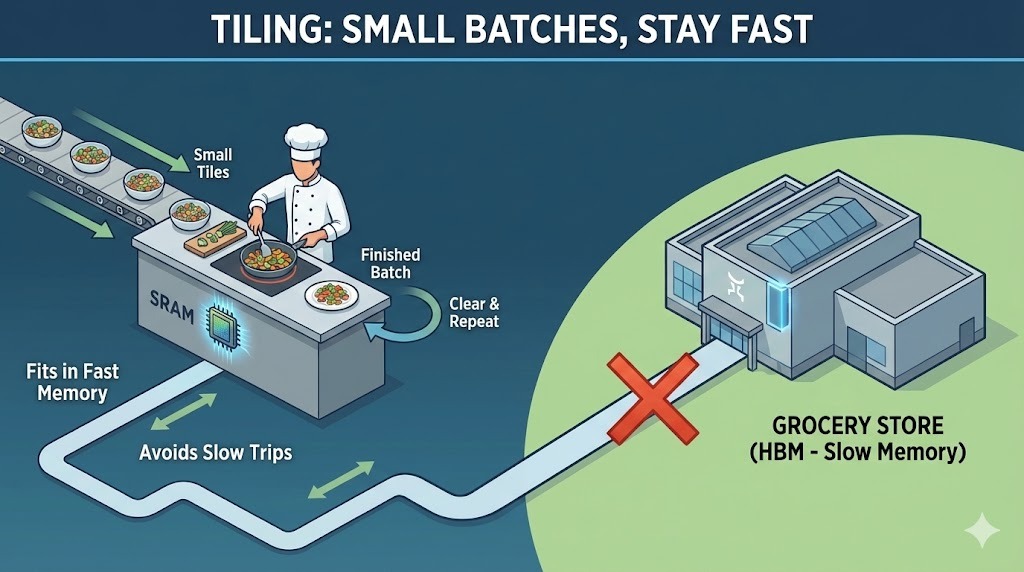
Kacheln in Flash Achtung
Während des Trainings speichert Standard Attention viele Zwischenergebnisse, damit sie beim Rückwärtsdurchlauf wiederverwendet werden können. Dieser Speicherplatz ist ziemlich teuer. Flash Attention geht das anders an. Anstatt diese Zwischenwerte zu speichern, berechnet es kleine Teile der Aufmerksamkeitswerte neu, wann immer sie gebraucht werden.
Zurück in der Küche ist das wie Zwiebeln schneiden. Du könntest zum Supermarkt laufen, um deine gehackten Zwiebeln zu retten, und später wieder zurücklaufen, um sie zu holen. Oder du kannst sie wegwerfen und einfach eine frische Zwiebel hacken, wenn es Zeit zum Kochen ist. Überraschenderweise ist die zweite Option schneller, weil sie häufige/längere Bewegungen vermeidet.
Bei modernen GPUs läuft die Neuberechnung genauso ab, weil zusätzliche Berechnungen im Vergleich zu Speicherbewegungen nicht so teuer sind. Durch die Neuberechnung kleiner Werte, anstatt sie zu speichern und zu laden, reduziert Flash Attention den Speicherverkehr erheblich und sorgt gleichzeitig für ein effizientes Training.
Durch die Kombination von Tiling und Neuberechnung kann Flash Attention die Aufmerksamkeitsberechnung auf dem Zähler halten, die Fahrten zum Supermarkt minimieren und die Stärken moderner GPU-Hardware voll ausnutzen.
Flash Attention 2 (FA2), das 2023 rausgekommen ist, ist ein echtes Upgrade gegenüber der ersten Generation. Es bleibt bei der Grundidee von IO-Bewusstsein und genauer Aufmerksamkeit, verbessert aber die Effizienz in mehreren Bereichen, die bei echten Arbeitslasten wichtig sind.
Die erste Version von Flash Attention hat die Berechnung über die Batchgröße und die Attention Heads verteilt. Das hat bei Trainingsaufbauten mit großen Chargen gut geklappt. Aber für die Inferenz war es nicht so gut, weil die Batchgrößen oft klein und die Sequenzlängen lang sind.
FA2 macht die ganze Sequenzlänge parallel. Dadurch können mehr Teile der Aufmerksamkeitsberechnung gleichzeitig laufen, auch wenn die Stapelgröße klein ist. Durch die Verteilung der Arbeit auf die Token in der Sequenz hält v2 mehr Recheneinheiten der GPU gleichzeitig beschäftigt.
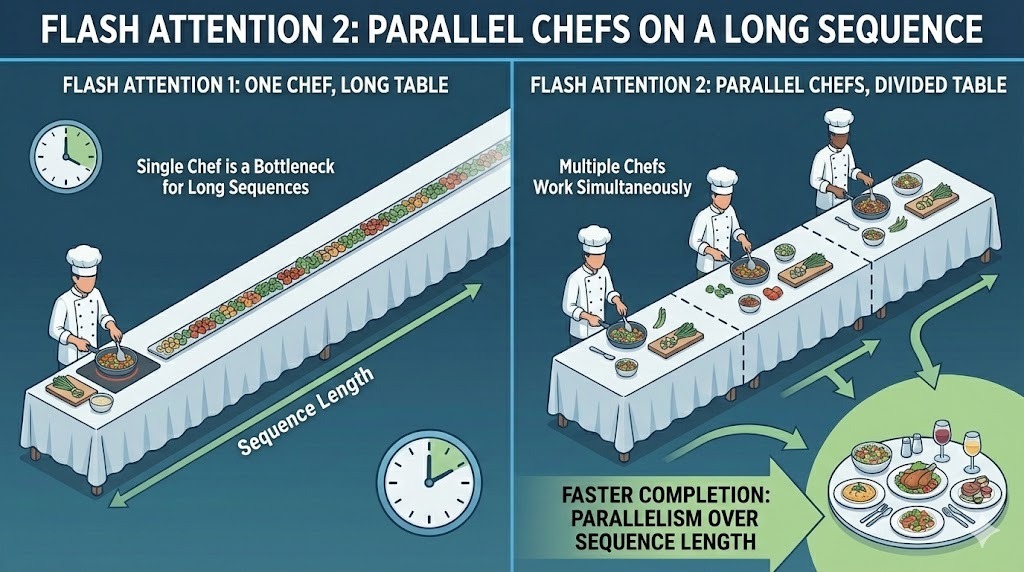
Parallelität über Batches hinweg in Flash Attention 2
Der praktische Vorteil ist ein höherer Durchsatz und eine bessere Hardwareauslastung in typischen Inferenzszenarien, wo lange Eingabeaufforderungen und kleine Stapel die Regel sind.
GPUs sind echt gut im Multiplizieren von Matrizen. Spezielle Hardware namens Tensor Cores kann allgemeine Matrixmultiplikationsoperationen (GEMM) super schnell ausführen.
Das Problem ist, dass Aufmerksamkeit nicht nur Matrixmultiplikation ist: Sie beinhaltet auch Sachen wie Skalierung, Maskierung und Softmax, die auf normalen GPU-Kernen laufen und im Vergleich viel langsamer sind.
FA2 hat dieses Ungleichgewicht verringert. Es strukturiert die Berechnung neu, um nicht-matrixbasierte Fließkommaoperationen zu minimieren, vor allem solche, die bei der Neuskalierung von Aufmerksamkeitswerten eine Rolle spielen. Der Großteil der Laufzeit wird für große, effiziente Matrixoperationen gebraucht, die Tensor Cores beschleunigen können.
Flash Attention v1 wurde für Kopfgrößen von 64 oder 128 optimiert, was zu Modellen wie BERT und GPT-3 passt. Mit der Weiterentwicklung der Modellarchitekturen wurden die Kopfabmessungen größer, um größere Einbettungsgrößen und eine höhere Modellkapazität zu ermöglichen.
FA2 unterstützt jetzt Kopfgrößen bis zu 256. Dadurch wurde es mit neueren Architekturen kompatibel, die auf breitere Aufmerksamkeitsköpfe setzen.
Flash Attention 3 (FA3) ist der aktuelle Industriestandard, der moderne Modelle wie GPT-5.2. Es baut auf derselben IO-bewussten, präzisen Aufmerksamkeitsgrundlage wie frühere Versionen auf, wurde aber speziell für NVIDIA H100 (Hopper) GPUs entwickelt.
Der entscheidende Unterschied ist, dass FA3 so gemacht ist, dass es die neuen asynchronen Hardwarefunktionen von Hopper nutzt, sodass Speicherbewegungen und Berechnungen viel aggressiver als vorher überlappen können.
In früheren Versionen sind alle GPU-Threads, die als Warps bezeichnet werden, dem gleichen Ausführungspfad gefolgt. FA3 ändert dieses Modell durch Warp-Spezialisierung. Es gibt jedem Warp eine von zwei verschiedenen Aufgaben:
Durch diese Trennung können Datenübertragung und Berechnung gleichzeitig laufen. Während die Producer-Warp-Prozessoren die nächsten Datenblöcke holen, arbeiten die Consumer-Warp-Prozessoren weiter an den aktuellen Datenblöcken, was die Latenzzeit deutlich verbessert.
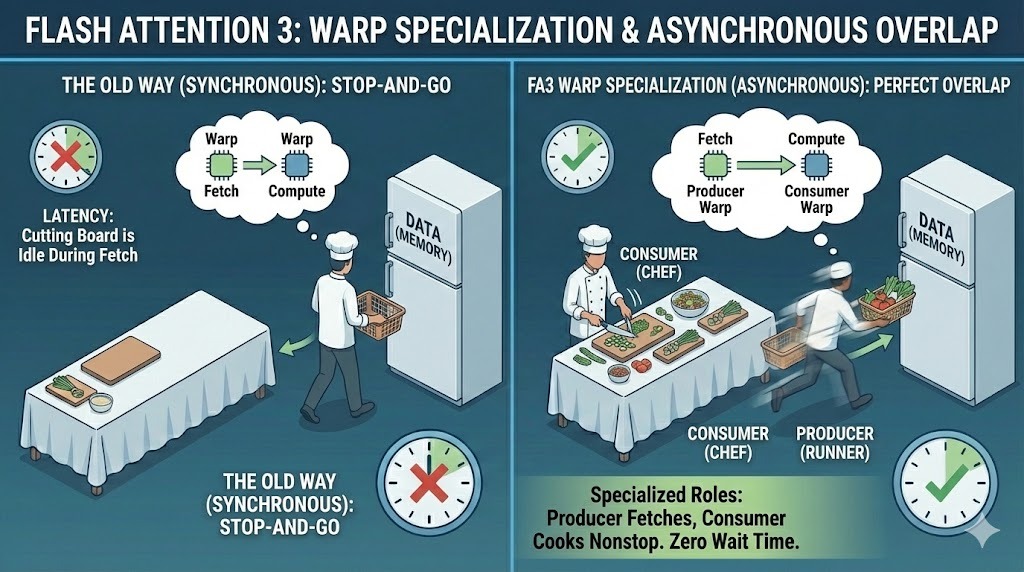
Warp-Spezialisierung in Flash Attention 3
Flash Attention 3 bietet jetzt auch native Unterstützung für FP8, also 8-Bit-Gleitkommagenauigkeit. Frühere Versionen haben hauptsächlich auf FP16 oder BF16 gesetzt, was den Speicherverbrauch im Vergleich zu FP32 schon reduziert hat, aber trotzdem noch viel Bandbreite verbraucht hat.
FP8 halbiert den Speicherbedarf noch mal ungefähr. Diese Reduzierung führt direkt zu einem höheren Durchsatz und weniger Speicherbedarf. Auf Hopper-GPUs ist FP8 hardwarebeschleunigt, was bedeutet, dass FA3 mehr Aufmerksamkeitsoperationen pro Sekunde verarbeiten kann, ohne die Genauigkeit auf Modellebene zu beeinträchtigen.
Diese Fähigkeit ist ein wichtiger Grund dafür, dass große Modelle wie Gemini 3 riesige Kontextfenster bewältigen und gleichzeitig Millionen von Nutzern effizient bedienen können.
Ein letzter Teil vom FA3-Design ist die Nutzung vom Tensor Memory Accelerator (TMA) des H100. Die TMA ist eine spezielle Hardware, die Speicherkopien asynchron macht, ohne die Hauptrechenkerne zu belasten.
Flash Attention 3 nutzt TMA, um Datenblöcke im Hintergrund zu verschieben, während die Berechnung ohne Unterbrechung weiterläuft. Durch die enge Verknüpfung von Speicherbewegungen mit mathematischen Operationen kann FA3 fast 75 Prozent der theoretischen Spitzenleistung der Hardware nutzen.
Flash Attention 4 (FA4) ist der nächste Schritt in der Forschung zur Optimierung der Aufmerksamkeit. Es ist für die neuen Blackwell B200-GPUs von NVIDIA gemacht und zeigt, was alles möglich wird, wenn man Attention-Kernel für eine ganz neue Art von Hardware entwickelt.
Da die Modellgrößen immer weiter wachsen und Trainingsläufe sich der Billionen-Parameter-Skala nähern, wird irgendwann sogar Flash Attention 3 an seine Grenzen stoßen. FA4 ist ein erster Versuch, diese Einschränkungen zu beseitigen, indem die Hardwareauslastung weiter als bei jedem bisherigen Attention-Kernel vorangetrieben wird.
Im Moment ist Flash Attention 4 noch eine Technologie, die in der Forschung und Vorproduktion steckt. Es sieht echt vielversprechend aus, wird aber noch nicht in eingesetzten oder produktionsreifen Modellen genutzt.
Einer der wichtigsten Punkte bei Flash Attention 4 ist die Leistung. Es ist der erste Attention-Kernel, der entwickelt wurde, um 1 PFLOPS oder eine Billiarde Fließkommaoperationen pro Sekunde auf einer einzigen GPU zu schaffen.
Es geht um eine Zukunft, in der das Trainieren von Modellen mit Billionen Parametern einfach zu lange dauern würde. Bei dieser Größe führen schon kleine Ineffizienzen zu riesigen Verzögerungen. FA4 will diese zukünftigen Trainingsläufe möglich machen, indem es extreme Leistung aus einem einzigen Chip rausholt.
Um diese Leistung zu erreichen, geht FA4 in Sachen Asynchronität viel weiter als die alten Versionen. Es erweitert das Produzenten-Konsumenten-Modell auf super komplexe, mehrstufige Pipelines, wo Datenbewegung, Berechnung und Synchronisation alle unabhängig voneinander laufen.
Anstatt nur das Laden und Rechnen einfach zu überlappen, macht FA4 eine echt asynchrone Ausführung über mehrere Phasen hinweg. Verschiedene Teile des Kernels laufen unterschiedlich schnell ab und werden durch die Planung auf Hardwareebene koordiniert, nicht durch einen einzigen synchronisierten Ablauf.
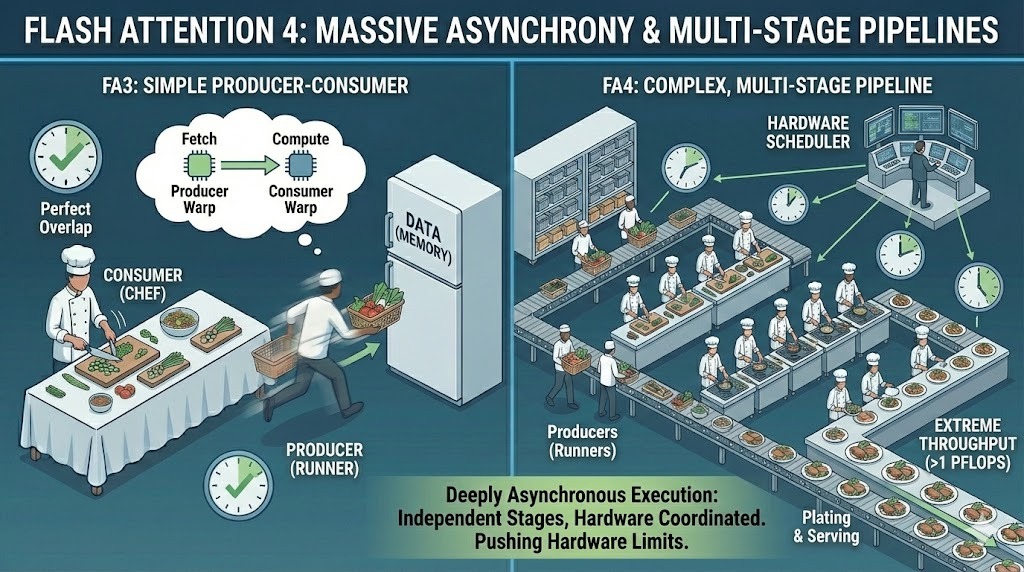
Massive Asynchronität in Flash Attention 4
Diese Komplexität ist auch der Grund, warum FA4 noch im Versuchsstadium ist. Die Genauigkeit, Stabilität und Integration auf dieser Ebene zu verwalten, ist echt schwierig. Die Community muss noch weiter daran arbeiten, bevor Teams sie zuverlässig in großen Produktionsmodellen nutzen können.
Schauen wir mal, wie Flash Attention im Vergleich zum normalen Aufmerksamkeitsmechanismus in ein paar wichtigen Bereichen abschneidet.
Benchmarks zeigen immer wieder, dass alle Flash Attention-Versionen besser sind als Standard-Self-Attention, wobei die Vorteile mit zunehmender Sequenzlänge noch größer werden.
Das ursprüngliche Flash-Attention-Studie sagt, dass es ungefähr 2 bis 4 Mal schneller ist als die optimierte Standard-Aufmerksamkeit. Flash Attention 2 macht das noch besser, indem es die Parallelität erhöht und die GPU besser auslastet, was in der Praxis oft zu einer weiteren Verbesserung um etwa das Doppelte führt.
Flash Attention 3 macht die Leistung auf Hopper-GPUs noch besser, vor allem mit FP8, und erreicht so eine viel höhere Hardwareauslastung als mit Standard-Attention.
Die Standardaufmerksamkeit macht die ganze N × N-Aufmerksamkeitsmatrix richtig sichtbar, was zu einem quadratischen Speicherwachstum in Bezug auf die Sequenzlänge führt. Wenn N größer wird, steigt der Speicherverbrauch extrem an und überlastet schnell den GPU-Speicher. Flash Attention vermeidet es, diese Matrix komplett zu speichern.
Durch die Berechnung der Aufmerksamkeit in Kacheln und die Speicherung von Zwischenergebnissen in einem schnellen On-Chip-Speicher wird der Speicherbedarf bei festen Kopfabmessungen auf einen linearen Wert in Abhängigkeit von der Sequenzlänge reduziert. Durch den Wechsel von quadratischer zu linearer Speicherskalierung wird der größte strukturelle Engpass bei der Standard-Aufmerksamkeit beseitigt.
Diese Speicherreduzierung ermöglicht direkt längere Kontextfenster. Bei normaler Aufmerksamkeit kommt es bei Modellen oft zu Speicherfehlern, sobald Sequenzen ein paar tausend Token erreichen.
Flash Attention macht 4k- und 8k-Token-Kontexte auf einer einzigen GPU möglich und ermöglicht in Kombination mit anderen speichersparenden Techniken sogar viel längere Fenster, wie z. B. 16k- oder 32k-Token, auf diesem einen Gerät.
Verwirr dich hier nicht: Die riesigen Fenster mit Millionen von Token, die in einigen aktuellen Grenzmodellen wie Gemini 3, werden durch die Aufteilung der Sequenz auf große GPU-Cluster erreicht, da sie die Speicherkapazität eines einzelnen Geräts weit übersteigen.
Flash Attention zu benutzen ist heute viel einfacher als früher. In den meisten Fällen musst du keine eigenen CUDA-Kernel schreiben oder deine Modellarchitektur ändern. Die Unterstützung ist schon in den gängigen Tools eingebaut.
Seit PyTorch 2.0 ist Flash Attention direkt über torch.nn.functional.scaled_dot_product_attention verfügbar. Wenn du diese Funktion aufrufst, sucht PyTorch automatisch das schnellste verfügbare Attention-Backend für deine Hardware raus.
Auf den unterstützten GPUs ist dieses Backend Flash Attention. Aus Sicht des Benutzers sieht es oft wie ein Standard-Aufmerksamkeitscode aus, aber im Hintergrund sendet PyTorch einen optimierten Flash-Attention-Kernel.
Wenn du Hugging Face Transformers, musst du für Flash Attention meistens nur eine Zeile ändern. Wenn du in der Modellkonfiguration „ attn_implementation="flash_attention_2" “ einstellst, sagt das der Bibliothek, dass sie Flash Attention 2 verwenden soll, wann immer es geht.
Bei vielen Transformator-Modellen reicht das aus, um sowohl die Geschwindigkeit als auch den Speicherbedarf zu verbessern, ohne den Rest des Trainings- oder Inferenzcodes anzufassen.
Flash Attention 2 ist für moderne NVIDIA-GPUs gedacht und läuft am besten auf Ampere-, Ada- und Hopper-Architekturen, wie zum Beispiel A100, RTX 3090, RTX 4090 und H100. Diese GPUs bieten die Speicherbandbreite und die Architekturmerkmale, die man braucht, um die Vorteile von Tiling und Parallelität in FA2 voll auszuschöpfen.
Übrigens, die alte Version von Flash Attention v1 läuft auch auf älteren GPUs. Turing-basierte Karten wie die T4 und RTX 2080 können immer noch Flash Attention v1 nutzen, aber die neueren Versionen brauchen aktuellere Hardware, um ihre volle Leistungssteigerung zu zeigen.
Wenn du PyTorch 2.x oder Hugging Face Transformers schon auf einer modernen NVIDIA-GPU benutzt, musst du in der Regel nur einen Konfigurationsschalter umlegen, um Flash Attention zu nutzen.
Die Standardaufmerksamkeit stieß auf eine harte Grenze, weil das quadratische Speicherwachstum lange Sequenzen langsam, teuer oder einfach unmöglich machte, weil der Speicherplatz nicht ausreichte. Flash Attention hat das geändert, indem es die Art und Weise, wie Aufmerksamkeit umgesetzt wird, neu gestaltet hat.
Durch die Reduzierung des Speicherbedarfs von quadratisch auf linear in Bezug auf die Sequenzlänge macht Flash Attention die Modellierung langer Kontexte praktikabel. Kontextfenster, die früher GPUs mit ein paar tausend Tokens überfordert haben, können jetzt auf derselben Hardware auf 4k, 8k und sogar über 32k Tokens skaliert werden.
Wenn du mit Transformatoren in großem Maßstab arbeitest und Flash Attention nicht nutzt, verschenkst du mit ziemlicher Sicherheit Leistung.
Willst du deine eigenen Modelle erstellen, die Flash Attention nutzen können? Mach unseren Kurs über Transformermodelle mit PyTorch!
KI-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Laiba Siddiqui
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree

