
Lernpfad
Associate AI Engineer für Entwickler
26 Std.
Meta hat gerade die Llama 4-Serie auf den Markt gebracht, die zwei fortschrittliche Modelle umfasst: Llama 4 Scout und Llama 4 Maverick. Beide sind offen, aber für die Feinabstimmung von Llama 4 Scout werden vier H100-GPUs benötigt, für Llama 4 Maverick acht. Das bedeutet, dass es sich nur Unternehmen mit großen Ressourcen leisten können, sie zu optimieren.
In diesem Blog zeige ich dir, wie du das Llama 4 Scout für nur 10 Dollar über die RunPod-Plattformfeinjustierenkannst . Du wirst lernen:
Wir halten unsere Leserinnen und Leser mit The Median auf dem Laufenden, unserem kostenlosen Freitags-Newsletter, der die wichtigsten Meldungen der Woche aufschlüsselt. Melde dich an und bleibe in nur ein paar Minuten pro Woche auf dem Laufenden:
Gehe zum RunPod Website und erstelle ein Konto. Danach gehst du auf die Seite Runpod-Rechnung und füge $25 mit der Kreditkarte hinzu. Du kannst auch mit Kryptowährungen bezahlen.
Navigieren Sie zu den Meine Pods um mit der Konfiguration deines Pods zu beginnen. Der Pod dient als virtueller Server, der dir die notwendigen CPUs, GPUs, Arbeitsspeicher und Speicher für deine Aufgaben zur Verfügung stellt.
Wir wählen 3x H200 SXM GPUs, die genügend Speicherplatz zum Laden des Modells bieten , quantisieren zu laden, es zu quantisieren und auf den neuen Datensatz abzustimmen. Alternativ kannst du auch das Unsloth Framework verwenden, um das Modell auf einem einzelnen H100 laufen zu lassen - allerdings hat dieser Ansatz bei mir nicht effektiv funktioniert.
Um deinen Pod einzurichten, befolge diese Schritte:
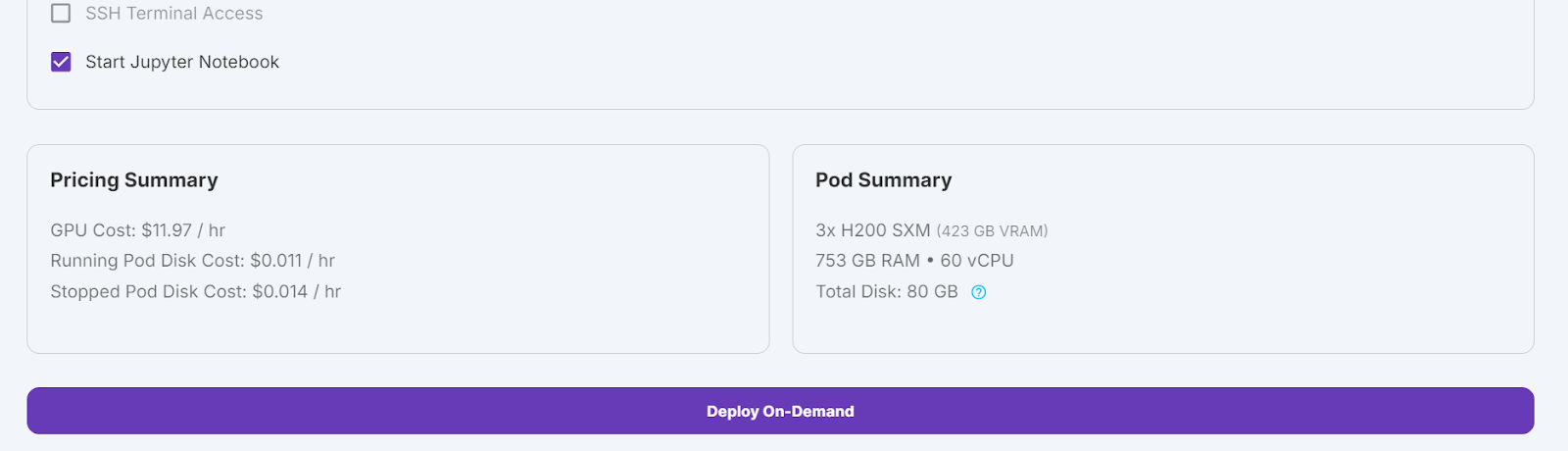
Wir ändern unseren Pod, indem wir die Festplattengröße des Containers auf 300 GB erhöhen und die Umgebungsvariable HF_TOKEN hinzufügen, die dein Hugging Face-Zugangs-Token ist. Dieser Token ist wichtig, um das Modell effektiv zu laden und zu speichern.
Es wird einige Zeit dauern, den Container aufzustellen. Wenn alles eingerichtet ist, klicke auf die Schaltfläche "Verbinden" und starte die JupyterLab-Instanz.
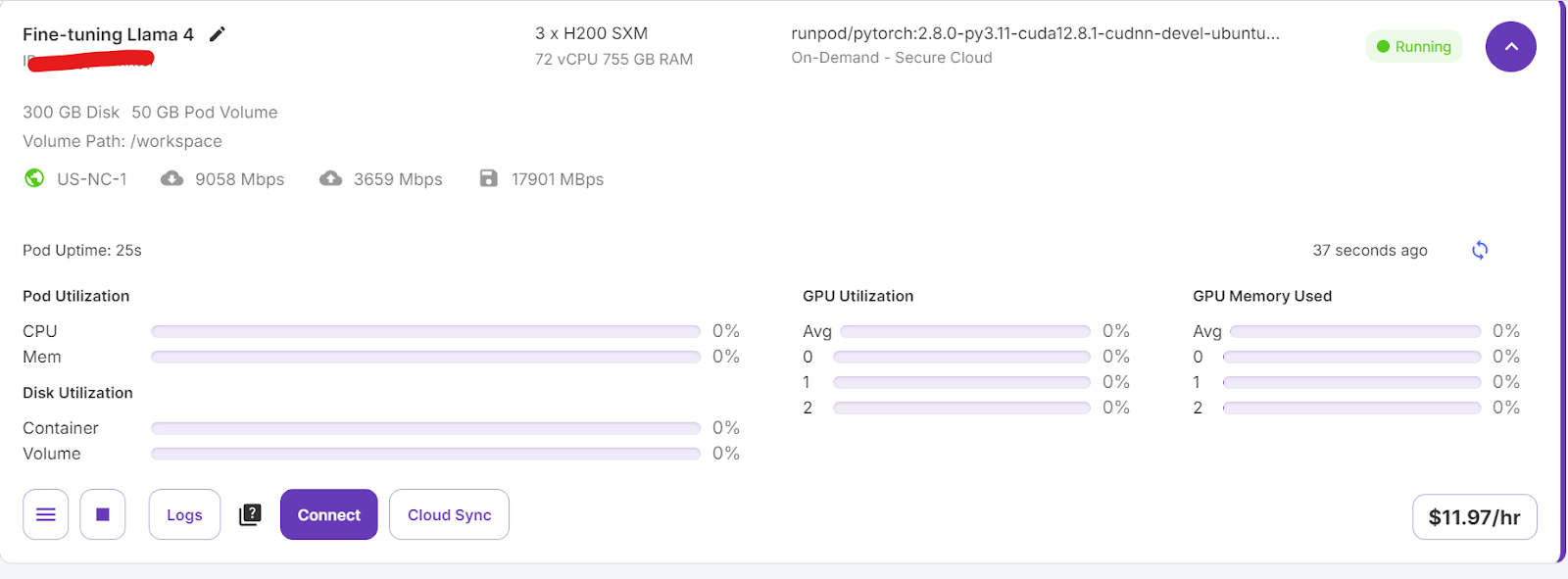
Erstelle ein neues Notebook und beginne mit der Nutzung dieser neuen Umgebung, ähnlich wie bei deiner lokalen Einrichtung.
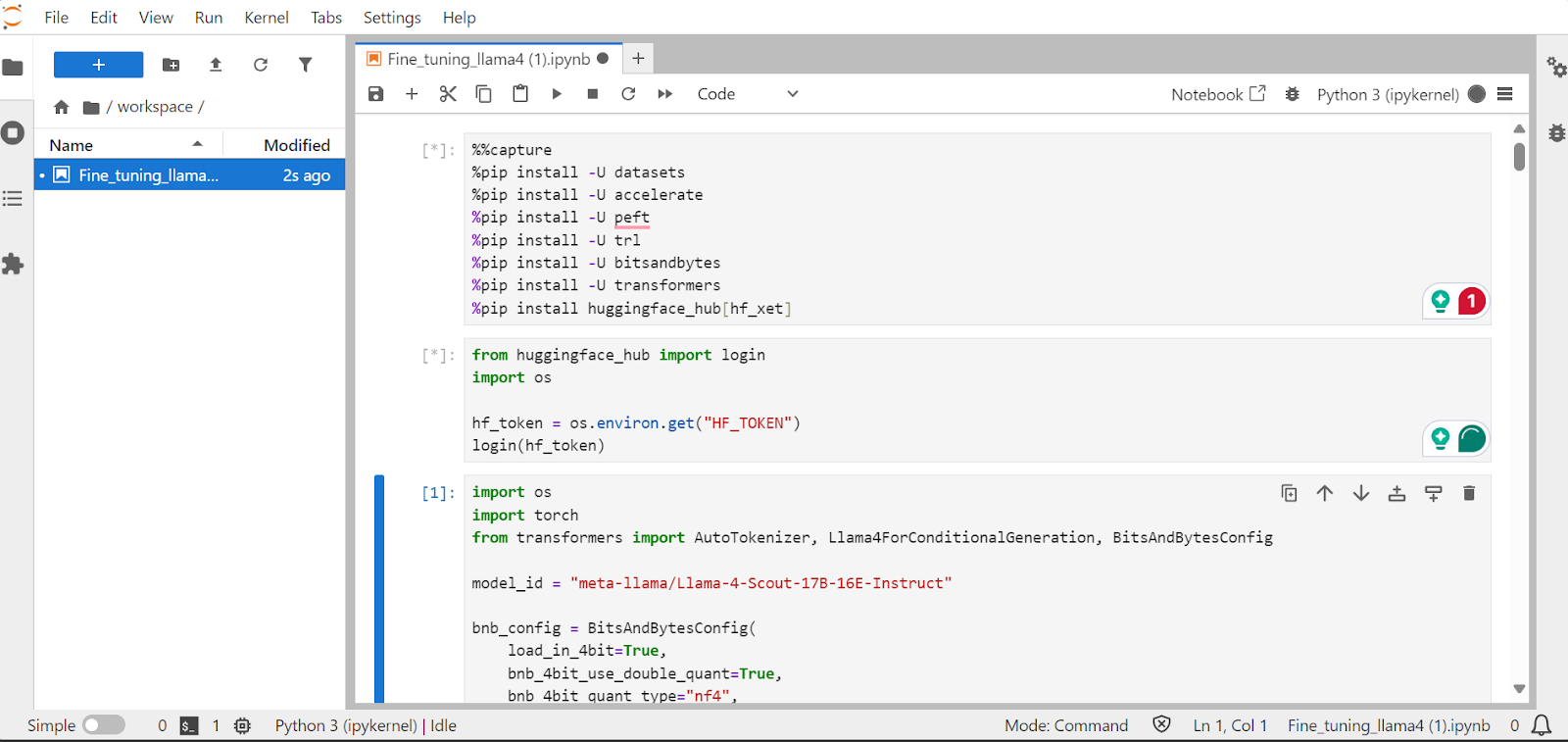
In diesem Abschnitt erfährst du, wie du häufige Probleme beim Feintuning des neuen Llama 4-Modells lösen kannst, z. B. Probleme mit dem Speicherplatz und Bugs in der Transformers-Bibliothek. Wir werden auch erklären, wie du den LoRA-Adapter nahtlos laden, anpassen und speichern kannst. Wenn du diese Schritte befolgst, kannst du dich auf die Feinabstimmung konzentrieren, ohne dich um technische Hürden zu kümmern.
Wir werden die notwendigen Python-Pakete installieren, um die großen Sprachmodelle fein abzustimmen.
Hinweis:
xet Integration, die schneller ist als Git-LFS. Durch diese Integration wird die Downloadgeschwindigkeit um das Dreifache erhöht.%%capture
!pip install transformers==4.51.0
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install huggingface_hub[hf_xet]Laden Sie den API-Schlüssel aus der Umgebungsvariable um sich bei Hugging Face anzumelden. Wenn du dich einloggst, kannst du auf die Gated Models zugreifen und auch fein abgestimmte Modelle und Tokenizer speichern.
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Laden Sie die Llama-4-Scout-17B-16E-Instruct Modell mit 4-Bit-Quantisierung für eine effiziente Speichernutzung. Stelle sicher, dass du device_map auf auto eingestellt hast, um alle drei H200-GPUs zu nutzen.
Hinweis: Vergewissere dich, dass du Zugriff auf das Modell hast, denn dieses Modell ist gesperrt und erfordert, dass du das Formular ausfüllst, indem du auf die Seite meta-llama/Llama-4-Scout-17B-16E-Instruct URL.
import os
import torch
from transformers import AutoTokenizer, Llama4ForConditionalGeneration, BitsAndBytesConfig
model_id = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config,
trust_remote_code=True,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
Wir werden auch den Tokenizer mit der gleichen Modell-ID laden.
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)Wenn du den folgenden Befehl ausführst, kannst du überprüfen, wie viel Speicherplatz für die Einrichtung des Trainers und die Feinabstimmung des Modells übrig ist.
!nvidia-smi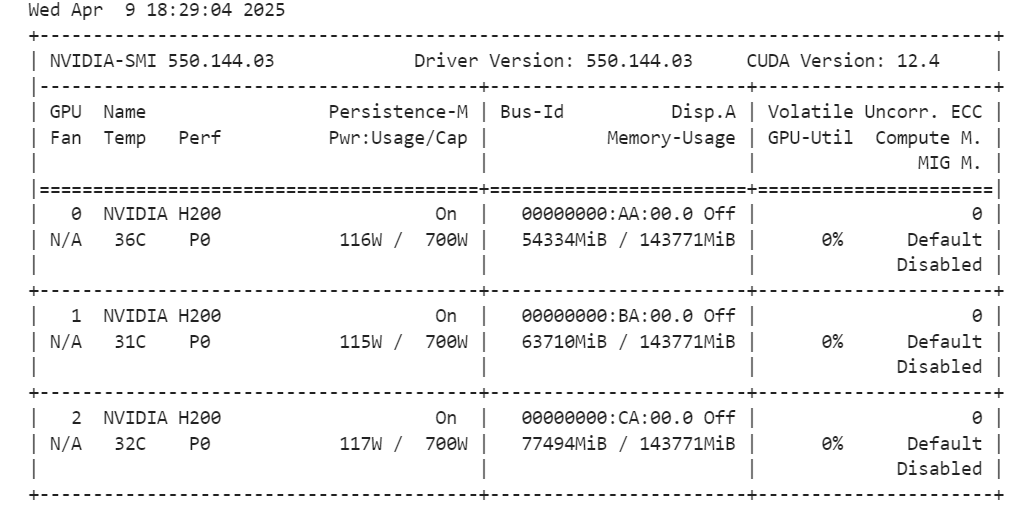
Wir werden einen Prompt-Stil für das Modell erstellen, einschließlich eines Systemprompts mit Platzhaltern für die Frage, Gedankenketteund die Antwort. Diese Aufforderung wird dem Modell helfen, Schritt für Schritt zu denken und klare und genaue Antworten zu geben.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""Als Nächstes erstellen wir die Python-Funktion, um die Spalte “text” mit dem Trainings-Prompt-Stil und den Spalten aus dem Datensatz zu erzeugen.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Wir laden die ersten 500 Proben aus dem FreedomIntelligence/medical-o1-reasoning-SFT die auf dem Hugging Face Hub verfügbar sind, und wenden dann die Funktion formatting_prompts_func an, um die Spalte “text” zu erstellen.
from datasets import load_dataset
dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT","en", split = "train[0:500]",trust_remote_code=True)
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset["text"][0]Die Spalte "Text" enthält eine Systemaufforderung, Anweisungen, eine Frage, eine Gedankenkette und die Antwort.

Der neue STF-Trainer akzeptiert keine Tokenizer, also werden wir den Tokenizer in einen Daten-Collator umwandeln und den Trainer mit dem Daten-Collator anstelle des Tokenizers versorgen.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Wir werden nun einen Test-Prompt-Stil erstellen, der alles aus dem Trainings-Prompt-Stil enthält, außer der Gedankenkette und der Antwort.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""Wir nehmen die erste Frage aus dem Datensatz, wandeln sie in den Prompt um, indem wir den Stil des Test-Prompts verwenden, und bereiten sie dann für das Modell vor, um die Antwort zu generieren.
question = dataset[0]['Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Die Gedankenkette des Modells ist lang, und die Antwort, die es gibt, ist recht kurz und unterscheidet sich erheblich vom Datensatz.
<think>assistant
To approach this question, let's break down the key elements provided and analyze them step by step:
1. **Symptoms**: The patient experiences involuntary urine loss during activities like coughing or sneezing but has no leakage at night. This pattern of urinary incontinence is suggestive of stress urinary incontinence (SUI), which is characterized by the involuntary leakage of urine on effort or exertion, or on sneezing or coughing.
2. **Diagnostic Tests Mentioned**:
- **Gynecological Exam**: This is likely performed to assess the pelvic anatomy, including the position and support of the urethra and bladder neck, and to check for any pelvic organ prolapse.
- **Q-tip Test**: This test is used to assess urethral mobility. A Q-tip (cotton swab) is inserted into the urethra, and its angle of movement is measured. Increased mobility (an angle change of more than 30 degrees) is often associated with stress urinary incontinence.
3. **Cystometry (Cystometrogram)**: This test measures the pressure within the bladder during filling and helps assess bladder function, including the residual volume and detrusor muscle contractions. The detrusor muscle is the smooth muscle in the wall of the bladder that contracts to allow urine to be expelled.
Given that the patient likely has stress urinary incontinence (SUI) based on her symptoms:
- **Residual Volume**: In patients with SUI, the bladder usually functions normally, and thus, the residual volume (the amount of urine left in the bladder after urination) is typically not significantly affected. Therefore, one would expect the residual volume to be normal or near-normal.
- **Detrusor Contractions**: In SUI, the problem primarily lies with the urethral sphincter mechanism and support rather than with the detrusor muscle itself. Hence, detrusor contractions are usually normal. The patient does not have symptoms suggestive of an overactive bladder (like urgency, urge incontinence, or nocturia), which would be more indicative of detrusor overactivity.
Based on this analysis, cystometry in this patient would most likely reveal:
- A **normal residual volume**, as her symptoms do not suggest a problem with bladder emptying.
- **Normal detrusor contractions**, as her condition (stress urinary incontinence) primarily involves issues with urethral support and continence mechanisms rather than detrusor function.
Therefore, cystometry would likely show that she has a normal residual volume and normal detrusor contractions.
</think>
The final answer is: $\boxed{Normal residual volume and normal detrusor contractions}$Wir werden nun LoRA (Low-Rank Adaptation) zur parameter-effizienten Feinabstimmung implementieren und auf das Modell anwenden. LoRA ist eine Technik zur Feinabstimmung großer Sprachmodelle, bei der die meisten Parameter des Modells eingefroren werden und nur eine kleine Teilmenge zusätzlicher Parameter trainiert wird.
Dieser Ansatz ist speichereffizient, schneller und kostengünstiger und bietet dennoch eine hohe Genauigkeit, die mit einer vollständigen Feinabstimmung vergleichbar ist.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Jetzt konfigurieren und initialisieren wir den SFTTrainer (Supervised Fine-Tuning Trainer), indem wir ihn mit dem Datensatz, dem Modell, dem Datensammler, den Trainingsargumenten und der LoRA-Konfiguration versorgen. Der SFTTrainer vereinfacht den Feinabstimmungsprozess, indem er all diese Komponenten in einen einzigen, rationalisierten Arbeitsablauf integriert und so das Training großer Sprachmodelle wie Llama 4 mit LoRA erleichtert.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Beginne den Trainingsprozess, indem du den folgenden Befehl ausführst:
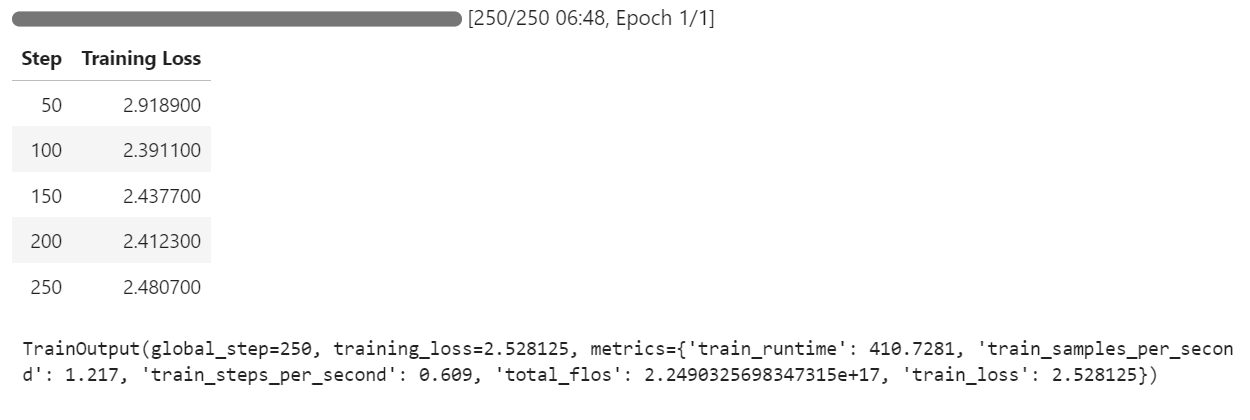
trainer.train()Wenn du zu deinem Pod-Dashboard wechselst, siehst du, dass der Trainer alle drei GPUs für das Training nutzt.
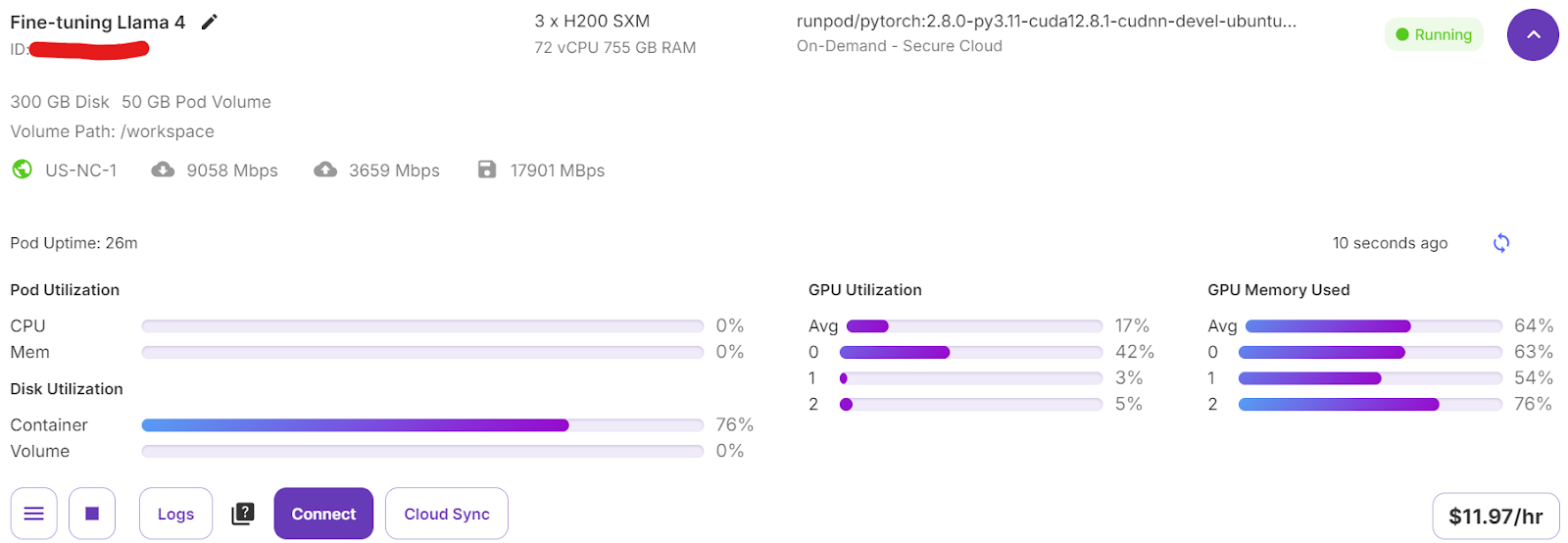
Wir haben nur 7 Minuten für die Feinabstimmung des Modells gebraucht und insgesamt 30 Minuten, um das ganze Projekt von Anfang bis Ende durchzuführen.
Wir werden nun das fein abgestimmte Modell mit der gleichen Stichprobe wie zuvor testen, um seine Leistung nach der Feinabstimmung zu vergleichen. So können wir beurteilen, wie gut sich das Modell bei der Argumentation und der Erstellung detaillierter Antworten verbessert hat.
question = dataset[0]['Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Der Denkprozess des Modells ist genau, und die Antwort ist detailliert und logisch:
<think>
Alright, let's think about what's going on with this 61-year-old woman. She's experiencing involuntary urine loss when she coughs or sneezes, which is classic for stress urinary incontinence. But there's no leakage at night, which is interesting. That detail might help us rule out other types of incontinence, like overactive bladder.
Now, let's think about the tests she's had. The gynecological exam and the Q-tip test are usually done to check for any anatomical issues that could be causing her symptoms. If the Q-tip test is positive, it means there's some mobility in the urethra, which can be a sign of stress incontinence.
Okay, so we've got stress urinary incontinence in mind. What does cystometry tell us? It's a test that looks at how well the bladder functions by measuring pressure and volume during filling and voiding.
For someone with stress incontinence, the cystometry would probably show that her bladder is doing its job properly. The residual volume, which is the amount of urine left in the bladder after she pees, should be normal. This means her bladder is emptying well enough.
Also, with stress incontinence, you wouldn't expect to see abnormal detrusor contractions. These are like muscle spasms in the bladder that can cause urgency and urge incontinence. But in stress incontinence, the problem is more about the urethral support and pressure control during activities, not the bladder muscle itself.
So, putting it all together, the cystometry should show a normal residual volume and no abnormal detrusor contractions. This fits perfectly with what we know about stress urinary incontinence. Yep, that's what I'd expect to see in this case.
</think>
In this scenario, the cystometry would most likely reveal a normal residual volume and no abnormal detrusor contractions. This is because stress urinary incontinence, as indicated by the patient's symptoms and the positive Q-tip test, is primarily related to issues with urethral support and pressure control during activities, not with the bladder muscle's function or emptying ability.Testen wir das Modell an einer anderen Stichprobe aus dem Datensatz, um seine Leistung weiter zu bewerten.
question = dataset[10]['Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Die Antwort ist logisch, detailliert und zeigt, dass das Modell in der Lage ist, medizinische Argumente effektiv anzuwenden:
<think>
Alright, let's break this down. So, we have a 42-year-old guy who's just recovered from pneumonia, and his T3 levels are low. Now, his TSH is slightly elevated at 4.7 µU/mL, which isn't too high but is definitely not normal. T4 is at 6 µg/dL, which is kind of in the middle range, and T3 is 68 ng/dL, which is low. Hmm, these numbers make me think of a condition called sick euthyroid syndrome. It's like when the body gets sick, the thyroid function tests can get all wonky, even if the thyroid itself is working fine.
In this syndrome, T3 usually drops first, and T4 might stay normal or even rise a bit. This makes sense here because his T3 is low, but T4 is still around 6 µg/dL. Now, the TSH is slightly elevated, which is a bit puzzling, but in sick euthyroid syndrome, TSH can be normal or even slightly elevated. So, this fits.
But wait, what about the other hormones? In sick euthyroid syndrome, we often see an increase in reverse T3 (rT3). This is because the body might convert T4 to rT3 instead of T3 when it's stressed. So, if I were to guess, I'd say the reverse T3 level is probably elevated in this case.
This all makes sense because the clinical picture and lab results are lining up nicely with sick euthyroid syndrome. So, if I had to pick an additional hormone that's likely elevated, it would be the reverse T3. Yeah, that seems to fit the scenario perfectly.
</think>
In this scenario, considering the clinical context of a 42-year-old man recovering from pneumonia with decreased T3 levels and slightly elevated TSH, along with normal T4 levels, the likely condition is sick euthyroid syndrome. In this condition, the body often converts T4 to reverse T3 (rT3) instead of T3 during stress or illness. Therefore, the additional hormone level that is likely to be elevated in this patient is reverse T3 (rT3).Wir werden nun das feinabgestimmte Modell (LoRA-Adapter) und den Tokenizer an den Hugging Face Hub senden. Dieser Prozess erstellt automatisch ein Repository für dich und lädt alle notwendigen Modelldateien hoch, so dass das Modell für die weitere Nutzung oder Weitergabe öffentlich zugänglich ist.
model.push_to_hub("Llama-4-Scout-17B-16E-Instruct-Medical-ChatBot")
tokenizer.push_to_hub("Llama-4-Scout-17B-16E-Instruct-Medical-ChatBot")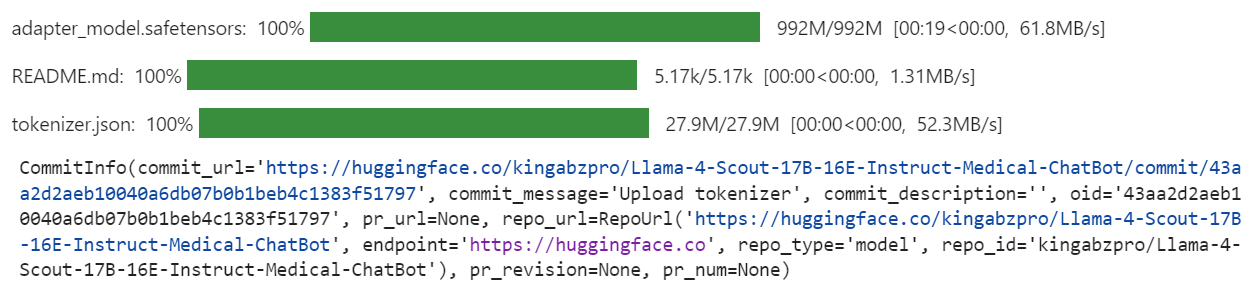
Sobald der Prozess abgeschlossen ist, kannst du unter folgendem Link auf das Modell-Repository zugreifen: kingabzpro/Llama-4-Scout-17B-16E-Instruct-Medical-ChatBot
Hier ist das Begleitheft das alle notwendigen Codes, Ausgaben und detaillierten Anweisungen enthält, um dir bei der Feinabstimmung deines eigenen Llama 4-Modells zu helfen.
Die Erstellung dieses Tutorials war eine herausfordernde, aber lohnende Erfahrung. Bei der Arbeit mit Llama 4 stieß ich auf mehrere Probleme, die die Komplexität dieses Modells verdeutlichten. Meiner Meinung nach ist Llama 4 noch nicht vollständig für den breiten Einsatz optimiert, insbesondere für Einzelpersonen, die auf Consumer-GPUs angewiesen sind. Hier sind einige der wichtigsten Herausforderungen, mit denen ich konfrontiert war:
Trotz dieser Herausforderungen solltest du, wenn du diese Anleitung Schritt für Schritt befolgst, in der Lage sein, Llama 4 relativ einfach auf jeden neuen Datensatz abzustimmen.
Um mehr über Llama 4 zu erfahren, schau dir diese Ressourcen an:
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
