
programa
Fundamentos del negocio de la IA
12 h
Los grandes modelos lingüísticos (LLM) son muy potentes, pero a menudo tienen dificultades para seguir la pista a las grandes ideas. Esto se debe a que los LLM funcionan prediciendo el texto de un token, o palabra, cada vez.
Este enfoque ficha a ficha, combinado con una ventana de contexto limitada, puede dar lugar a respuestas inconexas, pérdida de contexto y muchas repeticiones. Es como intentar escribir una redacción adivinando cada palabra siguiente en lugar de esbozar primero tus pensamientos.
Aquí es donde los modelos de grandes conceptos (MGC ) pueden resultar útiles. En lugar de trabajar palabra por palabra, los LCM procesan el lenguaje a nivel de frase y lo abstraen en conceptos. Esta abstracción permite al modelo comprender el lenguaje de una forma más reflexiva y significativa.
Un modelo de grandes conceptos (MGC) es un tipo de modelo lingüístico que procesa el lenguaje a nivel de concepto en lugar de analizar palabras individuales. A diferencia de los modelos tradicionales, que descomponen el texto palabra por palabra, los LCM interpretan representaciones semánticas, que corresponden a frases enteras o ideas cohesionadas. Este cambio les permite captar el significado más amplio del lenguaje en lugar de sólo la mecánica.

Imagina que lees una novela. Un LLM lo procesaría token a token, centrándose en las palabras individuales y sus vecinas inmediatas. Con este enfoque, podría generar un resumen prediciendo la palabra siguiente más probable. Pero puede pasar por alto la narrativa más amplia y los temas subyacentes.
Los LCM, sin embargo, analizan secciones más grandes de texto para extraer las ideas subyacentes. Este enfoque les ayuda a comprender los conceptos más amplios: el arco argumental general, el desarrollo de los personajes y los temas. Este enfoque no sólo puede ayudarles a generar un resumen más completo, sino que puede ayudarles a ampliar la historia de una forma más significativa.
Esta capacidad de pensar en conceptos más que en palabras hace que los MCL sean increíblemente flexibles. Se construyen sobre el espacio de incrustación SONARque les permite procesar texto en más de 200 idiomas y voz en 76.
En lugar de basarse en patrones específicos de la lengua, los MCL almacenan el significado a nivel conceptual. Esta abstracción los hace adaptables a tareas como el resumen multilingüe, la traducción y la generación de contenidos multiformato.
Como los LCM procesan el lenguaje a nivel conceptual, generan resultados estructurados y conscientes del contexto. A diferencia de los LLM, que construyen el texto palabra por palabra, los LCM utilizan representaciones numéricas de frases enteras para mantener el flujo lógico. Esto los hace especialmente eficaces para tareas como la redacción de informes o la traducción de documentos extensos.
También tienen un diseño modular, que permite a los desarrolladores integrar nuevos lenguajes o modalidades sin tener que volver a entrenar todo el sistema.
Los LLM y los LCM comparten muchos de los mismos objetivos: ambos generan texto, resumen información y traducen entre idiomas. Pero la forma en que realizan estas tareas es fundamentalmente diferente.
Los LLM predicen el texto de un token cada vez, lo que les permite producir frases fluidas. Sin embargo, esto suele dar lugar a incoherencias o redundancias en los resultados más largos. Los LCM, en cambio, procesan el lenguaje a nivel de frase, lo que les permite mantener la fluidez lógica en pasajes extensos.
Otra distinción es cómo gestionan el tratamiento multilingüe. Los LLM se basan en gran medida en datos de entrenamiento de lenguas con muchos recursos, o lenguas que tienen mucho contenido de entrenamiento, como el inglés. Como resultado, a menudo tienen dificultades con las lenguas de pocos recursos que carecen de grandes conjuntos de datos.
Sin embargo, los LCM operan en el espacio de incrustación SONAR. Este espacio de incrustación les permite procesar textos en muchas lenguas sin necesidad de reentrenamiento. Trabajar con conceptos abstractos los hace mucho más adaptables.
|
Capacidad |
Cómo funcionan los LLM |
Cómo lo mejoran los LCM |
|
Flexibilidad multilingüe y multiformato |
Formado sobre todo en lenguas de alto nivel y con dificultades con las menos comunes. Necesita formación adicional para diferentes formatos como el habla. |
Funciona en más de 200 idiomas y admite texto y voz, sin formación adicional. |
|
Generalizar a nuevas tareas |
Necesita ajustes para tratar nuevas lenguas o temas. Lucha con datos desconocidos. |
Utiliza un sistema independiente del idioma, lo que le permite manejar nuevos idiomas y tareas sin formación adicional. |
|
Coherencia en los contenidos de formato largo |
Escribe palabra por palabra, dando respuestas largas propensas a la incoherencia o la repetición. |
Procesa frases completas de una vez, manteniendo las respuestas más claras y estructuradas que un texto largo. |
|
Eficacia en el manejo del contexto |
Tiene dificultades con las entradas más largas debido al aumento de las necesidades de memoria y procesamiento. |
Utiliza representaciones de frases compactas, lo que facilita el procesamiento eficaz de documentos largos. |
Los grandes modelos conceptuales consiguen sus capacidades únicas mediante un sistema de tres partes:
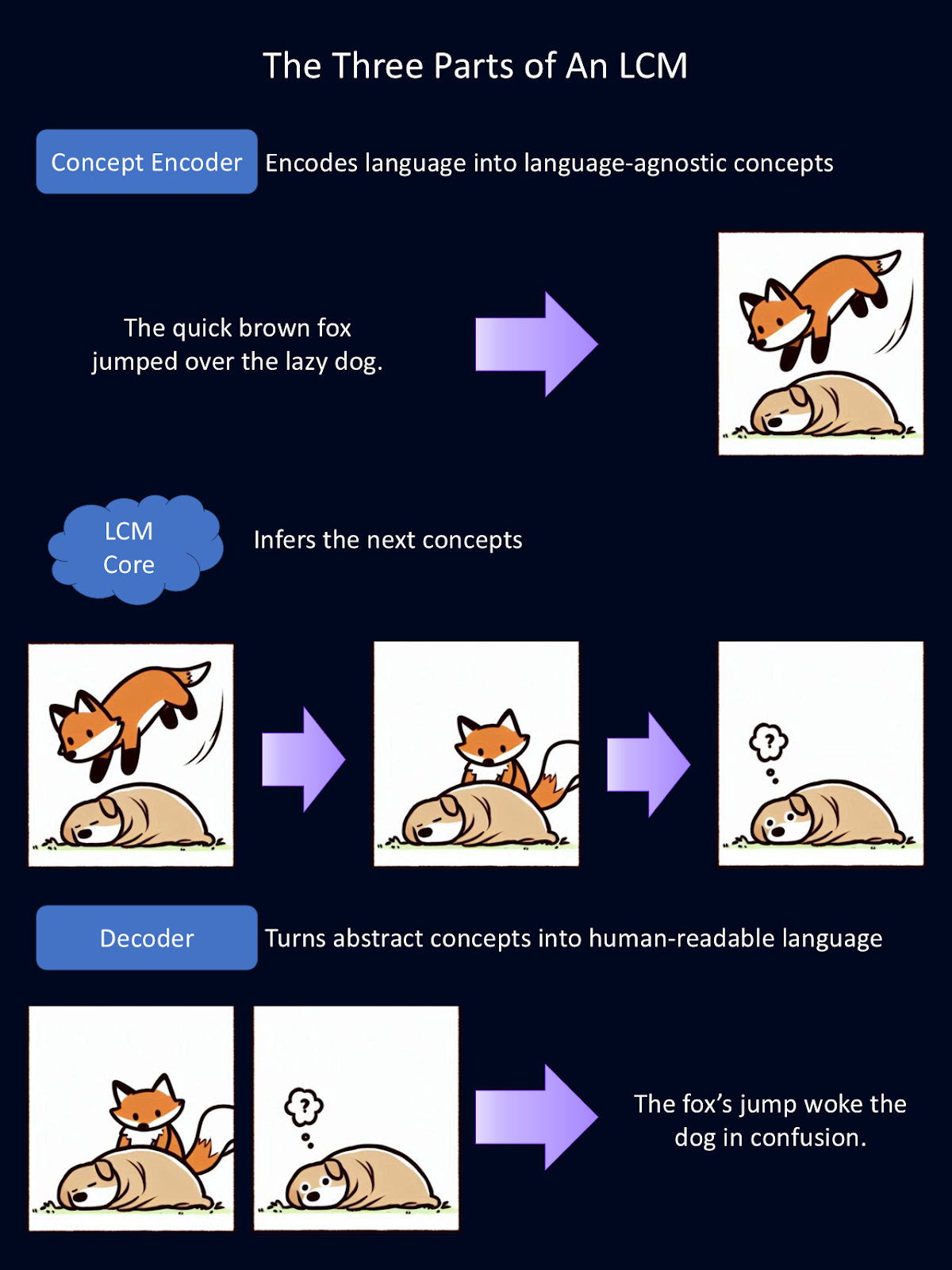
El diagrama anterior es una explicación simplificada del funcionamiento de cada uno de los tres componentes modulares de un LCM. El codificador convierte el lenguaje en conceptos abstractos. Aquí, estos conceptos abstractos se representan como imágenes. En el modelo, estos conceptos se representan matemáticamente. El núcleo realiza inferencias sobre esos conceptos. Luego, el descodificador convierte esas abstracciones en lenguaje legible por humanos. Para esta figura, Copilot proporcionó el primer borrador de los dibujos de los animales.
El primer paso en la cadena de procesamiento de un LCM es codificar la entrada en una representación semántica de alta dimensión. Esencialmente, esto convierte el lenguaje en representaciones matemáticas de conceptos. Este codificador de conceptos mapea grandes segmentos de texto, como frases enteras.
Los LCM utilizan SONAR, un potente espacio de incrustación para el lenguaje. Es este espacio de incrustación el que admite diferentes idiomas para el texto y la voz. SONAR permite al codificador procesar tanto el lenguaje escrito como el hablado, destilando los conceptos en algo que el modelo pueda entender.
Una vez codificados los conceptos, el núcleo LCM los procesa para generar otros nuevos basados en el contexto. Aquí es donde se produce la inferencia. A diferencia de los LLM, que predicen el texto token a token, el núcleo LCM predice frases o conceptos enteros.
Hay tres tipos de núcleos LCM, cada uno con un enfoque distinto de los conceptos de modelado:
Entre ellos, los MCL basados en la difusión han demostrado el mejor poder predictivo, generando los resultados más precisos y coherentes contextualmente.
Una vez que el Núcleo LCM ha procesado y predicho los nuevos conceptos, hay que volver a convertirlos en forma legible para el ser humano. Éste es el trabajo del descodificador de conceptos. Traduce las representaciones matemáticas de los conceptos en salidas de texto o voz.
Como los conceptos subyacentes se almacenan en un espacio de incrustación compartido, pueden descodificarse en cualquier lenguaje compatible sin necesidad de reprocesarlos. Esto es increíblemente potente porque significa que los resultados son independientes del idioma. Todo el "pensamiento" ocurre con las matemáticas. Así, un LCM entrenado principalmente en inglés y español podría leer entradas en alemán, "pensar" en matemáticas y generar contenidos en japonés.
Esto significa también que nuevos lenguajes y modalidades sin necesidad de volver a entrenar todo el modelo. Si se desarrolla un nuevo sistema de voz a texto, puede integrarse en un LCM existente sin necesidad de recursos informáticos masivos.
Imagina que alguien hiciera un codificador y descodificador para el lenguaje de signos. Podrían añadirlo a un núcleo LCM existente, sin necesidad de volver a formarse, y comunicar las ideas en un formato totalmente distinto. Esta flexibilidad hace de los LCM una solución escalable y adaptable para aplicaciones de IA multilingües y multiformato.
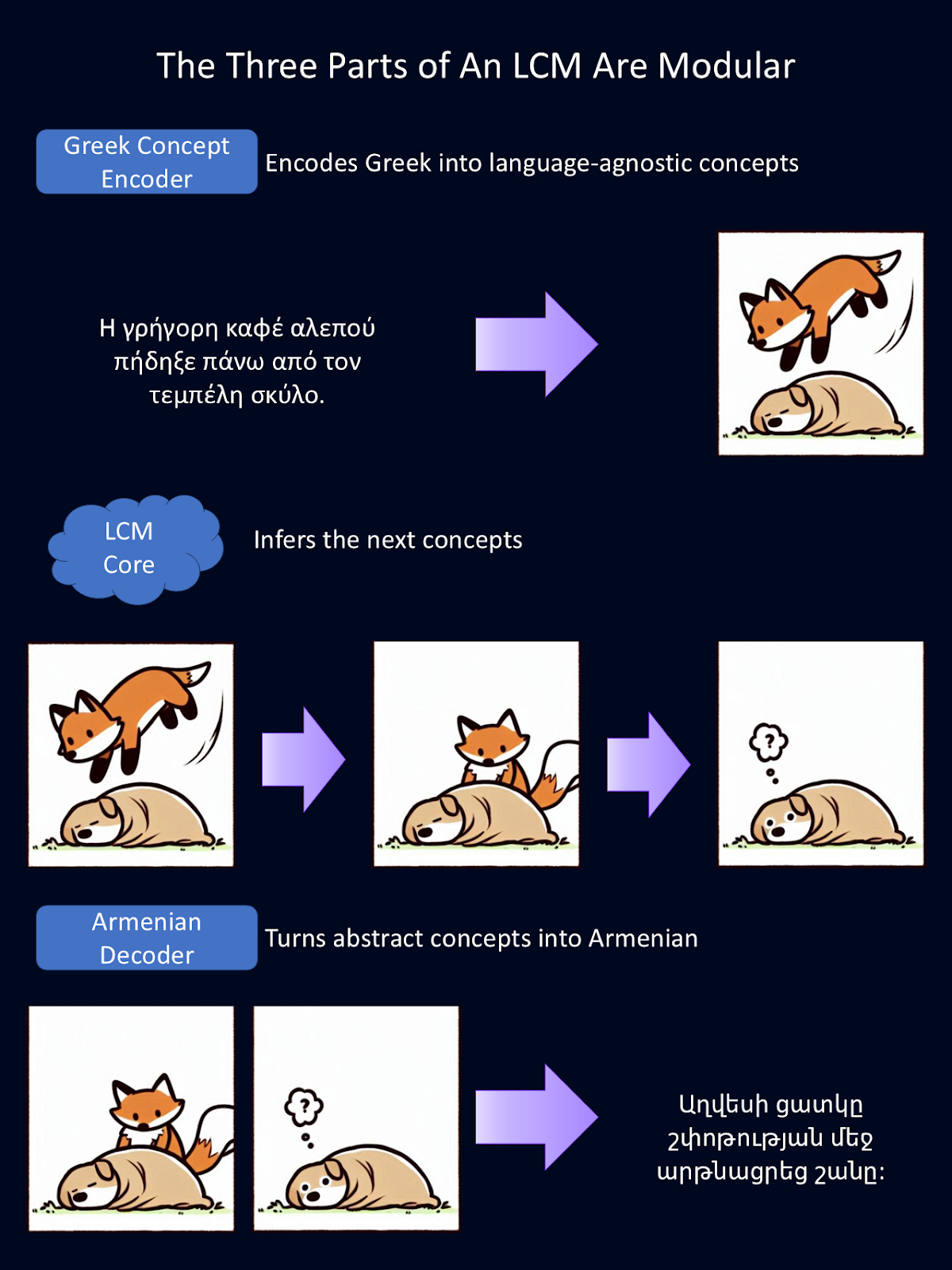
Como cada parte del LCM es modular, cada una de ellas puede intercambiarse independientemente. En el diagrama anterior, hemos sustituido el codificador y decodificador de lengua inglesa anteriores por un codificador de lengua griega y un decodificador de lengua armenia.
Estos codificadores y descodificadores también pueden cambiarse por otros que manejen distintas modalidades de lenguaje, como el habla verbal en lugar del texto. Para esta figura, Google Translate proporcionó las traducciones del inglés, y Copilot proporcionó el primer borrador de los dibujos de los animales.
Las aplicaciones de los LCM se solapan con las de los LLM, pero debido a que se centran en los conceptos y en una comprensión más profunda, tienen el potencial de crear un impacto más profundo en las industrias que requieren un pensamiento más profundo.
Los LCM simplifican la traducción y mejoran la comprensión interlingüística al operar en un espacio de incrustación agnóstico de la lengua. Esto las hace especialmente eficaces para tareas como el resumen multilingüe o la traducción de documentos complejos.
Por ejemplo, un LCM puede procesar un documento jurídico complejo en una lengua y generar un resumen coherente en otra. Esta capacidad tiene un valor incalculable para las organizaciones globales, la comunicación internacional y las traducciones en lenguas de escasos recursos.
Los LCM destacan en la producción de resultados coherentes y contextualmente relevantes, lo que los convierte en la opción ideal para tareas como la redacción de informes, la redacción de artículos y la creación de resúmenes. Al mantener la coherencia lógica en los contenidos de formato largo, los LCM pueden producir resultados que requieren bastante menos edición que los LLM, lo que ahorra tiempo y esfuerzo a los profesionales del periodismo, el marketing y la investigación.
Creo que la aplicabilidad de los LCM a la educación es lo más impresionante. Imagina un sistema de tutoría inteligente impulsado por un LCM que pueda generar contenidos explicativos e interactivos adaptados a cada alumno.
Un tutor LCM podría resumir un tema complejo en segmentos más sencillos y conceptualmente digeribles para estudiantes con distintos niveles de experiencia. Su adaptabilidad a las distintas lenguas podría permitir a un profesor enseñar a sus alumnos cientos de lenguas a la vez.
Los LCM también son adecuados para ayudar en la investigación y la escritura creativa. Pueden redactar escritos estructurados y coherentes, como ensayos, trabajos de investigación o narraciones de ficción, proporcionando borradores iniciales que los escritores pueden perfeccionar.
Los investigadores también pueden utilizar LCM para organizar ideas, ampliar resúmenes o incluso generar hipótesis basadas en datos existentes. Resuelven muchos de los problemas que los investigadores encuentran frustrantes en los LLM actuales.
Estoy seguro de que no soy el único que ha tenido la frustrante experiencia de interactuar con uno de estos nuevos robots de atención al cliente con tecnología LLM, sólo para que no entendiera mi problema. Con los LCM impulsándolos, los chatbots de atención al cliente pueden ofrecer una mejor comprensión de situaciones complejas y quizá incluso soluciones más creativas. Esto puede mejorar la satisfacción y retención de los clientes.
En la actualidad, los LLM se utilizan en varias de estas funciones, pero su eficacia es limitada. Los LCM tienen potencial para elevar el nivel de estas aplicaciones. Pronto, nuestros asistentes de IA podrían parecerse más a tener verdaderos asistentes humanos, capaces de seguir ideas y conversaciones más complejas, sólo que pueden comunicarse mucho más rápido que nosotros.
Aunque los MCL ofrecen posibilidades apasionantes, también plantean retos en cuanto a requisitos de datos, complejidad y costes computacionales. Repasemos algunos de los mayores retos actuales.
Entrenar cualquier modelo de IA requiere grandes cantidades de datos, pero los LCM tienen pasos de procesamiento adicionales en comparación con los LLM. En lugar de utilizar texto en bruto, se basan en representaciones a nivel de frase, lo que significa que primero hay que dividir el texto en frases y luego convertirlas en incrustaciones. Esto añade una capa de preprocesamiento y exigencias de almacenamiento.
Además, el entrenamiento con cientos de miles de millones de frases requiere una inmensa potencia de cálculo.
Los LCM procesan frases enteras como unidades únicas, lo que ayuda a mantener el flujo lógico, pero dificulta la resolución de problemas.
Los LLM generan el texto palabra a palabra, lo que nos permite rastrear los errores hasta las palabras individuales. En cambio, los LCM operan en un espacio de incrustación de alta dimensión, donde las decisiones se basan en relaciones abstractas.
Los LCM, especialmente los modelos basados en la difusión, requieren mucha más potencia de procesamiento que los LLM. Mientras que los LLM generan texto en una sola pasada hacia delante, los LCM basados en la difusión refinan sus resultados paso a paso, lo que aumenta tanto el tiempo de cálculo como el coste. Aunque los LCM pueden ser más eficientes para los documentos largos, suelen ser menos eficientes para las tareas de formato corto, como las respuestas rápidas o las interacciones basadas en el chat.
Definir los conceptos a nivel de frase crea sus propios retos. Las frases más largas pueden contener varias ideas, lo que dificulta captarlas como una sola unidad. Y las frases más cortas podrían no proporcionar suficiente contexto para una representación significativa.
Los LCM también se enfrentan a problemas de escasez de datos. Como las frases individuales son mucho más únicas que las palabras, el modelo tiene menos patrones repetidos de los que aprender.
Esta tecnología se está desarrollando rápidamente y estos retos se están abordando activamente. Como esta tecnología es de código abierto, puedes añadir tus propias soluciones para ayudar a afrontar estos retos y hacer avanzar esta tecnología.
¿Te interesa probar a trabajar con un LCM? Gran parte del código es de código abierto, ¡así que puedes hacerlo!
Un buen punto de partida es el código de entrenamiento LCM y el espacio de incrustación SONAR. Estas herramientas de código abierto permiten a los desarrolladores experimentar con esta nueva tecnología e introducir sus propias mejoras.
Para saber más sobre la teoría de los MCL, consulta este artículo de Meta.
La capacidad de los MCL para operar a nivel conceptual tiene el potencial de refinar las interacciones de la IA con el lenguaje. Al ir más allá de las limitaciones del análisis basado en tokens, los LCM abren el camino a aplicaciones más matizadas, conscientes del contexto y multilingües.
Te animo a que compruebes el código por ti mismo y añadas tu propio toque. ¿Qué mejoras puedes introducir en esta tecnología? ¿Qué productos puedes crear con él?
Aprende IA con estos cursos
programa
programa
programa
blog
Stanislav Karzhev
9 min
blog
Natassha Selvaraj
15 min
blog
Bhavishya Pandit
8 min
blog
Abid Ali Awan
11 min
Tutorial
Josep Ferrer
Tutorial
Kurtis Pykes

