
Track
AI Business Fundamentals
12 hr
Large language models (LLMs) are very powerful, but they often struggle with keeping track of big-picture ideas. That’s because LLMs work by predicting text one token, or word, at a time.
This token-by-token approach, combined with a limited context window, can lead to disjointed responses, lost context, and lots of repetition. It’s like trying to write an essay by guessing each next word instead of outlining your thoughts first.
This is where large concept models (LCMs) might prove useful. Instead of working word by word, LCMs process language at the sentence level and abstract language into concepts. This abstraction allows the model to understand language in a more thoughtful and meaningful way.
A large concept model (LCM) is a type of language model that processes language at the concept level rather than analyzing individual words. Unlike traditional models that break down text word by word, LCMs interpret semantic representations, which correspond to entire sentences or cohesive ideas. This shift allows them to grasp the broader meaning of language rather than just the mechanics.

Imagine reading a novel. An LLM would process it token by token, focusing on individual words and their immediate neighbors. With this approach, it could generate a summary by predicting the most likely next word. But it may miss the broader narrative and underlying themes.
LCMs, however, analyze larger sections of text to extract the underlying ideas. This approach helps them understand the broader concepts: overall story arc, character development, and themes. This approach can not only help them generate a more complete summary, but it can help them expand on the story in a more meaningful way.
This ability to think in concepts rather than words makes LCMs incredibly flexible. They are built on the SONAR embedding space, which allows them to process text in over 200 languages and speech in 76.
Instead of relying on language-specific patterns, LCMs store meaning at a conceptual level. This abstraction makes them adaptable for tasks like multilingual summarization, translation, and cross-format content generation.
Because LCMs process language at the conceptual level, they generate structured, contextually aware outputs. Unlike LLMs, which build text word by word, LCMs use numerical representations of entire sentences to maintain logical flow. This makes them especially effective for tasks like drafting reports or translating lengthy documents.
They also have a modular design, which allows developers to integrate new languages or modalities without retraining the entire system.
LLMs and LCMs share many of the same goals: both generate text, summarize information, and translate between languages. But the way they achieve these tasks is fundamentally different.
LLMs predict text one token at a time, which makes them great at producing fluent sentences. However, this often leads to inconsistencies or redundancies in longer outputs. LCMs, on the other hand, process language at the sentence level, allowing them to maintain logical flow across extended passages.
Another distinction is how they handle multilingual processing. LLMs rely heavily on training data from high-resource languages, or languages that have a lot of training content, like English. As a result, they often struggle with low-resource languages that lack large datasets.
LCMs, however, operate in the SONAR embedding space. This embedding space allows them to process text in many languages without retraining. Working with abstract concepts makes them far more adaptable.
|
Capability |
How LLMs work |
How LCMs improve it |
|
Multilingual and multiformat flexibility |
Trained mostly on high-resource languages and struggle with less common ones. Needs extra training for different formats like speech. |
Works in 200+ languages and supports text and speech, without extra training. |
|
Generalizing to new tasks |
Needs fine-tuning to handle new languages or topics. Struggles with unfamiliar data. |
Uses a language-independent system, allowing it to handle new languages and tasks without extra training. |
|
Coherence in long-form content |
Writes word by word, making long responses prone to inconsistency or repetition. |
Processes full sentences at once, keeping responses clearer and more structured over long text. |
|
Efficiency in handling context |
Struggles with longer inputs due to rising memory and processing needs. |
Uses compact sentence representations, making it easier to process long documents efficiently. |
Large concept models achieve their unique capabilities through a three-part system:
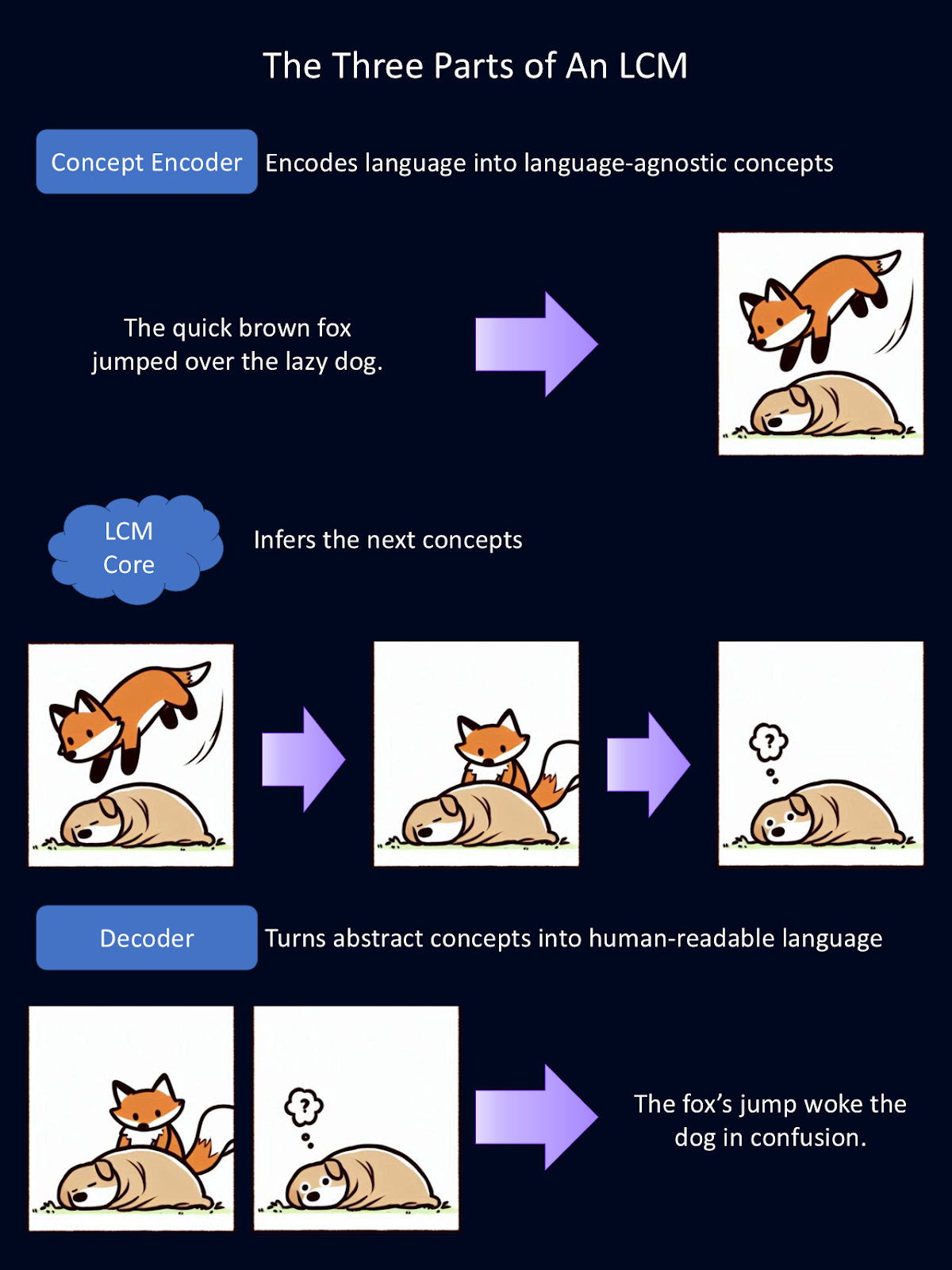
The above diagram is a simplified explanation of how each of the three modular components of an LCM works. The encoder turns language into abstract concepts. Here, these abstract concepts are represented as images. In the model, these concepts are represented mathematically. The core runs inference on those concepts. Then the decoder turns those abstractions into human-readable language. For this figure, Copilot provided the first draft of the animal drawings.
The first step in an LCM’s processing pipeline is to encode input into a high-dimensional semantic representation. Essentially, this turns language into mathematical representations of concepts. This concept encoder maps large segments of text, like entire sentences.
LCMs use SONAR, a powerful embedding space for language. It’s this embedding space that supports different languages for text and speech. SONAR allows the encoder to process both written and spoken language, distilling the concepts into something the model can understand.
Once concepts are encoded, the LCM core processes them to generate new ones based on context. This is where inference happens. Unlike LLMs, which predict text token by token, the LCM core predicts entire sentences or concepts.
There are three types of LCM cores, each with a distinct approach to modeling concepts:
Among these, diffusion-based LCMs have demonstrated the best predictive power, generating the most accurate and contextually coherent outputs.
Once the LCM Core has processed and predicted new concepts, they must be converted back into human-readable form. This is the job of the concept decoder. It translates the mathematical representations of concepts into text or speech outputs.
Because the underlying concepts are stored in a shared embedding space, they can be decoded into any supported language without reprocessing. This is incredibly powerful because it means the outputs are language-agnostic. All of the “thinking” happens with math. So, an LCM trained primarily on English and Spanish could read input in German, “think” in math, and generate content in Japanese.
This also means that new languages and modalities can be added without retraining the entire model. If a new speech-to-text system is developed, it can be integrated with an existing LCM without requiring massive computational resources.
Imagine if someone made an encoder and decoder for sign language. They could add it to an existing LCM core, without retraining, and communicate ideas in an entirely different format. This flexibility makes LCMs a scalable and adaptable solution for multilingual and multiformat AI applications.
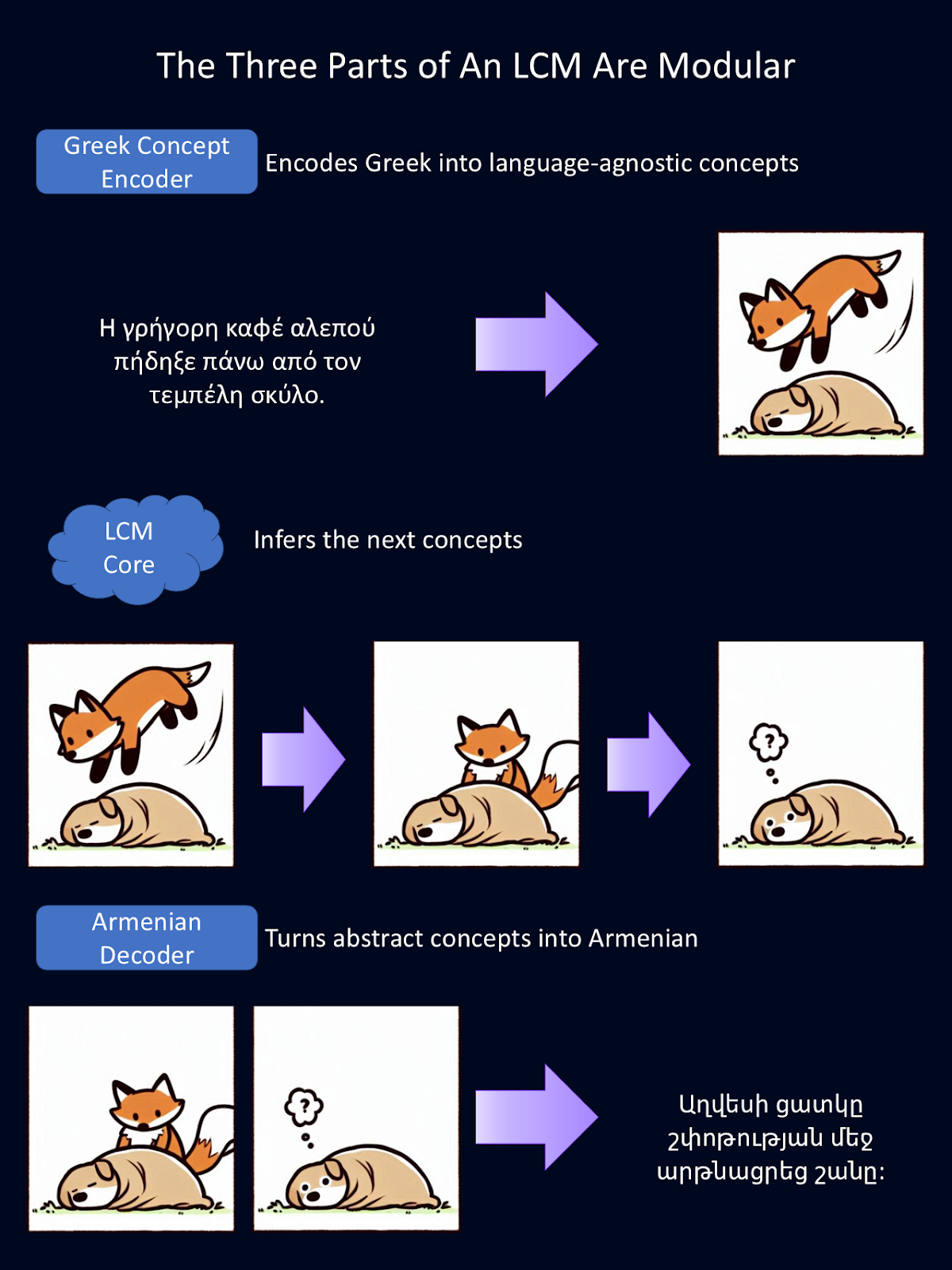
Since each part of the LCM is modular, each part can be swapped out independently. In the diagram above, we’ve swapped out the previous English language encoder and decoder with a Greek language encoder and an Armenian language decoder.
These encoders and decoders can also be swapped out for ones that handle different modalities of language, such as verbal speech instead of text. For this figure, Google Translate provided the translations from English, and Copilot provided the first draft of the animal drawings.
The applications of LCMs overlap with those of LLMs, but because of their focus on concepts and deeper understanding, they have the potential to create a more profound impact on industries that require deeper thought.
LCMs simplify translation and enhance cross-linguistic understanding by operating in a language-agnostic embedding space. This makes them particularly effective for tasks like multilingual summarization or translation of complex documents.
For example, an LCM can process a complex legal document in one language and generate a coherent summary in another. This capability is invaluable for global organizations, international communication, and translations involving low-resource languages.
LCMs excel at producing coherent and contextually relevant outputs, making them an ideal choice for tasks like drafting reports, writing articles, and creating summaries. By maintaining logical consistency across long-form content, LCMs can produce outputs that require significantly less editing than LLMs, saving time and effort for professionals in journalism, marketing, and research.
I think the applicability of LCMs to education is the most impressive. Imagine an intelligent tutoring system powered by an LCM that can generate explanatory and interactive content tailored to individual learners.
An LCM tutor could summarize a complex topic into simpler, conceptually digestible segments for students at varying levels of expertise. Its adaptability across languages could allow one teacher to teach students in hundreds of languages at once!
LCMs are also well-suited for assisting in research and creative writing. They can draft structured, coherent pieces of writing, such as essays, research papers, or fictional narratives, providing initial drafts that writers can refine further.
Researchers can also use LCMs to organize ideas, expand on summaries, or even generate hypotheses based on existing data. They solve a lot of the problems that researchers find frustrating with current LLMs.
I’m sure I’m not the only one who’s had the frustrating experience of interacting with one of these new LLM-powered customer support bots, only for it not to understand my problem. With LCMs powering them, customer support chatbots can offer an improved understanding of complex situations and maybe even more creative solutions. This can lead to improved customer satisfaction and retention.
Right now, LLMs are used in several of these capacities, but they have limited efficacy. LCMs have the potential to level up these applications. Soon, our AI assistants might be more like having real human assistants, capable of following along with more complex ideas and conversations—only they can communicate much faster than us.
While LCMs offer exciting possibilities, they also come with challenges in data requirements, complexity, and computational costs. Let’s go over a few of the biggest current challenges.
Training any AI model requires vast amounts of data, but LCMs have extra processing steps compared to LLMs. Instead of using raw text, they rely on sentence-level representations, meaning text must first be broken into sentences and then converted into embeddings. This adds a layer of preprocessing and storage demands.
Plus, training on hundreds of billions of sentences requires immense computational power.
LCMs process entire sentences as single units, which helps maintain logical flow, but makes troubleshooting more difficult.
LLMs generate text one word at a time, allowing us to trace errors back to individual tokens. In contrast, LCMs operate in a high-dimensional embedding space, where decisions are based on abstract relationships.
LCMs, especially diffusion-based models, require far more processing power than LLMs. While LLMs generate text in one forward pass, diffusion-based LCMs refine their outputs step by step, which increases both computation time and cost. While LCMs can be more efficient for long documents, they are often less efficient for short-form tasks like quick responses or chat-based interactions.
Defining concepts at the sentence level creates challenges of its own. Longer sentences may contain multiple ideas, making it difficult to capture them as a single unit. And shorter sentences might not provide enough context for meaningful representation.
LCMs also face data sparsity issues. Since individual sentences are far more unique than words, the model has fewer repeated patterns to learn from.
This technology is rapidly developing and these challenges are actively being addressed. Because this technology is open source, you can add your own solutions to help address these challenges and advance this technology.
Are you interested in trying your hand at working with an LCM? A lot of the code is open-source, so you can do just that!
A great starting point is the freely available LCM training code and the SONAR embedding space. These open-source tools allow developers to experiment with this new technology and make their own improvements.
To learn more about the theory behind LCMs, check out this paper by Meta.
The ability of LCMs to operate at a conceptual level has the potential to refine AI interactions with language. By moving beyond the constraints of token-based analysis, LCMs open the way for more nuanced, context-aware, and multilingual applications.
I encourage you to check out the code for yourself and add your own flair. What improvements can you make to this technology? What products can you create with it?
Learn AI with these courses!
Track
Track
Track
blog
Bhavishya Pandit
8 min
blog
Dr Ana Rojo-Echeburúa
8 min
blog
Javier Canales Luna
12 min
blog
Andrea Valenzuela
10 min
Tutorial
Josep Ferrer
code-along
Richie Cotton

