
Cursus
Principes fondamentaux de l'intelligence artificielle dans le monde des affaires
12 h
Les grands modèles de langage (LLM) sont très puissants, mais ils ont souvent du mal à suivre les idées générales. En effet, les LLM fonctionnent en prédisant le texte un jeton, ou mot, à la fois.
Cette approche jeton par jeton, combinée à une fenêtre contextuelle limitée, peut conduire à des réponses décousues, à une perte de contexte et à de nombreuses répétitions. C'est comme si vous essayiez d'écrire un essai en devinant chaque mot suivant au lieu d'ébaucher d'abord votre pensée.
C'est là que les grands modèles conceptuels (LCM) peuvent s'avérer utiles. Au lieu de travailler mot par mot, les LCM traitent le langage au niveau de la phrase et l'abstraient en concepts. Cette abstraction permet au modèle de comprendre la langue d'une manière plus réfléchie et plus significative.
Un modèle à grands concepts (LCM) est un type de modèle linguistique qui traite le langage au niveau du concept plutôt que d'analyser des mots individuels. Contrairement aux modèles traditionnels qui décomposent le texte mot par mot, les LCM interprètent les représentations sémantiques, qui correspondent à des phrases entières ou à des idées cohérentes. Ce changement leur permet de saisir le sens plus large de la langue plutôt que d'en saisir uniquement les mécanismes.

Imaginez que vous lisiez un roman. Un LLM le traiterait jeton par jeton, en se concentrant sur les mots individuels et leurs voisins immédiats. Avec cette approche, il pourrait générer un résumé en prédisant le mot suivant le plus probable. Mais elle risque de passer à côté du récit plus large et des thèmes sous-jacents.
Les MCL, quant à eux, analysent de plus grandes parties de texte pour en extraire les idées sous-jacentes. Cette approche les aide à comprendre les concepts plus larges : l'arc narratif global, le développement des personnages et les thèmes. Cette approche peut non seulement les aider à produire un résumé plus complet, mais aussi à développer l'histoire de manière plus significative.
Cette capacité à penser en concepts plutôt qu'en mots rend les MCP incroyablement flexibles. Ils sont construits sur l'espace d'intégration de espace d'intégration SONARce qui leur permet de traiter du texte dans plus de 200 langues et de la parole dans 76 langues.
Au lieu de s'appuyer sur des modèles spécifiques à une langue, les MCL stockent le sens à un niveau conceptuel. Cette abstraction leur permet de s'adapter à des tâches telles que le résumé multilingue, la traduction et la génération de contenu multiformat.
Parce que les LCM traitent le langage au niveau conceptuel, ils génèrent des résultats structurés et contextuels. Contrairement aux MLD, qui construisent le texte mot par mot, les MCL utilisent des représentations numériques de phrases entières pour maintenir le flux logique. Ils sont donc particulièrement efficaces pour des tâches telles que la rédaction de rapports ou la traduction de documents volumineux.
Ils ont également une conception modulaire, qui permet aux développeurs d'intégrer de nouvelles langues ou modalités sans avoir à reconfigurer l'ensemble du système.
Les LLM et les LCM partagent de nombreux objectifs : ils génèrent tous deux du texte, résument des informations et traduisent d'une langue à l'autre. Mais la manière dont ils accomplissent ces tâches est fondamentalement différente.
Les LLM prédisent le texte un jeton à la fois, ce qui leur permet de produire des phrases fluides. Toutefois, cela entraîne souvent des incohérences ou des redondances dans les résultats plus longs. Les LCM, quant à eux, traitent le langage au niveau de la phrase, ce qui leur permet de maintenir un flux logique dans de longs passages.
Une autre distinction concerne la manière dont ils gèrent le traitement multilingue. Les LLM s'appuient fortement sur des données de formation provenant de langues à ressources élevées, ou de langues qui ont beaucoup de contenu de formation, comme l'anglais. Par conséquent, ils sont souvent confrontés à des langues à faibles ressources qui ne disposent pas de vastes ensembles de données.
Les LCM, cependant, opèrent dans l'espace d'intégration du SONAR. Cet espace d'intégration leur permet de traiter des textes dans de nombreuses langues sans avoir à se recycler. Travailler avec des concepts abstraits les rend beaucoup plus aadaptables.
|
Capacité |
Comment fonctionne le LLM ? |
Comment les MCP l'améliorent |
|
Flexibilité multilingue et multiformat |
Formé principalement aux langues à hautes ressources, j'ai du mal avec les langues moins courantes. Nécessite une formation supplémentaire pour les différents formats, comme la parole. |
Fonctionne dans plus de 200 langues et prend en charge le texte et la parole, sans formation supplémentaire. |
|
Généralisation à de nouvelles tâches |
Nécessite une mise au point pour traiter de nouvelles langues ou de nouveaux sujets. Difficultés avec des données peu familières. |
Utilise un système indépendant de la langue, ce qui lui permet de gérer de nouvelles langues et de nouvelles tâches sans formation supplémentaire. |
|
Cohérence du contenu de longue durée |
Il écrit mot par mot, ce qui rend les réponses longues sujettes à des incohérences ou à des répétitions. |
Traite des phrases complètes en une seule fois, ce qui rend les réponses plus claires et plus structurées que les textes longs. |
|
Efficacité dans le traitement du contexte |
Difficulté à traiter les entrées plus longues en raison de l'augmentation des besoins en mémoire et en traitement. |
Utilise des représentations compactes des phrases, ce qui facilite le traitement efficace des documents longs. |
Les grands modèles conceptuels obtiennent leurs capacités uniques grâce à un système en trois parties :
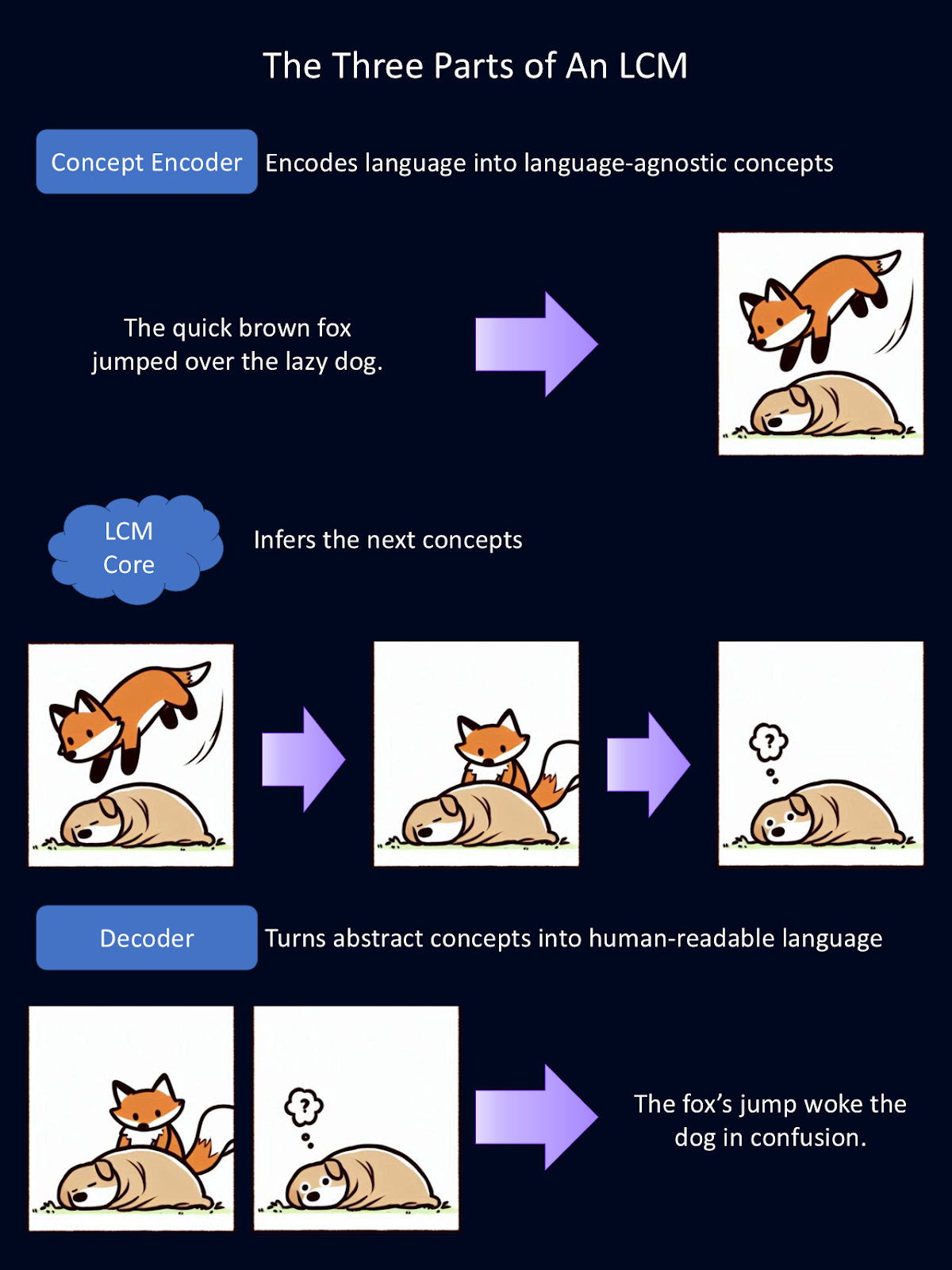
Le schéma ci-dessus est une explication simplifiée du fonctionnement de chacun des trois composants modulaires d'un LCM. L'encodeur transforme le langage en concepts abstraits. Ici, ces concepts abstraits sont représentés sous forme d'images. Dans le modèle, ces concepts sont représentés mathématiquement. Le noyau effectue des déductions sur ces concepts. Ensuite, le décodeur transforme ces abstractions en langage lisible par l'homme. Pour cette figure, Copilot a fourni la première ébauche des dessins d'animaux.
La première étape du processus de traitement d'un LCM consiste à encoder les données d'entrée dans une représentation sémantique à haute dimension. Il s'agit essentiellement de transformer le langage en représentations mathématiques de concepts. Ce codeur conceptuel cartographie de grands segments de texte, comme des phrases entières.
Les LCM utilisent SONAR, un espace d'intégration puissant pour le langage. C'est cet espace d'intégration qui permet d'utiliser différentes langues pour le texte et la parole. Le SONAR permet au codeur de traiter à la fois le langage écrit et le langage parlé, en distillant les concepts dans un langage compréhensible par le modèle.
Une fois les concepts encodés, le noyau LCM les traite pour en générer de nouveaux en fonction du contexte. C'est ici qu'intervient la déduction. Contrairement aux LLM, qui prédisent le texte mot à mot, le cœur du LCM prédit des phrases ou des concepts entiers.
Il existe trois types de noyaux LCM, chacun ayant une approche distincte des concepts de modélisation :
Parmi ceux-ci, les MCP basés sur la diffusion ont démontré le meilleur pouvoir prédictif, générant les résultats les plus précis et les plus cohérents sur le plan contextuel.
Une fois que le LCM Core a traité et prédit de nouveaux concepts, ceux-ci doivent être reconvertis sous une forme lisible par l'homme. C'est le travail du décodeur de concepts. Il traduit les représentations mathématiques des concepts en texte ou en sortie vocale.
Les concepts sous-jacents étant stockés dans un espace d'intégration partagé, ils peuvent être décodés dans n'importe quelle langue prise en charge sans retraitement. C'est incroyablement puissant, car cela signifie que les résultats ne dépendent pas de la langue. Toute la "réflexion" se fait en mathématiques. Ainsi, un LCM formé principalement à l'anglais et à l'espagnol pourrait lire des données en allemand, "penser" en mathématiques et générer du contenu en japonais.
Cela signifie également que de nouvelles langues et modalités peuvent être ajoutées sans qu'il soit nécessaire d'entraîner à nouveau l'ensemble du modèle. Si un nouveau système de synthèse vocale est développé, il peut être intégré à un LCM existant sans nécessiter d'énormes ressources informatiques.
Imaginez que quelqu'un fabrique un encodeur et un décodeur pour la langue des signes. Ils pourraient l'ajouter à un noyau LCM existant, sans recyclage, et communiquer des idées dans un format entièrement différent. Cette flexibilité fait des LCM une solution évolutive et adaptable pour les applications d'IA multilingues et multiformats.
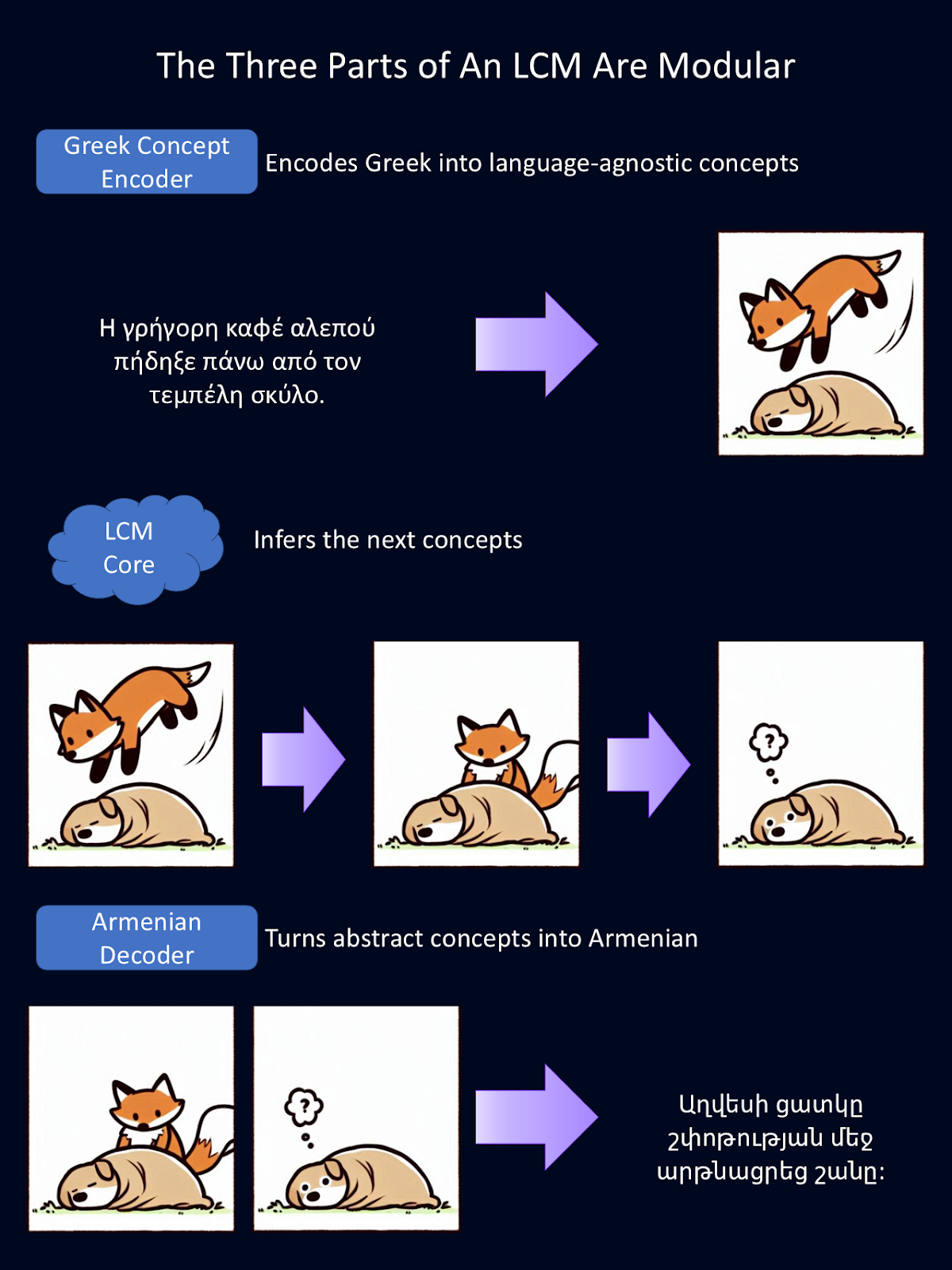
Comme chaque partie du LCM est modulaire, chaque partie peut être remplacée indépendamment. Dans le schéma ci-dessus, nous avons remplacé l'encodeur et le décodeur de langue anglaise par un encodeur de langue grecque et un décodeur de langue arménienne.
Ces encodeurs et décodeurs peuvent également être remplacés par des encodeurs et décodeurs qui gèrent différentes modalités de langage, comme la parole au lieu du texte. Pour cette figure, Google Translate a fourni les traductions de l'anglais et Copilot a fourni la première version des dessins d'animaux.
Les applications des LCM se recoupent avec celles des LLM, mais en raison de l'importance qu'ils accordent aux concepts et à une compréhension plus approfondie, ils ont le potentiel de créer un impact plus profond sur les industries qui exigent une réflexion plus approfondie.
Les LCM simplifient la traduction et améliorent la compréhension interlinguistique en opérant dans un espace d'intégration agnostique par rapport à la langue. Cela les rend particulièrement efficaces pour des tâches telles que le résumé multilingue ou la traduction de documents complexes.
Par exemple, un LCM peut traiter un document juridique complexe dans une langue et générer un résumé cohérent dans une autre. Cette capacité est inestimable pour les organisations mondiales, la communication internationale et les traductions impliquant des langues à faibles ressources.
Les MCL excellent dans la production de résultats cohérents et adaptés au contexte, ce qui en fait un choix idéal pour des tâches telles que la rédaction de rapports, d'articles et de résumés. En maintenant une cohérence logique dans les contenus de longue durée, les LCM peuvent produire des résultats qui nécessitent beaucoup moins d'édition que les LLM, ce qui permet aux professionnels du journalisme, du marketing et de la recherche de gagner du temps et d'économiser des efforts.
Je pense que l'applicabilité des MCP à l'éducation est la plus impressionnante. Imaginez un système de tutorat intelligent alimenté par un LCM capable de générer un contenu explicatif et interactif adapté à chaque apprenant.
Un tuteur LCM pourrait résumer un sujet complexe en segments plus simples et conceptuellement digestes pour des étudiants ayant des niveaux d'expertise variés. Son adaptabilité aux différentes langues pourrait permettre à un enseignant d'enseigner à ses élèves dans des centaines de langues à la fois !
Les LCM sont également bien adaptés à l'aide à la recherche et à la rédaction créative. Ils peuvent rédiger des textes structurés et cohérents, tels que des essais, des documents de recherche ou des récits fictifs, en fournissant des projets initiaux que les auteurs peuvent ensuite affiner.
Les chercheurs peuvent également utiliser les MCP pour organiser des idées, développer des résumés ou même générer des hypothèses sur la base de données existantes. Ils résolvent une grande partie des problèmes que les chercheurs trouvent frustrants avec les LLM actuels.
Je suis sûr que je ne suis pas le seul à avoir vécu l'expérience frustrante d'interagir avec l'un de ces nouveaux robots d'assistance à la clientèle alimentés par le LLM, pour qu'il ne comprenne pas mon problème. Grâce aux LCM, les chatbots d'assistance à la clientèle peuvent offrir une meilleure compréhension des situations complexes et peut-être même des solutions plus créatives. Cela peut conduire à une amélioration de la satisfaction et de la fidélisation des clients.
À l'heure actuelle, les LLM sont utilisés dans plusieurs de ces capacités, mais leur efficacité est limitée. Les LCM ont le potentiel de faire évoluer ces applications. Bientôt, nos assistants IA pourraient ressembler davantage à de véritables assistants humains, capables de suivre des idées et des conversations plus complexes, à ceci près qu'ils peuvent communiquer beaucoup plus rapidement que nous.
Si les MCP offrent des possibilités intéressantes, ils posent également des problèmes en termes de besoins en données, de complexité et de coûts de calcul. Passons en revue quelques-uns des plus grands défis actuels.
L'apprentissage de tout modèle d'IA nécessite de grandes quantités de données, mais les MCP comportent des étapes de traitement supplémentaires par rapport aux MLT. Au lieu d'utiliser du texte brut, ils s'appuient sur des représentations au niveau des phrases, ce qui signifie que le texte doit d'abord être décomposé en phrases, puis converti en enchâssements. Cela ajoute une couche de prétraitement et de stockage.
De plus, l'entraînement sur des centaines de milliards de phrases nécessite une puissance de calcul considérable.
Les LCM traitent des phrases entières comme des unités uniques, ce qui permet de maintenir le flux logique, mais rend le dépannage plus difficile.
Les LLM génèrent du texte un mot à la fois, ce qui nous permet de retracer les erreurs jusqu'aux tokens individuels. En revanche, les LCM opèrent dans un espace d'intégration à haute dimension, où les décisions sont basées sur des relations abstraites.
Les MCL, en particulier les modèles basés sur la diffusion, nécessitent beaucoup plus de puissance de traitement que les MLD. Alors que les MLD génèrent du texte en un seul passage, les MCL basés sur la diffusion affinent leurs résultats étape par étape, ce qui augmente à la fois le temps de calcul et le coût. Si les MCL peuvent être plus efficaces pour les documents longs, ils le sont souvent moins pour les tâches courtes telles que les réponses rapides ou les interactions par chat.
La définition des concepts au niveau de la phrase pose des problèmes spécifiques. Les phrases plus longues peuvent contenir plusieurs idées, ce qui rend difficile leur saisie en tant qu'unité unique. De plus, les phrases plus courtes peuvent ne pas fournir un contexte suffisant pour une représentation significative.
Les LCM sont également confrontés à des problèmes de rareté des données. Les phrases individuelles étant beaucoup plus uniques que les mots, le modèle a moins de modèles répétés à apprendre.
Cette technologie se développe rapidement et ces défis sont activement relevés. Cette technologie étant open source, vous pouvez ajouter vos propres solutions pour contribuer à relever ces défis et à faire progresser cette technologie.
Vous souhaitez travailler avec un LCM ? Une grande partie du code est libre, vous pouvez donc le faire !
Un excellent point de départ est le code de formation code de formation LCM et l'espace l'espace d'intégration SONAR. Ces outils à code source ouvert permettent aux développeurs d'expérimenter cette nouvelle technologie et d'y apporter leurs propres améliorations.
Pour en savoir plus sur la théorie qui sous-tend les MCP, consultez cet article par Meta.
La capacité des LCM à opérer à un niveau conceptuel peut permettre d'affiner les interactions de l'IA avec le langage. En dépassant les contraintes de l'analyse basée sur les jetons, les MCL ouvrent la voie à des applications plus nuancées, contextuelles et multilingues.
Je vous encourage à vérifier le code par vous-même et à y ajouter votre propre touche. Quelles améliorations pouvez-vous apporter à cette technologie ? Quels produits pouvez-vous créer avec elle ?
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cursus
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min