
Programa
Fundamentos do Negócio de IA
12 h
Os modelos de linguagem grande (LLMs) são muito avançados, mas muitas vezes têm dificuldade em manter o controle de ideias de grande porte. Isso ocorre porque os LLMs funcionam prevendo o texto um token, ou palavra, por vez.
Essa abordagem token a token, combinada com uma janela de contexto limitada, pode levar a respostas desarticuladas, perda de contexto e muita repetição. É como se você tentasse escrever uma redação adivinhando cada palavra, em vez de primeiro delinear seus pensamentos.
É nesse ponto que os modelos conceituais grandes (LCMs) podem ser úteis. Em vez de trabalhar palavra por palavra, os LCMs processam a linguagem no nível da frase e a abstraem em conceitos. Essa abstração permite que o modelo compreenda a linguagem de uma forma mais ponderada e significativa.
Um modelo de conceito grande (LCM) é um tipo de modelo de linguagem que processa a linguagem no nível do conceito em vez de analisar palavras individuais. Diferentemente dos modelos tradicionais que analisam o texto palavra por palavra, os LCMs interpretam representações semânticas, que correspondem a frases inteiras ou ideias coesas. Essa mudança permite que eles compreendam o significado mais amplo da linguagem em vez de apenas a mecânica.

Imagine que você esteja lendo um romance. Um LLM o processaria token por token, concentrando-se em palavras individuais e seus vizinhos imediatos. Com essa abordagem, ele poderia gerar um resumo prevendo a próxima palavra mais provável. Mas você pode não perceber a narrativa mais ampla e os temas subjacentes.
Os LCMs, no entanto, analisam seções maiores do texto para extrair as ideias subjacentes. Essa abordagem os ajuda a entender os conceitos mais amplos: arco geral da história, desenvolvimento de personagens e temas. Essa abordagem não só pode ajudá-los a gerar um resumo mais completo, como também pode ajudá-los a expandir a história de uma forma mais significativa.
Essa capacidade de pensar em conceitos em vez de palavras torna os LCMs incrivelmente flexíveis. Eles são construídos no espaço de incorporação espaço de incorporação SONARo que lhes permite processar texto em mais de 200 idiomas e fala em 76.
Em vez de depender de padrões específicos do idioma, os LCMs armazenam o significado em um nível conceitual. Essa abstração os torna adaptáveis a tarefas como resumo multilíngue, tradução e geração de conteúdo entre formatos.
Como os LCMs processam a linguagem no nível conceitual, eles geram resultados estruturados e contextualmente conscientes. Diferentemente dos LLMs, que criam o texto palavra por palavra, os LCMs usam representações numéricas de frases inteiras para manter o fluxo lógico. Isso os torna especialmente eficazes para tarefas como a elaboração de relatórios ou a tradução de documentos extensos.
Eles também têm um design modular, o que permite que os desenvolvedores integrem novos idiomas ou modalidades sem precisar treinar novamente todo o sistema.
Os LLMs e LCMs compartilham muitos dos mesmos objetivos: ambos geram texto, resumem informações e traduzem entre idiomas. Mas a maneira como eles realizam essas tarefas é fundamentalmente diferente.
Os LLMs preveem o texto um token de cada vez, o que os torna excelentes na produção de frases fluentes. No entanto, isso geralmente leva a inconsistências ou redundâncias em resultados mais longos. Os LCMs, por outro lado, processam a linguagem no nível da frase, o que lhes permite manter o fluxo lógico em passagens extensas.
Outra distinção é como eles lidam com o processamento multilíngue. Os LLMs dependem muito de dados de treinamento de idiomas com muitos recursos ou de idiomas que têm muito conteúdo de treinamento, como o inglês. Como resultado, eles geralmente têm dificuldades com idiomas de poucos recursos que não possuem grandes conjuntos de dados.
Os LCMs, no entanto, operam no espaço de incorporação do SONAR. Esse espaço de incorporação permite que eles processem textos em vários idiomas sem retreinamento. Trabalhar com conceitos abstratos os torna muito maisadaptáveis.
|
Capacidade |
Como funcionam os LLMs |
Como os LCMs melhoram isso |
|
Flexibilidade multilíngue e multiformato |
Treinada principalmente em idiomas com muitos recursos e com dificuldades nos menos comuns. Precisa de treinamento adicional para formatos diferentes, como fala. |
Funciona em mais de 200 idiomas e oferece suporte a texto e fala, sem necessidade de treinamento adicional. |
|
Generalização para novas tarefas |
Precisa de ajuste fino para lidar com novos idiomas ou tópicos. Você tem dificuldades com dados desconhecidos. |
Usa um sistema independente de idioma, o que permite que você lide com novos idiomas e tarefas sem treinamento adicional. |
|
Coerência em conteúdo de formato longo |
Escreve palavra por palavra, o que torna as respostas longas propensas a inconsistências ou repetições. |
Processa frases completas de uma só vez, mantendo as respostas mais claras e estruturadas em relação a textos longos. |
|
Eficiência no manuseio do contexto |
Tem dificuldades com entradas mais longas devido ao aumento das necessidades de memória e processamento. |
Usa representações compactas de frases, facilitando o processamento eficiente de documentos longos. |
Os modelos conceituais grandes alcançam seus recursos exclusivos por meio de um sistema de três partes:
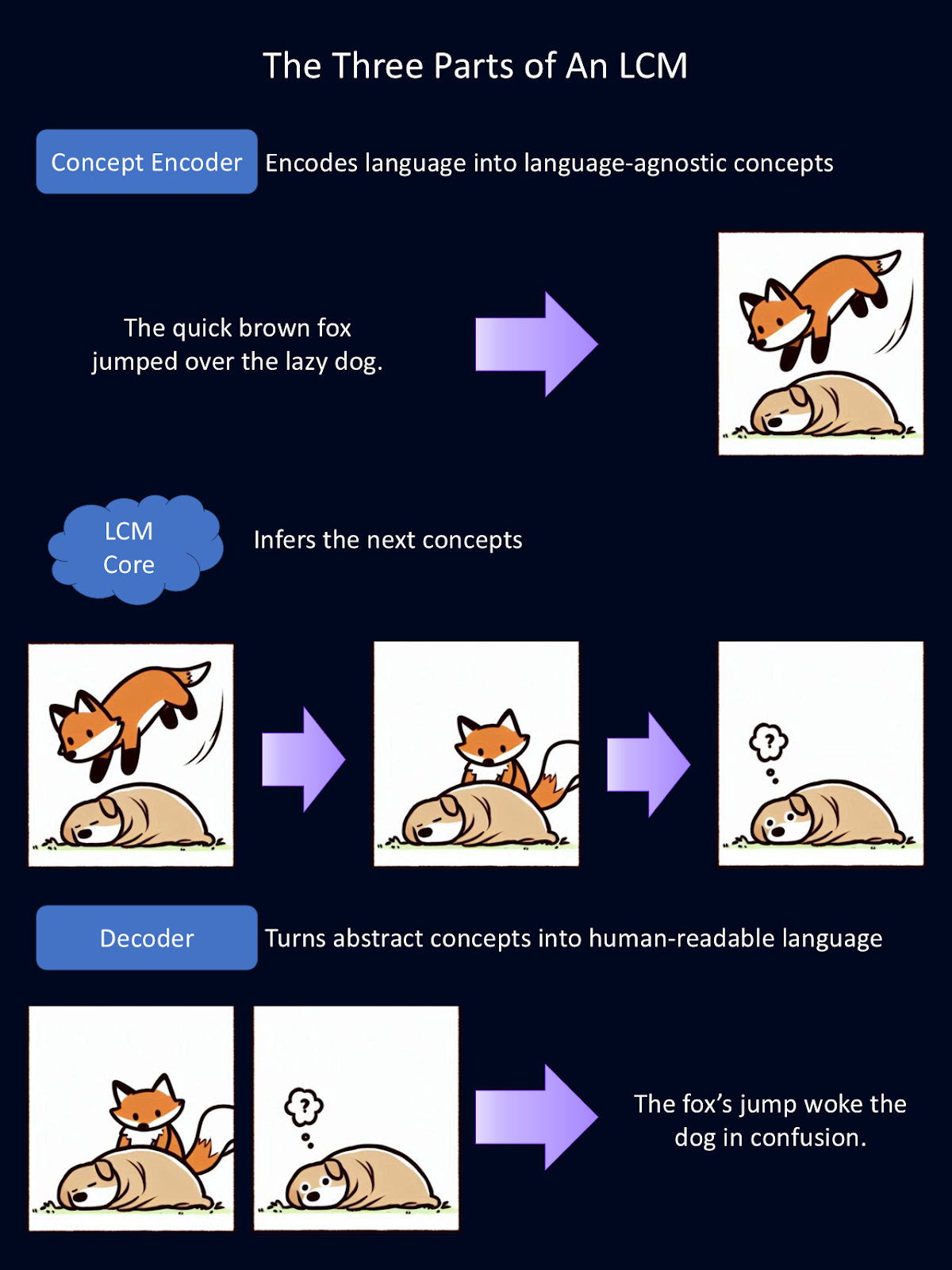
O diagrama acima é uma explicação simplificada de como cada um dos três componentes modulares de um LCM funciona. O codificador transforma a linguagem em conceitos abstratos. Aqui, esses conceitos abstratos são representados como imagens. No modelo, esses conceitos são representados matematicamente. O núcleo executa inferências sobre esses conceitos. Em seguida, o decodificador transforma essas abstrações em linguagem legível por humanos. Para essa figura, o Copilot forneceu o primeiro rascunho dos desenhos dos animais.
A primeira etapa do pipeline de processamento de um LCM é codificar a entrada em uma representação semântica de alta dimensão. Essencialmente, isso transforma a linguagem em representações matemáticas de conceitos. Esse codificador de conceito mapeia grandes segmentos de texto, como frases inteiras.
Os LCMs usam o SONAR, um espaço de incorporação avançado para a linguagem. É esse espaço de incorporação que oferece suporte a diferentes idiomas para texto e fala. O SONAR permite que o codificador processe tanto a linguagem escrita quanto a falada, destilando os conceitos em algo que o modelo possa entender.
Depois que os conceitos são codificados, o núcleo do LCM os processa para gerar novos conceitos com base no contexto. É aqui que ocorre a inferência. Diferentemente dos LLMs, que preveem texto token por token, o núcleo do LCM prevê frases ou conceitos inteiros.
Há três tipos de núcleos LCM, cada um com uma abordagem distinta dos conceitos de modelagem:
Entre eles, os LCMs baseados em difusão demonstraram o melhor poder de previsão, gerando os resultados mais precisos e contextualmente coerentes.
Depois que o LCM Core tiver processado e previsto novos conceitos, eles deverão ser convertidos novamente em um formato legível por humanos. Esse é o trabalho do decodificador de conceitos. Ele traduz as representações matemáticas de conceitos em saídas de texto ou fala.
Como os conceitos subjacentes são armazenados em um espaço de incorporação compartilhado, eles podem ser decodificados em qualquer linguagem compatível sem reprocessamento. Isso é incrivelmente poderoso porque significa que os resultados são independentes do idioma. Todo o "pensamento" acontece com a matemática. Assim, um LCM treinado principalmente em inglês e espanhol poderia ler entradas em alemão, "pensar" em matemática e gerar conteúdo em japonês.
Isso também significa que novas linguagens e modalidades podem ser adicionadas sem que você precise treinar novamente todo o modelo. Se um novo sistema de fala para texto for desenvolvido, ele poderá ser integrado a um LCM existente sem a necessidade de recursos computacionais maciços.
Imagine se alguém fizesse um codificador e um decodificador para a linguagem de sinais. Eles poderiam adicioná-lo a um núcleo de LCM existente, sem retreinamento, e comunicar ideias em um formato totalmente diferente. Essa flexibilidade torna os LCMs uma solução dimensionável e adaptável para aplicativos de IA multilíngues e multiformatos.
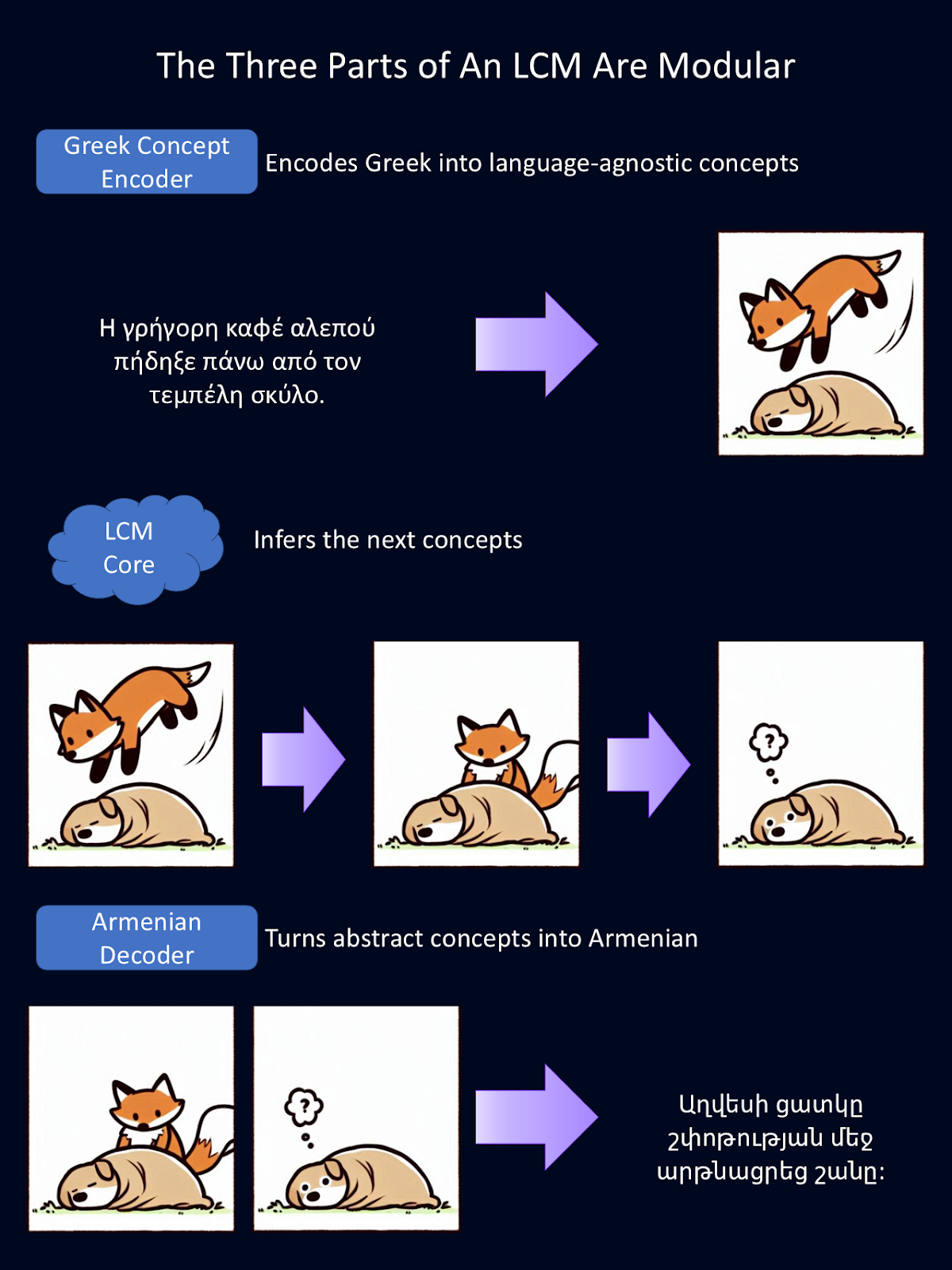
Como cada parte do LCM é modular, cada parte pode ser trocada de forma independente. No diagrama acima, trocamos o codificador e o decodificador do idioma inglês anterior por um codificador do idioma grego e um decodificador do idioma armênio.
Esses codificadores e decodificadores também podem ser trocados por outros que lidam com diferentes modalidades de linguagem, como fala verbal em vez de texto. Para esta figura, o Google Translate forneceu as traduções do inglês e o Copilot forneceu o primeiro rascunho dos desenhos dos animais.
As aplicações dos LCMs se sobrepõem às dos LLMs, mas, devido ao seu foco em conceitos e compreensão mais profunda, eles têm o potencial de criar um impacto mais profundo nos setores que exigem uma reflexão mais profunda.
Os LCMs simplificam a tradução e aprimoram a compreensão entre idiomas, operando em um espaço de incorporação independente do idioma. Isso os torna particularmente eficazes para tarefas como resumo multilíngue ou tradução de documentos complexos.
Por exemplo, um LCM pode processar um documento jurídico complexo em um idioma e gerar um resumo coerente em outro. Esse recurso é inestimável para organizações globais, comunicação internacional e traduções que envolvem idiomas com poucos recursos.
Os LCMs são excelentes na produção de resultados coerentes e contextualmente relevantes, o que os torna a escolha ideal para tarefas como elaboração de relatórios, redação de artigos e criação de resumos. Ao manter a consistência lógica em todo o conteúdo de formato longo, os LCMs podem produzir resultados que exigem muito menos edição do que os LLMs, economizando tempo e esforço dos profissionais de jornalismo, marketing e pesquisa.
Acho que a aplicabilidade dos LCMs à educação é a mais impressionante. Imagine um sistema de tutoria inteligente alimentado por um LCM que possa gerar conteúdo explicativo e interativo adaptado a cada aluno.
Um tutor de LCM poderia resumir um tópico complexo em segmentos mais simples e conceitualmente digeríveis para alunos com diferentes níveis de conhecimento. Sua adaptabilidade a vários idiomas poderia permitir que um professor ensinasse alunos em centenas de idiomas ao mesmo tempo!
Os LCMs também são adequados para auxiliar na pesquisa e na redação criativa. Eles podem redigir textos estruturados e coerentes, como ensaios, trabalhos de pesquisa ou narrativas ficcionais, fornecendo rascunhos iniciais que os escritores podem aperfeiçoar posteriormente.
Os pesquisadores também podem usar LCMs para organizar ideias, expandir resumos ou até mesmo gerar hipóteses com base em dados existentes. Eles resolvem muitos dos problemas que os pesquisadores consideram frustrantes nos LLMs atuais.
Tenho certeza de que não sou o único que teve a experiência frustrante de interagir com um desses novos bots de suporte ao cliente com LLM, mas ele não entendeu meu problema. Com os LCMs, os chatbots de suporte ao cliente podem oferecer uma melhor compreensão de situações complexas e talvez até soluções mais criativas. Isso pode levar a uma maior satisfação e retenção do cliente.
Atualmente, os LLMs são usados em várias dessas capacidades, mas sua eficácia é limitada. Os LCMs têm o potencial de elevar o nível desses aplicativos. Em breve, nossos assistentes de IA poderão ser mais parecidos com assistentes humanos reais, capazes de acompanhar ideias e conversas mais complexas - só que eles podem se comunicar muito mais rápido do que nós.
Embora os LCMs ofereçam possibilidades interessantes, eles também apresentam desafios em termos de requisitos de dados, complexidade e custos de computação. Vamos examinar alguns dos maiores desafios atuais.
O treinamento de qualquer modelo de IA requer grandes quantidades de dados, mas os LCMs têm etapas de processamento adicionais em comparação com os LLMs. Em vez de usar texto bruto, eles dependem de representações em nível de frase, o que significa que o texto deve primeiro ser dividido em frases e depois convertido em embeddings. Isso adiciona uma camada de demandas de pré-processamento e armazenamento.
Além disso, o treinamento em centenas de bilhões de frases requer um imenso poder computacional.
Os LCMs processam frases inteiras como unidades únicas, o que ajuda a manter o fluxo lógico, mas dificulta a solução de problemas.
Os LLMs geram texto uma palavra de cada vez, o que nos permite rastrear erros até tokens individuais. Por outro lado, os LCMs operam em um espaço de incorporação de alta dimensão, em que as decisões são baseadas em relações abstratas.
Os LCMs, especialmente os modelos baseados em difusão, exigem muito mais poder de processamento do que os LLMs. Enquanto os LLMs geram texto em uma única passagem, os LCMs baseados em difusão refinam seus resultados passo a passo, o que aumenta o tempo de computação e o custo. Embora os LCMs possam ser mais eficientes para documentos longos, eles geralmente são menos eficientes para tarefas de formato curto, como respostas rápidas ou interações baseadas em bate-papo.
A definição de conceitos no nível da frase cria desafios próprios. Frases mais longas podem conter várias ideias, dificultando a captura delas como uma única unidade. E frases mais curtas podem não fornecer contexto suficiente para uma representação significativa.
Os LCMs também enfrentam problemas de escassez de dados. Como as frases individuais são muito mais exclusivas do que as palavras, o modelo tem menos padrões repetidos para aprender.
Essa tecnologia está se desenvolvendo rapidamente e esses desafios estão sendo ativamente abordados. Como essa tecnologia é de código aberto, você pode adicionar suas próprias soluções para ajudar a enfrentar esses desafios e avançar essa tecnologia.
Você tem interesse em tentar trabalhar com um LCM? Grande parte do código é de código aberto, portanto, você pode fazer exatamente isso!
Um ótimo ponto de partida é o código de treinamento do código de treinamento do LCM e o espaço de espaço de incorporação do SONAR. Essas ferramentas de código aberto permitem que os desenvolvedores experimentem essa nova tecnologia e façam seus próprios aprimoramentos.
Para saber mais sobre a teoria por trás dos LCMs, confira este artigo por Meta.
A capacidade dos LCMs de operar em um nível conceitual tem o potencial de refinar as interações da IA com a linguagem. Ao ir além das restrições da análise baseada em tokens, os LCMs abrem caminho para aplicativos com mais nuances, sensíveis ao contexto e multilíngues.
Incentivo você a verificar o código por conta própria e adicionar seu próprio estilo. Que melhorias você pode fazer nessa tecnologia? Que produtos você pode criar com ele?
Aprenda IA com estes cursos!
Programa
Programa
Programa
blog
Nisha Arya Ahmed
12 min
blog
Stanislav Karzhev
9 min
blog
Natassha Selvaraj
15 min
Tutorial
Josep Ferrer
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita

