
Lernpfad
KI-Grundlagen für Unternehmen
12 Std.
Große Sprachmodelle (Large Language Models, LLMs) sind sehr leistungsfähig, aber sie haben oft Probleme, den Überblick über die großen Zusammenhänge zu behalten. Das liegt daran, dass LLMs den Text immer nur für ein Token, also ein Wort, vorhersagen.
Dieser Token-by-Token-Ansatz kann in Kombination mit einem begrenzten Kontextfenster zu unzusammenhängenden Antworten, verlorenem Kontext und vielen Wiederholungen führen. Das ist so, als würdest du versuchen, einen Aufsatz zu schreiben, indem du jedes nächste Wort errätst, anstatt deine Gedanken vorher zu skizzieren.
Hier können sich große Konzeptmodelle (LCMs) als nützlich erweisen. Anstatt Wort für Wort zu arbeiten, verarbeiten LCMs Sprache auf der Satzebene und abstrahieren Sprache zu Konzepten. Diese Abstraktion ermöglicht es dem Modell, Sprache auf eine durchdachte und sinnvolle Weise zu verstehen.
Ein Large Concept Model (LCM) ist eine Art Sprachmodell, das Sprache auf der Konzeptebene verarbeitet, anstatt einzelne Wörter zu analysieren. Im Gegensatz zu traditionellen Modellen, die einen Text Wort für Wort aufschlüsseln, interpretieren LCMs semantische Repräsentationen, die ganzen Sätzen oder zusammenhängenden Ideen entsprechen. Diese Veränderung ermöglicht es ihnen, die breitere Bedeutung der Sprache zu erfassen und nicht nur die Mechanik.

Stell dir vor, du liest einen Roman. Ein LLM würde es Token für Token verarbeiten und sich dabei auf einzelne Wörter und ihre unmittelbaren Nachbarn konzentrieren. Mit diesem Ansatz könnte es eine Zusammenfassung erstellen, indem es das wahrscheinlichste nächste Wort vorhersagt. Aber es kann sein, dass es die breitere Geschichte und die zugrunde liegenden Themen verpasst.
LCMs hingegen analysieren größere Textabschnitte, um die zugrunde liegenden Ideen zu extrahieren. Dieser Ansatz hilft ihnen, die umfassenderen Konzepte zu verstehen: den allgemeinen Handlungsbogen, die Charakterentwicklung und die Themen. Dieser Ansatz kann ihnen nicht nur dabei helfen, eine vollständigere Zusammenfassung zu erstellen, sondern auch, die Geschichte sinnvoll zu erweitern.
Diese Fähigkeit, in Konzepten und nicht in Worten zu denken, macht LCMs unglaublich flexibel. Sie basieren auf dem SONAR-EinbettungsraumDadurch können sie Text in über 200 Sprachen und Sprache in 76 Sprachen verarbeiten.
Anstatt sich auf sprachspezifische Muster zu verlassen, speichern LCMs die Bedeutung auf einer konzeptionellen Ebene. Diese Abstraktion macht sie anpassungsfähig für Aufgaben wie mehrsprachige Zusammenfassungen, Übersetzungen und die Erstellung formatübergreifender Inhalte.
Da LCMs Sprache auf der konzeptionellen Ebene verarbeiten, erzeugen sie strukturierte, kontextbezogene Ergebnisse. Im Gegensatz zu LLMs, die den Text Wort für Wort aufbauen, verwenden LCMs numerische Darstellungen ganzer Sätze, um den logischen Fluss zu erhalten. Das macht sie besonders effektiv für Aufgaben wie das Verfassen von Berichten oder das Übersetzen längerer Dokumente.
Außerdem sind sie modular aufgebaut, so dass Entwickler neue Sprachen oder Modalitäten integrieren können, ohne das gesamte System umzuschulen.
LLMs und LCMs haben viele der gleichen Ziele: Beide generieren Text, fassen Informationen zusammen und übersetzen zwischen Sprachen. Aber die Art und Weise, wie sie diese Aufgaben erfüllen, ist grundlegend anders.
LLMs sagen Text ein Token nach dem anderen voraus, was sie dazu befähigt, flüssige Sätze zu produzieren. Dies führt jedoch oft zu Ungereimtheiten oder Redundanzen bei längeren Outputs. LCMs hingegen verarbeiten Sprache auf der Satzebene und können so den logischen Fluss über längere Passagen hinweg aufrechterhalten.
Ein weiterer Unterschied ist die Art und Weise, wie sie die Mehrsprachigkeit verarbeiten. LLMs stützen sich stark auf Trainingsdaten aus ressourcenstarken Sprachen oder Sprachen, die viele Trainingsinhalte haben, wie Englisch. Daher haben sie oft Probleme mit Sprachen mit geringen Ressourcen, für die es keine großen Datensätze gibt.
LCMs arbeiten jedoch im SONAR-Einbettungsraum. Dieser Einbettungsraum ermöglicht es ihnen, Texte in vielen Sprachen zu verarbeiten, ohne umzulernen. Die Arbeit mit abstrakten Konzepten macht sie vielanpassungsfähiger.
|
Fähigkeit |
Wie LLMs funktionieren |
Wie LCMs es verbessern |
|
Mehrsprachige und Multiformat-Flexibilität |
Sie sind vor allem in den Hochsprachen geschult und tun sich mit den weniger verbreiteten Sprachen schwer. Benötigt zusätzliches Training für verschiedene Formate wie Sprache. |
Funktioniert in mehr als 200 Sprachen und unterstützt Text und Sprache, ohne zusätzliches Training. |
|
Verallgemeinerung auf neue Aufgaben |
Benötigt Feinabstimmung, um neue Sprachen oder Themen zu behandeln. Kämpfe mit unbekannten Daten. |
Verwendet ein sprachunabhängiges System, so dass es neue Sprachen und Aufgaben ohne zusätzliches Training bewältigen kann. |
|
Kohärenz in langen Inhalten |
Schreibt Wort für Wort, so dass lange Antworten anfällig für Unstimmigkeiten oder Wiederholungen sind. |
Verarbeitet ganze Sätze auf einmal, damit die Antworten klarer und strukturierter sind als lange Texte. |
|
Effizienter Umgang mit dem Kontext |
Schwierigkeiten bei längeren Eingaben aufgrund des steigenden Speicher- und Verarbeitungsbedarfs. |
Verwendet kompakte Satzdarstellungen, um lange Dokumente effizient zu bearbeiten. |
Große Konzeptmodelle erreichen ihre einzigartigen Fähigkeiten durch ein dreiteiliges System:
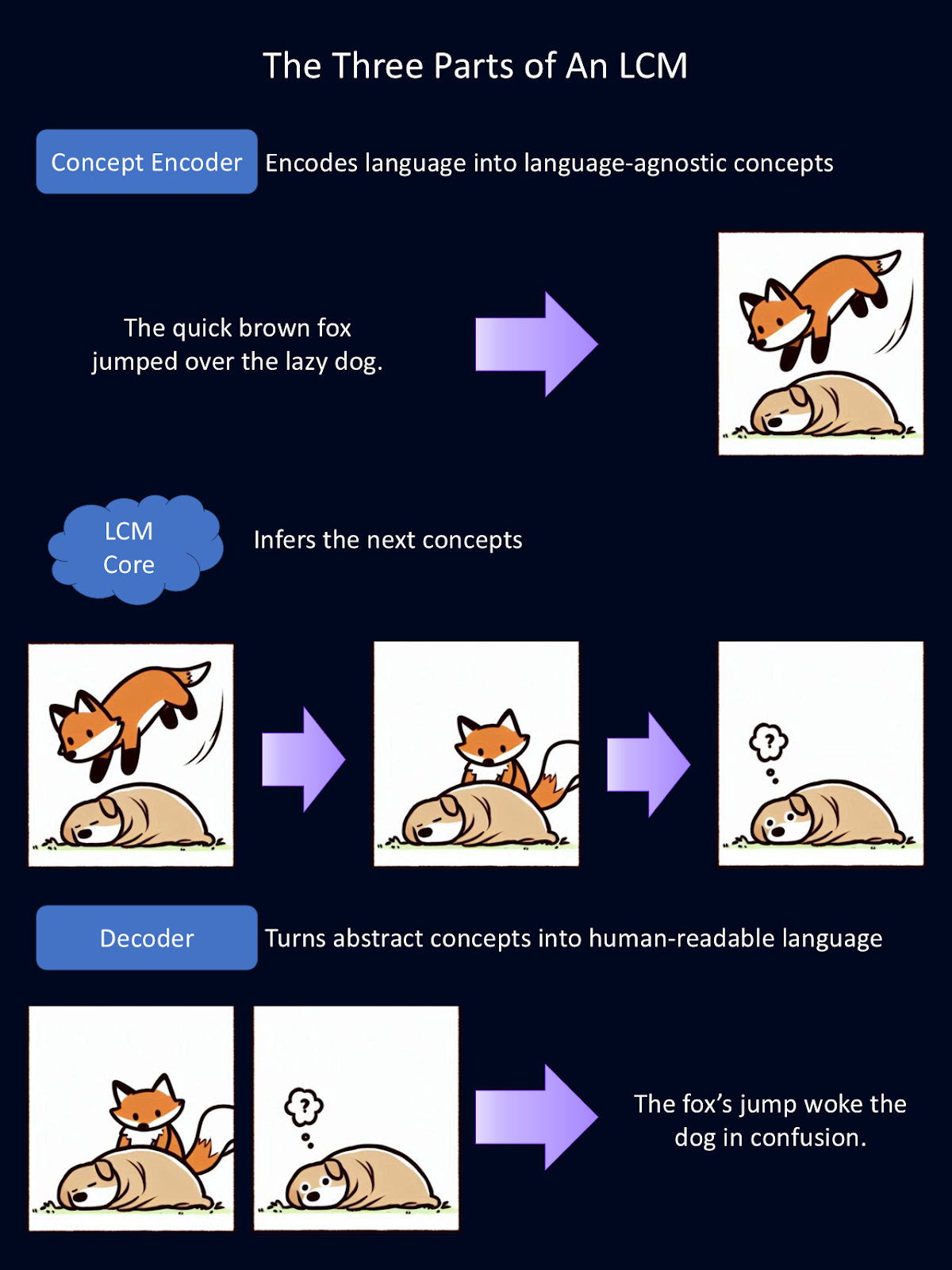
Das obige Diagramm ist eine vereinfachte Erklärung, wie jede der drei modularen Komponenten eines LCMs funktioniert. Der Encoder verwandelt Sprache in abstrakte Konzepte. Hier werden diese abstrakten Konzepte als Bilder dargestellt. In dem Modell werden diese Konzepte mathematisch dargestellt. Das Kernstück ist die Inferenz auf diese Konzepte. Dann wandelt der Decoder diese Abstraktionen in eine für Menschen lesbare Sprache um. Für diese Figur hat Copilot den ersten Entwurf der Tierzeichnungen erstellt.
Der erste Schritt in der Verarbeitungspipeline eines LCM ist die Kodierung der Eingaben in eine hochdimensionale semantische Darstellung. Im Wesentlichen wird dadurch Sprache zu mathematischen Darstellungen von Konzepten. Dieser Konzept-Encoder bildet große Textabschnitte, wie z. B. ganze Sätze, ab.
LCMs verwenden SONAR, einen leistungsstarken Einbettungsraum für Sprache. Es ist dieser Einbettungsraum, der verschiedene Sprachen für Text und Sprache unterstützt. SONAR ermöglicht es dem Encoder, sowohl geschriebene als auch gesprochene Sprache zu verarbeiten und die Konzepte in etwas zu destillieren, das das Modell verstehen kann.
Sobald die Konzepte kodiert sind, verarbeitet der LCM-Kern sie, um neue Konzepte auf der Grundlage des Kontexts zu erstellen. An dieser Stelle wird gefolgert. Im Gegensatz zu LLMs, die den Text Token für Token vorhersagen, sagt der LCM-Kern ganze Sätze oder Konzepte voraus.
Es gibt drei Arten von LCM-Kernen, jeder mit einem anderen Ansatz für die Modellierung von Konzepten:
Unter diesen haben diffusionsbasierte LCMs die beste Vorhersagekraft bewiesen, da sie die genauesten und kontextuell kohärentesten Ergebnisse liefern.
Sobald der LCM-Kern neue Konzepte verarbeitet und vorhergesagt hat, müssen sie wieder in eine für Menschen lesbare Form gebracht werden. Das ist die Aufgabe des Konzeptdecoders. Sie übersetzt die mathematischen Darstellungen von Konzepten in Text- oder Sprachausgaben.
Da die zugrundeliegenden Konzepte in einem gemeinsamen Einbettungsraum gespeichert werden, können sie ohne erneute Bearbeitung in jede unterstützte Sprache dekodiert werden. Das ist unglaublich leistungsstark, denn es bedeutet, dass die Ergebnisse sprachunabhängig sind. Das ganze "Denken" findet in Mathe statt. So kann ein LCM, das hauptsächlich auf Englisch und Spanisch trainiert wurde, Eingaben auf Deutsch lesen, in Mathe "denken" und Inhalte auf Japanisch erstellen.
Das bedeutet auch, dass neue Sprachen und Modalitäten hinzugefügt werden können, ohne das gesamte Modell neu zu trainieren. Wenn ein neues Sprache-zu-Text-System entwickelt wird, kann es in ein bestehendes LCM integriert werden, ohne dass große Rechenressourcen benötigt werden.
Stell dir vor, jemand würde einen Encoder und Decoder für die Gebärdensprache bauen. Sie könnten es ohne Umschulung zu einem bestehenden LCM-Kern hinzufügen und Ideen in einem völlig anderen Format vermitteln. Diese Flexibilität macht LCMs zu einer skalierbaren und anpassungsfähigen Lösung für mehrsprachige und mehrformatige KI-Anwendungen.
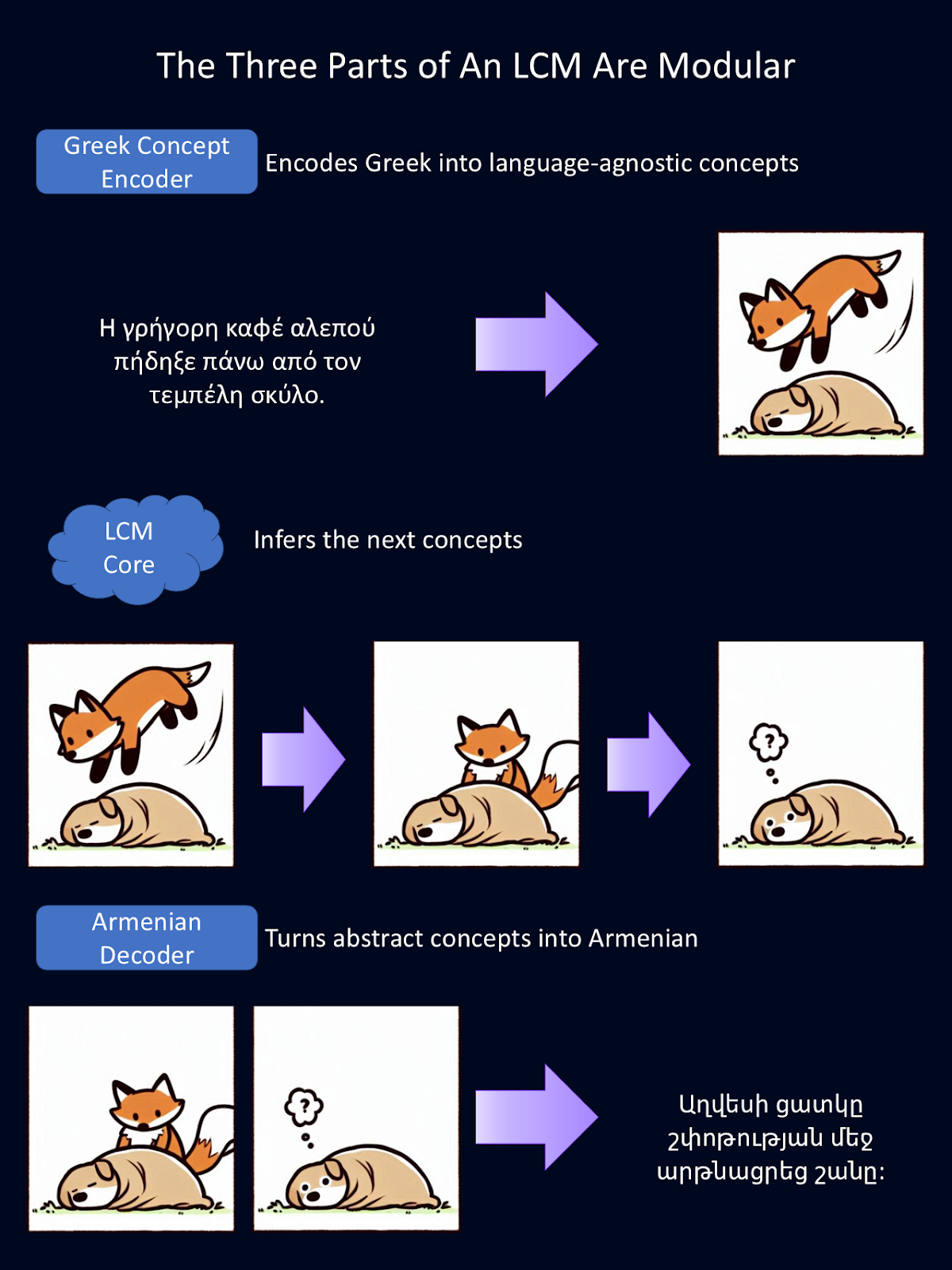
Da jedes Teil des LCM modular aufgebaut ist, kann jedes Teil unabhängig voneinander ausgetauscht werden. Im obigen Diagramm haben wir den bisherigen englischen Sprachcodierer und -decodierer durch einen griechischen Sprachcodierer und einen armenischen Sprachdecodierer ausgetauscht.
Diese Encoder und Decoder können auch gegen solche ausgetauscht werden, die andere Modalitäten der Sprache verarbeiten, z. B. verbale Sprache anstelle von Text. Für diese Abbildung lieferte Google Translate die Übersetzungen aus dem Englischen, und Copilot lieferte den ersten Entwurf der Tierzeichnungen.
Die Anwendungsbereiche von LCMs überschneiden sich mit denen von LLMs, aber da sie sich auf Konzepte und ein tieferes Verständnis konzentrieren, haben sie das Potenzial, einen tiefgreifenderen Einfluss auf Branchen zu haben, die ein tieferes Denken erfordern.
LCMs vereinfachen die Übersetzung und verbessern das sprachübergreifende Verständnis, indem sie in einem sprachunabhängigen Einbettungsraum arbeiten. Das macht sie besonders effektiv für Aufgaben wie mehrsprachige Zusammenfassungen oder die Übersetzung komplexer Dokumente.
Ein LCM kann zum Beispiel ein komplexes juristisches Dokument in einer Sprache bearbeiten und eine kohärente Zusammenfassung in einer anderen Sprache erstellen. Diese Fähigkeit ist von unschätzbarem Wert für globale Organisationen, internationale Kommunikation und Übersetzungen in Sprachen mit geringen Ressourcen.
LCMs zeichnen sich dadurch aus, dass sie kohärente und kontextbezogene Ergebnisse liefern, was sie zu einer idealen Wahl für Aufgaben wie das Verfassen von Berichten, Artikeln und Zusammenfassungen macht. Durch die Beibehaltung der logischen Konsistenz von Langform-Inhalten können LCMs Ergebnisse produzieren, die deutlich weniger Bearbeitung erfordern als LLMs, was Fachleuten aus Journalismus, Marketing und Forschung Zeit und Mühe spart.
Ich denke, die Anwendbarkeit der LCMs im Bildungsbereich ist am beeindruckendsten. Stell dir ein intelligentes Nachhilfesystem vor, das von einem LCM angetrieben wird und erklärende und interaktive Inhalte generieren kann, die auf einzelne Lernende zugeschnitten sind.
Ein LCM-Tutor könnte ein komplexes Thema in einfachere, konzeptionell verdauliche Abschnitte für Schüler mit unterschiedlichem Wissensstand zusammenfassen. Dank seiner Anpassungsfähigkeit an verschiedene Sprachen kann eine Lehrkraft Schüler/innen in Hunderten von Sprachen gleichzeitig unterrichten!
LCMs sind auch gut geeignet, um bei der Recherche und beim kreativen Schreiben zu helfen. Sie können strukturierte, zusammenhängende Texte verfassen, wie z. B. Aufsätze, Forschungsarbeiten oder fiktionale Erzählungen, und so erste Entwürfe erstellen, die die Autorinnen und Autoren weiter verfeinern können.
Forscherinnen und Forscher können LCMs auch nutzen, um Ideen zu ordnen, Zusammenfassungen zu erweitern oder sogar Hypothesen auf der Grundlage vorhandener Daten aufzustellen. Sie lösen viele der Probleme, die Forscher/innen bei den aktuellen LLMs frustrierend finden.
Ich bin sicher, dass ich nicht der Einzige bin, der die frustrierende Erfahrung gemacht hat, mit einem dieser neuen LLM-gesteuerten Kundensupport-Bots zu interagieren, nur um dann festzustellen, dass er mein Problem nicht versteht. Wenn LCMs sie antreiben, können Chatbots für den Kundensupport komplexe Situationen besser verstehen und vielleicht sogar kreativere Lösungen anbieten. Das kann zu einer höheren Kundenzufriedenheit und Kundenbindung führen.
Zurzeit werden LLMs in mehreren dieser Funktionen eingesetzt, aber sie sind nur begrenzt wirksam. LCMs haben das Potenzial, diese Anwendungen zu verbessern. Schon bald könnten unsere KI-Assistenten echten menschlichen Assistenten ähnlicher sein, die in der Lage sind, komplexeren Ideen und Gesprächen zu folgen - nur können sie viel schneller kommunizieren als wir.
LCMs bieten zwar spannende Möglichkeiten, aber sie bringen auch Herausforderungen in Bezug auf Datenanforderungen, Komplexität und Rechenkosten mit sich. Lass uns ein paar der größten aktuellen Herausforderungen besprechen.
Für das Training jedes KI-Modells werden große Datenmengen benötigt, aber LCMs haben im Vergleich zu LLMs zusätzliche Verarbeitungsschritte. Anstatt Rohtext zu verwenden, stützen sie sich auf Darstellungen auf Satzebene, d.h. der Text muss zunächst in Sätze zerlegt und dann in Einbettungen umgewandelt werden. Dies führt zu einer zusätzlichen Ebene der Vorverarbeitung und des Speicherbedarfs.
Außerdem erfordert das Training mit Hunderten von Milliarden Sätzen eine immense Rechenleistung.
LCMs verarbeiten ganze Sätze als einzelne Einheiten, was dazu beiträgt, den logischen Fluss aufrechtzuerhalten, aber die Fehlersuche erschwert.
LLMs erzeugen den Text wortweise, so dass wir Fehler auf einzelne Token zurückführen können. Im Gegensatz dazu arbeiten LCMs in einem hochdimensionalen Einbettungsraum, in dem Entscheidungen auf abstrakten Beziehungen beruhen.
LCMs, insbesondere diffusionsbasierte Modelle, benötigen viel mehr Rechenleistung als LLMs. Während LLMs den Text in einem Vorwärtsdurchlauf erzeugen, verfeinern diffusionsbasierte LCMs ihre Ergebnisse Schritt für Schritt, was sowohl die Rechenzeit als auch die Kosten erhöht. Während LCMs für lange Dokumente effizienter sein können, sind sie für kurze Aufgaben wie schnelle Antworten oder Chat-basierte Interaktionen oft weniger effizient.
Die Definition von Begriffen auf der Satzebene ist eine ganz eigene Herausforderung. Längere Sätze können mehrere Ideen enthalten, was es schwierig macht, sie als eine Einheit zu erfassen. Und kürzere Sätze bieten vielleicht nicht genug Kontext für eine sinnvolle Darstellung.
Auch bei LCMs gibt es Probleme mit spärlichen Daten. Da einzelne Sätze viel einzigartiger sind als Wörter, hat das Modell weniger wiederkehrende Muster, von denen es lernen kann.
Diese Technologie entwickelt sich rasant und diese Herausforderungen werden aktiv angegangen. Da diese Technologie quelloffen ist, kannst du deine eigenen Lösungen einbringen, um diese Herausforderungen zu meistern und die Technologie voranzubringen.
Bist du daran interessiert, die Arbeit mit einem LCM auszuprobieren? Ein großer Teil des Codes ist Open-Source, also kannst du genau das tun!
Ein guter Startpunkt ist der frei verfügbare LCM-Schulungscode und der SONAR-Einbettungsraum. Diese Open-Source-Tools ermöglichen es Entwicklern, mit dieser neuen Technologie zu experimentieren und ihre eigenen Verbesserungen vorzunehmen.
Um mehr über die Theorie hinter LCMs zu erfahren, schau dir dieses Papier von Meta.
Die Fähigkeit der LCMs, auf einer konzeptionellen Ebene zu arbeiten, hat das Potenzial, die Interaktion der KI mit der Sprache zu verbessern. Indem sie die Beschränkungen der Token-basierten Analyse überwinden, öffnen LCMs den Weg für nuanciertere, kontextbezogene und mehrsprachige Anwendungen.
Ich möchte dich ermutigen, den Code selbst auszuprobieren und dein eigenes Flair hinzuzufügen. Welche Verbesserungen kannst du an dieser Technologie vornehmen? Welche Produkte kannst du damit herstellen?
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Lernpfad
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
