
Track
Developing AI Applications
21 hr
For years, scaling AI models mostly meant adding more parameters and training data.
While this approach improves performance, it also significantly increases computational costs. Mixture of Experts (MoE) has emerged as a promising solution to address this challenge, using sparsely activated expert modules instead of traditional dense feed-forward layers.
MoE functions by delegating the tasks to different experts based on their expertise in the topic. Each expert is heavily trained on a specific dataset to serve a particular purpose, and another component, the gating network, is responsible for delegating these tasks.
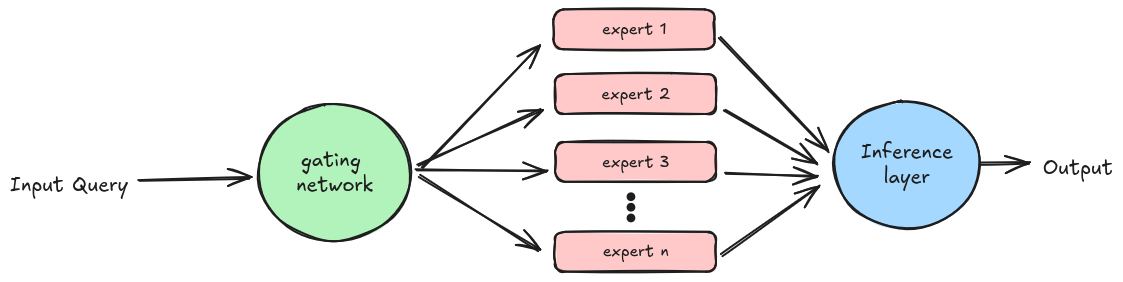
While MoE models outperform traditional models with Feed-Forward Layers, their efficiency can plateau as the model size grows due to the limitations of using a fixed number of training tokens.
Addressing this issue requires high-granularity architectures with a large number of experts. However, the only existing architecture supporting over ten thousand experts, the Mixture of Word Experts (MoWE), is language-specific and relies on a fixed routing scheme.
The Mixture of A Million Experts (MoME), introduced in this paper, tackles this challenge by introducing the Parameter Efficient Expert Retrieval (PEER) architecture, which employs product key retrieval for efficient routing to a vast number of experts.
One of the major challenges in scaling LLMs lies in the computational and memory demands of feedforward layers within transformer blocks. MoE addresses this by replacing these layers with sparsely activated expert modules, each specializing in different aspects of the task. This approach enhances efficiency by activating only relevant experts for a given input, reducing computational overhead.
Current approaches to MoE have limitations, such as fixed routers that need to be readjusted when new experts are added. So, a new approach to routing is introduced, replacing the fixed router with a learned index.
Parameter Efficient Expert Retrieval (PEER) reduces the number of active parameters in the MoE layer, affecting computation and activation memory consumption during pre-training and inference.
PEER demonstrates that by applying the right retrieval and routing mechanisms, MoE can be scaled to millions of experts, reducing the cost and complexity of training and serving very large language models.
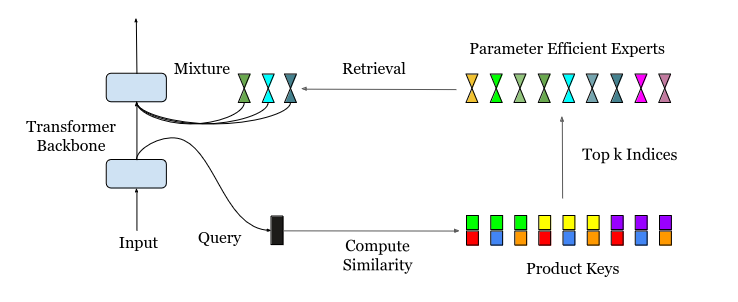
In the diagram above, the input query initially undergoes product key retrieval to identify the top k experts. These selected experts then process the input based on their specialized knowledge, and their outputs are combined during the inference phase to generate the final model output.
PEER's core innovation is the use of product key retrieval. The goal remains the same as in traditional MoE: finding the top k experts best suited for the given task. However, with a vast number of experts (potentially exceeding a million), the previous techniques become computationally expensive or inefficient.
Consider a scenario with N experts, each represented by a d-dimensional vector. Computing the top k experts directly would involve calculating the similarity between the input query and all N expert keys, resulting in a time complexity of O(Nd). When N is very large (e.g., N ≥ 10^6), this becomes prohibitively expensive.
PEER addresses this by employing a clever strategy: instead of using N independent d-dimensional expert keys, it splits each key into two independent subsets, each with dimensionality d/2. Similarly, the query vector is divided into two sub-queries. The top-k operation is then applied to the inner products between these sub-queries and sub-keys.
This Cartesian product structure of the keys dramatically reduces the computational complexity from O(Nd) to O((N^.5+ k2)d), making it feasible to efficiently identify the top k experts even with a massive number of experts.
The Parameter-Efficient Expert Retrieval (PEER) layer is an MoE architecture that uses product keys in the router and single-neuron MLPs as experts.
A PEER layer consists of three components:
Here is how it works:
In essence, the PEER layer efficiently identifies the most relevant experts for a given input, allowing for the effective utilization of a massive number of experts while maintaining computational tractability. This innovation is a key enabler for scaling MoE models to millions of experts, paving the way for more powerful and efficient LLMs.
PEER, in conjunction with the MoME architecture, offers several compelling advantages over traditional MoE approaches, pushing the boundaries of LLM capabilities:
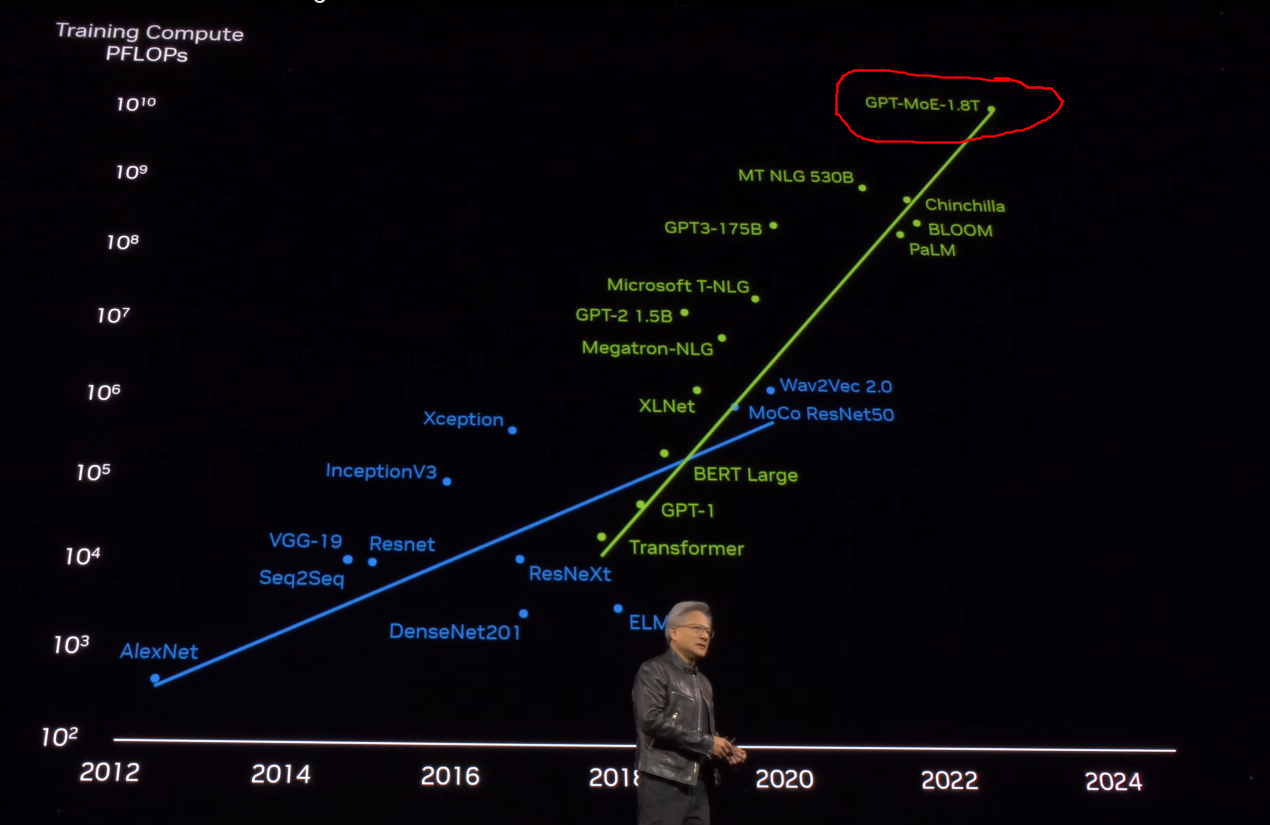
Mixture-of-Experts is already a widely used model paradigm in the industry, with companies like YouTube integrating it into their recommendation system. The future of MoME looks similar, and it was already hinted at in Nvidia's GTC 2024, when they talked about GPT’s 1.8 trillion model.
Mixture of Million Experts (MoME), with its PEER architecture, shows particular promise for complex NLP tasks requiring a broad knowledge base and rapid response retrieval. It addresses the scalability challenges inherent in training and serving very large language models, opening up new possibilities for their use in domains like computer vision, content generation, recommendation systems, and smart computing.
Scaling a model up to a million experts seems promising from an efficiency point of view but managing such a large network poses its challenges. Let’s explore some of them:
In this article, we explored the Mixture of Million Experts (MoME) technique, a scalable approach for large language models.
MoME leverages specialized expert networks and the PEER routing mechanism to improve efficiency and performance.
We discussed its core components, benefits, and potential applications. For a deeper dive, refer to the research paper for technical details and benchmark results.
For more information, refer to the research paper for technical details and benchmark results.
Develop AI applications!
Track
Course
Course
blog
Bhavishya Pandit
8 min
blog
Zoumana Keita
13 min
blog
Dimitri Didmanidze
14 min
blog
Andrea Valenzuela
15 min
blog
Stanislav Karzhev
10 min
Tutorial
Bex Tuychiev

