Programa
Desenvolvimento de aplicativos de IA
21 h
Durante anos, o dimensionamento de modelos de IA significava principalmente adicionar mais parâmetros e dados de treinamento.
Embora essa abordagem melhore o desempenho, ela também aumenta significativamente os custos computacionais. A mistura de especialistas (MoE) surgiu como uma solução promissora para enfrentar esse desafio, usando módulos de especialistas ativados de forma esparsa em vez das tradicionais camadas densas de feed-forward.
O MoE funciona delegando as tarefas a diferentes especialistas com base em seus conhecimentos sobre o assunto. Cada especialista é altamente treinado em um conjunto de dados específico para atender a uma finalidade específica, e outro componente, a rede de gating, é responsável por delegar essas tarefas.
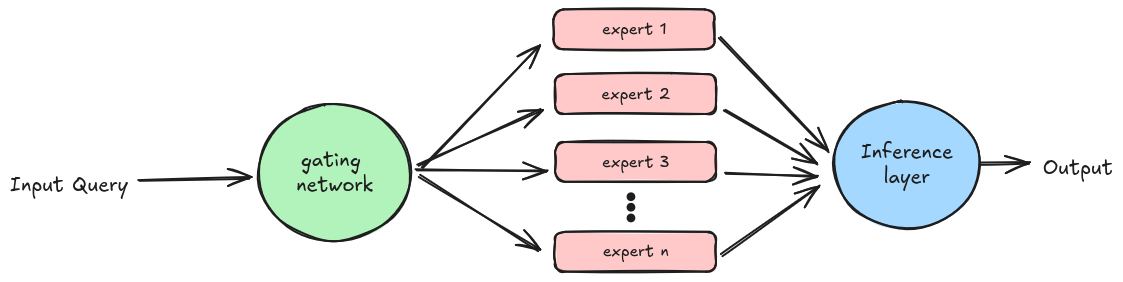
Embora os modelos MoE superem os modelos tradicionais com camadas feed-forward, sua eficiência pode atingir um patamar à medida que o tamanho do modelo aumenta devido às limitações do uso de um número fixo de tokens de treinamento.
Para resolver esse problema, são necessárias arquiteturas de alta granularidade com um grande número de especialistas. No entanto, a única arquitetura existente que suporta mais de dez mil especialistas, a Mixture of Word Experts (MoWE)é específica do idioma e depende de um esquema de roteamento fixo.
O Mistura de um milhão de especialistas (MoME)introduzida neste este artigoaborda esse desafio introduzindo o Recuperação de Especialistas com Eficiência de Parâmetros (PEER) que emprega a recuperação de chave de produto para roteamento eficiente para um grande número de especialistas.
Um dos maiores desafios no dimensionamento de LLMs está nas demandas computacionais e de memória das camadas de alimentação dentro dos blocos de transformadores. O MoE resolve isso substituindo essas camadas por módulos de especialistas ativados de forma esparsa, cada um especializado em diferentes aspectos da tarefa. Essa abordagem aumenta a eficiência ativando apenas os especialistas relevantes para uma determinada entrada, reduzindo a sobrecarga computacional.
As abordagens atuais do MoE têm limitações, como roteadores fixos que precisam ser reajustados quando novos especialistas são adicionados. Assim, uma nova abordagem de roteamento é introduzida, substituindo o roteador fixo por um índice aprendido.
O PEER (Parameter Efficient Expert Retrieval) reduz o número de parâmetros ativos na camada MoE, afetando o consumo de memória de computação e ativação durante o pré-treinamento e a inferência.
O PEER demonstra que, com a aplicação dos mecanismos corretos de recuperação e roteamento, o MoE pode ser dimensionado para milhões de especialistas, reduzindo o custo e a complexidade do treinamento e da utilização de modelos de idiomas muito grandes.
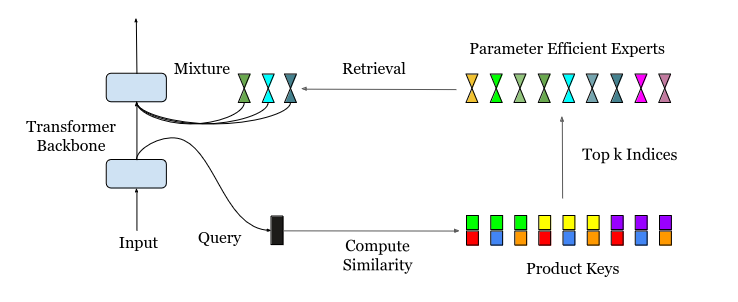
No diagrama acima, a consulta de entrada é inicialmente submetida à recuperação da chave do produto para identificar os kprincipais especialistas do site. Em seguida, esses especialistas selecionados processam a entrada com base em seu conhecimento especializado, e seus resultados são combinados durante a fase de inferência para gerar o resultado final do modelo.
A principal inovação do PEER é o uso da recuperação da chave do produto. O objetivo continua sendo o mesmo do MoE tradicional: encontrar os k melhores especialistas mais adequados para uma determinada tarefa. No entanto, com um grande número de especialistas (potencialmente superior a um milhão), as técnicas anteriores se tornam computacionalmente caras ou ineficientes.
Considere um cenário com N especialistas, cada um representado por um vetord-dimensional. A computação dos principais k especialistas diretamente envolveria o cálculo da similaridade entre a consulta de entrada e todas as N chaves de especialistas, resultando em uma complexidade de tempo de O(Nd). Quando N é muito grande (por exemplo, N ≥ 10^6), isso se torna proibitivamente caro.
O PEER resolve isso empregando uma estratégia inteligente: em vez de usar N chaves especializadas independentes de dimensão d, ele divide cada chave em dois subconjuntos independentes, cada um com dimensionalidade d/2. Da mesma forma, o vetor de consulta é dividido em duas subconsultas. A operação top-k é então aplicada aos produtos internos entre essas subconsultas e subchaves.
Essa estrutura de produto cartesiano das chaves reduz drasticamente a complexidade computacional de O(Nd) para O((N^.5+ k2)d), tornando viável a identificação eficiente dos k melhores especialistas, mesmo com um grande número de especialistas.
A camada Parameter-Efficient Expert Retrieval (PEER) é uma arquitetura MoE que usa chaves de produto no roteador e MLPs de neurônio único como especialistas.
Uma camada PEER consiste em três componentes:
Veja como isso funciona:
Essencialmente, a camada PEER identifica de forma eficiente os especialistas mais relevantes para uma determinada entrada, permitindo a utilização efetiva de um grande número de especialistas e mantendo a capacidade de processamento computacional. Essa inovação é um facilitador essencial para o dimensionamento de modelos de MoE para milhões de especialistas, abrindo caminho para LLMs mais poderosos e eficientes.
O PEER, em conjunto com a arquitetura do MoME, oferece várias vantagens atraentes em relação às abordagens tradicionais do MoE, ampliando os limites dos recursos do LLM:
O Mixture-of-Experts já é um paradigma de modelo amplamente utilizado no setor, com empresas como o YouTube integrando-o ao seu sistema de recomendação. O futuro do MoME parece semelhante e já foi sugerido no GTC 2024 da Nvidia, quando eles falaram sobre o modelo de 1,8 trilhão da GPT.
O Mixture of Million Experts (MoME), com sua arquitetura PEER, é particularmente promissor para tarefas complexas de NLP que exigem uma ampla base de conhecimento e recuperação rápida de respostas. Ele aborda os desafios de dimensionamento inerentes ao treinamento e ao fornecimento de modelos de linguagem muito grandes, abrindo novas possibilidades para seu uso em domínios como visão computacional, geração de conteúdo, sistemas de recomendação e computação inteligente.
O dimensionamento de um modelo para até um milhão de especialistas parece promissor do ponto de vista da eficiência, mas o gerenciamento de uma rede tão grande apresenta seus desafios. Vamos explorar alguns deles:
Neste artigo, exploramos a técnica Mixture of Million Experts (MoME), uma abordagem dimensionável para grandes modelos de linguagem.
O MoME aproveita as redes de especialistas especializados e o mecanismo de roteamento PEER para melhorar a eficiência e o desempenho.
Discutimos seus principais componentes, benefícios e possíveis aplicações. Para se aprofundar no assunto, consulte o documento de pesquisa para obter detalhes técnicos e resultados de benchmark.
Para obter mais informações, consulte o artigo de pesquisa para obter detalhes técnicos e resultados de benchmark.
Desenvolva aplicativos de IA!
Programa
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Javier Canales Luna
8 min
blog
Nisha Arya Ahmed
12 min
blog
Abid Ali Awan
8 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita