
Track
Data Manipulation in Python
16 hr
With the increasing volume, variety, and velocity of data, focusing on building quality and well-structured datasets has become more critical than ever, as they directly influence the accuracy of insights and the effectiveness of decisions across industries.
Poorly organized or flawed data can lead to misguided conclusions, costing time, money, and resources. This is where data wrangling steps in as the essential process that ensures raw, unstructured data is transformed into a clean, organized format ready for analysis.
Data wrangling involves a series of steps to ensure that it is accurate, reliable, and tailored to meet the specific needs of the analysis at hand. By mastering data wrangling, you can unlock the full potential of your data, turning it into actionable insights that drive informed decisions and ultimately lead to success.
Data wrangling is the process of transforming raw data into a more usable format. This involves cleaning, structuring, and enriching data so that it’s ready for analysis.
Imagine you’ve just received a huge dataset—it’s messy, with missing values, inconsistencies, and irrelevant information. Data wrangling is like a toolkit that helps you tidy up this data, ensuring it’s organized and consistent.
Data wrangling is important for ensuring that your data is high quality and well-structured, which is crucial for accurate data analysis. Clean, structured data serves as the foundation for all subsequent steps in the data workflow—whether you’re building a machine learning model, generating visualizations, or performing statistical analysis.
High-quality data reduces the risk of errors and biases in your analysis, leading to more reliable insights. Understanding the importance of data wrangling is key, as it directly impacts the validity of the decisions made based on that data.
Poorly wrangled data can lead to flawed conclusions, which can have significant consequences in real-world applications. Therefore, mastering data wrangling is essential for anyone serious about making data-driven decisions.
There are 5 main steps to data wrangling:
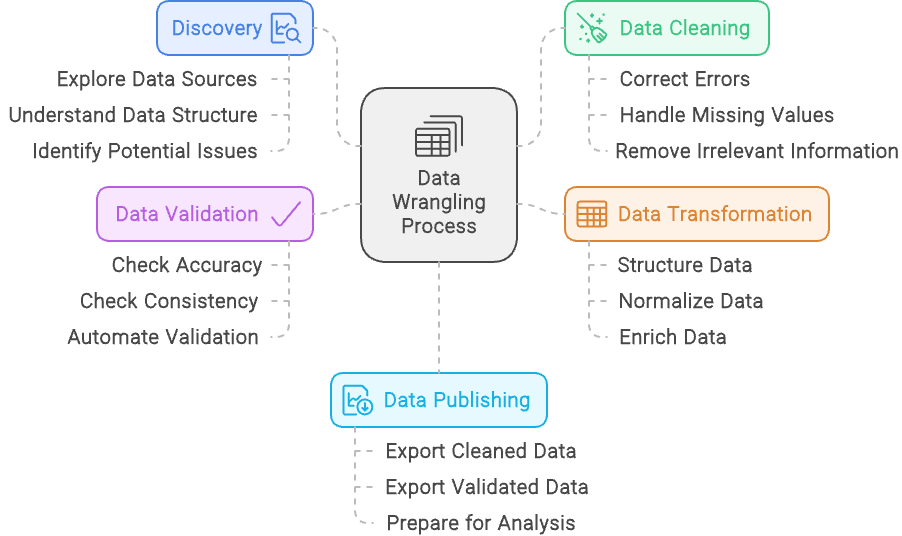
The data wrangling process - created with Napkin.ai
We’ve outlined the five steps of data wrangling, but let’s look at each one in more detail:
The discovery step in data wrangling is like taking a first look at a puzzle before you start putting the pieces together. It involves examining the dataset to get a clear sense of what you’re working with, including understanding the types of data, its sources, and how it’s structured.
Just as you might sort puzzle pieces by color or edge shape, discovery helps you categorize and recognize patterns in the data, setting the stage for the work ahead.
But discovery is also about spotting potential problems—like missing pieces or mismatched colors in a puzzle.
During this step, you identify any issues in the data, such as inconsistencies, missing values, or unexpected patterns. By uncovering these challenges early on, you can plan how to address them in the subsequent steps of data wrangling, ensuring a smoother path to a clean, usable dataset.
Data cleaning involves refining your dataset to ensure it’s accurate and reliable.
This process includes addressing issues such as correcting errors, handling missing values, and fixing inconsistencies. For example, if your dataset contains duplicate entries for the same individual or transaction, data cleaning would involve removing these duplicates to avoid skewing results.
Additionally, if you find that some entries are misformatted, like phone numbers with varying formats, you would standardize them to a consistent format. The goal is to enhance the overall quality and integrity of the data, making it ready for accurate and meaningful analysis.
Data transformation is the process of modifying and enhancing your dataset to better align with the requirements of your analysis. This step involves structuring the data, such as reshaping it to fit the desired format or combining multiple sources into a cohesive structure.
Normalizing data is another key aspect, which means adjusting values to a common scale or format, like converting all currency values to a single currency or standardizing units of measurement.
Additionally, data transformation includes enriching the dataset by adding new variables or integrating external data sources to provide more context or insights. For example, you might calculate new metrics based on existing data or append additional information from other databases to provide a fuller picture.
The aim of data transformation is to prepare the data in a way that enhances its usability and relevance for in-depth analysis.
Data validation involves ensuring the accuracy and reliability of your dataset through systematic checks and automated processes. This step is critical for confirming that the data is both correct and consistent.
During data validation, you perform various checks to identify any discrepancies, such as comparing data against known benchmarks or validating against predefined rules and constraints. Automated processes might include running scripts that flag anomalies or inconsistencies, ensuring that the data adheres to expected formats and ranges.
The goal of data validation is to catch any issues before the data is used for analysis, preventing errors from impacting the results. By rigorously verifying data accuracy and reliability, you ensure that the insights drawn from the data are based on trustworthy information.
Data publishing is the final step in the data wrangling process, where the cleaned and structured data is made available for analysis and decision-making. This step involves preparing the data for dissemination, often by creating dashboards, reports, or interactive visualizations that make it accessible and understandable to stakeholders.
During data publishing, you might set up data pipelines or interfaces that allow users to query and interact with the data, ensuring that it’s delivered in a format that meets their needs.
The goal is to provide clear, actionable insights from the data, enabling informed decision-making and facilitating communication of findings across the organization. By effectively publishing the data, you ensure that the hard work of data wrangling translates into meaningful and practical outcomes.
The terms data wrangling and data cleaning are often used interchangeably, but they refer to different aspects of the data preparation process. While both are essential for preparing data for analysis, they serve distinct purposes and involve different tasks. Understanding the difference between them helps clarify their roles and ensures that each aspect of data preparation is handled effectively.
Data Wrangling is a comprehensive process that involves transforming raw data into a format suitable for analysis. It encompasses several stages, including acquiring the data, structuring it, cleaning it, and validating it. The goal of data wrangling is to prepare data from diverse sources so it can be effectively analyzed and used to generate insights. This process ensures that data is organized, accurate, and ready for detailed analysis.
Data Cleaning, on the other hand, is a specific subset of data wrangling. It focuses solely on improving the quality of the data by addressing and correcting errors and inconsistencies. This includes tasks such as removing duplicate records, correcting typos, handling missing values, and standardizing data formats. While data cleaning is a crucial part of data wrangling, it is just one step in the broader process.
Put simply, data wrangling is the overall framework that prepares data for analysis, including multiple steps to handle various aspects of data preparation. Data cleaning is an integral component of this framework, dedicated specifically to enhancing the accuracy and consistency of the data.
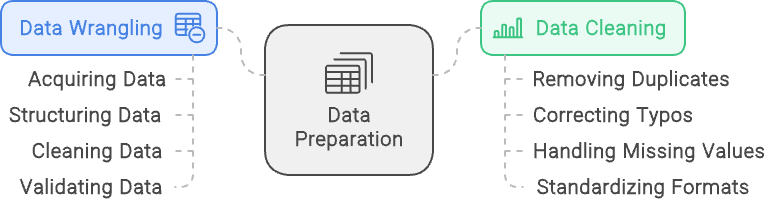
Data Wrangling vs Data Cleaning: Data Wrangling focuses on structuring and validating data whereas Data Cleaning focuses on ensuring clean and quality data is available. Image created with napkin.ai
There are many ways to wrangle data, either through the usage of fundamental GUI-based tools such as Excel or Alteryx and through coding with languages such as R and Python. We will explore a few options here.
For simple data wrangling tasks, spreadsheets like Microsoft Excel and Google Sheets are often the go-to options. These tools are highly accessible and provide a familiar interface, making them ideal for tasks like sorting, filtering, and basic data cleaning. Spreadsheets are particularly useful for smaller datasets or for those who are just starting to learn about data wrangling.
With built-in functions and formulas, they allow users to quickly perform calculations and manipulate data without requiring extensive technical knowledge.
For more complex data manipulation and automation, programming languages like Python and R are widely used. Python, with its powerful libraries such as Pandas, NumPy, and OpenRefine, is excellent for handling large datasets and performing intricate data transformations.
R, with packages like dplyr and tidyr, is another strong option, particularly favored in the statistical and academic communities for its robust data analysis capabilities. Both languages offer a high degree of flexibility, allowing users to script custom workflows and automate repetitive tasks, making them ideal for data practitioners working with more sophisticated data wrangling needs.

Our Data Wrangling in Pandas Cheat Sheet can help you master many of the basics
Dedicated software tools are specifically designed to streamline the data wrangling process, offering advanced features that simplify complex data tasks. These tools are ideal for users who need powerful, yet accessible, solutions to clean, structure, and prepare data for analysis without the need for extensive coding.
Alteryx is a leading tool in this category, known for its intuitive drag-and-drop interface that allows users to easily cleanse, blend, and transform data from multiple sources. It comes equipped with a variety of built-in tools for data manipulation, making it straightforward to perform tasks like filtering, joining, and aggregating data.
The cloud-based Alteryx Designer Cloud further enhances these capabilities by providing a scalable, collaborative platform for data wrangling. This solution allows teams to work together in real-time, handling large datasets and complex workflows efficiently across different environments. Whether used on-premises or in the cloud, Alteryx ensures that data is accurately prepared and ready for insightful analysis.
For comprehensive data projects that require end-to-end solutions, integrated platforms like KNIME, Apache NiFi, and Microsoft Power BI are often used. These platforms not only support data wrangling but also provide tools for data integration, analysis, and visualization within a single environment.
KNIME, for example, is known for its modular, node-based interface that allows users to build complex workflows visually. Apache NiFi excels in managing and automating data flows between systems, while Power BI combines data preparation with powerful visualization capabilities. These platforms are ideal for projects where data needs to be seamlessly prepared, analyzed, and shared, offering a holistic approach to data-driven decision-making.
There are many options when it comes to data wrangling with Python. Two main packages utilized are Pandas and NumPy. These two packages have powerful tools that allow users to easily perform key data wrangling techniques on their datasets.
So much data processing happens in Python so mastering these packages will be essential for any data practitioner. While there are many techniques, some key things to know are how to perform high-level data cleaning (dropping nulls, for example), merging datasets, and handling missing values.
There are many occasions where data needs to be cleaned in Python before being utilized. This could involve things like removing trailing whitespaces from strings, dropping null values, or correcting data types to name a few.
Each dataset is different and will have its own needs so explore your dataset to understand if additional cleaning is required. Practicing various techniques and coding skills is a great way to learn all the different ways we can clean data in Python.
When it comes to cleaning up strings, one of the many issues is trailing/leading white space. This can cause issues when trying to parse strings based on length, location, or matching. The best way to handle something like this is to use the str.strip() method on a series.
# Example utilizes a pandas series
# If working with a dataframe, call the series using df[col] syntax
s = pd.Series(['1. Ant. ', '2. Bee!\n', '3. Cat?\t', np.nan, 10, True])
# It is important to include the .str or else the method will not work
s.str.strip()Dropping null values in Pandas is easy. We will discuss how to fill in null values later in this article. You can simply use the dropna() method. There are optional parameters in this method which allow you to choose the exact conditions that will drop a row/column but the default behavior is to drop any row with any null values
# For any dataframe
df = pd.DataFrame({"name": ['Alfred', 'Batman', 'Catwoman'],
"toy": [np.nan, 'Batmobile', 'Bullwhip'],
"born": [pd.NaT, pd.Timestamp("1940-04-25"), pd.NaT]}
df.dropna()The method .astype() allows users to change the datatype of a series, but correcting data types is a little trickier as you have to make sure that every value in your Pandas series matches that data type.
For instance, converting a series that is an object to an integer means you know that every value is an integer. If there is a single value that isn’t an integer, it will cause the method to error out. You can choose to coerce it by making invalid values null but it may be more worthwhile to investigate while certain values are not being converted.
Merging DataFrames in Pandas is similar to joining in SQL. The default behavior of a Pandas merge() is to perform an inner join. However, it will join on nulls so be careful. Performing a merge requires you to utilize a particular key. You can join on a variety of columns or even the index.
# Create two dataframes
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],
'value': [1, 2, 3, 5]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]})
# merge the df1 DataFrame to the df2 DataFrame using the columns key and rkey as keys
df1.merge(df2, left_on='lkey', right_on='rkey')The above code will merge the two DataFrames based on matching keys in their respective lkey and rkey columns. Unmatched values will be dropped and you are left with only the matched values. However, you can change the merge behavior and choose a left/right/outer merge as well. This is a powerful tool for allowing data scientists to bring together different datasets from various data sources.
When it comes to missing values, the exact methodology can vary based on the business case. When we talk about missing values, we must consider why the value is missing. If the value is missing due to technical errors, maybe we should focus on fixing the technical error before analyzing our data and see if we can’t recover historical data.
Sometimes, we can use the rest of the data and simply ignore the missing value. If historical data is important and unrecoverable, we must fill in the missing data. Let's discuss how to fill in missing information.
The main method for filling in data is to use the fillna() method from Pandas. For string values, this method can be used to fill in those nulls for example: df.fillna(value=’missing’) which may be enough! The joy of this method is we can get creative. By combining the Pandas fillna() method with a variety of NumPy methods such as mean() , median(), and lambda functions, we can mathematically fill in our missing values.
Alternatively, there even exists Pandas methods such as interpolate() which can algorithmically fill in gaps if your data is ordered (e.g. time-based). The goal is to fill the data as accurately as possible so that it reflects the real data.
Performing data wrangling in SQL can be an effective way of processing your data especially if your SQL database is on the cloud. This limits the amount of data processed by your local machine and the amount of data egress/ingress over networks.
The main focus of data wrangling in SQL is limiting the scope of data flowing through our pipelines through proper data extraction, transformation, and loading. Some ways we manage that is filtering data, joining to reference tables, and performing aggregations.
The primary way we filter tables in SQL is using the WHERE clause. It is fairly straightforward to use but can be extraordinarily powerful. The conditions can be simple equality statements, looking for similar strings, or even utilizing other subqueries. You can combine multiple where clauses using AND and OR statements as well!
Filtering based on simple cases such as looking for a particular value of a column can look something like this:
SELECT *
FROM sample_table
WHERE sample_col = 23Using more complex statements such as LIKE or IN can provide flexibility to your WHERE clauses. For example, the following query looks for people whose name starts with J thanks to the % wildcard and also whose last name is IN the list provided.
SELECT *
FROM sample_table
WHERE name LIKE ‘J%’ /* looks for people whose name starts with J */
AND last_name IN (‘Smith’, ‘Rockefeller’, ‘Williams’) /* Looks for people whose last name is in this list */Finally, something like using other subqueries can lend flexibility to your filtering. It can be based on the results of another table. One common example, is finding a list of customer IDs after a particular datetime.
SELECT *
FROM sample_table
WHERE customer_id IN (SELECT id FROM reference_table WHERE date >= ‘2024-01-01’)Using a combination of these techniques ensures that your data inputs are exactly what you are looking for and dataset sizes can be minimized. One extra powerful usage of filters is removing duplicates in your dataset and cleaning it up that way. Some more advanced techniques to implement are HAVING filters for aggregations and QUALIFY statements with window functions.
Performing table joins allows us to gather extra information we might need for our datasets. SQL has a variety of joins such as INNER, OUTER, LEFT, and RIGHT. With INNER and OUTER joins, we determine what data is kept. INNER joins keep data only if there is a match on both sides whereas OUTER keeps data that is also not matched depending on which side we are joining from (left or right).
The LEFT join keeps data on the left side of the join and RIGHT join keeps data on the right side of the join. You combine LEFT and RIGHT joins with INNER and OUTER joins as well as the special FULL OUTER JOIN which simply joins all data from both tables.
An example join might be:
SELECT *
FROM a
LEFT OUTER JOIN
b
WHERE a.id = b.idThe above statement has table a on the left since it is first and table b on the right since it is second. The LEFT OUTER JOIN says, join the data from table a and table b where a.id = b.id, but if there is no match keep all the data from table a. Joins are powerful tools for bringing in extra data that might be necessary for your data input.
One final tool we could utilize in SQL for data wrangling is the GROUP BY clause to perform aggregations. This simplifies the data and allows us to pre-process the data somewhat prior to sending it further down the pipeline. Aggregation is a powerful tool to calculate summary statistics. Here is an example where we are looking at the total sales by customer ID.:
SELECT
Customer_ID,
SUM(sales)
FROM sample_table
GROUP BY Customer_IDThere are numerous aggregation functions such as SUM, MEAN, MAX, and MIN which allow us to quickly and easily get an understanding of our data. Taking advantage of aggregations simplifies data ingress to pipelines.
This section will cover some practical examples and use cases for data wrangling techniques. The main goals we will focus on are: standardizing data, merging data sources, and text processing.
Standardizing data into the same units is important. If working with data that is measuring the same thing in different units or currency difference then it could cause issues with analysis.
We will cover a simple example of converting different currencies to USD in SQL. First, let's assume we have two tables. Table 1 is a sales table which has product sales for various regions and Table 2 is currency_exchange table which contains the exchange rate for various regions for various days. An example of this conversion may look like:
SELECT
a.sale_id,
a.region,
CASE WHEN region <> ‘US’
THEN a.sale_price * b.exchange_rate
ELSE a.sale_price
END AS sale_price
FROM sales AS a
LEFT OUTER JOIN
currency_exchange AS b
WHERE a.region = b.regionThis takes the sale_id and region from the sales table and joins to the reference currency_exchange table on the region so that we can get the exchange rate. Oftentimes, there may be a date involved so that we can get the currency exchange rate of the day.
One major portion of data wrangling is processing data for our machine learning models. Recently, many models have been focused on natural language processing and one precursor to that is sentiment analysis through text data.
A critical step of this is the preparation of text by normalization and removal of punctuation. Since punctuation and capitalization may not provide important context to a machine learning model, it is often better to normalize.
To do this, we will utilize basic Python packages and the re package. See below for an example of removing punctuation, normalizing text to remove capitalization, and trimming empty space.
# import regex
import re
# input string
test_string = " Python 3.0, released in 2008, was a major revision of the language that is not completely backward compatible and much Python 2 code does not run unmodified on Python 3. With Python 2's end-of-life, only Python 3.6.x[30] and later are supported, with older versions still supporting e.g. Windows 7 (and old installers not restricted to 64-bit Windows)."
# remove whitespaces
no_space_string = test_string.strip()
# convert to lower case
lower_string = no_space_string .lower()
# remove numbers
no_number_string = re.sub(r'\d+','',lower_string)
print(no_number_string)The above code snippet provides a great foundation for removing whitespace, converting characters to all lowercase, and removing numbers/non-alphabetical data.
Data wrangling is a critical component of preparing our data for machine learning models and analysis. There are a multitude of tools in Python such as the pandas and numpy packages alongside a variety of SQL methods such as WHERE and GROUP BY clauses that allow us to prepare our data.
Mastery of these techniques is critical for any aspiring data professional to succeed in the profession. If you want to dive deeper into the topics of data wrangling, consider the following resources:
Top DataCamp Courses
Track
Course
Course
blog
Matt Crabtree
10 min
blog
Matt Crabtree
15 min
blog
Kurtis Pykes
15 min
cheat-sheet
Karlijn Willems
Tutorial
DataCamp Team
Tutorial
Laiba Siddiqui



