
programa
Procesamiento del lenguaje natural en Python
20 h
Los avances científicos rara vez se producen en el vacío. Por el contrario, a menudo son el penúltimo peldaño de una escalera construida sobre el conocimiento humano acumulado. Para entender el éxito de los grandes modelos lingüísticos (LLM), como ChatGPT y Google Bart, tenemos que retroceder en el tiempo y hablar del BERT.
Desarrollado en 2018 por investigadores de Google, BERT es uno de los primeros LLM. Con sus asombrosos resultados, se convirtió rápidamente en una línea de base omnipresente en las tareas de PNL, como la comprensión general del lenguaje, las preguntas y respuestas y el reconocimiento de entidades con nombre.
¿Te interesa saber más sobre los LLM? Empieza hoy mismo el Capítulo 1 de nuestro curso Conceptos de los grandes modelos lingüísticos (LLM).
Es justo decir que BERT allanó el camino para la revolución de la IA generativa que estamos presenciando estos días. A pesar de ser uno de los primeros LLM, el BERT se sigue utilizando ampliamente, con miles de modelos BERT de código abierto, gratuitos y preentrenados disponibles para casos de uso específicos, como el análisis de sentimientos, el análisis de notas clínicas y la detección de comentarios tóxicos.
¿Tienes curiosidad por BERT? Sigue leyendo el artículo, donde exploraremos la arquitectura de Ber, el funcionamiento interno de la tecnología, algunas de sus aplicaciones en el mundo real y sus limitaciones.
BERT (siglas de Bidirectional Encoder Representations from Transformers) es un modelo de código abierto desarrollado por Google en 2018. Se trataba de un ambicioso experimento para probar el rendimiento del llamado transformador -una innovadora arquitectura neuronal presentada por los investigadores de Google en el famoso artículo Attention is All You Need en 2017- en tareas de lenguaje natural (PLN).
La clave del éxito del BERT es su arquitectura de transformadores. Antes de que aparecieran los transformadores, modelar el lenguaje natural era una tarea muy difícil. A pesar del auge de las redes neuronales sofisticadas -en concreto, las redes neuronales recurrentes o convolucionales-, los resultados sólo fueron parcialmente satisfactorios.
El principal reto reside en el mecanismo que utilizan las redes neuronales para predecir la palabra que falta en una frase. Por aquel entonces, las redes neuronales más avanzadas se basaban en la arquitectura codificador-decodificador, un mecanismo potente pero que consume mucho tiempo y recursos, y que no es adecuado para la computación paralela.
Teniendo en cuenta estos retos, los investigadores de Google desarrollaron el transformador, una arquitectura neuronal innovadora basada en el mecanismo de la atención, como se explica en la sección siguiente.
Veamos cómo funciona el BERT, la tecnología que hay detrás del modelo, cómo se entrena y cómo procesa los datos.
Las redes neuronales recurrentes y convolucionales utilizan el cálculo secuencial para generar predicciones. Es decir, pueden predecir qué palabra seguirá a una secuencia de palabras dadas una vez entrenadas en enormes conjuntos de datos. En ese sentido, se consideraron algoritmos unidireccionales o libres de contexto.
En cambio, los modelos impulsados por transformadores como el BERT, que también se basan en la arquitectura codificador-decodificador, son bidireccionales porque predicen las palabras basándose en las palabras anteriores y en las siguientes. Esto se consigue mediante el mecanismo de autoatención, una capa que se incorpora tanto en el codificador como en el descodificador. El objetivo de la capa de atención es captar las relaciones contextuales existentes entre las distintas palabras de la frase de entrada.
Hoy en día, hay muchas versiones de BERT preentrenadas, pero en el artículo original, Google entrenó dos versiones de BERT: BERTbase y BERTlarge con diferentes arquitecturas neuronales. En esencia, BERTbase se desarrolló con 12 capas de transformación, 12 capas de atención y 110 millones de parámetros, mientras que BERTlarge utilizó 24 capas de transformación, 16 capas de atención y 340 millones de parámetros. Como era de esperar, BERTlarge superó a su hermano pequeño en las pruebas de precisión.
Para conocer en detalle cómo funciona la arquitectura codificador-decodificador en los transformadores, te recomendamos encarecidamente que leas nuestra Introducción al uso de transformadores y Cara de abrazo.
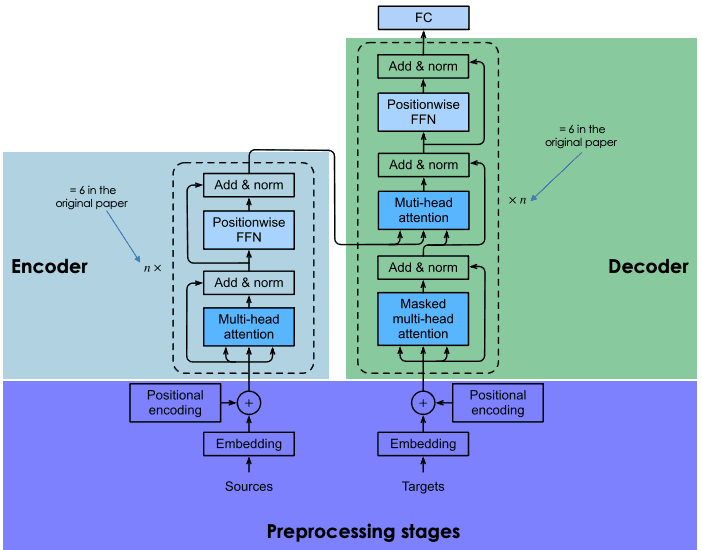
Explicación de la arquitectura de los transformadores
Los transformadores se entrenan desde cero en un enorme corpus de datos, siguiendo un proceso largo y costoso (que sólo un grupo limitado de empresas, entre ellas Google, pueden permitirse).
En el caso de BERT, se preentrenó durante cuatro días en Wikipedia (~2,5B de palabras) y en el BooksCorpus de Google (~800M de palabras). Esto permite que el modelo adquiera conocimientos no sólo en inglés, sino también en muchas otras lenguas de todo el mundo.
Para optimizar el proceso de entrenamiento, Google desarrolló un nuevo hardware, la llamada TPU (Unidad de Procesamiento Tensorial), diseñada específicamente para tareas de aprendizaje automático.
Para evitar interacciones innecesarias y costosas en el proceso de entrenamiento, los investigadores de Google utilizaron técnicas de aprendizaje por transferencia para separar la fase de (pre)entrenamiento de la fase de ajuste. Esto permite a los desarrolladores elegir modelos preentrenados, refinar los datos del par entrada-salida de la tarea objetivo y volver a entrenar la cabeza del modelo preentrenado utilizando datos específicos del dominio. Esta característica es lo que hace que los LLM como BERT sean el modelo base de un sinfín de aplicaciones construidas sobre ellos,
El elemento clave para lograr el aprendizaje bidireccional en el BERT (y en todo LLM basado en transformadores) es el mecanismo de atención. Este mecanismo se basa en el modelado del lenguaje enmascarado (MLM). Al enmascarar una palabra de una frase, esta técnica obliga al modelo a analizar las palabras restantes en ambas direcciones de la frase para aumentar las posibilidades de predecir la palabra enmascarada. La MLM se basa en técnicas ya probadas en el campo de la visión por ordenador, y es estupenda para tareas que requieren una buena comprensión contextual de toda una secuencia.
El BERT fue el primer LLM en aplicar esta técnica. En concreto, durante el entrenamiento se enmascaró un 15% aleatorio de las palabras tokenizadas. El resultado muestra que el BERT podía predecir las palabras ocultas con gran precisión.
¿Tienes curiosidad por el modelado lingüístico enmascarado? Consulta nuestro Curso de Conceptos de Grandes Modelos Lingüísticos (LLMs ) para conocer todos los detalles sobre esta innovadora técnica.
Impulsado por transformadores, el BERT fue capaz de lograr resultados de vanguardia en múltiples tareas de PNL. Éstas son algunas de las pruebas en las que BERT destaca:
Se han probado muchos LLM en conjuntos experimentales, pero no muchos se han incorporado a aplicaciones bien establecidas. No es el caso del BERT, que utilizan a diario millones de personas (aunque no seamos conscientes de ello).
Un gran ejemplo es la Búsqueda en Google. En 2020, Google anunció que había adoptado el BERT a través de la Búsqueda de Google en más de 70 idiomas. Esto significa que Google utiliza BERT para clasificar el contenido y mostrar fragmentos destacados. Con el mecanismo de atención, Google puede ahora utilizar el contexto de tu pregunta para proporcionar información útil, como se muestra en el ejemplo siguiente.
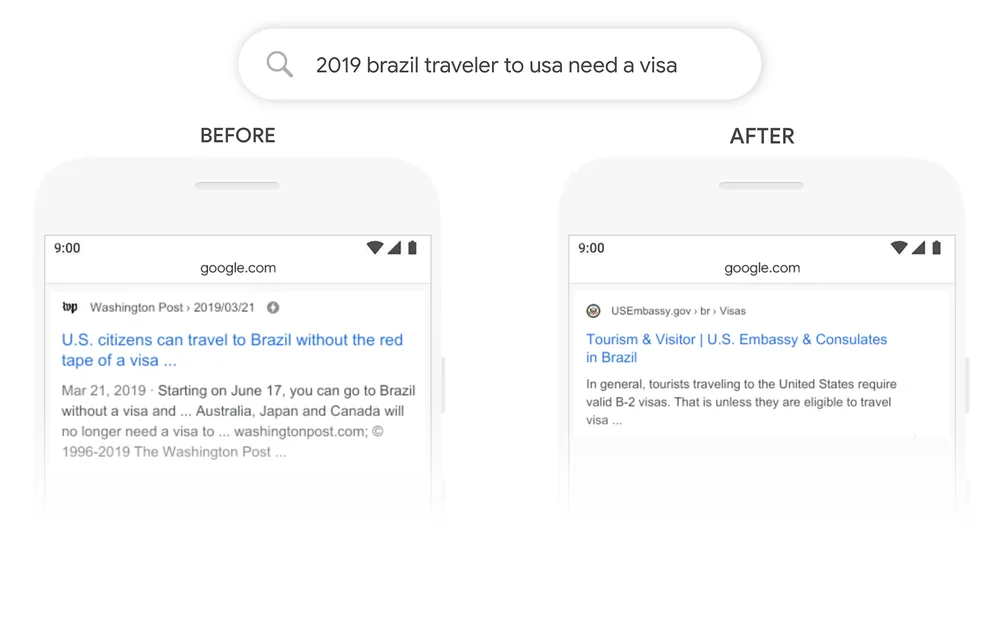
Fuente: Google
Pero esto es sólo una parte de la historia. El éxito del BERT se debe en gran medida a su naturaleza de código abierto, que ha permitido a los desarrolladores acceder al código fuente del BERT original y crear nuevas funciones y mejoras.
Esto ha dado lugar a un buen número de variantes de BERT. A continuación, encontrarás algunas de las variantes más conocidas:
Si quieres saber más sobre el movimiento LLM de código abierto, te recomendamos encarecidamente que leas nuestro post con el Top LLM de código abierto en 2023
Una de las mejores cosas del BERT, y de los LLM en general, es que el proceso de preentrenamiento está separado del proceso de ajuste. Eso significa que los desarrolladores pueden tomar versiones preentrenadas de BERT y personalizarlas para sus casos de uso específicos.
En el caso del BERT, hay cientos de versiones afinadas del BERT desarrolladas para una gran diversidad de tareas de PNL. A continuación, puedes encontrar una lista muy, muy limitada de versiones afinadas de BERT:
El BERT viene con las limitaciones y problemas tradicionales asociados a los LLM. Las predicciones del BERT se basan siempre en la cantidad y calidad de los datos utilizados para su entrenamiento. Si los datos de entrenamiento son limitados, pobres y sesgados, el BERT puede arrojar resultados inexactos, perjudiciales o incluso las llamadas alucinaciones LLM.
En el caso del BERT original, esto es aún más probable, ya que el modelo se entrenó sin Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF), una técnica estándar utilizada por modelos más avanzados, como ChatGPT, LLaMA 2 y Google Bard, para mejorar la seguridad de la IA. La RLHF consiste en utilizar la retroalimentación humana para supervisar y dirigir el proceso de aprendizaje del LLM durante la formación, garantizando así sistemas eficaces, más seguros y fiables.
Además, aunque puede considerarse un modelo pequeño en comparación con otros LLM de última generación, como ChatGPT, sigue necesitando una cantidad considerable de potencia informática para ejecutarlo, por no hablar de entrenarlo desde cero. Por lo tanto, los desarrolladores con recursos limitados no podrán utilizarlo.
El BERT fue uno de los primeros LLM modernos. Pero lejos de estar anticuado, el BERT sigue siendo uno de los LLM más exitosos y utilizados. Gracias a su naturaleza de código abierto, hoy en día existen múltiples variantes y cientos de versiones preentrenadas de BERT diseñadas para tareas específicas de PNL.
Si estás interesado en mantenerte al día sobre el BERT y los últimos avances en PNL, DataCamp está aquí para ayudarte. Echa un vistazo a nuestros materiales curados y ¡mantente informado sobre la actual revolución de la IA generativa!
¡Comienza hoy tu viaje con la PNL!
programa
Curso
Curso
blog
Natassha Selvaraj
15 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Joanne Xiong

