
Track
AI Fundamentals
10 hr
Text embedding (the same as word embeddings) is a transformative technique in natural language processing (NLP) that has improved how machines understand and process human language.
Text embedding converts raw text into numerical vectors, allowing computers to understand it better.
The reason for this is simple - computers only think in numbers and can’t understand human words independently. Thanks to text embeddings, it's easier for computers to read, understand texts, and provide more accurate responses to queries.
In this article, we will dissect the meaning of text embedding, its importance, evolution, use case, top models, and intuition.
Text embeddings are a way to convert words or phrases from text into numerical data that a machine can understand. Think of it as turning text into a list of numbers, where each number captures a part of the text's meaning. This technique helps machines grasp the context and relationships between words.
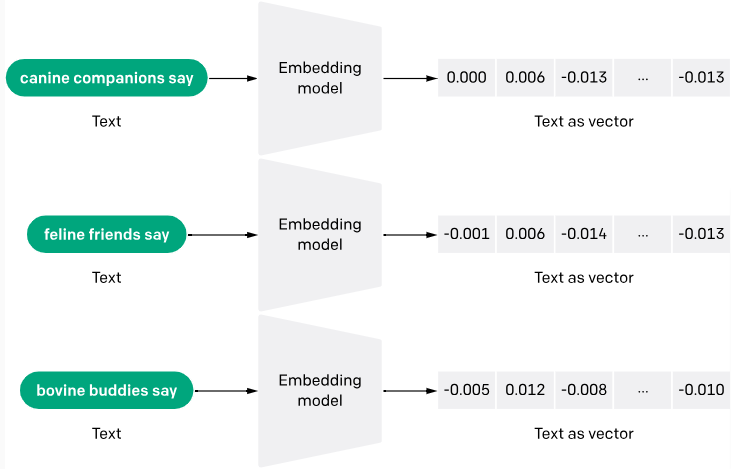
The process of generating text embeddings often involves neural networks that learn to encode the semantic meaning of words into dense vectors of real numbers. Methods like Word2Vec and GloVe are popular for generating these embeddings by analyzing the co-occurrence of words within large chunks of text.
You can learn more about text embeddings with the OpenAI API and see a practical application in a separate article.
Conventional language models regarded words as independent units. Word embeddings address this issue by positioning words that share meanings or contexts near each other within a multi-dimensional space.
Here are some more reasons why text embeddings are important:
Embeddings help models better generalize new, unseen words or phrases using the learned context from the training data. This is especially useful in dynamic languages where new words frequently emerge.
Embeddings are extensively used as features in various machine-learning tasks, such as document classification, sentiment analysis, and machine translation. They improve algorithms' performance by providing a rich, condensed form of data that captures basic textual properties.
Text embeddings are capable of handling multiple languages by identifying and representing semantic similarities across these different languages. An example is the Language-agnostic BERT Sentence Embedding (LaBSE) model, which has demonstrated remarkable capabilities in producing cross-lingual sentence embeddings covering 109 languages.
Traditional methods like one-hot encoding can generate sparse data (especially because most observations have a value of 0) and high-dimensional vectors, which are inefficient for large vocabularies. Embeddings reduce dimensionality and computational complexity, making them suitable for handling extensive text data better.
Text embeddings are dense vector representations of text data, where words and documents with similar meanings are represented by similar vectors in a high-dimensional vector space.
The intuition behind text embeddings is to capture the semantic and contextual relationships between text elements, allowing machine learning models to reason about and process text data more effectively.
One of the core intuitions behind text embeddings is the distributional hypothesis, which states that words or phrases that appear in similar contexts tend to have similar meanings.
For example, consider the words "king" and "queen." Although they are not synonyms, they share a similar context related to royalty and monarchy. Text embeddings aim to capture this semantic similarity by representing these words with vectors that are close together in the vector space.
Another intuition behind text embeddings is the idea of vector space operations. By representing text as numerical vectors, we can use vector space operations like addition, subtraction, and cosine similarity to capture and manipulate semantic relationships between words and phrases. For instance, let’s consider the following example:
king - man + woman ≈ queen
In this example, the vector operation "king - man + woman" might result in a vector that is very close to the embedding for "queen," capturing the analogical relationship between these words.
Another intuition I'd like to point out is dimensionality reduction in text embedding. Traditional sparse text representations, such as one-hot encoding, can have extremely high dimensionality (equal to the vocabulary size). Text embeddings, on the other hand, typically have a lower dimensionality (e.g., 300 dimensions), allowing them to capture the most salient features of the text while reducing noise and computational complexity.
I will be using the example of a restaurant to illustrate a general intuition of word embeddings:
Imagine you have a corpus of restaurant reviews and want to build a system that automatically classifies each review's sentiment as positive or negative. I recommend using text embeddings to represent each review as a dense vector, so it captures the semantic meaning and sentiment expressed in the text.
Let's consider two reviews:
Review 1: "The food was delicious, and the service was excellent. I highly recommend this restaurant."
Review 2: "The food was mediocre, and the service was poor. I won't be going back."
Even though these reviews don't share many words, their embeddings should be distant from each other in the vector space, reflecting the contrasting sentiments expressed. The positive sentiment words like "delicious" and "excellent" in Review 1 would have embeddings closer to the positive region of the vector space, while the negative sentiment words like "mediocre" and "poor" in Review 2 would have embeddings closer to the negative region.
By training a machine learning model on these text embeddings, it can learn to map the semantic patterns and sentiment information encoded in the embeddings to the corresponding sentiment labels (positive or negative), accurately classifying new, unseen reviews.
According to the book “Embeddings in Natural Language Processing: Theory and Advances in Vector Representations of Meaning” - by Mohammad Taher Pilehvar and Jose Camacho-Collados, text embeddings were,
“mainly popularized after 2013, with the introduction of Word2vec.”
This year indeed marked a major breakthrough for text embeddings. However, research on text embeddings goes back as far as the 1950s. While this section is not exhaustive, I will cover some of the major milestones in the evolution of text embeddings.
From the 1950s-2000s, methods like one-hot encoding and Bag-of-Words (BoW) were the norm. Unfortunately, these methods weren't very sufficient and posed some challenges, such as:
TF-IDF (Term Frequency-Inverse Document Frequency) was another early attempt in the 70s to capture texts as numbers. This approach calculated the weight of each word not only by its frequency in a specific document but also by its commonness across all documents, assigning higher values to less common words. While it improved upon one-hot encoding by offering more insight, it still fell short in capturing the semantic meaning of words.
According to IBM, the 2000s began with researchers,
“exploring neural language models (NLMs), which use neural networks to model the relationships between words in a continuous space. These early models laid the foundation for the later development of word embeddings.”
An early example is the introduction of "Neural probabilistic language models" by Bengio et al. around 2000, which aimed to learn distributed representations of words.
Later on, in 2013, Word2Vec entered the picture as the revolutionary model that introduced the idea of turning words into numerical vectors. These vectors captured semantic similarities, so words with similar meanings ended up closer in vector space. It was like creating a map of words based on their relationships.
In 2014, GloVe was introduced in a research paper titled “Glove: Global Vectors for Word Representation” by Jeffery Pennington and his co-authors. GloVe improved Word2Vec by better understanding word meanings by considering both the immediate context of a word and overall usage across the corpus.
During this period, methods like attention mechanisms (2017) and Transfer Learning and Context (2018) came to light.
Attention mechanisms allowed models to focus on specific parts of a sentence and assign them different weights based on their importance. This helped the model understand the relationships between words and how they contribute to their meaning.
For example, in this sentence, "The quick brown fox jumps over the lazy dog," the attention mechanism might pay more attention to "quick" and "jumps" when predicting the next word, compared to "the" or "brown."
On the other hand, Transfer Learning and Context welcomed the use of pre-trained models. Techniques like ULMFiT and BERT allowed these pre-trained models to be fine-tuned for specific tasks. This meant less data and computing power were needed for high performance.
Embedding APIs is a recent approach to text embedding. While it may be recent, its gradual emergence dates back to the 2010s, when cloud-based AI solutions and advancements in pre-trained models were becoming widespread.
Fast-forward to the 2020s. The adoption of APIs has grown massively within the developer community, and so has embedding APIs. An embedding API makes obtaining texts easier through pre-trained models.
A good example of an embedding API is the OpenAI embedding API. OpenAI introduced its Embedding API with significant updates in December 2022. This API offers a unified model known as text-embedding-ada-002, which integrates capabilities from several previous models into a single model. This model has been designed to excel at tasks like text search, code search, and sentence similarity.
Let’s discuss some of the use cases of text embeddings.
Word embeddings allow search engines to understand the underlying meaning of your query and find relevant documents, even if they don't contain the exact words you used. This is particularly helpful for ambiguous searches or finding similar content.
E-commerce platforms, social media platforms, and streaming services are common examples of applications that use text embeddings to recommend products or content based on your past preferences. By analyzing the descriptions and reviews of items you've interacted with, they can suggest similar things you might be interested in.
Meta (Facebook) uses text embeddings for its social search. You can learn more about this in this abstract.
Text embeddings go beyond translating words one-to-one. They consider the context and meaning of the text, leading to more accurate and natural-sounding translations.
Chatbots powered by text embeddings can understand the intent behind your questions and respond more reasonably and engagingly. They can analyze the sentiment of your message and adjust their communication style accordingly.
Word embeddings can be used to generate different creative text formats, like product descriptions or social media posts. Brands can also use text embeddings to analyze social media conversations and understand customer sentiment towards their products or services.
Here's a look at the top text embedding models, including both open-source and closed-source options:
As we already discussed, Word2Vec is one of the pioneering text embedding models. It was developed by Tomas Mikolov and colleagues at Google. Word2Vec uses shallow neural networks to generate word vectors that capture semantic similarities.
Word2Vec utilizes two model architectures: Continuous Bag-of-Words (CBOW) and Skip-Gram. CBOW predicts a word based on its surrounding context, while Skip-Gram predicts surrounding words based on a given word. This process helps encode semantic relationships between words.
Popular NLP libraries like Gensim and spaCY offer implementations of Word2Vec. You can find the open-source version of Word2vec hosted by Google and released under the Apache 2.0 license.
Stanford's GloVe is another widely used model. It focuses on capturing both local and global context by analyzing word co-occurrence statistics within a large text corpus. GloVe builds a word co-occurrence matrix and then factors it down to obtain word vectors. This process considers both nearby and distant word co-occurrences, leading to a comprehensive understanding of word meaning.
GloVe is also open-source. Pre-trained GloVe vectors are available for download, and implementations can be found in libraries like Gensim as well.
FastText, developed by Facebook (now Meta), is an extension of Word2Vec that addresses the limitation of not handling out-of-vocabulary (OOV) words. It incorporates subword information to represent words, allowing it to create embeddings for unseen words.
FastText decomposes words into character n-grams (subwords). Similar to Word2Vec, it trains word vectors based on these subword units. This allows the model to represent new words based on the meaning of their constituent subwords.
FastText is open-source and available through the FastText library. Pre-trained FastText vectors can also be downloaded for various languages.
The embedding v3 (Text-embedding-3) is the latest release of OpenAIs embedding models. The models come in two classes: text-embedding-3-small (the smaller model) and text-embedding-3-large (the larger model). They are closed-source, and you need a paid API to gain access.
Text-embedding-3 models transform text into numerical representations by first breaking it down into tokens (words or subwords). Each token is mapped to a vector in a high-dimensional space. A Transformer encoder then analyzes these vectors, considering each word's context based on its surroundings.
Finally, the model outputs a single vector representing the entire text, capturing its overall meaning and the relationships between the words within it. The large version boasts a more complex architecture and higher dimensionality for potentially better accuracy, while the small version prioritizes speed and efficiency with a simpler architecture and lower dimensionality.
To learn more about OpenAI embeddings, check out our guide: Exploring Text-Embedding-3-Large: A Comprehensive Guide to the new OpenAI Embeddings.
USE is a closed-source sentence embedding model created by Google AI. It converts text into high-dimensional embeddings that reflect the semantic meanings of sentences or short paragraphs.
Unlike models that embed individual words, USE handles entire sentences using a pre-trained deep neural network on a diverse text corpus. This design allows it to capture semantic relationships effectively, producing fixed-size vectors for variable-length sentences that enhance computational efficiency.
Google provides access through its TensorFlow Hub repository.
In this guide, we gained a comprehensive introduction to text embeddings, what they mean, their importance, and major milestones in their evolution. We also examined text embedding use cases and top text embedding models.
To learn in-depth about AI, NLP, and text embeddings, check out these resources:
Learn More About AI With DataCamp
Track
Course
Course
blog
Tom Farnschläder
9 min
blog
Javeria Rahim
7 min
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
DataCamp Team
code-along
James Briggs

