
programa
dbt Fundamentos
8 h
dbt Nube se ha convertido en el servicio gestionado líder para la transformación de datos, que proporciona a los equipos de análisis modernos flujos de trabajo escalables, fiables y colaborativos.
Amplía el poder de dbt Core, ofreciendo un entorno alojado que automatiza las implementaciones, coordina los trabajos, gestiona las credenciales y proporciona funciones de colaboración para los equipos de datos.
Esto permite a las organizaciones gestionar transformaciones basadas en SQL en un entorno seguro, automatizado y fácil de usar para los equipos.
En este tutorial introductorio, veremos qué es dbt Nube, cómo configurarlo y ejemplos de cómo se puede utilizar.
Si eres nuevo en el marco y prefieres una ruta de aprendizaje estructurada, te recomiendo que comiences con nuestra curso Introducción a dbt .
Empecemos con una descripción general de qué es dbt Nube y algunas de sus características.
En esencia, dbt Nube permite a los equipos seguir el proceso enfoque ELT (extraer, cargar, transformar). A diferencia de los procesos ETL tradicionales, en los que las transformaciones se realizan antes de cargar los datos en el almacén, dbt realiza las transformaciones dentro del almacén utilizando su potencia de cálculo y su escalabilidad.
Fuente: dbt
dbt Nube simplifica el proceso de transformación de datos, ya que:
dbt Nube se compone de los mismos conceptos que dbt Core.
Entre ellos se incluyen:
Un flujo de trabajo típico de dbt Nube tiene el siguiente aspecto: Desarrollar modelos > Probar transformaciones > Confirmar en Git > Implementar a través de trabajos de dbt Nube > Supervisar las ejecuciones en dbt Nube.
Para explicar cómo funciona dbt Nube, veamos un ejemplo práctico de cómo configurar un entorno por ti mismo.
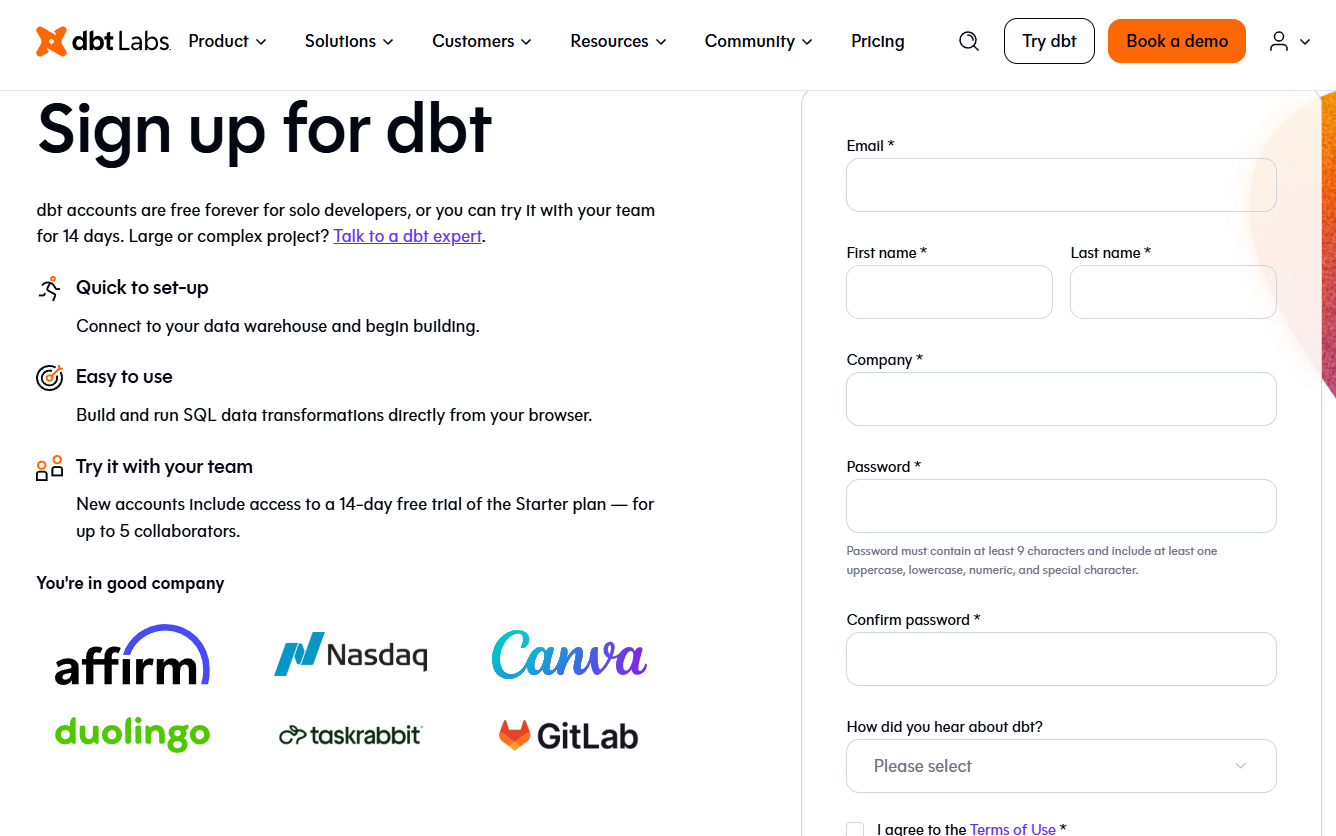
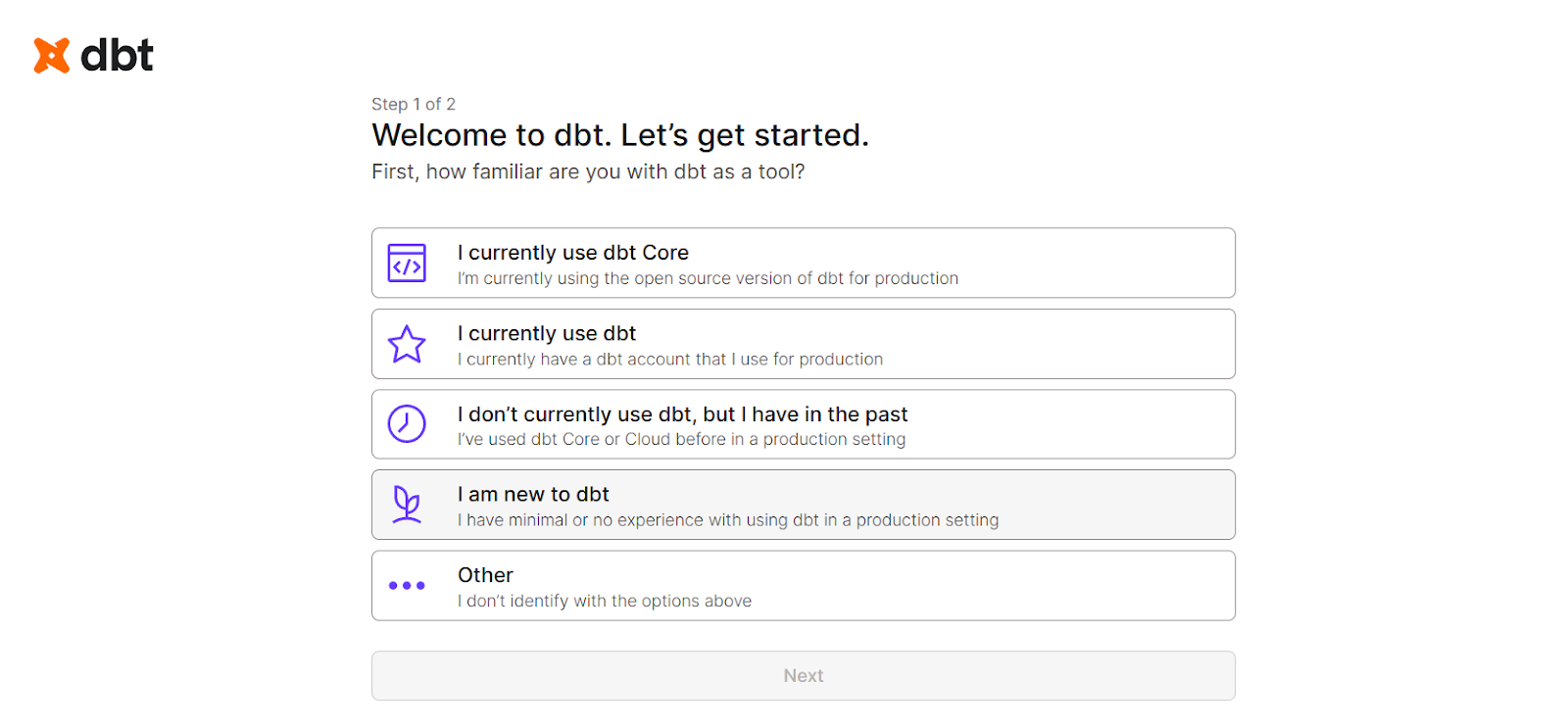
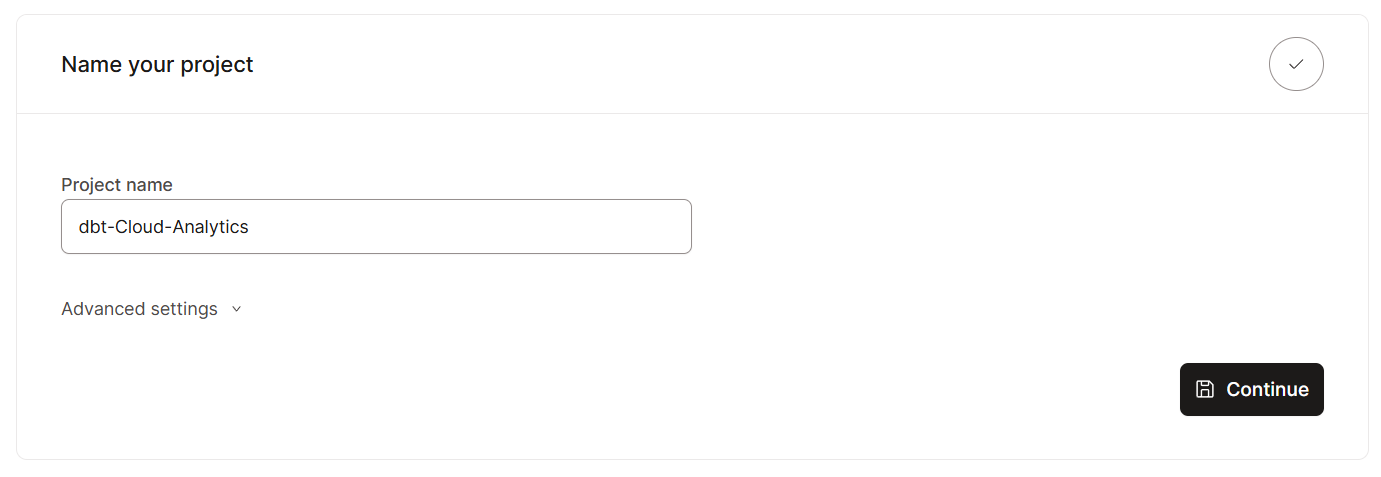
Empezar a utilizar dbt Cloud es muy sencillo, ya que está diseñado para una rápida incorporación. Estos son los pasos que debes seguir:
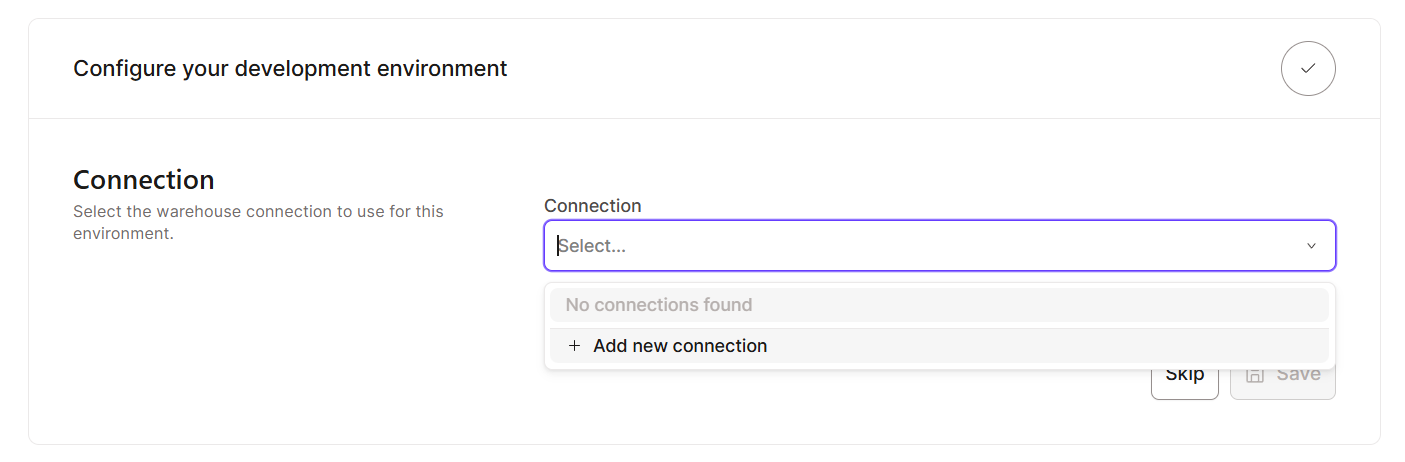
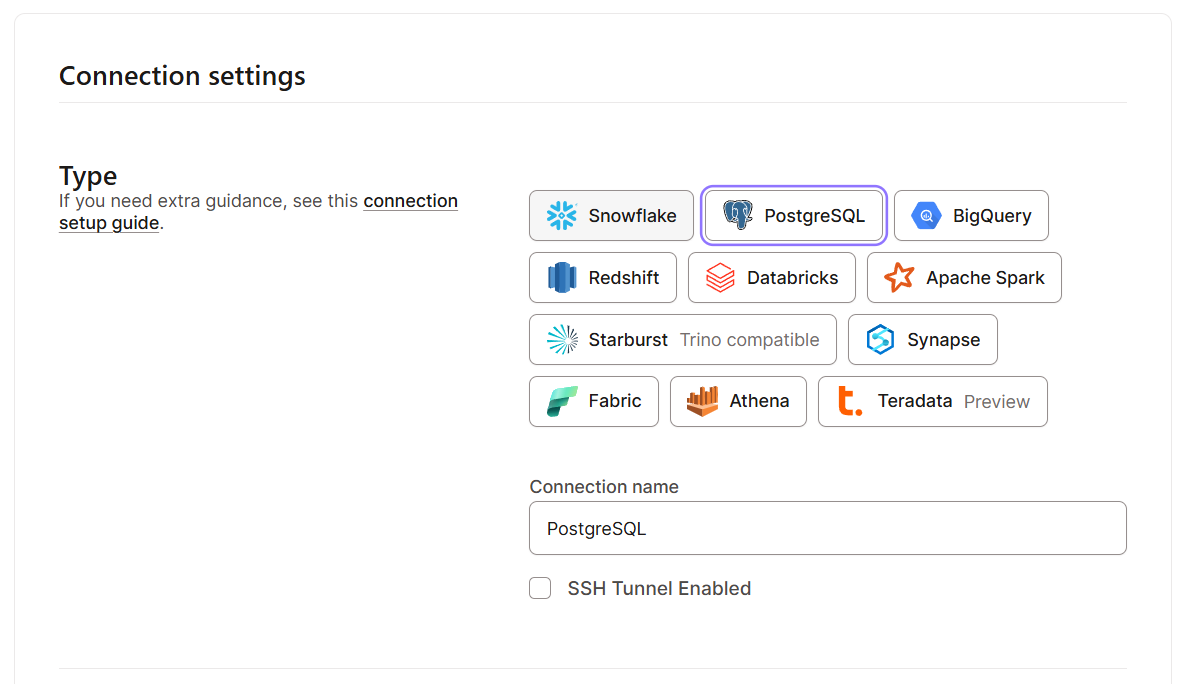
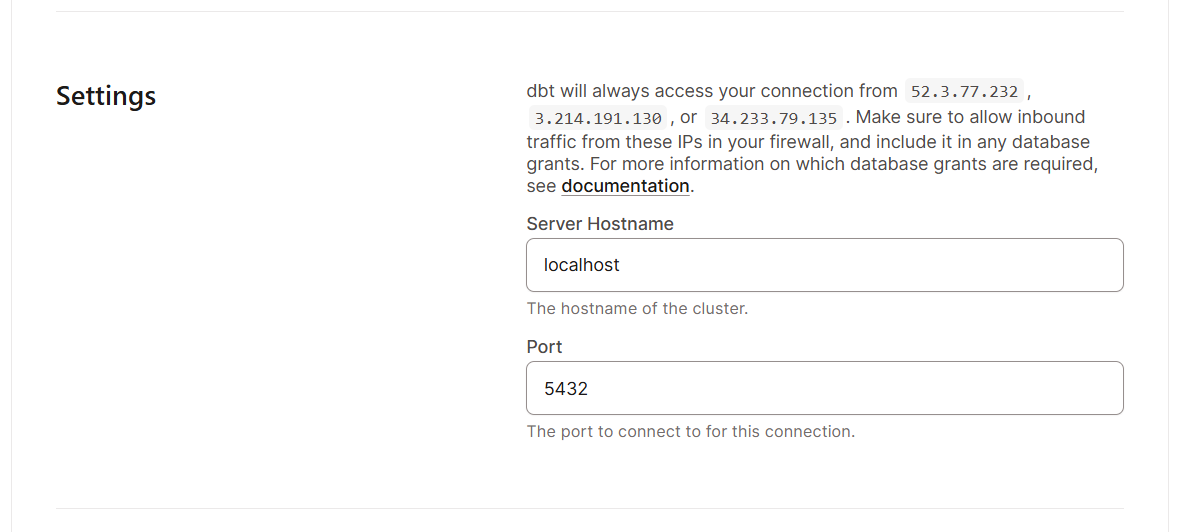
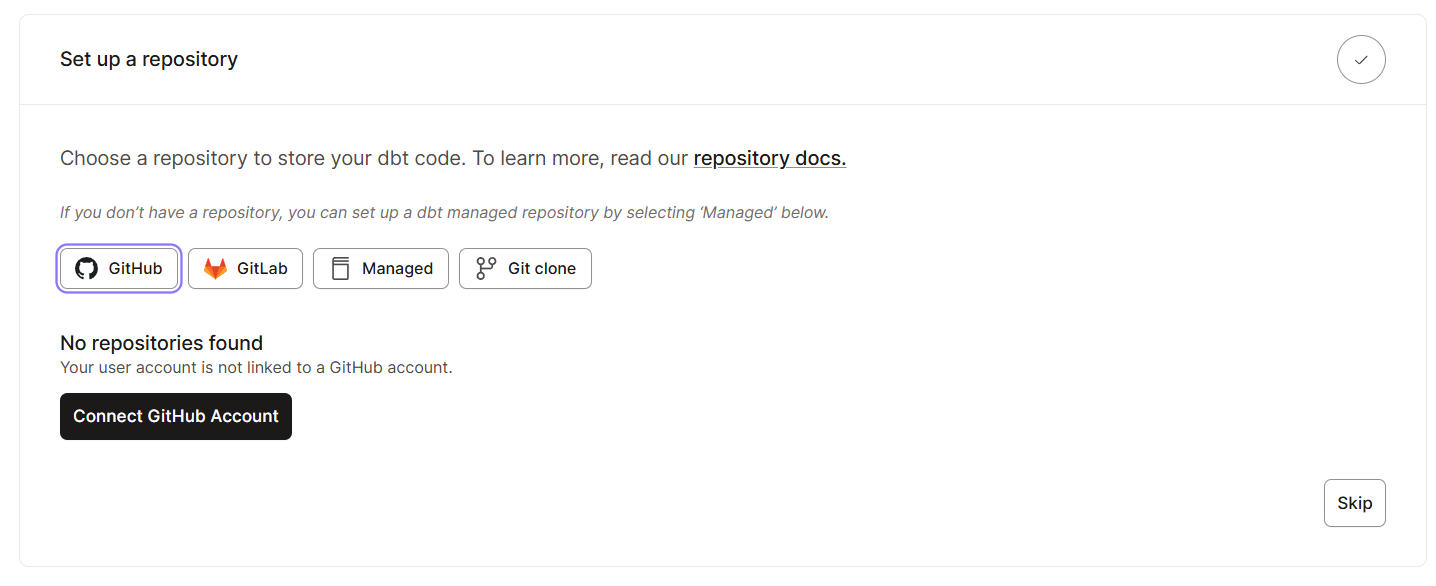
Una vez que tengas todas las configuraciones básicas listas, exploremos la interfaz. Esto es lo que deberías esperar ver en la interfaz de dbt Nube:
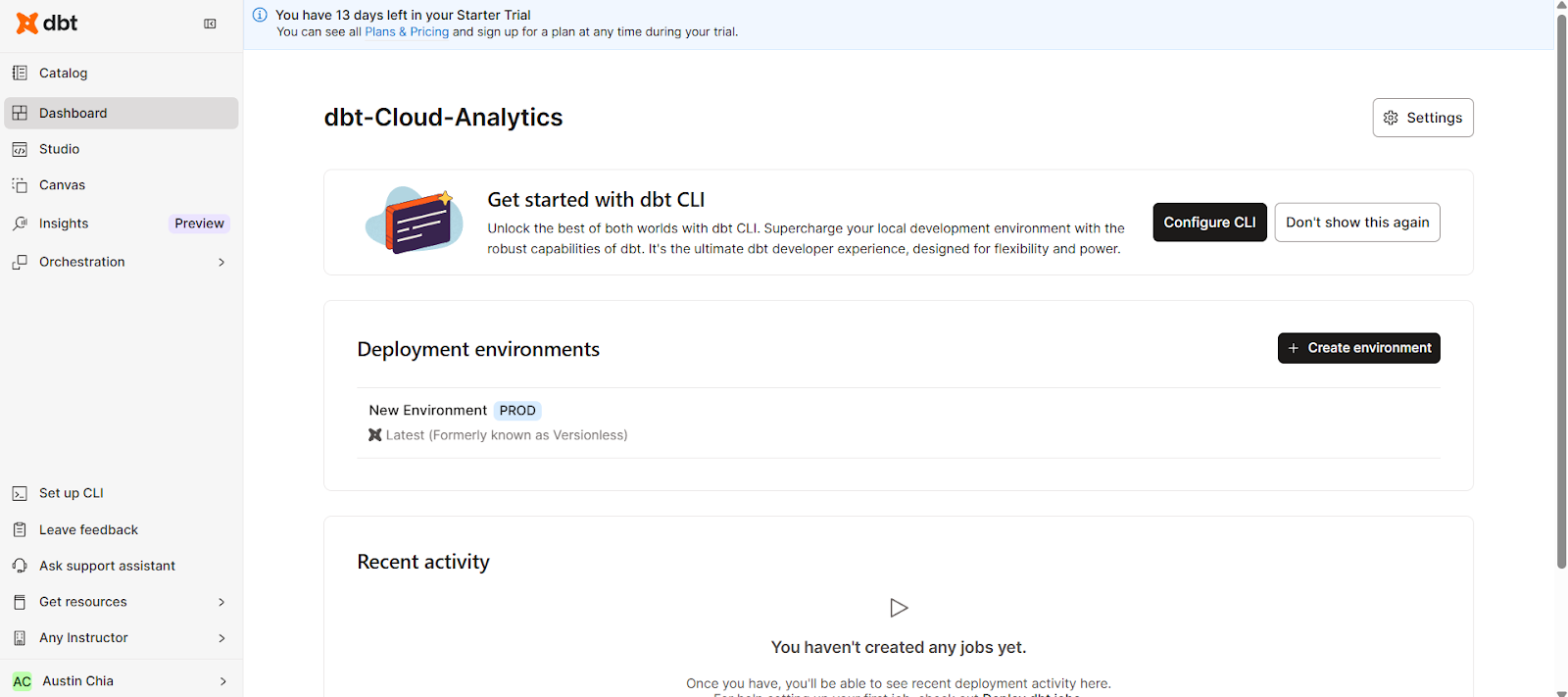
La interfaz de usuario de dbt Nube organiza tu flujo de trabajo de manera eficiente. Mediante la barra de navegación, puedes acceder a las siguientes áreas clave:
Esto consolida toda la información necesaria, el estudio de codificación y los ajustes de configuración en una única interfaz web.
dbt Nube también ofrece un IDE basado en navegador diseñado específicamente para la ingeniería analítica con integración en GitHub. Se creó para crear, ejecutar, probar y controlar las versiones de los proyectos dbt desde tu navegador.
El IDE en la nube de dbt no requiere ninguna configuración local, lo que facilita la incorporación de los analistas. Para acceder a él, puedes hacer clic en la pestaña Estudio situada en la parte izquierda de la interfaz.
Esto debería abrir una interfaz sencilla para escribir, compilar y ejecutar código.
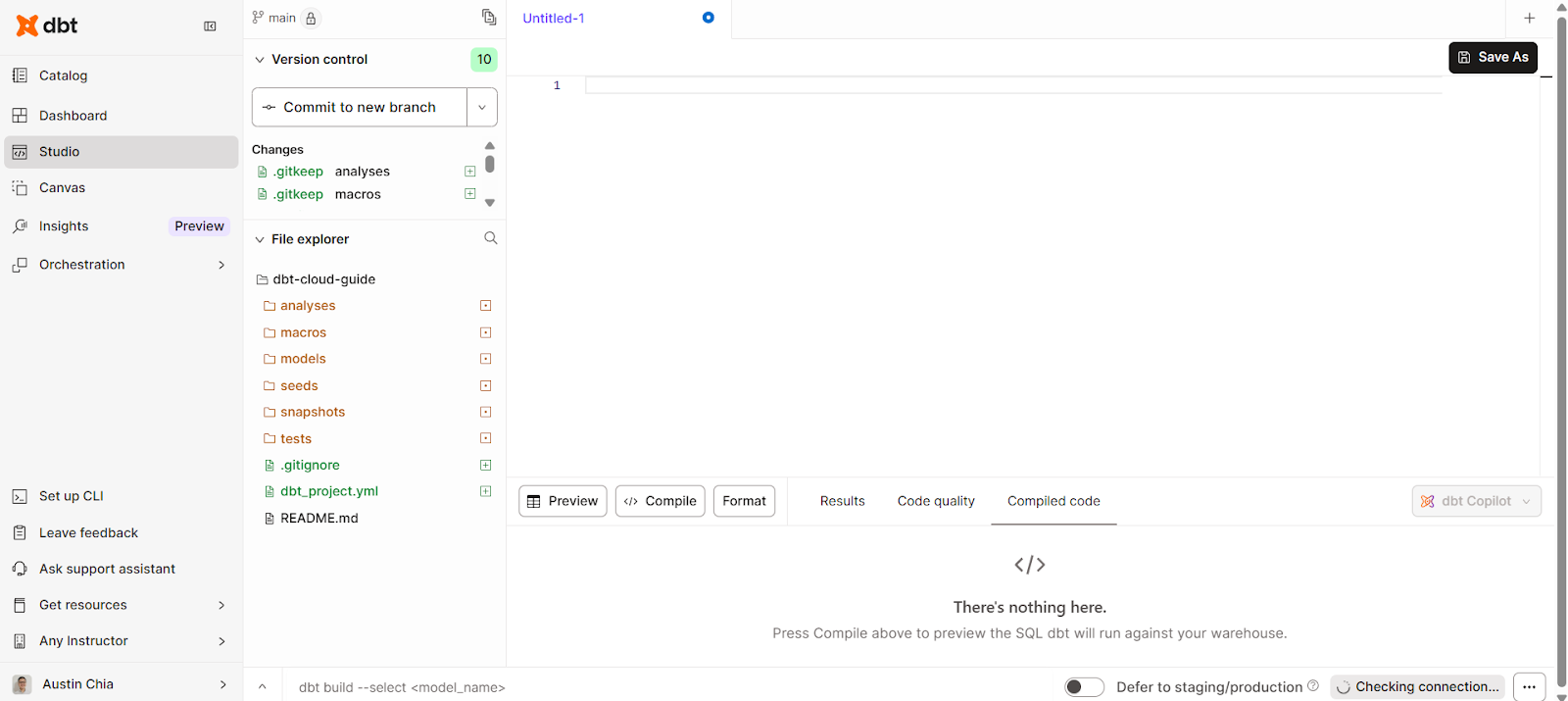
El IDE en la nube de dbt te permite realizar las siguientes tareas:
Además, dbt Nube también te permite integrarte con GitHub para la integración del control de versiones.
Esta función te permite:
Al igual que en dbt Core, también podrás crear y probar modelos de datos desde dbt Nube. Veamos algunas formas de hacerlo.
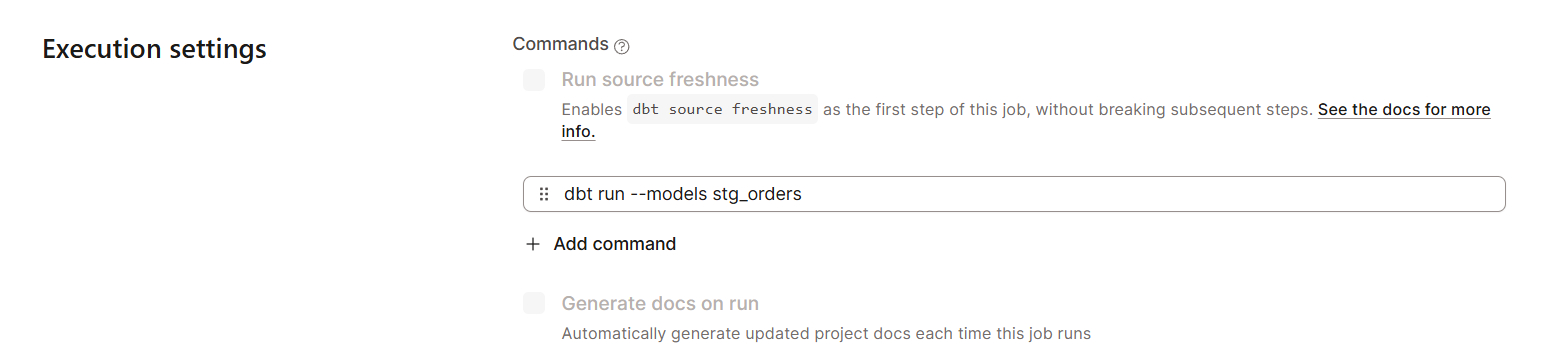
Cuando trabajes con modelos de datos, es probable que tengas que realizar algunas transformaciones. En el IDE de dbt Nube, podemos escribir sentencias SQL dentro de Studio.
Puedes crear un modelo de datos para transformar así:
with source as (
select * from {{ source('raw', 'orders') }}
)
select
id as order_id,
user_id,
order_date,
status
from sourceAsí es como se ve la interfaz:
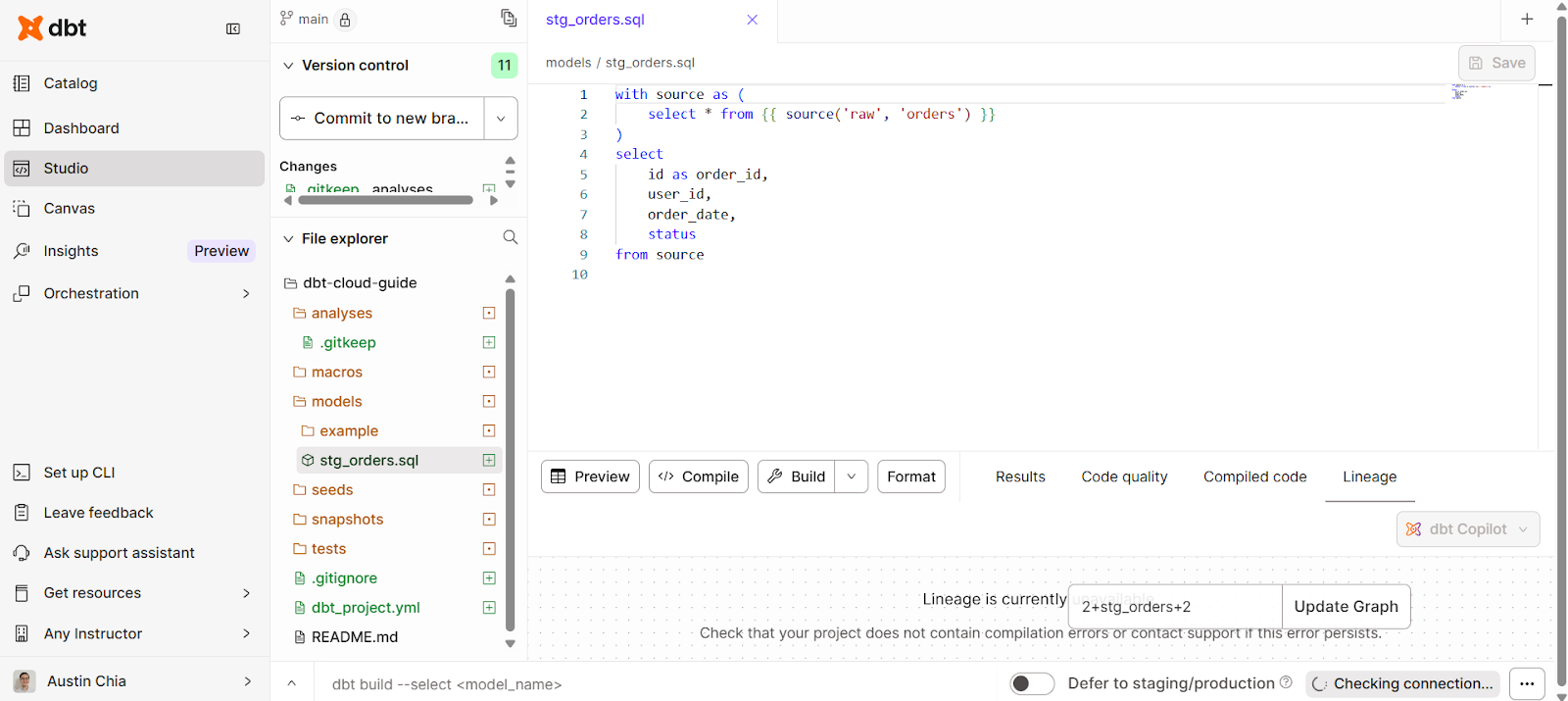
Algunas prácticas recomendadas que debes tener en cuenta:
Además, también puedes definir pruebas en YAML para comprobaciones automatizadas:
models:
- name: stg_orders
columns:
- name: order_id
tests:
- not_null
- unique
- name: status
tests:
- accepted_values:
values: ['completed', 'pending', 'cancelled']Probar tus datos refuerza la confianza en las transformaciones. Esto garantiza que cualquier trabajo que ejecutes tendrá pruebas integradas para mantener la integridad.
Si eres un usuario avanzado, también puedes definir pruebas personalizadas utilizando Jinja y SQL.
En dbt Nube, la programación y la coordinación de tareas ayudan a automatizar los análisis. Garantizan que tus transformaciones se ejecuten de forma coherente, puntual y en el entorno adecuado, con una intervención manual mínima.
En esta sección se explica cómo programar trabajos, activarlos automáticamente y supervisar su rendimiento en tiempo real.
En la interfaz de dbt Nube, puedes:
Para crear una programación de tareas en dbt Nube:
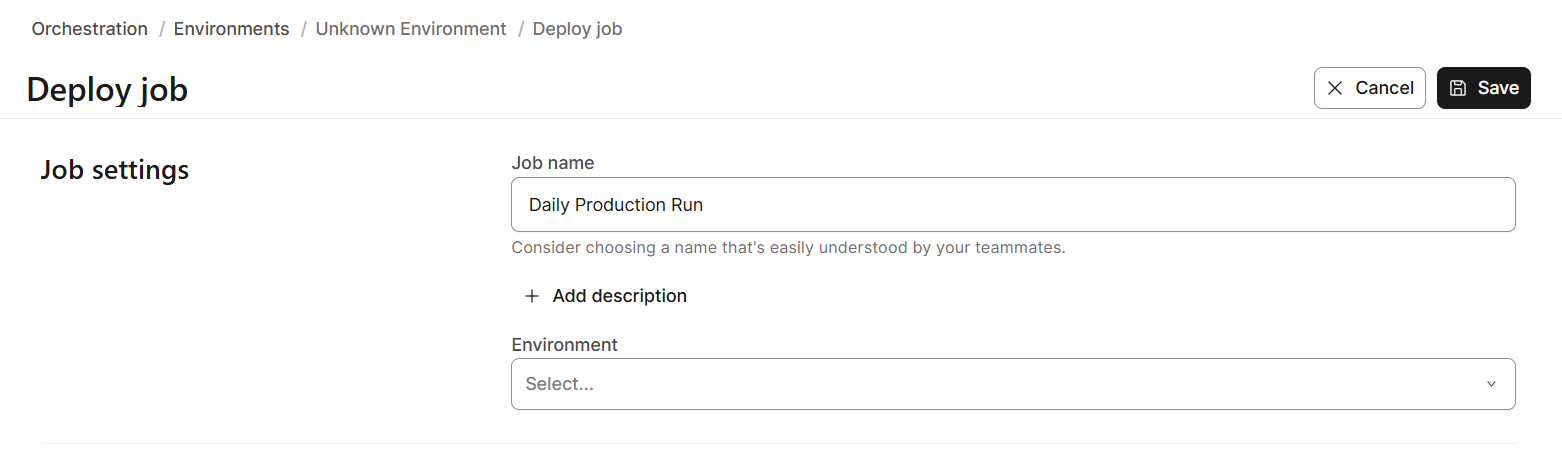
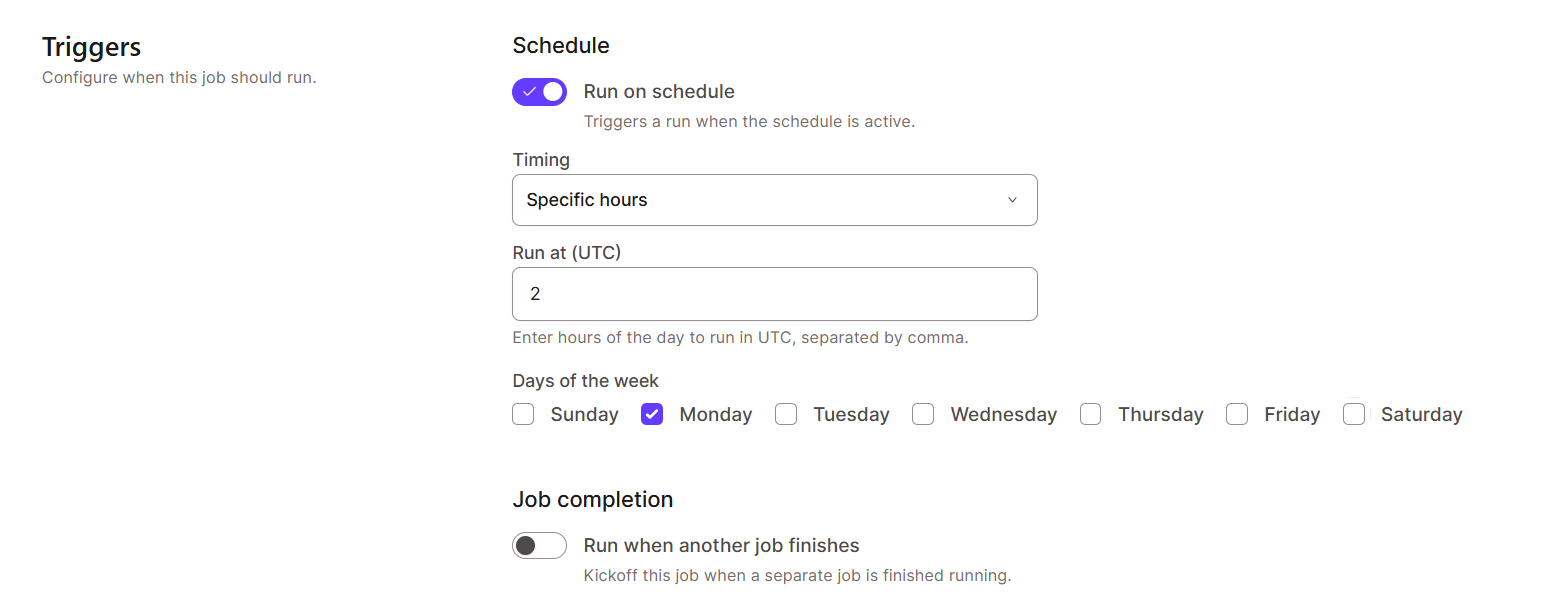
dbt Nube admite funciones de supervisión y registro para mejorar la observabilidad de los datos. Esto es esencial para solucionar fallos y optimizar el rendimiento.
Te permite:
Más allá de sus capacidades básicas de modelado y coordinación, dbt Nube ofrece funciones avanzadas que aportan inteligencia, coherencia y automatización a los flujos de trabajo analíticos modernos.
Se pueden encontrar en dos características principales: la capa semántica de dbt y las herramientas basadas en inteligencia artificial, como dbt Copilot y Fusion.
La capa semántica de dbt proporciona una capa central y regulada en la que los equipos pueden definir, gestionar y ofrecer métricas empresariales de forma coherente y con control de versiones.
Ayuda a:
Esta capa unificada salva la brecha entre la transformación de datos y la visualización a través de sus conexiones con herramientas comunes de BI.
Para ver un ejemplo práctico, consulta este tutorial sobre implementación de una capa semántica con dbt.
Una de las últimas funciones de dbt, dbt Copilot, es un asistente de IA integrado directamente en el IDE de dbt Nube. Ayuda a los programadores a escribir, depurar y optimizar código dbt utilizando indicaciones en lenguaje natural y sugerencias contextuales.
Con dbt Copilot, puedes:
El motor Fusion es un nuevo motor escrito en Rust para sustituir a dbt Core, con muchas más funciones.
Aporta algunos casos de uso, tales como:
En los flujos de trabajo de transformación de datos, la seguridad y la gobernanza son innegociables. Por eso, dbt Nube también cuenta con controles de seguridad de nivel empresarial para proteger la información confidencial, mantener el cumplimiento normativo y garantizar la responsabilidad entre los equipos.
dbt Nube utiliza el control de acceso basado en roles (RBAC) para gestionar los permisos de los usuarios y restringir el acceso a activos críticos como proyectos, entornos y credenciales.
Las posibles funciones incluyen:
Para configurar el control de acceso en dbt Nube:
dbt Nube incluye funciones completas de registro de auditoría y cumplimiento normativo diseñadas para ayudar a las organizaciones a cumplir los estrictos requisitos de gobernanza de datos, que cumplen con normas como SOC 2, GDPR y otras.
Los registros de auditoría también permiten investigar problemas, y la compatibilidad con SCIM mejora la integración de la gestión de identidades.
Una de las mayores fortalezas de dbt Nube reside en su capacidad para conectarse a la perfección con el ecosistema de datos más amplio. Se integra fácilmente con los principales almacenes de datos, API, herramientas de orquestación y plataformas de supervisión.
Esto lo convierte en una buena opción para crear un flujo de trabajo analítico unificado y automatizado, desde la ingestión hasta la visualización. Exploremos estos aspectos a continuación:
dbt Cloud es compatible con todos los principales almacenes de datos y lagos de datos en la nube, lo que permite a los equipos ejecutar transformaciones de forma nativa en los entornos donde ya residen sus datos.
Esto elimina la necesidad de mover o duplicar datos, aprovechando en su lugar el rendimiento y la escalabilidad de cada plataforma.
Las opciones de integración de dbt Nube incluyen:
También puedes tener varias opciones de autenticación por plataforma, como la autenticación por par de claves, OAuth o nombre de usuario/contraseña.
Para las organizaciones que requieren extensibilidad y automatización, dbt Nube también proporciona una potente API REST y un marco webhook.
La API de dbt Nube permite a los programadores:
Los webhooks de dbt Nube proporcionan una integración basada en eventos, lo que permite a los sistemas externos responder a eventos clave de dbt, como la finalización de trabajos, los fallos de ejecución o las actualizaciones de implementación.
Los webhooks se pueden utilizar para:
A medida que las canalizaciones de datos crecen en escala y complejidad, la observabilidad se vuelve esencial para mantener la fiabilidad, el rendimiento y la confianza.
Pero, ¿qué ofrece dbt Nube? Todo se reduce a dos aspectos: supervisión de los procesos y optimización de los modelos.
Cada ejecución de trabajo se registra, se programa y se visualiza dentro de la plataforma, lo que te permite comprender el estado integral de tus transformaciones.
Por ejemplo, dentro del panel de historial de ejecución , dbt Nube muestra información detallada como:
dbt Nube también se integra fácilmente con herramientas de supervisión de datos como Datadog.
Las grandes transformaciones monolíticas son difíciles de mantener y optimizar. dbt promueve el desarrollo modular, en el que la lógica compleja se divide en modelos más pequeños y reutilizables, cada uno de los cuales realiza una tarea específica.
Para optimizar el rendimiento, puedes seguir estas prácticas recomendadas:
stg_, int_, fct_, dim_) para aclarar el propósito del modelo.dbt deps y dbt docs generate para validar las dependencias y la documentación.También puedes utilizar materializaciones incrementales para reducir los costes de computación, como se muestra en el siguiente ejemplo.
{{ config(materialized='incremental') }}
select *
from {{ source('raw', 'events') }}
{% if is_incremental() %}
where event_timestamp > (select max(event_timestamp) from {{ this }})
{% endif %}Dado que los equipos de datos necesitan compartir más datos dentro de una organización, también deberás tener en cuenta las opciones de colaboración que ofrece dbt Nube.
dbt Mesh permite una colaboración escalable entre grandes organizaciones mediante la gestión centralizada de todo el linaje de datos. Permite a tu equipo crear múltiples proyectos interdependientes, cada uno de ellos propiedad de diferentes unidades de negocio o dominios de datos.
Las principales ventajas de dbt Mesh son:
En esencia, dbt Mesh permite a los equipos hacer referencia a modelos de distintos proyectos sin perder su autonomía.
Por ejemplo, un equipo financiero puede mantener un proyecto de «métricas financieras básicas», mientras que el equipo de marketing crea un proyecto independiente que hace referencia a esos modelos financieros sin duplicar el código ni la lógica.
dbt Mesh permite referencias entre proyectos a través de la función ` ref() `, ampliada con espacios de nombres de proyectos. Por ejemplo:
SELECT *
FROM {{ ref('finance_project', 'fct_revenue') }}Esto permite que el modelo de marketing consulte el modelo fct_revenue directamente desde el proyecto financiero, utilizando la versión canónica definida por ese equipo.
Para garantizar la compatibilidad con versiones anteriores y la confianza entre proyectos, dbt Mesh introduce dos mecanismos esenciales: el control de versiones de modelos y los contratos de modelos.
El control de versiones de modelos es uno de los métodos que permite a los equipos modificar sus modelos sin romper las dependencias existentes. Puedes definir varias versiones del mismo modelo utilizando la propiedad « versions: » en el archivo YAML del modelo.
Por ejemplo:
models:
- name: fct_revenue
versions:
- v: 1
description: "Initial revenue aggregation"
- v: 2
description: "Includes new discount and refund logic"Los contratos modelo definen la estructura, los tipos de datos y las restricciones de un modelo. Actúa como un acuerdo entre los productores y los consumidores de datos.
Cuando un modelo incluye un contrato, dbt lo valida antes de su ejecución, asegurándose de que los cambios en el esquema (como eliminaciones de columnas o incompatibilidades de tipos) no propaguen errores no deseados en fases posteriores.
Ejemplo de un contrato sencillo:
models:
- name: fct_revenue
contract:
enforced: true
columns:
- name: customer_id
data_type: string
- name: total_revenue
data_type: numeric
- name: report_date
data_type: dateSi alguien intenta eliminar o modificar una columna contratada, dbt generará un error, protegiendo así los modelos y paneles dependientes.
dbt Nube amplía la funcionalidad de dbt Core al proporcionar una plataforma gestionada de extremo a extremo para la ingeniería analítica.
A lo largo de esta guía, hemos explorado cómo centraliza el desarrollo a través del IDE Studio, gestiona la orquestación y es compatible con herramientas más recientes, como dbt Mesh y Semantic Layer.
Al integrar estas herramientas en una única plataforma, dbt Nube permite a los equipos gestionar todo el ciclo de vida de los datos, desde la ingestión hasta la documentación, sin necesidad de gestionar la infraestructura subyacente.
Si estás interesado en adquirir experiencia práctica en el uso de dbt, nuestro dbt Fundamentals te ofrece una forma práctica de empezar a crear tu primer proyecto.
Cursos de dbt
programa
Curso
Curso
Tutorial
Joleen Bothma
Tutorial
Anneleen Rummens
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Joleen Bothma
Tutorial
Abid Ali Awan

