
Lernpfad
dbt Grundlagen
8 Std.
dbt Cloud hat sich als führender Managed Service für Datentransformationund unterstützt moderne Analyseteams mit skalierbaren, zuverlässigen und kollaborativen Arbeitsabläufen.
Es erweitert die Möglichkeiten von dbt Core und bietet eine gehostete Umgebung, die Deployments automatisiert, Jobs koordiniert, Anmeldedaten verwaltet und Funktionen für die Zusammenarbeit von Datenteams bereitstellt.
So können Unternehmen SQL-basierte Transformationen in einer sicheren, automatisierten und teamfreundlichen Umgebung verwalten.
In diesem Einführungs-Tutorial schauen wir uns an, was dbt Cloud ist, wie man es einrichtet und wie man es nutzen kann.
Wenn du neu im Framework bist und einen strukturierten Lernpfad bevorzugst, empfehle ich dir, mit unserer Einführung in dbt .
Schauen wir uns erstmal an, was dbt Cloud ist und welche Funktionen es hat.
Im Grunde genommen hilft dbt Cloud Teams dabei, den ELT-Ansatz (Extract, Load, Transform) Ansatz zu nutzen. Anders als bei den üblichen ETL-Prozessen, wo die Transformationen vor dem Laden der Daten ins Warehouse passieren, macht dbt die Transformationen direkt im Warehouse, dank seiner Rechenleistung und Skalierbarkeit.
Quelle: dbt
dbt Cloud macht die Datenumwandlung einfacher, weil es:
dbt Cloud hat die gleichen Konzepte wie dbt Core.
Dazu gehören:
Ein typischer dbt Cloud-Workflow sieht so aus: Entwickle Modelle > Transformationen testen > In Git speichern > Über Cloud-Jobs bereitstellen > Überwachung der Ausführung in dbt Cloud.
Um zu zeigen, wie dbt Cloud funktioniert, schauen wir uns mal ein praktisches Beispiel an, wie du selbst eine Umgebung einrichten kannst.
Der Einstieg in dbt Cloud ist echt einfach, weil es für schnelles Onboarding gemacht ist. Hier sind die Schritte, die du machen musst:
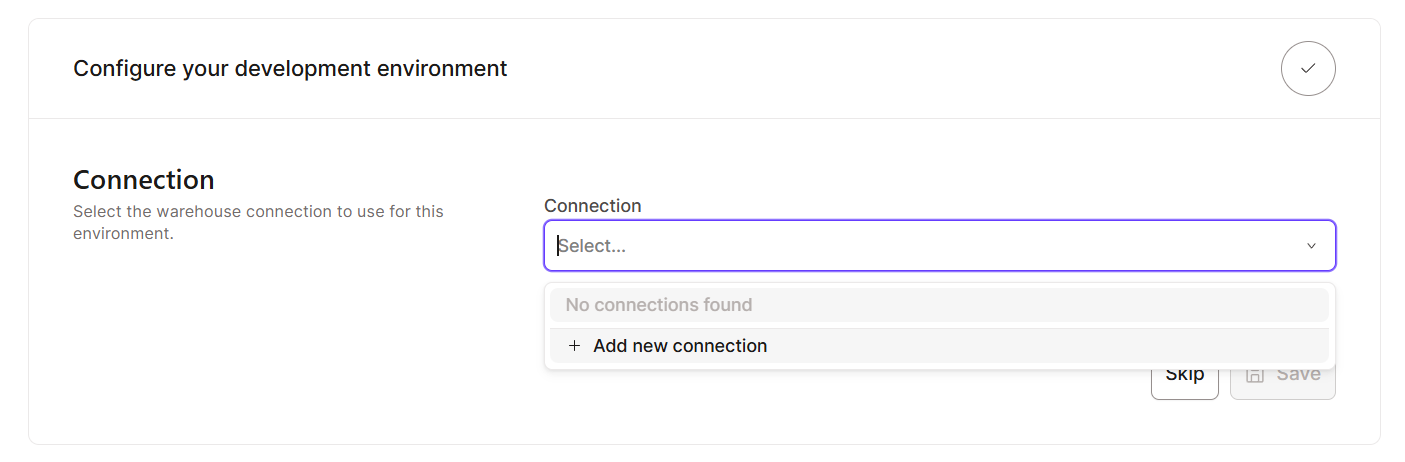
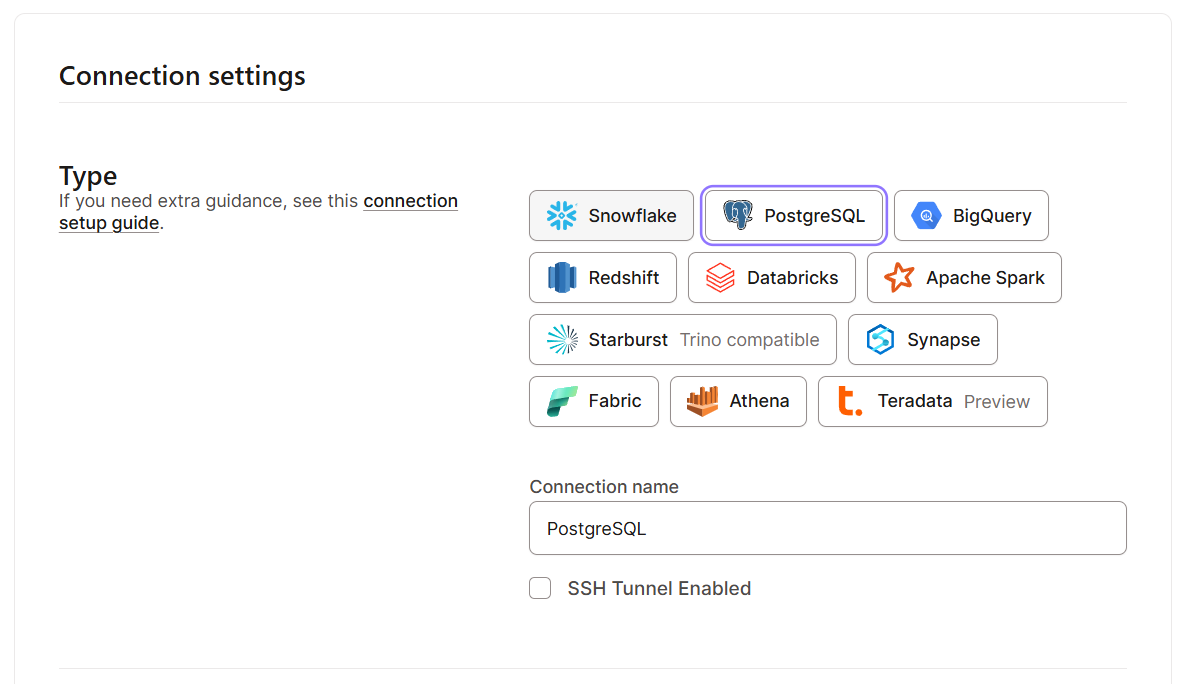
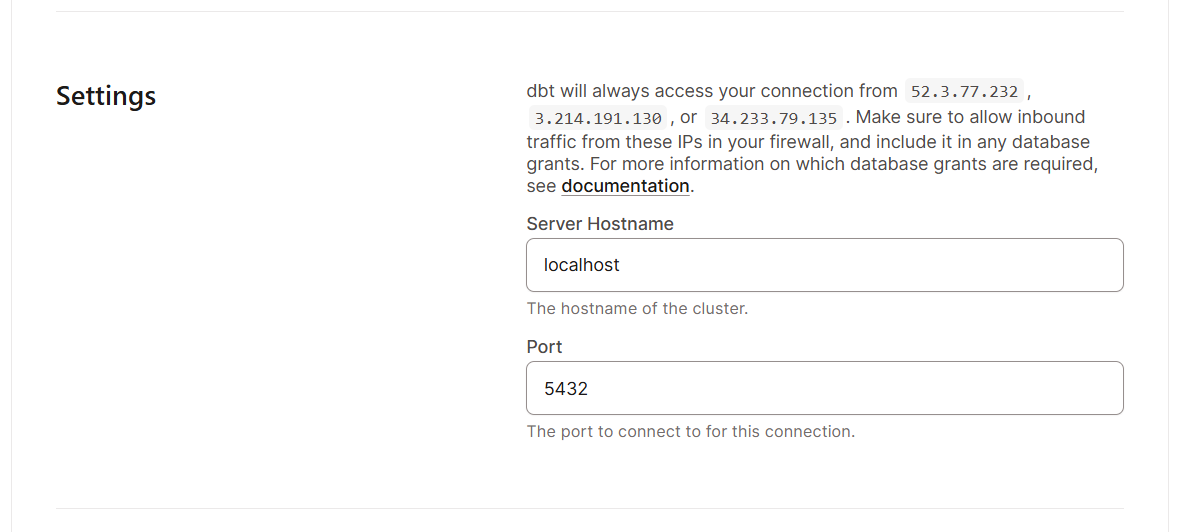
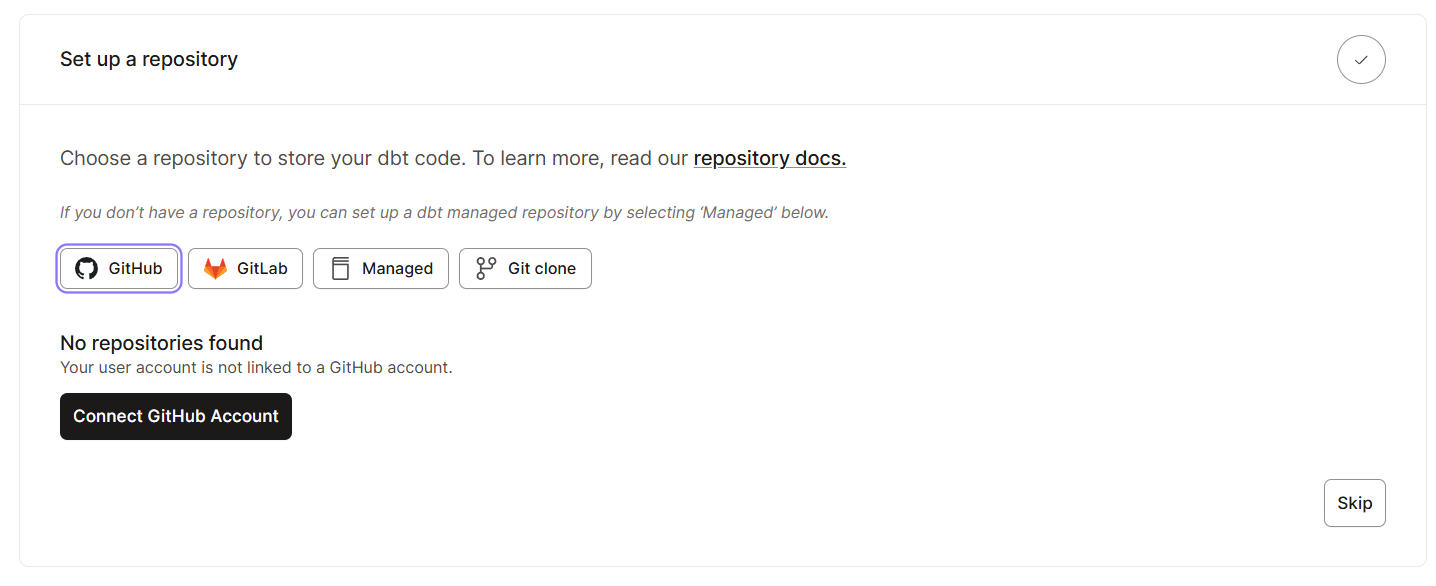
Sobald du alle grundlegenden Einstellungen vorgenommen hast, schauen wir uns die Benutzeroberfläche an. Hier ist, was du in der dbt Cloud-Oberfläche erwarten kannst:
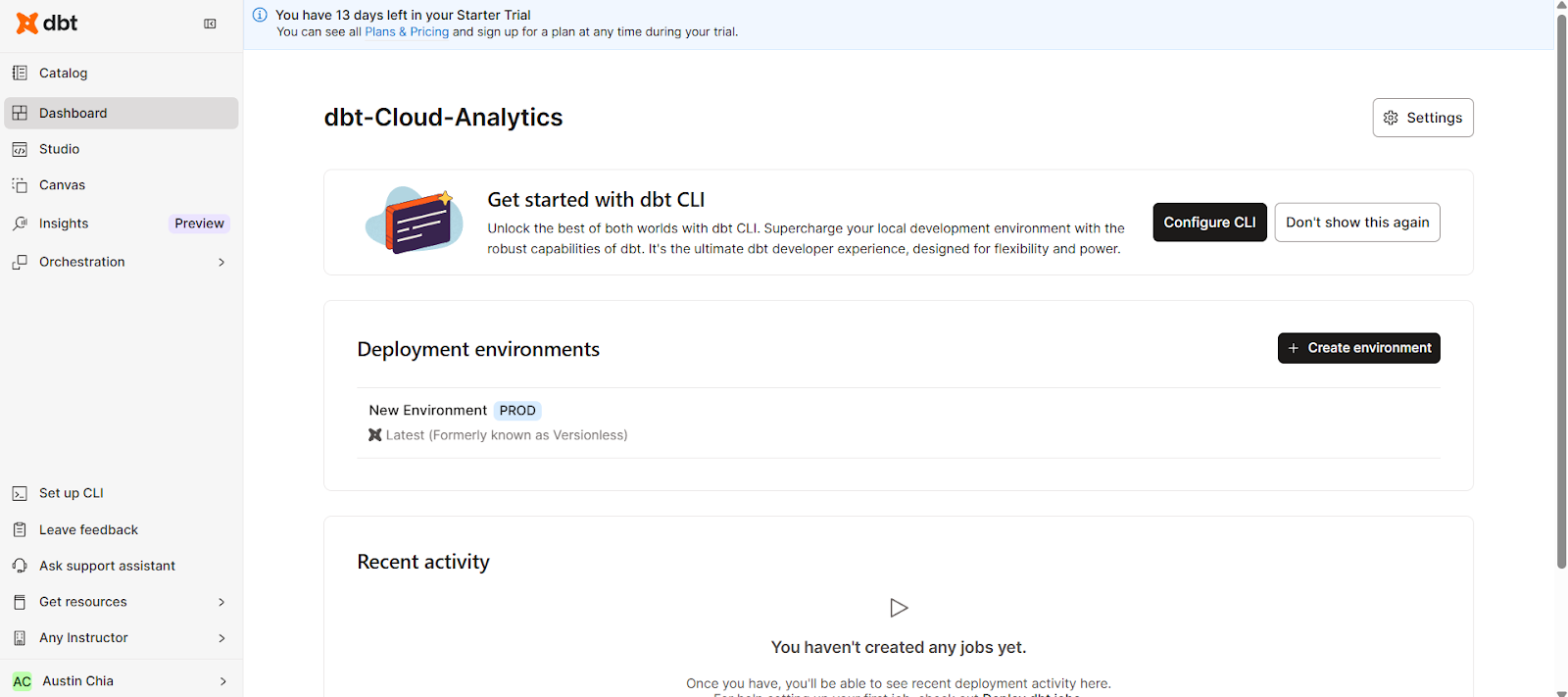
Die dbt Cloud-Benutzeroberfläche macht deinen Arbeitsablauf richtig effizient. Über die Navigationsleiste kommst du zu den folgenden wichtigen Bereichen:
Hier findest du alle wichtigen Infos, das Coding Studio und die Konfigurationseinstellungen in einer Weboberfläche.
dbt Cloud bietet auch eine browserbasierte IDE, die speziell für Analytics Engineering entwickelt wurde und GitHub integriert. Es wurde entwickelt, um dbt-Projekte über deinen Browser zu erstellen, auszuführen, zu testen und zu verwalten.
Die dbt Cloud IDE braucht keine lokale Installation, was den Einstieg für Analysten einfacher macht. Um draufzugreifen, klick einfach auf den Reiter „Studio“ auf der linken Seite der Benutzeroberfläche.
Damit solltest du eine einfache Oberfläche zum Schreiben, Kompilieren und Ausführen von Code sehen.
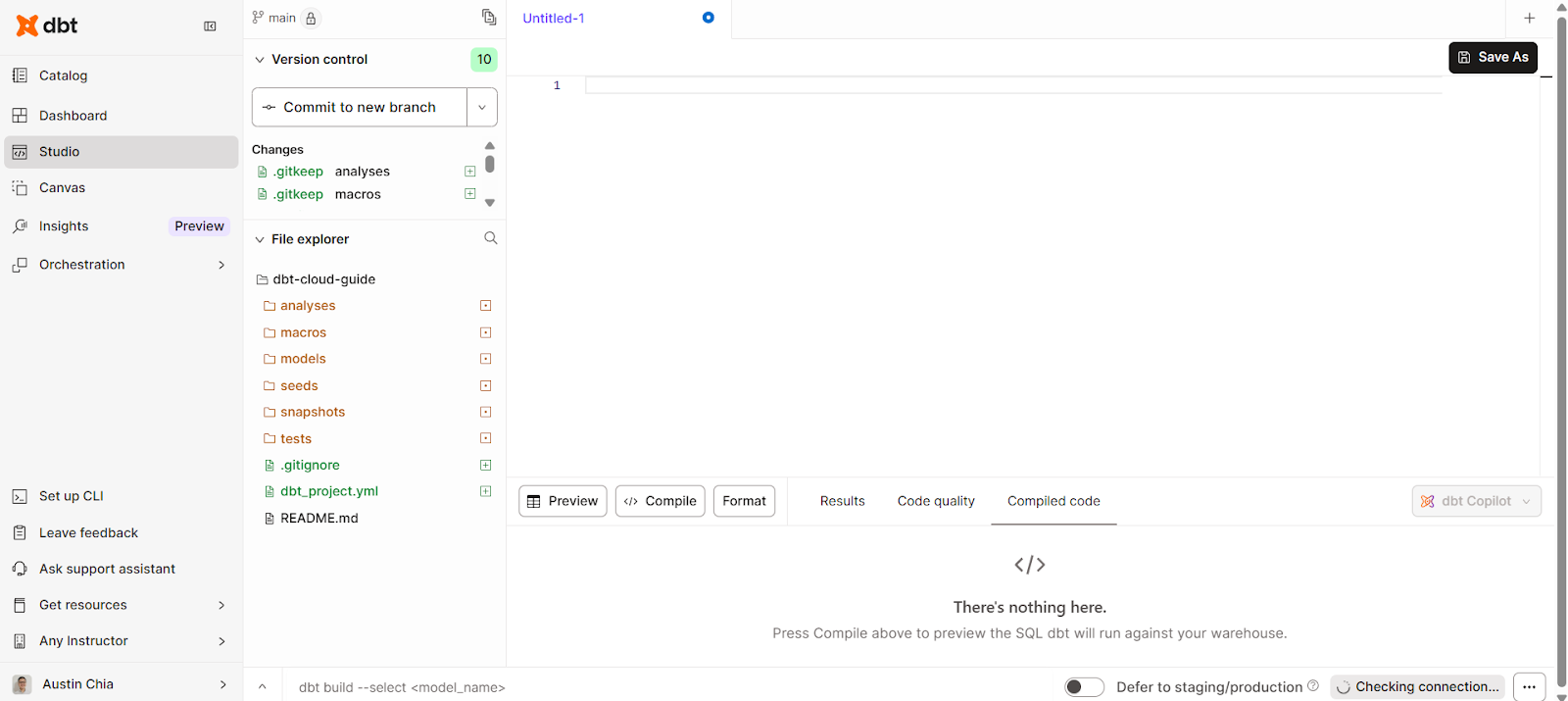
Mit der dbt Cloud IDE kannst du diese Aufgaben erledigen:
Außerdem kannst du mit dbt Cloud auch GitHub einbinden, um die Versionskontrolle zu integrieren.
Mit dieser Funktion kannst du:
Genau wie in dbt Core kannst du auch in dbt Cloud Datenmodelle erstellen und testen. Schauen wir uns mal ein paar Möglichkeiten an, wie das gemacht werden kann.
Wenn du mit Datenmodellen arbeitest, musst du wahrscheinlich ein paar Umwandlungen vornehmen. In der dbt Cloud IDE können wir SQL-Anweisungen direkt im Studio schreiben.
Du kannst ein Datenmodell erstellen, um es wie folgt umzuwandeln:
with source as (
select * from {{ source('raw', 'orders') }}
)
select
id as order_id,
user_id,
order_date,
status
from sourceSo sieht die Benutzeroberfläche aus:
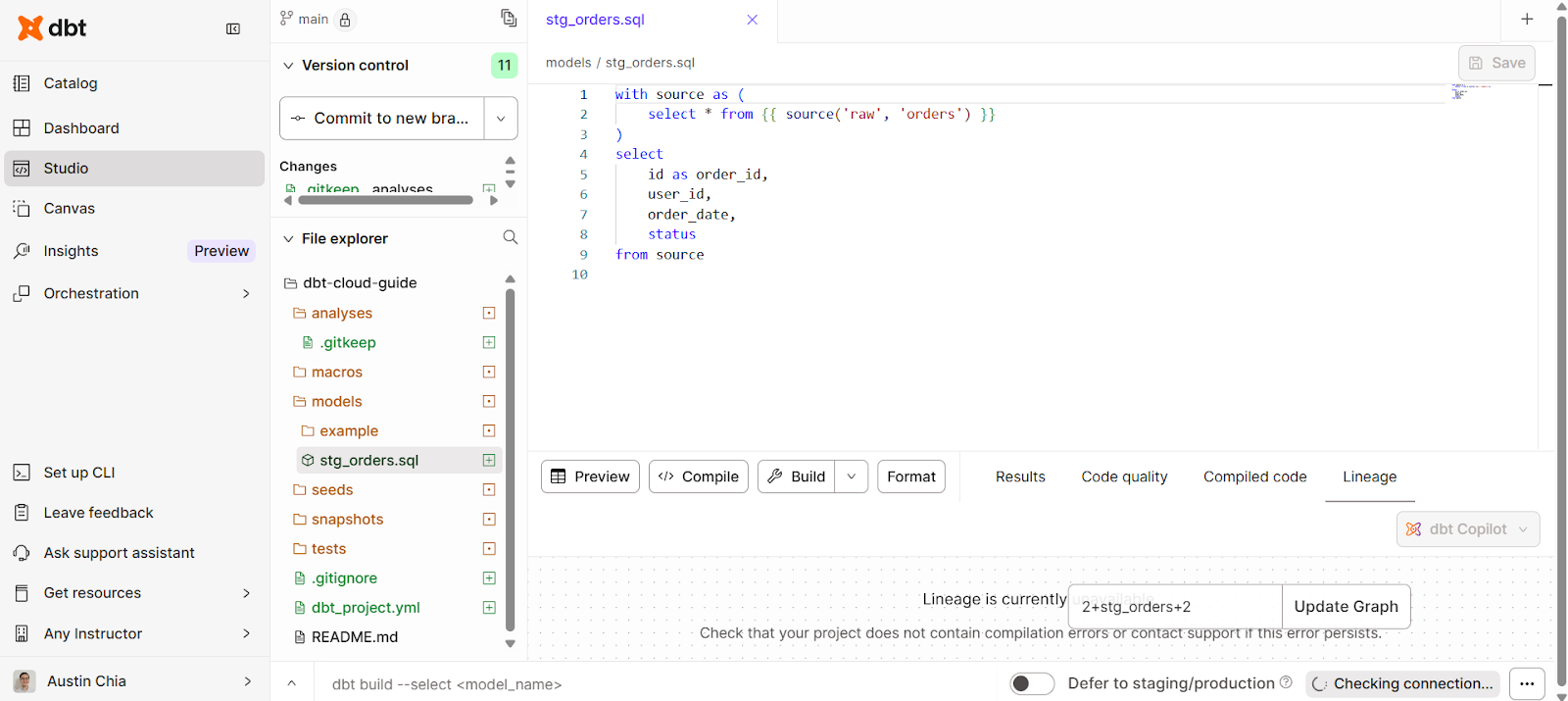
Ein paar bewährte Vorgehensweisen, die du beachten solltest:
Außerdem kannst du Tests in YAML für automatisierte Überprüfungen festlegen:
models:
- name: stg_orders
columns:
- name: order_id
tests:
- not_null
- unique
- name: status
tests:
- accepted_values:
values: ['completed', 'pending', 'cancelled']Das Testen deiner Daten sorgt für Vertrauen in die Transformationen. So stellst du sicher, dass alle Jobs, die du ausführst, Tests haben, um die Integrität zu halten.
Wenn du ein fortgeschrittener Benutzer bist, kannst du auch eigene Tests mit Jinja und SQL erstellen.
In dbt Cloud helfen Jobplanung und -koordination dabei, die Automatisierung von Analysen zu unterstützen. Sie sorgen dafür, dass deine Transformationen konsistent, pünktlich und in der richtigen Umgebung mit minimalem manuellem Aufwand laufen.
Hier geht's darum, wie du Jobs planst, automatisch startest und ihre Leistung in Echtzeit im Auge behältst.
In der dbt Cloud-Oberfläche kannst du:
So erstellst du einen Job-Zeitplan in dbt Cloud:
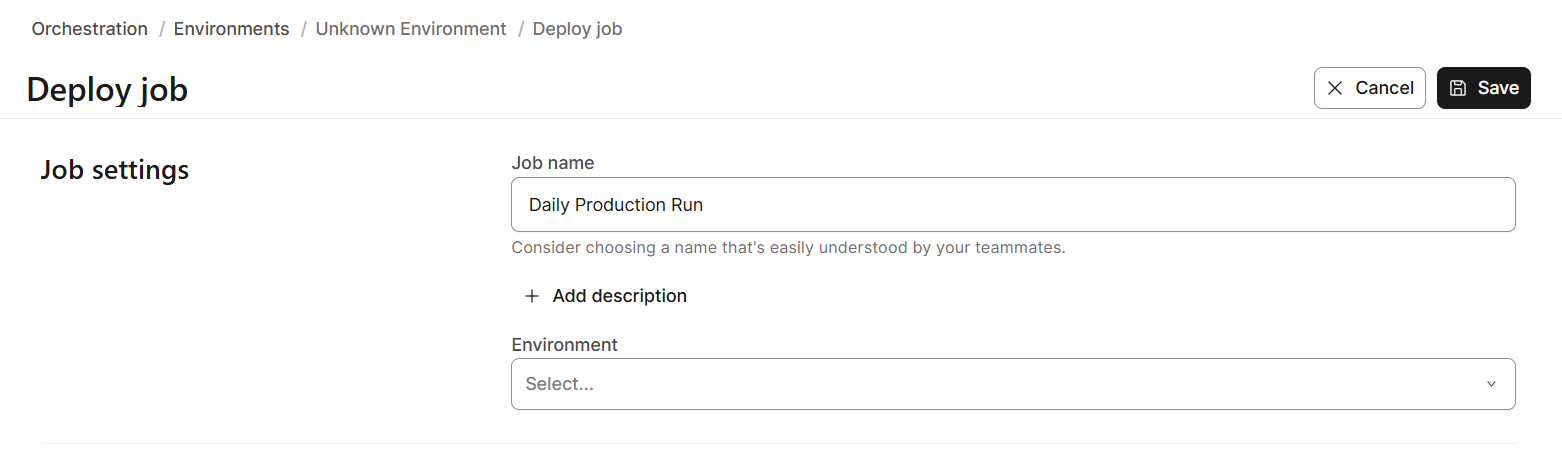
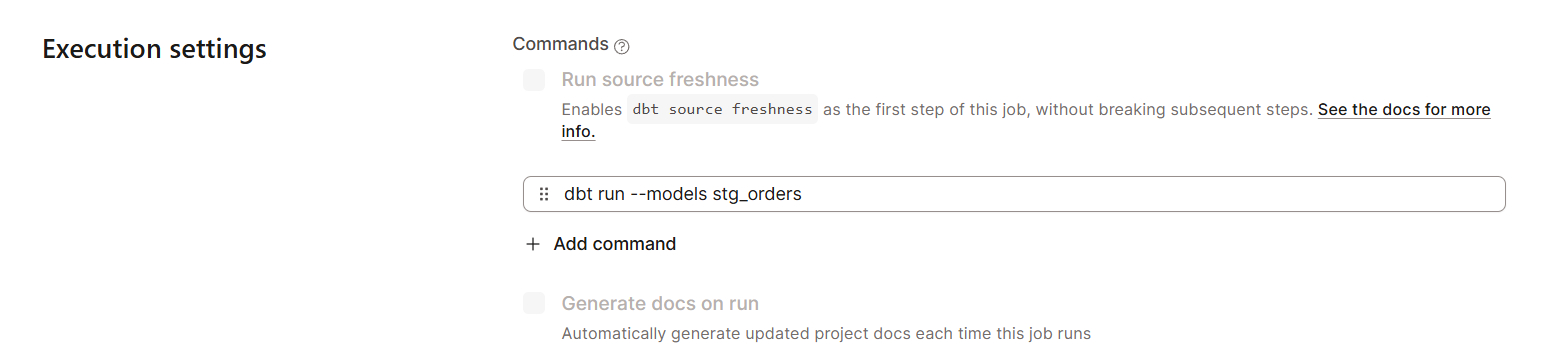
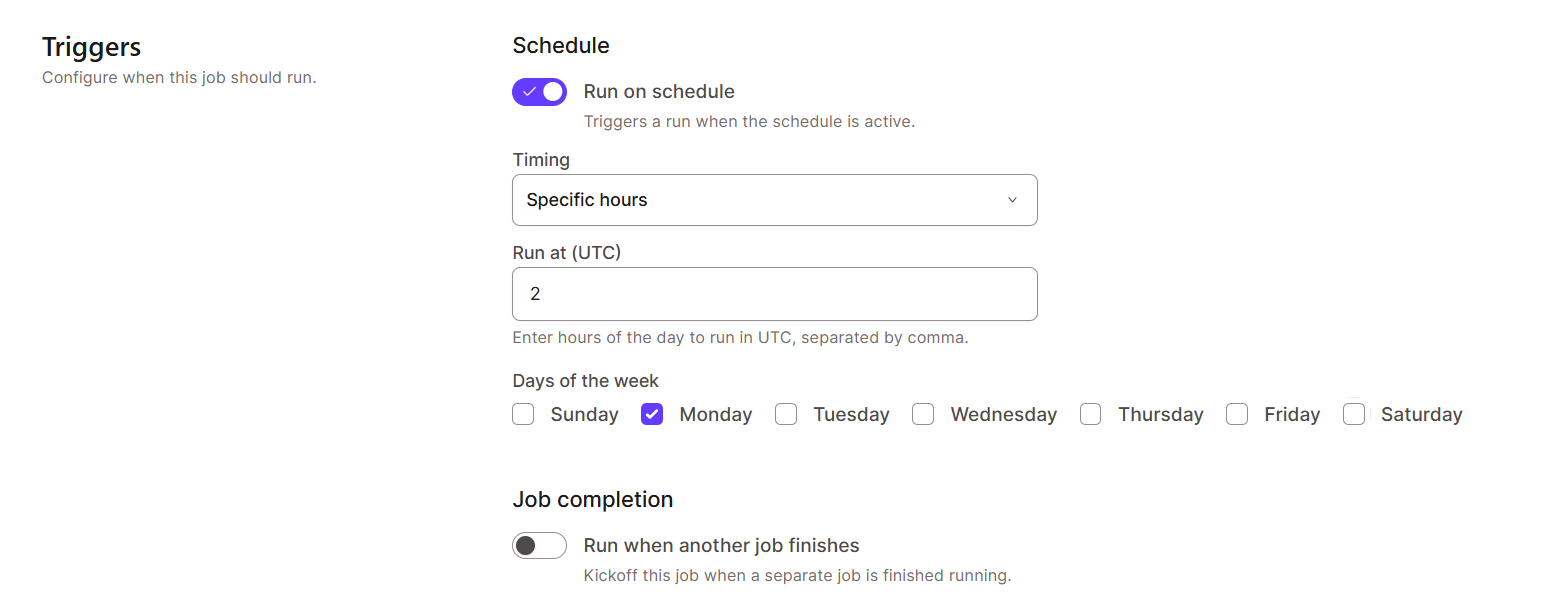
dbt Cloud hat Überwachungs- und Protokollierungsfunktionen, damit du deine Daten besser im Blick behalten kannst. Das ist echt wichtig, um Probleme zu lösen und die Leistung zu verbessern.
Damit kannst du:
Neben den grundlegenden Funktionen für Modellierung und Orchestrierung bietet dbt Cloud erweiterte Features, die moderne Analyse-Workflows intelligenter, konsistenter und automatisierter machen.
Sie haben zwei Hauptmerkmale: die dbt Semantic Layer und KI-gestützte Tools wie dbt Copilot und Fusion.
Die dbt Semantic Layer bietet eine zentrale, verwaltete Ebene, auf der Teams Geschäftsmetriken auf einheitliche und versionskontrollierte Weise definieren, verwalten und bereitstellen können.
Es hilft:
Diese einheitliche Ebene schließt die Lücke zwischen Datentransformation und Visualisierung, indem sie mit gängigen BI-Tools verbunden ist.
Ein praktisches Beispiel findest du in diesem Tutorial zur Implementierung einer semantischen Schicht mit dbt.
Eine der neuesten Funktionen von dbt, dbt Copilot, ist ein KI-Assistent, der direkt in die IDE von dbt Cloud eingebaut ist. Es hilft Entwicklern dabei, dbt-Code mit Hilfe von Eingabeaufforderungen in natürlicher Sprache und kontextbezogenen Vorschlägen zu schreiben, zu debuggen und zu optimieren.
Mit dbt Copilot kannst du:
Die Fusion-Engine ist eine neue Engine, die in Rust geschrieben wurde, um dbt Core zu ersetzen, und die viel mehr Funktionen hat.
Es gibt ein paar Anwendungsfälle, wie zum Beispiel:
Bei Datenumwandlungs-Workflows sind Sicherheit und Governance einfach ein Muss. Deshalb hat dbt Cloud auch Sicherheitsfunktionen auf Unternehmensniveau eingebaut, um sensible Infos zu schützen, die Compliance zu wahren und die Verantwortlichkeit über alle Teams hinweg sicherzustellen.
dbt Cloud nutzt rollenbasierte Zugriffskontrolle (RBAC), um Benutzerberechtigungen zu verwalten und den Zugriff auf wichtige Sachen wie Projekte, Umgebungen und Anmeldedaten zu beschränken.
Mögliche Aufgaben sind:
So richtest du die Zugriffskontrolle in dbt Cloud ein:
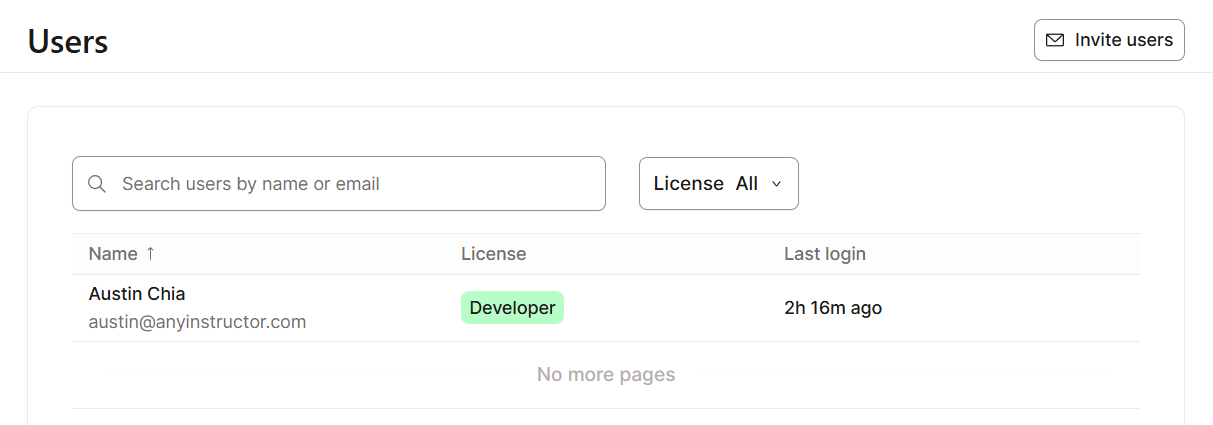
dbt Cloud hat umfassende Audit-Protokollierungs- und Compliance-Funktionen, die Unternehmen dabei helfen sollen, strenge Anforderungen an die Datenverwaltung zu erfüllen, die mit Standards wie SOC 2, DSGVO und anderen übereinstimmen.
Audit-Protokolle helfen auch bei der Untersuchung von Problemen, und SCIM-Unterstützung verbessert die Integration der Identitätsverwaltung.
Eine der größten Stärken von dbt Cloud ist, dass es sich super in das größere Daten-Ökosystem einbinden lässt. Es lässt sich ganz einfach mit den gängigsten Data Warehouses, APIs, Orchestrierungstools und Überwachungsplattformen verbinden.
Das macht es zu einer guten Wahl für den Aufbau eines einheitlichen und automatisierten Analyse-Workflows, von der Erfassung bis zur Visualisierung. Schauen wir uns diese Punkte mal genauer an:
dbt Cloud funktioniert mit allen großen Cloud-Data-Warehouses und Lakehouses, sodass Teams Transformationen direkt in den Umgebungen machen können, wo ihre Daten schon sind.
Dadurch muss man keine Daten mehr verschieben oder duplizieren, sondern kann einfach die Leistung und Skalierbarkeit jeder Plattform nutzen.
Die Integrationsoptionen von dbt Cloud umfassen:
Du kannst auch mehrere Authentifizierungsoptionen pro Plattform haben, wie zum Beispiel Schlüsselpaar-Authentifizierung, OAuth oder Benutzername/Passwort.
Für Unternehmen, die Erweiterbarkeit und Automatisierung brauchen, bietet dbt Cloud auch eine starke REST-API und ein Webhook-Framework.
Die dbt Cloud API ermöglicht Entwicklern Folgendes:
dbt Cloud-Webhooks bieten eine ereignisbasierte Integration, sodass externe Systeme auf wichtige dbt-Ereignisse wie Jobabschluss, Ausführungsfehler oder Bereitstellungsaktualisierungen reagieren können.
Die Webhooks kannst du für Folgendes nutzen:
Da Datenpipelines immer größer und komplexer werden, ist es wichtig, dass man sie gut im Blick hat, um die Zuverlässigkeit, Leistung und das Vertrauen zu sichern.
Aber was hat dbt Cloud denn so zu bieten? Es geht im Grunde um zwei Sachen: die Überwachung von Pipelines und die Optimierung von Modellen.
Jeder Joblauf wird auf der Plattform protokolliert, verfolgt und angezeigt, sodass du den gesamten Status deiner Transformationen im Blick hast.
Zum Beispiel im Ausführungsverlauf zeigt dbt Cloud detaillierte Infos wie:
dbt Cloud lässt sich auch ganz einfach mit Datenüberwachungstools wie Datadog verbinden.
Große monolithische Transformationen sind echt schwer zu pflegen und zu optimieren. dbt macht die modulare Entwicklung einfacher, indem komplexe Logik in kleinere, wiederverwendbare Modelle aufgeteilt wird, die jeweils eine bestimmte Aufgabe erledigen.
Um die Leistung zu verbessern, kannst du diese bewährten Methoden anwenden:
stg_, int_, fct_, dim_), um den Zweck des Modells klarer zu machen.dbt deps “ und „ dbt docs generate “ aus, um Abhängigkeiten und Dokumentation zu überprüfen.Du kannst auch inkrementelle Materialisierungen nutzen, um die Rechenkosten zu senken, wie im folgenden Beispiel gezeigt.
{{ config(materialized='incremental') }}
select *
from {{ source('raw', 'events') }}
{% if is_incremental() %}
where event_timestamp > (select max(event_timestamp) from {{ this }})
{% endif %}Da Datenteams immer mehr Daten innerhalb einer Organisation austauschen müssen, solltest du auch die Kollaborationsoptionen von dbt Cloud in Betracht ziehen.
dbt Mesh macht eine skalierbare Zusammenarbeit in großen Unternehmen möglich, indem es die gesamte Datenherkunft zentral verwaltet. Damit kann dein Team mehrere voneinander abhängige Projekte erstellen, die jeweils verschiedenen Geschäftsbereichen oder Datenbereichen zugeordnet sind.
Die wichtigsten Vorteile von dbt Mesh sind:
Im Grunde genommen ermöglicht dbt Mesh Teams, Modelle projektübergreifend zu nutzen und dabei ihre Unabhängigkeit zu behalten.
Zum Beispiel könnte das Finanzteam ein Projekt mit „wichtigen Finanzkennzahlen” verwalten, während das Marketingteam ein eigenes Projekt aufbaut, das auf diese Finanzmodelle zugreift, ohne Code oder Logik zu duplizieren.
dbt Mesh macht projektübergreifende Verweise über die Funktion „ ref() “ möglich, die um Projekt-Namespaces erweitert wurde. Zum Beispiel:
SELECT *
FROM {{ ref('finance_project', 'fct_revenue') }}Dadurch kann das Marketingmodell das Modell „ fct_revenue ” direkt aus dem Finanzprojekt heraus abfragen und dabei die von diesem Team definierte kanonische Version verwenden.
Um Abwärtskompatibilität und Vertrauen zwischen Projekten zu sichern, hat dbt Mesh zwei wichtige Mechanismen eingeführt: Modellversionierung und Modellverträge.
Die Modellversionierung ist eine der Methoden, mit denen Teams ihre Modelle ändern können, ohne bestehende Abhängigkeiten zu zerstören. Du kannst mehrere Versionen desselben Modells über die Eigenschaft „ versions: “ in der YAML-Datei des Modells festlegen.
Zum Beispiel:
models:
- name: fct_revenue
versions:
- v: 1
description: "Initial revenue aggregation"
- v: 2
description: "Includes new discount and refund logic"Musterverträge legen die Struktur, Datentypen und Einschränkungen eines Modells fest. Es ist wie eine Vereinbarung zwischen Leuten, die Daten machen, und denen, die sie nutzen.
Wenn ein Modell einen Vertrag hat, checkt dbt ihn vor der Ausführung, um sicherzustellen, dass Schemaänderungen (wie das Löschen von Spalten oder Typkonflikte) keine ungewollten Fehler weitergeben.
Beispiel für einen einfachen Vertrag:
models:
- name: fct_revenue
contract:
enforced: true
columns:
- name: customer_id
data_type: string
- name: total_revenue
data_type: numeric
- name: report_date
data_type: dateWenn jemand versucht, eine vertraglich vereinbarte Spalte zu löschen oder zu ändern, gibt dbt eine Fehlermeldung aus und schützt so abhängige Modelle und Dashboards.
dbt Cloud macht dbt Core noch besser, indem es eine komplett verwaltete Plattform für Analytics Engineering bietet.
In diesem Leitfaden haben wir uns angesehen, wie es die Entwicklung über die Studio-IDE zentralisiert, die Orchestrierung übernimmt und neuere Tools wie dbt Mesh und die Semantic Layer unterstützt.
Durch die Zusammenführung dieser Tools auf einer einzigen Plattform können Teams mit dbt Cloud den ganzen Datenlebenszyklus von der Erfassung bis zur Dokumentation verwalten, ohne sich um die zugrunde liegende Infrastruktur kümmern zu müssen.
Wenn du praktische Erfahrungen mit dbt sammeln möchtest, ist unser dbt Fundamentals Skill Track bietet dir einen praktischen Einstieg, um dein erstes Projekt zu erstellen.
dbt-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
