
Curso
Introducción a los LLMs en Python
3 h
33.7K
Microsoft se ha unido al competitivo panorama de los grandes modelos lingüísticos junto a Meta AI con la introducción de la serie Phi-3.5. Esta serie incluye un pequeño modelo lingüístico, un modelo lingüístico de visión y emplea una Mezcla de Expertos para conseguir un rendimiento de primer nivel.
En este tutorial, exploraremos la familia de modelos Microsoft Phi-3.5. Cargaremos el modelo Phi-3.5-mini-instrucción y lo pondremos a punto para clasificar productos de comercio electrónico basándonos en sus descripciones textuales. En los pasos finales, demostraremos cómo fusionar la LoRA (Adaptación de Bajo Rango) con el modelo base y empujarlo a Cara Abrazada. Esto permitirá un despliegue eficiente en la nube, haciendo que el modelo sea accesible para diversas aplicaciones.
Toma el Dominar los Conceptos de los Grandes Modelos Lingüísticos (LLM) y conoce las aplicaciones de los LLM, las metodologías de formación, las consideraciones éticas y las últimas investigaciones.

Imagen del autor
En Microsoft Phi-3.5 introduce tres modelos innovadores: Phi-3.5-mini, Phi-3.5-vision, y la última incorporación, Phi-3.5-MoE, un modelo de Mezcla de Expertos.
Phi-3.5-mini está optimizado para un mayor soporte multilingüe con una impresionante longitud de contexto de 128K. A pesar de su menor tamaño, ofrece un rendimiento que rivaliza con modelos más grandes, gracias a rigurosas mejoras mediante el ajuste fino supervisado, la optimización proximal de políticas y la optimización directa de preferencias, que garantizan una adherencia precisa a las instrucciones.
Phi-3.5-vision es un modelo multimodal vanguardista y ligero que se entrenó con los conjuntos de datos compuestos por datos sintéticos y sitios web públicos filtrados. Destaca en la comprensión y el razonamiento de imágenes de varios fotogramas, por lo que es ideal para la comparación detallada de imágenes, el resumen/relato de varias imágenes y el resumen de vídeos, con un amplio potencial de aplicación.
El modelo destacado, Phi-3,5-MoE, presenta una arquitectura de Mezcla de Expertos con 16 expertos y 6.600 millones de parámetros activos. Ofrece un rendimiento excepcional con una latencia reducida y una seguridad robusta, junto con un amplio soporte multilingüe.
La familia de modelos Phi-3.5 ofrece soluciones rentables y de alto rendimiento para la comunidad de código abierto, avanzando en pequeños modelos de lenguaje e IA generativa.
Para conocer la arquitectura, las características y las aplicaciones de Phi-3, sigue el tutorial Phi-3: Manos a la obra con el modelo de IA más pequeño de Microsoft guide.
En esta sección, cargaremos el modelo Phi-3.5-mini-instruct y ejecutaremos la inferencia del modelo en la plataforma Kaggle.
pip.%%capture
%pip install -U transformers acceleratetext-generation con el modelo y el tokenizador. from transformers import AutoTokenizer,AutoModelForCausalLM,pipeline
import torch
base_model = "microsoft/Phi-3.5-mini-instruct"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the tallest building in the world?"}
]
# Apply the chat template to the messages
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# Generate the output using the pipeline
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
# Print the generated text
print(outputs[0]["generated_text"])Obtuvimos un resultado preciso y detallado.
<|system|>
You are a helpful assistant.<|end|>
<|user|>
What is the tallest building in the world?<|end|>
<|assistant|>
As of my knowledge cutoff in 2023, the tallest building in the world is the Burj Khalifa, located in Dubai, United Arab Emirates. It stands at a remarkable 828 meters (2,716.5 feet) tall once its antenna is included. Completed in January 2010, the Burj Khalifa marks a significant achievement in architecture and engineering, setting numerous records. It provides office space, luxury condominiums, and various leisure facilities. This landmark continues toprompt = """
In a call center environment, classify customer interactions as 'Fraudulent' or 'Non-Fraudulent'.
Consider factors such as the nature of the inquiry, caller verification details, transaction history, and any red flags raised during the call.
[Lisa Adams, contacts the call center claiming unauthorized transactions on her credit card statement. She demands a full refund, asserting that she has never visited the merchant in question.] =
"""
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])Como podemos ver, el modelo ha funcionado bastante bien, marcando la llamada como fraudulenta y proporcionando una explicación.
In a call center environment, classify customer interactions as 'Fraudulent' or 'Non-Fraudulent'.
Consider factors such as the nature of the inquiry, caller verification details, transaction history, and any red flags raised during the call.
[Lisa Adams, contacts the call center claiming unauthorized transactions on her credit card statement. She demands a full refund, asserting that she has never visited the merchant in question.] =
Call Interaction Classification: Fraudulent
Explanation:
The situation described by Lisa Adams indicates a potential case of credit card fraud. There are several red flags in this interaction that suggest the customer might be reporting unauthorized transactions:
1. The caller claims unauthorized transactions - This is a common indicator of fraud, especially if the transactions were for places or services the customer did not recognize or didn't patronize according to their personal knowledge or documented transaction history (e.g., no visits to theSi tienes problemas para ejecutar el modelo en la plataforma Kaggle, consulta la página Inferencia del modelo simple de Phi-3.5 cuaderno Kaggle. Viene con una configuración y un código preconstruidos junto con las salidas.
En esta guía, aprenderemos a cargar y procesar los datos de clasificación de texto de Comercio Electrónico. También cargaremos el modelo y el tokenizador, evaluaremos el modelo en el conjunto de datos de prueba antes del ajuste fino, construiremos el entrenador, ajustaremos el modelo en el conjunto de entrenamiento y probaremos el modelo después del ajuste fino.
Si eres nuevo en el proceso, no dejes de leer nuestra guía, Guía introductoria al perfeccionamiento del LLMy aprende la teoría que hay detrás del ajuste del LLM.
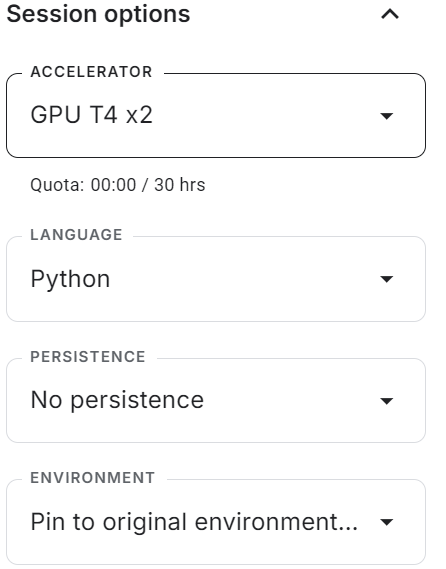
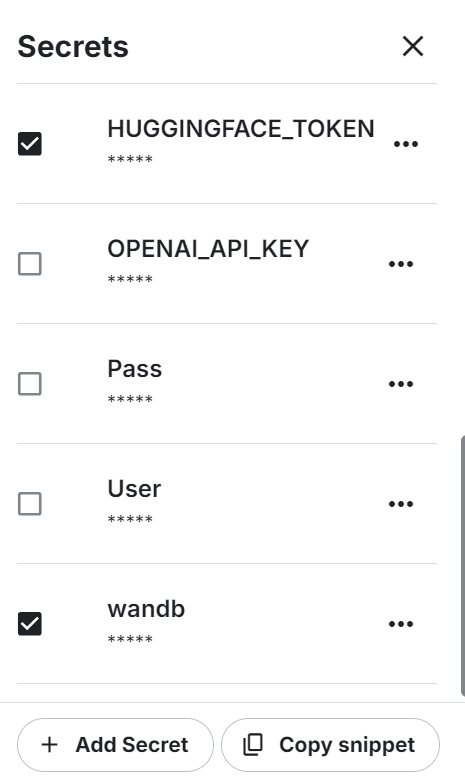
Inicia el nuevo cuaderno Kaggle con la aceleración por GPU activada. A continuación, asegúrate de que has establecido la Cara de Abrazo y el token de la API de Pesos y Sesgos como variables de entorno utilizando los secretos de Kaggle.
Instala todos los paquetes Python necesarios.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trlConéctate al servicio Pesos y sesgos, firma la clave API e inicia el nuevo proyecto.
import wandb
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Phi-3.5-it on Ecommerce Text Classification',
job_type="training",
anonymous="allow"
Por último, carga todos los paquetes y funciones de Python necesarios que vayamos a utilizar durante el proceso de ajuste y evaluación.
import numpy as np
import pandas as pd
import os
from tqdm import tqdm
import bitsandbytes as bnb
import torch
import torch.nn as nn
import transformers
from datasets import Dataset
from peft import LoraConfig, PeftConfig
from trl import SFTTrainer
from trl import setup_chat_format
from transformers import (AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging)
from sklearn.metrics import (accuracy_score,
classification_report,
confusion_matrix)
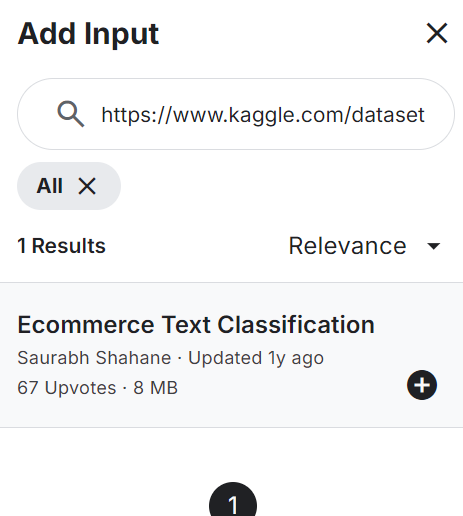
from sklearn.model_selection import train_test_splitAñade la Clasificación de textos de comercio electrónico a tu bloc de notas, como se muestra a continuación. El conjunto de datos consta de dos columnas: etiquetas (categorías de comercio electrónico) y descripciones textuales del producto.
Carga el archivo CSV, procésalo y visualiza las 5 filas superiores.
df = pd.read_csv("/kaggle/input/ecommerce-text-classification/ecommerceDataset.csv")
df.columns = ["label","text"]
df.loc[:,'label'] = df.loc[:,'label'].str.replace('Clothing & Accessories','Clothing')
df.head()El conjunto de datos consta de la descripción de los productos y la etiqueta de categoría.

Baraja el conjunto de datos y selecciona sólo las 2000 filas superiores. Se trata de una guía de ejemplo, pensada para acelerar el proceso de ajuste mediante la puesta a punto del modelo en un conjunto limitado de muestras.
A continuación, dividiremos los datos en conjuntos de datos de entrenamiento, evaluación y prueba.
# Shuffle the DataFrame and select only 2000 rows
df = df.sample(frac=1, random_state=85).reset_index(drop=True).head(2000)
# Split the DataFrame
train_size = 0.8
eval_size = 0.1
# Calculate sizes
train_end = int(train_size * len(df))
eval_end = train_end + int(eval_size * len(df))
# Split the data
X_train = df[:train_end]
X_eval = df[train_end:eval_end]
X_test = df[eval_end:]Crearemos dos funciones. La función generate_prompt convertirá las columnas de texto del aviso, incluyendo instrucciones, descripciones de texto y etiquetas. La función generate_test_prompt es la misma pero sin la etiqueta.
# Define the prompt generation functions
def generate_prompt(data_point):
return f"""
Classify the E-commerce text into Electronics, Household, Books and Clothing.
text: {data_point["text"]}
label: {data_point["label"]}""".strip()
def generate_test_prompt(data_point):
return f"""
Classify the E-commerce text into Electronics, Household, Books and Clothing.
text: {data_point["text"]}
label: """.strip()
# Generate prompts for training and evaluation data
X_train.loc[:,'text'] = X_train.apply(generate_prompt, axis=1)
X_eval.loc[:,'text'] = X_eval.apply(generate_prompt, axis=1)
# Generate test prompts and extract true labels
y_true = X_test.loc[:,'label']
X_test = pd.DataFrame(X_test.apply(generate_test_prompt, axis=1), columns=["text"])Convierte los marcos de datos de entrenamiento y evaluación de pandas en los conjuntos de datos Cara Abrazada.
# Convert to datasets
train_data = Dataset.from_pandas(X_train[["text"]])
eval_data = Dataset.from_pandas(X_eval[["text"]])
train_data['text'][3]El texto consta de instrucciones del sistema, una descripción textual del producto y una etiqueta.

Carga el modelo cuantificado de 4 bits y el tokenizador del Hub Cara Abrazada utilizando el ID del repositorio. A continuación, configura el modelo y el tokenizador para que estén listos para ser utilizados.
base_model_name = "microsoft/Phi-3.5-mini-instruct"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16",
)
model = AutoModelForCausalLM.from_pretrained(
base_model_name,
device_map="auto",
torch_dtype="float16",
quantization_config=bnb_config,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
tokenizer.pad_token_id = tokenizer.eos_token_idTenemos que evaluar el modelo base antes de afinarlo para determinar si el afinamiento ha mejorado los resultados o no. Para ello, crearemos una función predict que tome el conjunto de datos de prueba y genere categorías de comercio electrónico basadas en el producto y la descripción del texto.
def predict(test, model, tokenizer):
y_pred = []
categories = ["Electronics", "Household", "Books", "Clothing"]
for i in tqdm(range(len(test))):
prompt = test.iloc[i]["text"]
pipe = pipeline(task="text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=4,
temperature=0.1)
result = pipe(prompt)
answer = result[0]['generated_text'].split("label:")[-1].strip()
# Determine the predicted category
for category in categories:
if category.lower() in answer.lower():
y_pred.append(category)
break
else:
y_pred.append("none")
return y_pred
y_pred = predict(X_test, model, tokenizer)Tenemos una lista de categorías predichas, y ahora las compararemos con las categorías reales para generar el informe de evaluación del modelo. La función "evaluar" toma una lista de categorías previstas y reales y genera un informe de evaluación detallado. Este informe incluye la precisión media, la precisión individual de cada categoría, un informe de clasificación y una matriz de confusión.
def evaluate(y_true, y_pred):
labels = ["Electronics", "Household", "Books", "Clothing"]
mapping = {label: idx for idx, label in enumerate(labels)}
def map_func(x):
return mapping.get(x, -1) # Map to -1 if not found, but should not occur with correct data
y_true_mapped = np.vectorize(map_func)(y_true)
y_pred_mapped = np.vectorize(map_func)(y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_true=y_true_mapped, y_pred=y_pred_mapped)
print(f'Accuracy: {accuracy:.3f}')
# Generate accuracy report
unique_labels = set(y_true_mapped) # Get unique labels
for label in unique_labels:
label_indices = [i for i in range(len(y_true_mapped)) if y_true_mapped[i] == label]
label_y_true = [y_true_mapped[i] for i in label_indices]
label_y_pred = [y_pred_mapped[i] for i in label_indices]
label_accuracy = accuracy_score(label_y_true, label_y_pred)
print(f'Accuracy for label {labels[label]}: {label_accuracy:.3f}')
# Generate classification report
class_report = classification_report(y_true=y_true_mapped, y_pred=y_pred_mapped, target_names=labels, labels=list(range(len(labels))))
print('\nClassification Report:')
print(class_report)
# Generate confusion matrix
conf_matrix = confusion_matrix(y_true=y_true_mapped, y_pred=y_pred_mapped, labels=list(range(len(labels))))
print('\nConfusion Matrix:')
print(conf_matrix)
evaluate(y_true, y_pred)Alcanzamos una precisión media del 65%. Determinemos si el ajuste fino puede mejorar esta puntuación.
Accuracy: 0.645
Accuracy for label Electronics: 0.950
Accuracy for label Household: 0.531
Accuracy for label Books: 0.561
Accuracy for label Clothing: 0.658
Classification Report:
precision recall f1-score support
Electronics 0.46 0.95 0.62 40
Household 0.83 0.53 0.65 81
Books 0.96 0.56 0.71 41
Clothing 0.86 0.66 0.75 38
micro avg 0.69 0.65 0.67 200
macro avg 0.78 0.67 0.68 200
weighted avg 0.79 0.65 0.67 200
Confusion Matrix:
[[38 0 1 0]
[33 43 0 2]
[ 9 6 23 2]
[ 2 3 0 25]]Extrae el nombre del modelo lineal del modelo.
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)
modules['gate_up_proj', 'down_proj', 'qkv_proj', 'o_proj']Utiliza el nombre del módulo lineal para crear la LoRA. Sólo afinaremos el LoRA y dejaremos el resto del modelo para ahorrar memoria y acelerar el tiempo de entrenamiento.
A continuación, configura los hiperparámetros del modelo para el entorno Kaggle. Puedes cambiar estos parámetros para mejorar la precisión y reducir el tiempo de entrenamiento en función de tu máquina. Para saber más sobre cada hiperparámetro, sigue el enlace Puesta a punto de Llama 2 tutorial.
A continuación, configuraremos un entrenador de ajuste fino supervisado (SFT) y proporcionaremos un conjunto de datos de entrenamiento y evaluación, la configuración de LoRA, el argumento de entrenamiento, el tokenizador y el modelo.
output_dir="Phi-3.5-mini-instruct"
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules,
)
training_arguments = TrainingArguments(
output_dir=output_dir, # directory to save and repository id
num_train_epochs=1, # number of training epochs
per_device_train_batch_size=1, # batch size per device during training
gradient_accumulation_steps=4, # number of steps before performing a backward/update pass
gradient_checkpointing=True, # use gradient checkpointing to save memory
optim="paged_adamw_8bit",
logging_steps=1,
learning_rate=2e-5, # learning rate, based on QLoRA paper
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3, # max gradient norm based on QLoRA paper
max_steps=-1,
warmup_ratio=0.03, # warmup ratio based on QLoRA paper
group_by_length=False,
lr_scheduler_type="cosine", # use cosine learning rate scheduler
report_to="wandb", # report metrics to w&b
eval_strategy="steps", # save checkpoint every epoch
eval_steps = 0.2
)
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_data,
eval_dataset=eval_data,
peft_config=peft_config,
dataset_text_field="text",
tokenizer=tokenizer,
max_seq_length=512,
packing=False,
dataset_kwargs={
"add_special_tokens": False,
"append_concat_token": False,
}
)Utilizaremos la función .train para iniciar el proceso de ajuste.
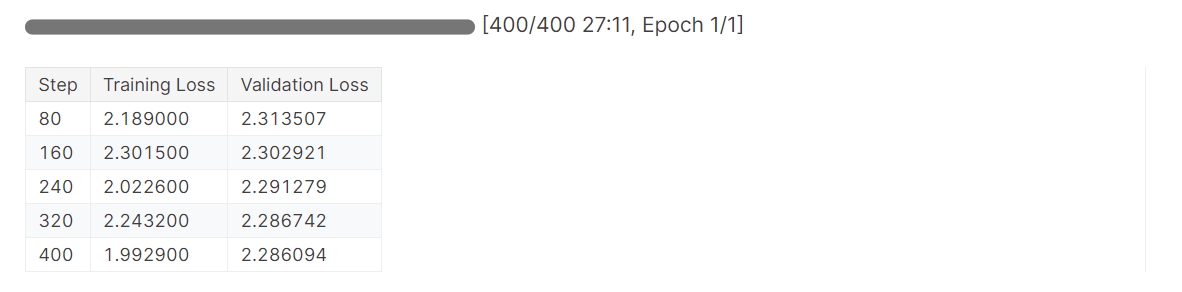
# Train model
trainer.train()La pérdida se ha reducido gradualmente, y podríamos haber obtenido resultados aún mejores con más épocas.
Finaliza la ejecución de ponderaciones y sesgos para generar el informe de evaluación.
wandb.finish()
model.config.use_cache = True
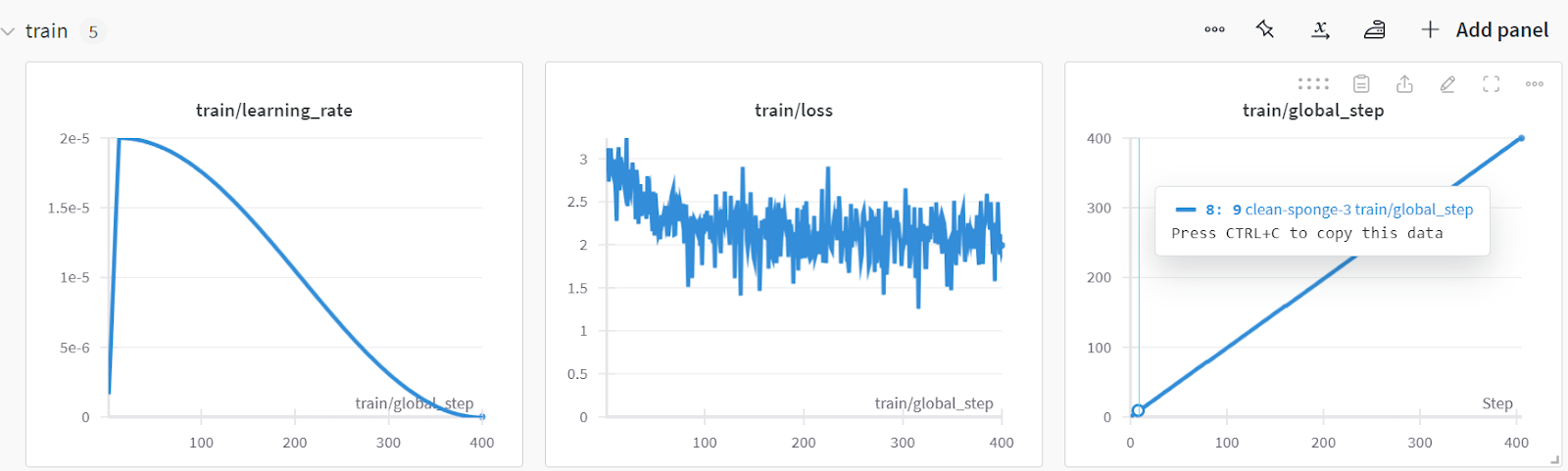
Puedes analizar el rendimiento del modelo visitando el sitio web Pesos y Sesgos, seleccionando tu proyecto y viendo el análisis de entrenamiento.
Guarda el modelo y el tokenizador localmente para poder utilizarlos más tarde en la fusión de modelos y envíalos al servidor remoto.
# Save trained model and tokenizer
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)Esta guía contiene bastante código. Si buscas una solución más sencilla, puedes poner a punto un modelo de código abierto siguiendo la Guía para principiantes de LlaMA-Factory WebUI de : Perfeccionamiento de LLMs tutorial. Para una solución aún más sencilla en la que no tengas que preocuparte por los problemas de hardware, te recomendamos encarecidamente el Ajuste fino GPT-4o Mini: Guía paso a paso tutorial. Esto te ayudará a afinar en la nube con un código mínimo.
Comprobemos si el rendimiento del modelo mejoró tras el ajuste fino. Primero generaremos una lista de etiquetas predicadas y se la proporcionaremos a la función evaluate junto con las etiquetas reales.
y_pred = predict(X_test, model, tokenizer)
evaluate(y_true, y_pred)La precisión del modelo mejoró aproximadamente un 32,31%, y el resto de las métricas de rendimiento son asombrosas. Aparte de la categoría Libros, el modelo fue capaz de identificar las categorías con bastante precisión.
Accuracy: 0.860
Accuracy for label Electronics: 0.825
Accuracy for label Household: 0.926
Accuracy for label Books: 0.683
Accuracy for label Clothing: 0.947
Classification Report:
precision recall f1-score support
Electronics 0.97 0.82 0.89 40
Household 0.88 0.93 0.90 81
Books 0.90 0.68 0.78 41
Clothing 0.88 0.95 0.91 38
micro avg 0.90 0.86 0.88 200
macro avg 0.91 0.85 0.87 200
weighted avg 0.90 0.86 0.88 200
Confusion Matrix:
[[33 6 1 0]
[ 1 75 2 3]
[ 0 3 28 2]
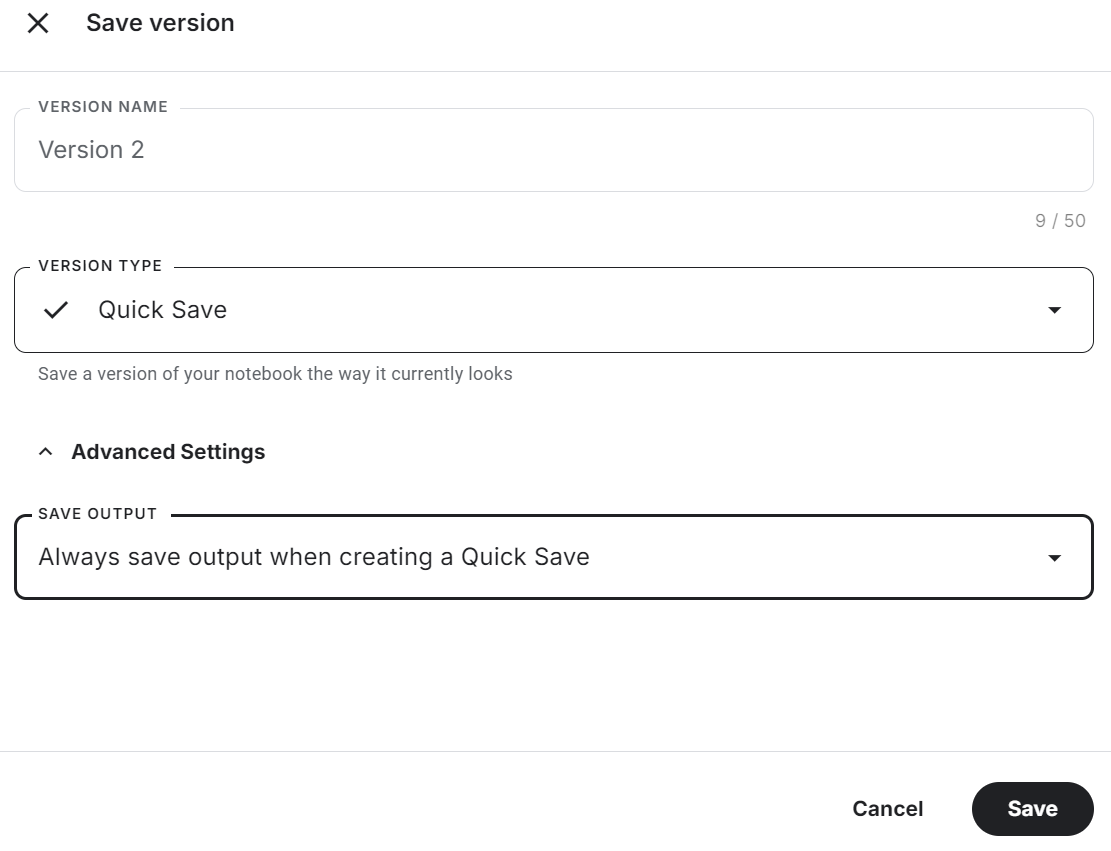
[ 0 1 0 36]]Asegúrate de guardar el cuaderno Kaggle haciendo clic en el botón "Guardar versión" de la parte superior derecha. A continuación, selecciona la opción de guardado rápido y cambia la opción de guardar salida para que incluya guardar el archivo del modelo y todo el código.
Si te encuentras con problemas al ajustar el modelo, consulta el Ajuste fino de Phi-3.5 para la clasificación de textos cuaderno Kaggle.
Para fusionar y exportar el modelo a Cara de Abrazo, primero crearemos un nuevo cuaderno Kaggle y añadiremos el cuaderno guardado para acceder al modelo afinado y al tokenizador.
Añadir otro cuaderno Kaggle es similar a añadir un conjunto de datos y un modelo. Pulsa el botón "+ Añadir entrada", pega el enlace del cuaderno y pulsa el botón añadir.
Establecer la API de Cara Abrazada como variable de entorno utilizando los secretos de Kaggle e instalar todos los paquetes Python necesarios para cargar y fusionar el modelo.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peftEstablece las variables del modelo base y del modelo afinado con el ID del modelo y la ubicación del adoptante del modelo.
# Model
base_model = "microsoft/Phi-3.5-mini-instruct"
fine_tuned_model = "/kaggle/input/fine-tune-phi-3-5-for-text-classification/Phi-3.5-mini-instruct/"Carga el modelo completo del centro Cara Abrazada junto al tokenizador.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)Fusiona el modelo base con el adoptador utilizando dos líneas de código.
# Merge adapter with base model
model = PeftModel.from_pretrained(base_model_reload, fine_tuned_model)
model = model.merge_and_unload()Para comprobar si el modelo se ha fusionado correctamente, crearemos una canalización de generación de texto con el modelo fusionado y el tokenizador, y pasaremos la consulta de ejemplo para generar la respuesta.
text = "Inalsa Dazzle Glass Top, 3 Burner Gas Stove with Rust Proof Powder Coated Body, Black Toughened Glass Top, 2 Medium and 1 Small High Efficiency Brass Burners, Aluminum Mixing Tubes, Powder Coated Body, Inbuilt Stainless Steel Drip Trays, 360 degree Swivel Nozzle,Bigger Legs to Facilitate Cleaning Under Cooktop"
prompt = f"""Classify the E-commerce text into Electronics, Household, Books and Clothing.
text: {text}
label: """.strip()
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipe(prompt, max_new_tokens=4, do_sample=True, temperature=0.1)
print(outputs[0]["generated_text"].split("label: ")[-1].strip())1].strip())El modelo ha predicho con exactitud la categoría de producción.
HouseholdGuardaremos el modelo completo localmente proporcionándole el directorio del modelo.
model_dir = "Phi-3.5-mini-instruct-Ecommerce-Text-Classification"
model.save_pretrained(model_dir)
tokenizer.save_pretrained(model_dir)Empuja el modelo guardado hacia el cubo Cara de Abrazo. En primer lugar, inicia sesión en la CLI de Cara Abrazada utilizando la clave API extraída de los secretos de Kaggle y, a continuación, utiliza la función push_to_hub para enviar tanto el modelo como el tokenizador.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
model.push_to_hub(model_dir, use_temp_dir=False)
tokenizer.push_to_hub(model_dir, use_temp_dir=False)Ha creado un nuevo repositorio de modelos y ha enviado todos los archivos al repositorio de modelos de Cara Abrazada.
Fuente: kingabzpro/Phi-3.5-mini-instruccion-Ecomercio-Texto-Clasificacion
Si tienes problemas para fusionar el modelo y exportarlo, consulta el Adaptador Phi-3.5 afinado al modelo completo Cuaderno Kaggle.
Además, echa un vistazo a nuestro tutorial más reciente sobre Afinar Llama 3.2 y utilizarla localmente: Guía paso a paso. En este tutorial, aprenderás a afinar el modelo en un conjunto de datos personalizado utilizando GPUs libres, a fusionar y exportar el modelo al Hugging Face Hub, y a convertir el modelo afinado al formato GGUF para poder utilizarlo localmente con la aplicación Jan.
Los grandes modelos lingüísticos son cada vez más pequeños y eficaces, lo que reduce los costes operativos y mejora la adaptabilidad en diversos campos. En este tutorial, exploramos los modelos Phi-3.5 Mini, Vision y MoE. También aprendimos a acceder a los modelos Phi-3.5 Mini utilizando los Cuadernos Kaggle.
A continuación, afinamos los modelos en datos de clasificación y evaluamos su rendimiento, consiguiendo una mejora significativa del 65% al 86% de precisión, un logro notable. Este rendimiento no se consigue sólo con la RAG o la llamada a funciones.
Por último, integramos el LoRA con el modelo base y exportamos el modelo completo al Hugging Face Hub, donde está disponible para que lo utilice todo el mundo.
El siguiente paso en tu viaje es construir un proyecto siguiendo la lista de 12 proyectos LLM para todos los niveles. Incluye proyectos LLM para principiantes, estudiantes de nivel intermedio, becarios de último curso y expertos. Cada proyecto incluye un código fuente, una guía visual y enlaces de apoyo.
Los mejores cursos LLM
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Dimitri Didmanidze

