
Cours
Introduction aux LLM en Python
3 h
33.8K
Avec l'introduction de la série Phi-3.5, Microsoft a rejoint le paysage concurrentiel des grands modèles de langage et de Meta AI. Cette série comprend un petit modèle de langage, un modèle de langage de vision et emploie un modèle de langage de vision. mélange d'experts pour obtenir des performances de premier ordre.
Dans ce tutoriel, nous allons explorer la famille de modèles Microsoft Phi-3.5. Nous chargerons le modèle Phi-3.5-mini-instruction et l'ajusterons pour classer les produits du commerce électronique sur la base de leurs descriptions textuelles. Dans les dernières étapes, nous montrerons comment fusionner la LoRA (Low-Rank Adaptation) avec le modèle de base et la pousser jusqu'à Hugging Face. Cela permettra un déploiement efficace dans le cloud, rendant le modèle accessible à diverses applications.
Prenez le Maîtriser les concepts des grands modèles de langage (LLM) et découvrez les applications des LLM, les méthodologies de formation, les considérations éthiques et les dernières recherches.

Image par l'auteur
Le Microsoft Phi-3.5 introduit trois modèles innovants : Phi-3.5-mini, Phi-3.5-vision et le dernier né, Phi-3.5-MoE, un modèle de mélange d'experts.
Phi-3.5-mini est optimisé pour un support multilingue amélioré avec une longueur de contexte impressionnante de 128K. Malgré sa taille réduite, il offre des performances qui rivalisent avec les modèles plus grands, grâce à des améliorations rigoureuses par le biais d'un réglage fin supervisé, d'une optimisation proximale de la politique et d'une optimisation directe des préférences, garantissant un respect précis des instructions.
Phi-3.5-vision est un modèle multimodal léger de pointe qui a été entraîné sur des ensembles de données composés de données synthétiques et de sites web publics filtrés. Il excelle dans la compréhension et le raisonnement d'images multiples, ce qui le rend idéal pour la comparaison détaillée d'images, le résumé/la narration d'images multiples et le résumé de vidéos, avec un large potentiel d'application.
Le modèle le plus remarquable, Phi-3.5-MoE, est doté d'une architecture de mélange d'experts avec 16 experts et 6,6 milliards de paramètres actifs. Il offre des performances exceptionnelles avec une latence réduite et une sécurité robuste, ainsi qu'un support multilingue complet.
La famille de modèles Phi-3.5 offre des solutions rentables et performantes à la communauté open-source, en faisant progresser les petits modèles de langage et l'IA générative.
Pour en savoir plus sur l'architecture, les caractéristiques et les applications du Phi-3, suivez le tutoriel Phi-3 Tutorial : Découvrez le plus petit modèle d'intelligence artificielle de Microsoft guide.
Dans cette section, nous allons charger le modèle Phi-3.5-mini-instruct et exécuter l'inférence du modèle dans la plateforme Kaggle.
pip.%%capture
%pip install -U transformers acceleratetext-generation avec le modèle et le tokenizer. from transformers import AutoTokenizer,AutoModelForCausalLM,pipeline
import torch
base_model = "microsoft/Phi-3.5-mini-instruct"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the tallest building in the world?"}
]
# Apply the chat template to the messages
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# Generate the output using the pipeline
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
# Print the generated text
print(outputs[0]["generated_text"])Nous avons obtenu un résultat précis et détaillé.
<|system|>
You are a helpful assistant.<|end|>
<|user|>
What is the tallest building in the world?<|end|>
<|assistant|>
As of my knowledge cutoff in 2023, the tallest building in the world is the Burj Khalifa, located in Dubai, United Arab Emirates. It stands at a remarkable 828 meters (2,716.5 feet) tall once its antenna is included. Completed in January 2010, the Burj Khalifa marks a significant achievement in architecture and engineering, setting numerous records. It provides office space, luxury condominiums, and various leisure facilities. This landmark continues toprompt = """
In a call center environment, classify customer interactions as 'Fraudulent' or 'Non-Fraudulent'.
Consider factors such as the nature of the inquiry, caller verification details, transaction history, and any red flags raised during the call.
[Lisa Adams, contacts the call center claiming unauthorized transactions on her credit card statement. She demands a full refund, asserting that she has never visited the merchant in question.] =
"""
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])Comme nous pouvons le voir, le modèle a bien fonctionné, signalant l'appel comme frauduleux et fournissant une explication.
In a call center environment, classify customer interactions as 'Fraudulent' or 'Non-Fraudulent'.
Consider factors such as the nature of the inquiry, caller verification details, transaction history, and any red flags raised during the call.
[Lisa Adams, contacts the call center claiming unauthorized transactions on her credit card statement. She demands a full refund, asserting that she has never visited the merchant in question.] =
Call Interaction Classification: Fraudulent
Explanation:
The situation described by Lisa Adams indicates a potential case of credit card fraud. There are several red flags in this interaction that suggest the customer might be reporting unauthorized transactions:
1. The caller claims unauthorized transactions - This is a common indicator of fraud, especially if the transactions were for places or services the customer did not recognize or didn't patronize according to their personal knowledge or documented transaction history (e.g., no visits to theSi vous rencontrez des problèmes pour exécuter le modèle sur la plateforme Kaggle, veuillez vous référer à la section Modèle simple d'inférence de Phi-3.5 dans le carnet Kaggle. Il est livré avec une configuration et un code préconstruits, ainsi que des sorties.
Dans ce guide, nous allons apprendre à charger et à traiter les données de classification des textes de commerce électronique. Nous chargerons également le modèle et le tokenizer, évaluerons le modèle sur l'ensemble de données de test avant de l'affiner, construirons l'entraîneur, affinerons le modèle sur l'ensemble d'entraînement et testerons le modèle après l'avoir affiné.
Si vous êtes novice en la matière, n'oubliez pas de lire notre guide, Guide d'introduction à l'affinage des LLMet apprenez la théorie qui sous-tend la mise au point du LLM.
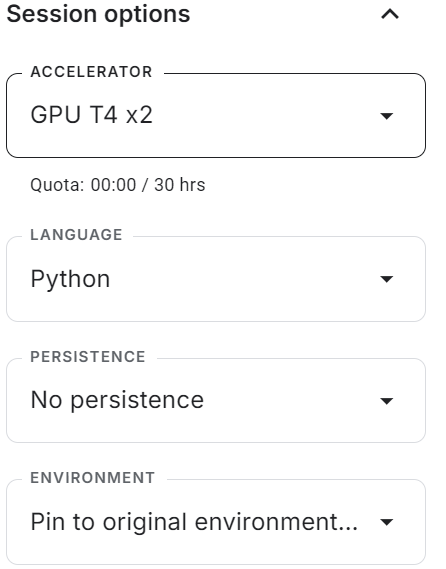
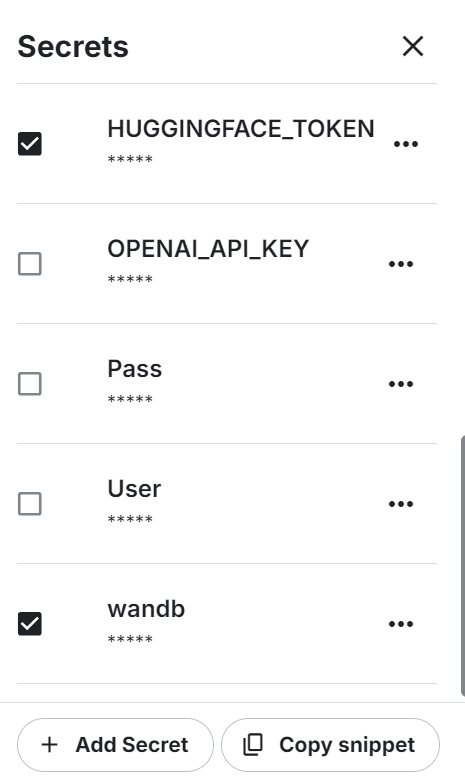
Lancez le nouveau notebook Kaggle avec l'accélération GPU activée. Ensuite, assurez-vous d'avoir défini le Hugging Face et le jeton API Weights & Biases comme variables d'environnement à l'aide des secrets Kaggle.
Installez tous les paquets Python nécessaires.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trlConnectez-vous au service Weights and biases, signez la clé API et lancez le nouveau projet.
import wandb
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Phi-3.5-it on Ecommerce Text Classification',
job_type="training",
anonymous="allow"
Enfin, chargez tous les paquets et fonctions Python nécessaires que nous allons utiliser au cours du processus de mise au point et d'évaluation.
import numpy as np
import pandas as pd
import os
from tqdm import tqdm
import bitsandbytes as bnb
import torch
import torch.nn as nn
import transformers
from datasets import Dataset
from peft import LoraConfig, PeftConfig
from trl import SFTTrainer
from trl import setup_chat_format
from transformers import (AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging)
from sklearn.metrics import (accuracy_score,
classification_report,
confusion_matrix)
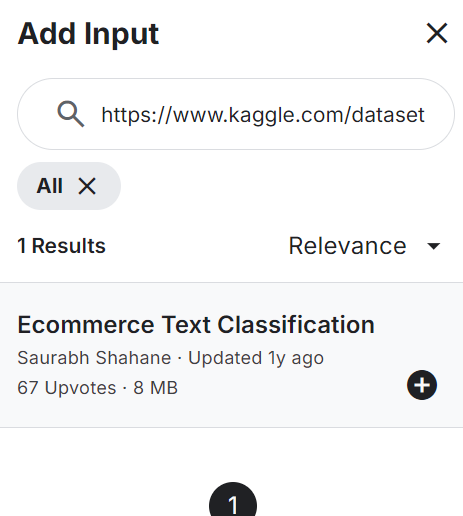
from sklearn.model_selection import train_test_splitAjoutez la Classification de texte pour le commerce électronique à votre notebook, comme indiqué ci-dessous. L'ensemble de données se compose de deux colonnes : les étiquettes (catégories de commerce électronique) et les descriptions textuelles du produit.
Chargez le fichier CSV, traitez-le et affichez les 5 premières lignes.
df = pd.read_csv("/kaggle/input/ecommerce-text-classification/ecommerceDataset.csv")
df.columns = ["label","text"]
df.loc[:,'label'] = df.loc[:,'label'].str.replace('Clothing & Accessories','Clothing')
df.head()L'ensemble de données se compose de la description des produits et de l'étiquette de la catégorie.

Mélangez l'ensemble des données et ne sélectionnez que les 2000 premières lignes. Il s'agit d'un exemple de guide, destiné à accélérer le processus de mise au point en affinant le modèle sur un ensemble limité d'échantillons.
Ensuite, nous diviserons les données en ensembles de données de formation, d'évaluation et de test.
# Shuffle the DataFrame and select only 2000 rows
df = df.sample(frac=1, random_state=85).reset_index(drop=True).head(2000)
# Split the DataFrame
train_size = 0.8
eval_size = 0.1
# Calculate sizes
train_end = int(train_size * len(df))
eval_end = train_end + int(eval_size * len(df))
# Split the data
X_train = df[:train_end]
X_eval = df[train_end:eval_end]
X_test = df[eval_end:]Nous allons créer deux fonctions. La fonction generate_prompt convertit les colonnes de texte de l'invite, y compris les instructions, les descriptions de texte et les étiquettes. La fonction generate_test_prompt est la même, mais sans l'étiquette.
# Define the prompt generation functions
def generate_prompt(data_point):
return f"""
Classify the E-commerce text into Electronics, Household, Books and Clothing.
text: {data_point["text"]}
label: {data_point["label"]}""".strip()
def generate_test_prompt(data_point):
return f"""
Classify the E-commerce text into Electronics, Household, Books and Clothing.
text: {data_point["text"]}
label: """.strip()
# Generate prompts for training and evaluation data
X_train.loc[:,'text'] = X_train.apply(generate_prompt, axis=1)
X_eval.loc[:,'text'] = X_eval.apply(generate_prompt, axis=1)
# Generate test prompts and extract true labels
y_true = X_test.loc[:,'label']
X_test = pd.DataFrame(X_test.apply(generate_test_prompt, axis=1), columns=["text"])Convertissez les dataframes de données de formation et d'évaluation pandas en ensembles de données Hugging Face.
# Convert to datasets
train_data = Dataset.from_pandas(X_train[["text"]])
eval_data = Dataset.from_pandas(X_eval[["text"]])
train_data['text'][3]Le texte se compose d'instructions relatives au système, d'une description du produit et d'une étiquette.

Chargez le modèle quantifié à 4 bits et le tokenizer à partir du Hugging Face Hub en utilisant l'identifiant du référentiel. Ensuite, configurez le modèle et le tokenizer pour qu'ils soient prêts à être utilisés.
base_model_name = "microsoft/Phi-3.5-mini-instruct"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16",
)
model = AutoModelForCausalLM.from_pretrained(
base_model_name,
device_map="auto",
torch_dtype="float16",
quantization_config=bnb_config,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
tokenizer.pad_token_id = tokenizer.eos_token_idNous devons évaluer le modèle de base avant de l'affiner afin de déterminer si l'affinement a amélioré les résultats ou non. Pour ce faire, nous allons créer une fonction predict qui prend l'ensemble de données de test et génère des catégories de commerce électronique sur la base du produit et de la description textuelle.
def predict(test, model, tokenizer):
y_pred = []
categories = ["Electronics", "Household", "Books", "Clothing"]
for i in tqdm(range(len(test))):
prompt = test.iloc[i]["text"]
pipe = pipeline(task="text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=4,
temperature=0.1)
result = pipe(prompt)
answer = result[0]['generated_text'].split("label:")[-1].strip()
# Determine the predicted category
for category in categories:
if category.lower() in answer.lower():
y_pred.append(category)
break
else:
y_pred.append("none")
return y_pred
y_pred = predict(X_test, model, tokenizer)Nous disposons d'une liste de catégories prédites et nous allons maintenant les comparer avec les catégories réelles pour générer le rapport d'évaluation du modèle. La fonction "évaluer" prend une liste de catégories prédites et réelles et génère un rapport d'évaluation détaillé. Ce rapport comprend la précision moyenne, la précision individuelle pour chaque catégorie, un rapport de classification et une matrice de confusion.
def evaluate(y_true, y_pred):
labels = ["Electronics", "Household", "Books", "Clothing"]
mapping = {label: idx for idx, label in enumerate(labels)}
def map_func(x):
return mapping.get(x, -1) # Map to -1 if not found, but should not occur with correct data
y_true_mapped = np.vectorize(map_func)(y_true)
y_pred_mapped = np.vectorize(map_func)(y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_true=y_true_mapped, y_pred=y_pred_mapped)
print(f'Accuracy: {accuracy:.3f}')
# Generate accuracy report
unique_labels = set(y_true_mapped) # Get unique labels
for label in unique_labels:
label_indices = [i for i in range(len(y_true_mapped)) if y_true_mapped[i] == label]
label_y_true = [y_true_mapped[i] for i in label_indices]
label_y_pred = [y_pred_mapped[i] for i in label_indices]
label_accuracy = accuracy_score(label_y_true, label_y_pred)
print(f'Accuracy for label {labels[label]}: {label_accuracy:.3f}')
# Generate classification report
class_report = classification_report(y_true=y_true_mapped, y_pred=y_pred_mapped, target_names=labels, labels=list(range(len(labels))))
print('\nClassification Report:')
print(class_report)
# Generate confusion matrix
conf_matrix = confusion_matrix(y_true=y_true_mapped, y_pred=y_pred_mapped, labels=list(range(len(labels))))
print('\nConfusion Matrix:')
print(conf_matrix)
evaluate(y_true, y_pred)Nous avons obtenu une précision moyenne de 65 %. Déterminons si un réglage fin peut améliorer ce score.
Accuracy: 0.645
Accuracy for label Electronics: 0.950
Accuracy for label Household: 0.531
Accuracy for label Books: 0.561
Accuracy for label Clothing: 0.658
Classification Report:
precision recall f1-score support
Electronics 0.46 0.95 0.62 40
Household 0.83 0.53 0.65 81
Books 0.96 0.56 0.71 41
Clothing 0.86 0.66 0.75 38
micro avg 0.69 0.65 0.67 200
macro avg 0.78 0.67 0.68 200
weighted avg 0.79 0.65 0.67 200
Confusion Matrix:
[[38 0 1 0]
[33 43 0 2]
[ 9 6 23 2]
[ 2 3 0 25]]Extraire le nom du modèle linéaire du modèle.
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)
modules['gate_up_proj', 'down_proj', 'qkv_proj', 'o_proj']Utilisez le nom du module linéaire pour créer le LoRA. Nous nous contenterons d'affiner le LoRA et laisserons le reste du modèle pour économiser de la mémoire et accélérer le temps de formation.
Ensuite, configurez les hyperparamètres du modèle pour l'environnement Kaggle. Vous pouvez modifier ces paramètres pour améliorer la précision et réduire le temps de formation en fonction de votre machine. Pour en savoir plus sur chaque hyperparamètre, suivez le lien suivant Le réglage fin du lama 2 pour en savoir plus sur les hyperparamètres.
Nous allons maintenant mettre en place un formateur de réglage fin supervisé (SFT) et fournir un ensemble de données de formation et d'évaluation, une configuration LoRA, un argument de formation, un tokenizer et un modèle.
output_dir="Phi-3.5-mini-instruct"
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules,
)
training_arguments = TrainingArguments(
output_dir=output_dir, # directory to save and repository id
num_train_epochs=1, # number of training epochs
per_device_train_batch_size=1, # batch size per device during training
gradient_accumulation_steps=4, # number of steps before performing a backward/update pass
gradient_checkpointing=True, # use gradient checkpointing to save memory
optim="paged_adamw_8bit",
logging_steps=1,
learning_rate=2e-5, # learning rate, based on QLoRA paper
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3, # max gradient norm based on QLoRA paper
max_steps=-1,
warmup_ratio=0.03, # warmup ratio based on QLoRA paper
group_by_length=False,
lr_scheduler_type="cosine", # use cosine learning rate scheduler
report_to="wandb", # report metrics to w&b
eval_strategy="steps", # save checkpoint every epoch
eval_steps = 0.2
)
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_data,
eval_dataset=eval_data,
peft_config=peft_config,
dataset_text_field="text",
tokenizer=tokenizer,
max_seq_length=512,
packing=False,
dataset_kwargs={
"add_special_tokens": False,
"append_concat_token": False,
}
)Nous utiliserons la fonction .train pour lancer le processus de réglage fin.
# Train model
trainer.train()La perte s'est progressivement réduite, et nous aurions pu obtenir de meilleurs résultats avec un plus grand nombre d'époques.
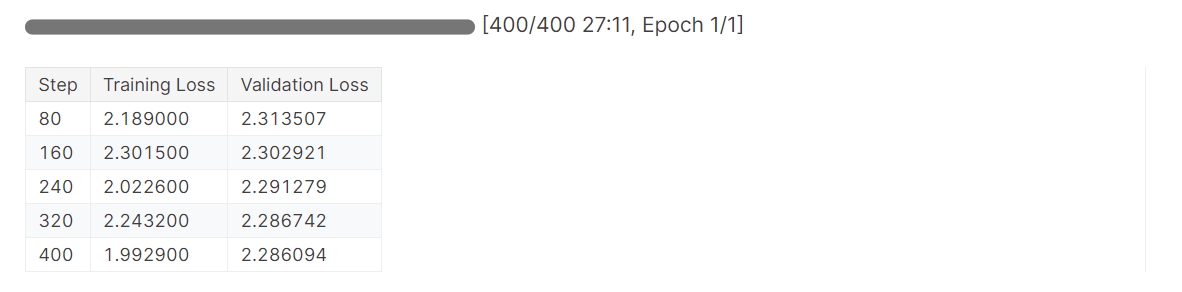
Terminez l'exécution de Pondérations et Biais pour générer le rapport d'évaluation.
wandb.finish()
model.config.use_cache = True
Vous pouvez analyser les performances du modèle en visitant le site Web Pondérations et biais, en sélectionnant votre projet et en consultant l'analyse de l'entraînement.
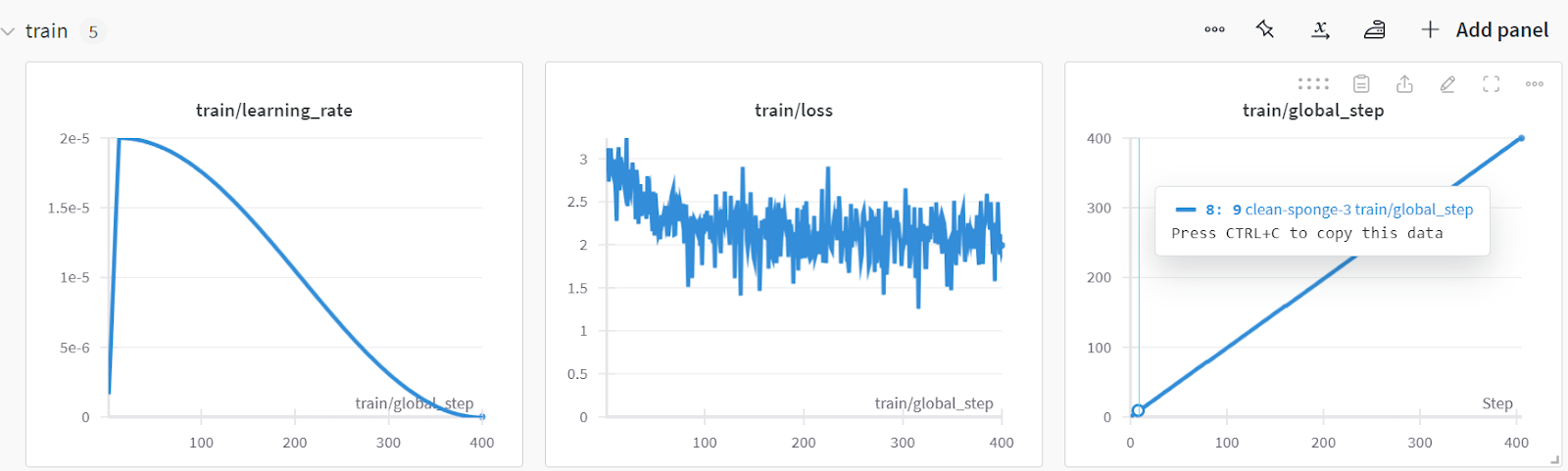
Enregistrez le modèle et le tokenizer localement afin de pouvoir les utiliser ultérieurement pour la fusion de modèles et les envoyer au serveur distant.
# Save trained model and tokenizer
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)Ce guide contient beaucoup de code. Si vous recherchez une solution plus simple, vous pouvez affiner un modèle open-source en suivant le guide du débutant de l'interface WebUI de LlaMA-Factory ( ) : Affiner les LLM tutoriel. Pour une solution encore plus simple où vous n'avez pas à vous soucier des problèmes matériels, nous vous recommandons vivement le Fine-tuning GPT-4o Mini : Un guide étape par étape tutorial. Cela vous permettra d'effectuer des ajustements sur le cloud avec un minimum de code.
Testons si la performance du modèle s'est améliorée après le réglage fin. Nous allons d'abord générer une liste d'étiquettes prédites et la fournir à la fonction evaluate avec les étiquettes réelles.
y_pred = predict(X_test, model, tokenizer)
evaluate(y_true, y_pred)La précision du modèle s'est améliorée d'environ 32,31 %, et les autres mesures de performance sont étonnantes. A l'exception de la catégorie Livres, le modèle a été capable d'identifier les catégories de manière assez précise.
Accuracy: 0.860
Accuracy for label Electronics: 0.825
Accuracy for label Household: 0.926
Accuracy for label Books: 0.683
Accuracy for label Clothing: 0.947
Classification Report:
precision recall f1-score support
Electronics 0.97 0.82 0.89 40
Household 0.88 0.93 0.90 81
Books 0.90 0.68 0.78 41
Clothing 0.88 0.95 0.91 38
micro avg 0.90 0.86 0.88 200
macro avg 0.91 0.85 0.87 200
weighted avg 0.90 0.86 0.88 200
Confusion Matrix:
[[33 6 1 0]
[ 1 75 2 3]
[ 0 3 28 2]
[ 0 1 0 36]]Veillez à sauvegarder le carnet Kaggle en cliquant sur le bouton "Save Version" en haut à droite. Ensuite, sélectionnez l'option d'enregistrement rapide et modifiez l'option d'enregistrement de sortie pour inclure l'enregistrement du fichier de modèle et de l'ensemble du code.
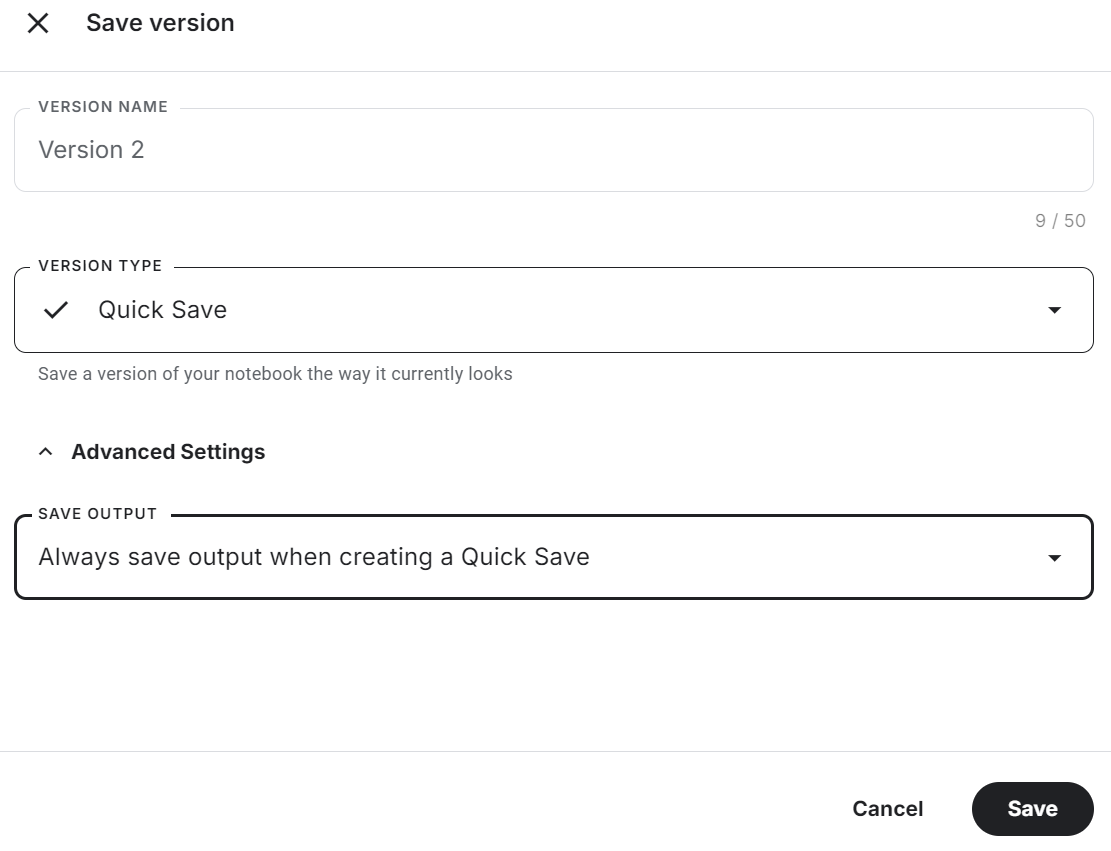
Si vous rencontrez des problèmes lors de la mise au point du modèle, veuillez vous référer à la section Mise au point de Phi-3.5 pour la classification de textes. Carnet Kaggle.
Pour fusionner et exporter le modèle vers Hugging Face, nous allons d'abord créer un nouveau notebook Kaggle et ajouter le notebook sauvegardé pour accéder au modèle affiné et au tokenizer.
L'ajout d'un autre carnet Kaggle est similaire à l'ajout d'un jeu de données et d'un modèle. Cliquez sur le bouton "+ Ajouter une entrée", collez le lien du carnet de notes, puis appuyez sur le bouton "Ajouter".
Définition de l'API Hugging Face en tant que variable d'environnement à l'aide des secrets Kaggle et installation de tous les packages Python nécessaires au chargement et à la fusion du modèle.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peftDéfinissez les variables du modèle de base et du modèle affiné avec l'ID du modèle et la localisation de l'adoptant du modèle.
# Model
base_model = "microsoft/Phi-3.5-mini-instruct"
fine_tuned_model = "/kaggle/input/fine-tune-phi-3-5-for-text-classification/Phi-3.5-mini-instruct/"Chargez le modèle complet du hub Hugging Face avec le tokenizer.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)Fusionnez le modèle de base avec l'adoptant en utilisant deux lignes de code.
# Merge adapter with base model
model = PeftModel.from_pretrained(base_model_reload, fine_tuned_model)
model = model.merge_and_unload()Pour tester si le modèle a été fusionné avec succès, nous allons créer un pipeline de génération de texte avec le modèle fusionné et le tokenizer, et passer l'exemple d'invite pour générer la réponse.
text = "Inalsa Dazzle Glass Top, 3 Burner Gas Stove with Rust Proof Powder Coated Body, Black Toughened Glass Top, 2 Medium and 1 Small High Efficiency Brass Burners, Aluminum Mixing Tubes, Powder Coated Body, Inbuilt Stainless Steel Drip Trays, 360 degree Swivel Nozzle,Bigger Legs to Facilitate Cleaning Under Cooktop"
prompt = f"""Classify the E-commerce text into Electronics, Household, Books and Clothing.
text: {text}
label: """.strip()
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipe(prompt, max_new_tokens=4, do_sample=True, temperature=0.1)
print(outputs[0]["generated_text"].split("label: ")[-1].strip())1].strip())Le modèle a prédit avec précision la catégorie de production.
HouseholdNous enregistrerons le modèle complet localement en lui fournissant le répertoire du modèle.
model_dir = "Phi-3.5-mini-instruct-Ecommerce-Text-Classification"
model.save_pretrained(model_dir)
tokenizer.save_pretrained(model_dir)Poussez le modèle sauvegardé vers le concentrateur Hugging Face. Tout d'abord, connectez-vous au CLI de Hugging Face à l'aide de la clé API extraite des secrets Kaggle, puis utilisez la fonction push_to_hub pour pousser à la fois le modèle et le tokenizer.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
model.push_to_hub(model_dir, use_temp_dir=False)
tokenizer.push_to_hub(model_dir, use_temp_dir=False)Il a créé un nouveau référentiel de modèles et a transféré tous les fichiers dans le référentiel de modèles de Hugging Face.
Source : kingabzpro/Phi-3.5-mini-instruct-Ecommerce-Text-Classification
Si vous avez des difficultés à fusionner le modèle et à l'exporter, veuillez consulter l'adaptateur Phi-3.5 Fine-tuned pour le modèle complet. Carnet Kaggle.
Jetez également un coup d'œil à notre nouveau tutoriel sur . Vous pourrez ainsi peaufiner Llama 3.2 et l'utiliser localement : Un guide étape par étape. Dans ce tutoriel, vous apprendrez à affiner le modèle sur un jeu de données personnalisé en utilisant des GPU gratuits, à fusionner et à exporter le modèle vers le Hugging Face Hub, et à convertir le modèle affiné au format GGUF afin qu'il puisse être utilisé localement avec l'application Jan.
Les grands modèles linguistiques sont de plus en plus petits et efficaces, ce qui permet de réduire les coûts opérationnels et d'améliorer l'adaptabilité dans différents domaines. Dans ce tutoriel, nous avons exploré les modèles Phi-3.5 Mini, Vision et MoE. Nous avons également appris à accéder aux modèles Phi-3.5 Mini en utilisant Kaggle Notebooks.
Ensuite, nous avons affiné les modèles sur des données de classification et évalué leurs performances, obtenant une amélioration significative de 65 % à 86 % de précision - un accomplissement remarquable. Une telle performance n'est pas réalisable par le biais du RAG ou de l'appel de fonction uniquement.
Enfin, nous avons intégré le LoRA au modèle de base et exporté le modèle complet vers le Hugging Face Hub, où il est à la disposition de tous.
L'étape suivante de votre parcours est de construire un projet en suivant la liste de 12 projets LLM pour tous les niveaux. Il comprend des projets LLM pour les débutants, les étudiants intermédiaires, les étudiants de dernière année et les experts. Chaque projet est accompagné d'un code source, d'un guide visuel et de liens complémentaires.
Principaux cours de LLM
Cours
Cours
Cours