
Kurs
Einführung in LLMs mit Python
3 Std.
33.7K
Microsoft hat sich mit der Einführung der Phi-3.5-Serie in die Wettbewerbslandschaft der großen Sprachmodelle neben Meta AI eingereiht. Diese Serie umfasst ein kleines Sprachmodell, ein Vision-Sprachmodell und verwendet eine Mixture-of-Experts Ansatz, um eine erstklassige Leistung zu erzielen.
In diesem Lernprogramm werden wir uns mit der Microsoft Phi-3.5-Modellfamilie beschäftigen. Wir laden das Phi-3.5-Mini-Instruct-Modell und passen es an, um E-Commerce-Produkte anhand ihrer Textbeschreibungen zu klassifizieren. In den letzten Schritten zeigen wir dir, wie du die LoRA (Low-Rank Adaptation) mit dem Basismodell verschmilzt und es zu Hugging Face pusht. Dies ermöglicht einen effizienten Cloud-Einsatz und macht das Modell für verschiedene Anwendungen zugänglich.
Nimm die Master Large Language Models (LLMs) Concepts und erfahre mehr über LLM-Anwendungen, Trainingsmethoden, ethische Überlegungen und die neueste Forschung.

Bild vom Autor
Die Microsoft Phi-3.5 Version führt drei innovative Modelle ein: Phi-3.5-mini, Phi-3.5-vision und die neueste Ergänzung, Phi-3.5-MoE, ein Mixture-of-Experts-Modell.
Phi-3.5-mini ist für eine verbesserte mehrsprachige Unterstützung mit einer beeindruckenden Kontextlänge von 128K optimiert. Trotz seiner geringen Größe bietet es eine Leistung, die mit größeren Modellen mithalten kann, dank rigoroser Verbesserungen durch überwachte Feinabstimmung, proximale Richtlinienoptimierung und direkte Präferenzoptimierung, die eine präzise Befolgung der Anweisungen gewährleisten.
Phi-3.5-vision ist ein hochmodernes, leichtgewichtiges multimodales Modell, das auf Datensätzen aus synthetischen Daten und gefilterten öffentlichen Websites trainiert wurde. Es zeichnet sich durch seine Fähigkeit aus, Bilder mit mehreren Bildern zu verstehen und Schlussfolgerungen zu ziehen, was es ideal für detaillierte Bildvergleiche, Zusammenfassungen von mehreren Bildern und Videozusammenfassungen macht und ein breites Anwendungspotenzial bietet.
Das herausragende Modell, Phi-3.5-MoE, verfügt über eine Mixture-of-Experts-Architektur mit 16 Experten und 6,6 Milliarden aktiven Parametern. Sie bietet eine außergewöhnliche Leistung mit reduzierter Latenzzeit und robuster Sicherheit sowie eine umfassende mehrsprachige Unterstützung.
Die Phi-3.5-Modellfamilie bietet kosteneffiziente, leistungsstarke Lösungen für die Open-Source-Community und bringt kleine Sprachmodelle und generative KI voran.
Wenn du mehr über die Phi-3 Architektur, die Funktionen und die Anwendungen erfahren möchtest, kannst du das Phi-3 Tutorial lesen: Hands-On mit Microsofts kleinstem KI-Modell guide.
In diesem Abschnitt laden wir das Phi-3.5-Mini-Instruct-Modell und führen die Modellinferenz auf der Kaggle-Plattform durch.
pip.%%capture
%pip install -U transformers acceleratetext-generation Pipeline mit Model und Tokenizer. from transformers import AutoTokenizer,AutoModelForCausalLM,pipeline
import torch
base_model = "microsoft/Phi-3.5-mini-instruct"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the tallest building in the world?"}
]
# Apply the chat template to the messages
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# Generate the output using the pipeline
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
# Print the generated text
print(outputs[0]["generated_text"])Wir haben ein genaues und detailliertes Ergebnis erhalten.
<|system|>
You are a helpful assistant.<|end|>
<|user|>
What is the tallest building in the world?<|end|>
<|assistant|>
As of my knowledge cutoff in 2023, the tallest building in the world is the Burj Khalifa, located in Dubai, United Arab Emirates. It stands at a remarkable 828 meters (2,716.5 feet) tall once its antenna is included. Completed in January 2010, the Burj Khalifa marks a significant achievement in architecture and engineering, setting numerous records. It provides office space, luxury condominiums, and various leisure facilities. This landmark continues toprompt = """
In a call center environment, classify customer interactions as 'Fraudulent' or 'Non-Fraudulent'.
Consider factors such as the nature of the inquiry, caller verification details, transaction history, and any red flags raised during the call.
[Lisa Adams, contacts the call center claiming unauthorized transactions on her credit card statement. She demands a full refund, asserting that she has never visited the merchant in question.] =
"""
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])Wie wir sehen können, hat das Modell recht gut funktioniert und den Anruf als betrügerisch gekennzeichnet und eine Erklärung geliefert.
In a call center environment, classify customer interactions as 'Fraudulent' or 'Non-Fraudulent'.
Consider factors such as the nature of the inquiry, caller verification details, transaction history, and any red flags raised during the call.
[Lisa Adams, contacts the call center claiming unauthorized transactions on her credit card statement. She demands a full refund, asserting that she has never visited the merchant in question.] =
Call Interaction Classification: Fraudulent
Explanation:
The situation described by Lisa Adams indicates a potential case of credit card fraud. There are several red flags in this interaction that suggest the customer might be reporting unauthorized transactions:
1. The caller claims unauthorized transactions - This is a common indicator of fraud, especially if the transactions were for places or services the customer did not recognize or didn't patronize according to their personal knowledge or documented transaction history (e.g., no visits to theWenn du Probleme bei der Ausführung des Modells auf der Kaggle-Plattform hast, lies bitte die Einfache Modellinferenz von Phi-3.5 Kaggle Notizbuch. Es wird mit einem vorgefertigten Setup und Code zusammen mit den Ausgaben geliefert.
In diesem Leitfaden lernst du, wie du Daten zur Klassifizierung von E-Commerce-Texten laden und verarbeiten kannst. Außerdem laden wir das Modell und den Tokenizer, evaluieren das Modell auf dem Testdatensatz vor der Feinabstimmung, erstellen den Trainer, nehmen die Feinabstimmung des Modells auf dem Trainingssatz vor und testen das Modell nach der Feinabstimmung.
Wenn du neu in diesem Prozess bist, solltest du unbedingt unseren Leitfaden lesen, Einleitender Leitfaden zur Feinabstimmung von LLMsund lerne die Theorie hinter der LLM-Feinabstimmung kennen.
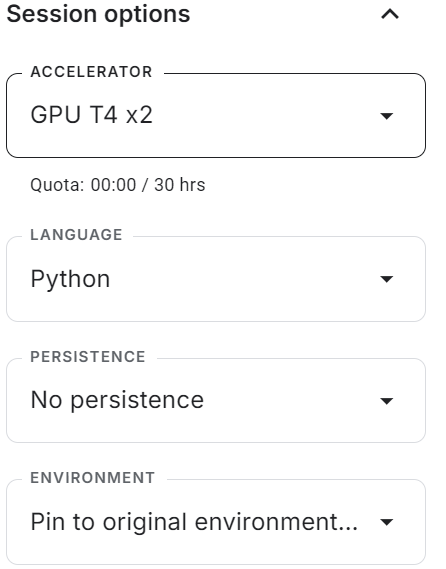
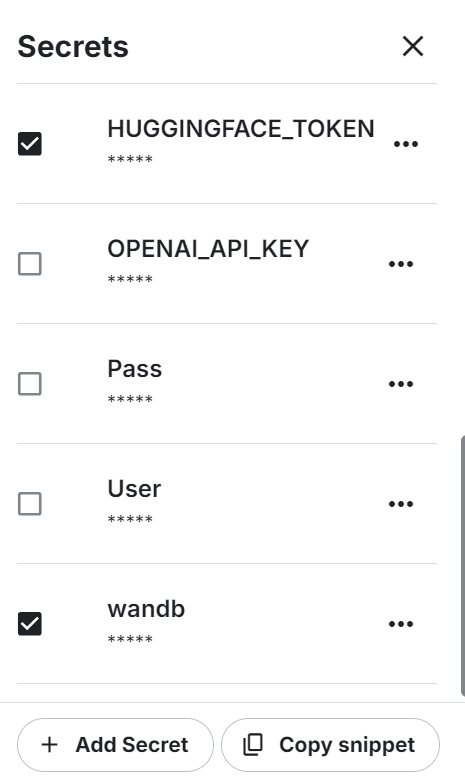
Starte das neue Kaggle-Notebook mit aktivierter GPU-Beschleunigung. Stelle dann sicher, dass du das Hugging Face und das Weights & Biases API-Token als Umgebungsvariablen mit den Kaggle-Geheimnissen gesetzt hast.
Installiere alle notwendigen Pythons-Pakete.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trlMelde dich beim Dienst "Gewichte und Vorurteile" an, signiere den API-Schlüssel und starte das neue Projekt.
import wandb
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Phi-3.5-it on Ecommerce Text Classification',
job_type="training",
anonymous="allow"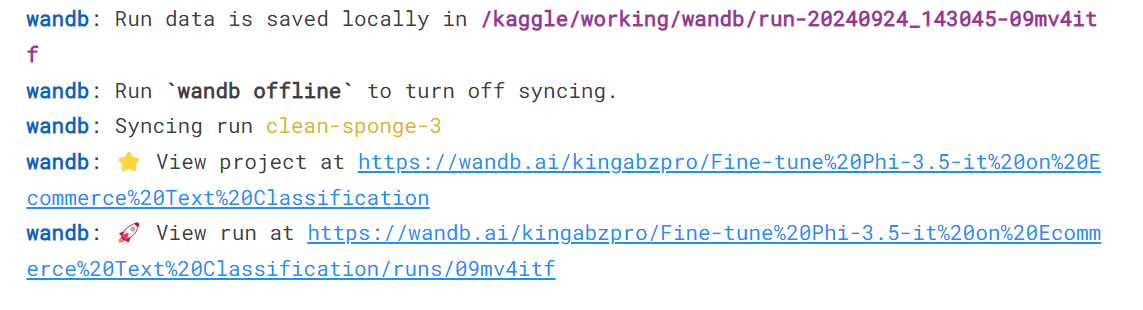
Zum Schluss lädst du alle notwendigen Python-Pakete und -Funktionen, die wir bei der Feinabstimmung und Auswertung verwenden werden.
import numpy as np
import pandas as pd
import os
from tqdm import tqdm
import bitsandbytes as bnb
import torch
import torch.nn as nn
import transformers
from datasets import Dataset
from peft import LoraConfig, PeftConfig
from trl import SFTTrainer
from trl import setup_chat_format
from transformers import (AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging)
from sklearn.metrics import (accuracy_score,
classification_report,
confusion_matrix)
from sklearn.model_selection import train_test_splitHinzufügen der E-Commerce Text Klassifizierung Datensatz zu deinem Notizbuch hinzu, wie unten gezeigt. Der Datensatz besteht aus zwei Spalten: Labels (E-Commerce-Kategorien) und Textbeschreibungen des Produkts.
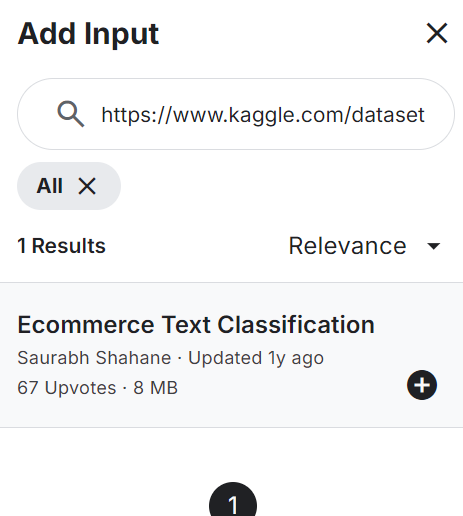
Lade die CSV-Datei, verarbeite sie und sieh dir die obersten 5 Zeilen an.
df = pd.read_csv("/kaggle/input/ecommerce-text-classification/ecommerceDataset.csv")
df.columns = ["label","text"]
df.loc[:,'label'] = df.loc[:,'label'].str.replace('Clothing & Accessories','Clothing')
df.head()Der Datensatz besteht aus der Beschreibung der Produkte und der Kategoriebezeichnung.

Mische den Datensatz und wähle nur die obersten 2000 Zeilen aus. Dies ist ein Beispielleitfaden, der den Feinabstimmungsprozess beschleunigen soll, indem er das Modell anhand einer begrenzten Anzahl von Stichproben feinabstimmt.
Als Nächstes teilen wir die Daten in Trainings-, Bewertungs- und Testdatensätze auf.
# Shuffle the DataFrame and select only 2000 rows
df = df.sample(frac=1, random_state=85).reset_index(drop=True).head(2000)
# Split the DataFrame
train_size = 0.8
eval_size = 0.1
# Calculate sizes
train_end = int(train_size * len(df))
eval_end = train_end + int(eval_size * len(df))
# Split the data
X_train = df[:train_end]
X_eval = df[train_end:eval_end]
X_test = df[eval_end:]Wir werden zwei Funktionen erstellen. Die Funktion generate_prompt konvertiert Textspalten in der Eingabeaufforderung, einschließlich Anweisungen, Textbeschreibungen und Beschriftungen. Die Funktion generate_test_prompt ist die gleiche, nur ohne die Beschriftung.
# Define the prompt generation functions
def generate_prompt(data_point):
return f"""
Classify the E-commerce text into Electronics, Household, Books and Clothing.
text: {data_point["text"]}
label: {data_point["label"]}""".strip()
def generate_test_prompt(data_point):
return f"""
Classify the E-commerce text into Electronics, Household, Books and Clothing.
text: {data_point["text"]}
label: """.strip()
# Generate prompts for training and evaluation data
X_train.loc[:,'text'] = X_train.apply(generate_prompt, axis=1)
X_eval.loc[:,'text'] = X_eval.apply(generate_prompt, axis=1)
# Generate test prompts and extract true labels
y_true = X_test.loc[:,'label']
X_test = pd.DataFrame(X_test.apply(generate_test_prompt, axis=1), columns=["text"])Konvertiere die Pandas-Train- und Evaluierungsdaten in die Hugging Face-Datensätze.
# Convert to datasets
train_data = Dataset.from_pandas(X_train[["text"]])
eval_data = Dataset.from_pandas(X_eval[["text"]])
train_data['text'][3]Der Text besteht aus Systemanweisungen, einer Textbeschreibung des Produkts und einem Etikett.

Lade das quantisierte 4-Bit-Modell und den Tokenizer aus dem Hugging Face Hub mit Hilfe der Repository ID. Richte dann das Modell und den Tokenizer so ein, dass sie einsatzbereit sind.
base_model_name = "microsoft/Phi-3.5-mini-instruct"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16",
)
model = AutoModelForCausalLM.from_pretrained(
base_model_name,
device_map="auto",
torch_dtype="float16",
quantization_config=bnb_config,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
tokenizer.pad_token_id = tokenizer.eos_token_idWir müssen das Basismodell vor der Feinabstimmung bewerten, um festzustellen, ob die Feinabstimmung die Ergebnisse verbessert hat oder nicht. Dazu erstellen wir eine predict Funktion, die den Testdatensatz nimmt und E-Commerce-Kategorien auf der Grundlage der Produkt- und Textbeschreibung generiert.
def predict(test, model, tokenizer):
y_pred = []
categories = ["Electronics", "Household", "Books", "Clothing"]
for i in tqdm(range(len(test))):
prompt = test.iloc[i]["text"]
pipe = pipeline(task="text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=4,
temperature=0.1)
result = pipe(prompt)
answer = result[0]['generated_text'].split("label:")[-1].strip()
# Determine the predicted category
for category in categories:
if category.lower() in answer.lower():
y_pred.append(category)
break
else:
y_pred.append("none")
return y_pred
y_pred = predict(X_test, model, tokenizer)Wir haben eine Liste der vorhergesagten Kategorien und werden sie nun mit den tatsächlichen Kategorien vergleichen, um den Bericht zur Modellbewertung zu erstellen. Die Funktion "Auswerten" nimmt eine Liste von vorhergesagten und tatsächlichen Kategorien und erstellt einen detaillierten Auswertungsbericht. Dieser Bericht enthält die durchschnittliche Genauigkeit, die individuelle Genauigkeit für jede Kategorie, einen Klassifizierungsbericht und eine Konfusionsmatrix.
def evaluate(y_true, y_pred):
labels = ["Electronics", "Household", "Books", "Clothing"]
mapping = {label: idx for idx, label in enumerate(labels)}
def map_func(x):
return mapping.get(x, -1) # Map to -1 if not found, but should not occur with correct data
y_true_mapped = np.vectorize(map_func)(y_true)
y_pred_mapped = np.vectorize(map_func)(y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_true=y_true_mapped, y_pred=y_pred_mapped)
print(f'Accuracy: {accuracy:.3f}')
# Generate accuracy report
unique_labels = set(y_true_mapped) # Get unique labels
for label in unique_labels:
label_indices = [i for i in range(len(y_true_mapped)) if y_true_mapped[i] == label]
label_y_true = [y_true_mapped[i] for i in label_indices]
label_y_pred = [y_pred_mapped[i] for i in label_indices]
label_accuracy = accuracy_score(label_y_true, label_y_pred)
print(f'Accuracy for label {labels[label]}: {label_accuracy:.3f}')
# Generate classification report
class_report = classification_report(y_true=y_true_mapped, y_pred=y_pred_mapped, target_names=labels, labels=list(range(len(labels))))
print('\nClassification Report:')
print(class_report)
# Generate confusion matrix
conf_matrix = confusion_matrix(y_true=y_true_mapped, y_pred=y_pred_mapped, labels=list(range(len(labels))))
print('\nConfusion Matrix:')
print(conf_matrix)
evaluate(y_true, y_pred)Wir erreichten eine durchschnittliche Genauigkeit von 65 %. Lass uns herausfinden, ob eine Feinabstimmung dieses Ergebnis verbessern kann.
Accuracy: 0.645
Accuracy for label Electronics: 0.950
Accuracy for label Household: 0.531
Accuracy for label Books: 0.561
Accuracy for label Clothing: 0.658
Classification Report:
precision recall f1-score support
Electronics 0.46 0.95 0.62 40
Household 0.83 0.53 0.65 81
Books 0.96 0.56 0.71 41
Clothing 0.86 0.66 0.75 38
micro avg 0.69 0.65 0.67 200
macro avg 0.78 0.67 0.68 200
weighted avg 0.79 0.65 0.67 200
Confusion Matrix:
[[38 0 1 0]
[33 43 0 2]
[ 9 6 23 2]
[ 2 3 0 25]]Extrahiere den Namen des linearen Modells aus dem Modell.
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)
modules['gate_up_proj', 'down_proj', 'qkv_proj', 'o_proj']Verwende den linearen Modulnamen, um das LoRA zu erstellen. Wir werden nur die LoRA feinabstimmen und den Rest des Modells stehen lassen, um Speicherplatz zu sparen und um die Trainingszeit zu verkürzen.
Als nächstes konfigurierst du die Hyperparameter des Modells für die Kaggle-Umgebung. Du kannst diese Parameter ändern, um die Genauigkeit zu verbessern und die Trainingszeit je nach Maschine zu verkürzen. Um mehr über jeden Hyperparmeter zu erfahren, folge der Feinabstimmung Llama 2 Tutorium.
Wir werden nun einen SFT-Trainer (Supervised Fine-Tuning) einrichten und einen Trainings- und Evaluierungsdatensatz, eine LoRA-Konfiguration, ein Trainingsargument, einen Tokenizer und ein Modell bereitstellen.
output_dir="Phi-3.5-mini-instruct"
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules,
)
training_arguments = TrainingArguments(
output_dir=output_dir, # directory to save and repository id
num_train_epochs=1, # number of training epochs
per_device_train_batch_size=1, # batch size per device during training
gradient_accumulation_steps=4, # number of steps before performing a backward/update pass
gradient_checkpointing=True, # use gradient checkpointing to save memory
optim="paged_adamw_8bit",
logging_steps=1,
learning_rate=2e-5, # learning rate, based on QLoRA paper
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3, # max gradient norm based on QLoRA paper
max_steps=-1,
warmup_ratio=0.03, # warmup ratio based on QLoRA paper
group_by_length=False,
lr_scheduler_type="cosine", # use cosine learning rate scheduler
report_to="wandb", # report metrics to w&b
eval_strategy="steps", # save checkpoint every epoch
eval_steps = 0.2
)
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_data,
eval_dataset=eval_data,
peft_config=peft_config,
dataset_text_field="text",
tokenizer=tokenizer,
max_seq_length=512,
packing=False,
dataset_kwargs={
"add_special_tokens": False,
"append_concat_token": False,
}
)Wir verwenden die Funktion .train, um den Feinabstimmungsprozess einzuleiten.
# Train model
trainer.train()Der Verlust hat sich allmählich verringert, und wir hätten mit mehr Epochen noch bessere Ergebnisse erzielen können.
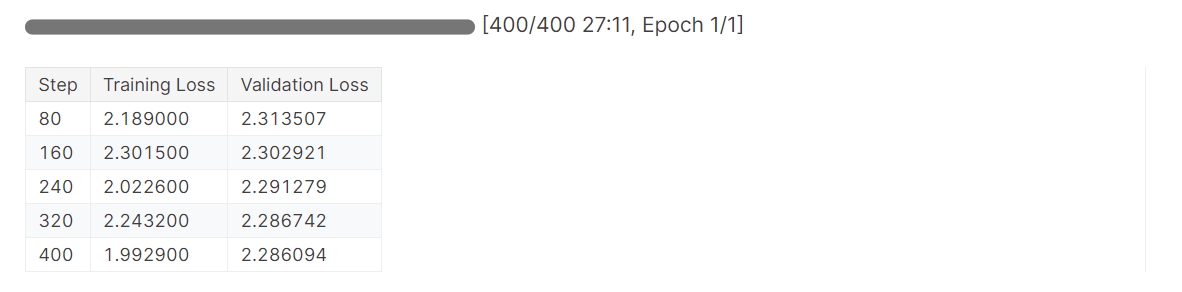
Beende den Lauf Gewichte & Verzerrungen, um den Auswertungsbericht zu erstellen.
wandb.finish()
model.config.use_cache = True
Du kannst die Leistung des Modells analysieren, indem du die Website von Weights & Biases besuchst, dein Projekt auswählst und dir die Trainingsanalyse ansiehst.
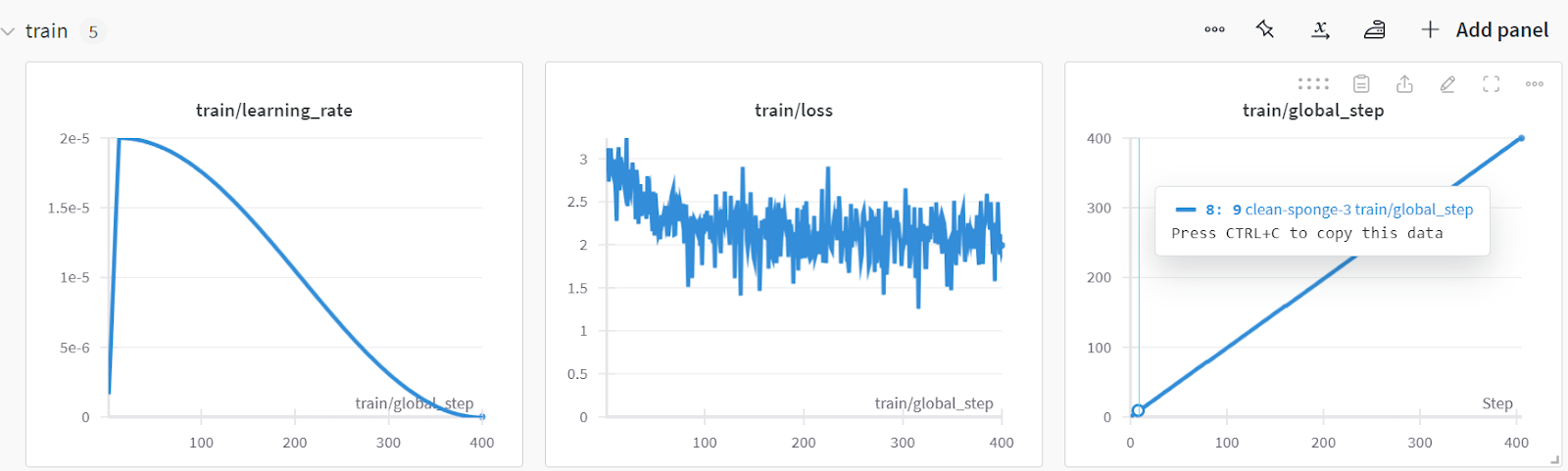
Speichere das Modell und den Tokenizer lokal, damit wir sie später für die Modellzusammenführung verwenden und auf den Remote-Server übertragen können.
# Save trained model and tokenizer
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)Dieser Leitfaden ist ziemlich code-lastig. Wenn du eine einfachere Lösung suchst, kannst du mit dem LlaMA-Factory WebUI Beginner's Guide ein Open-Source-Modell feinjustieren: Feinabstimmung der LLMs tutorial. Für eine noch einfachere Lösung, bei der du dir keine Gedanken über Hardwareprobleme machen musst, empfehlen wir dir das Fine-tuning GPT-4o Mini: Eine Schritt-für-Schritt-Anleitung tutorial. So kannst du die Feinabstimmung in der Cloud mit minimalem Code vornehmen.
Testen wir, ob sich die Leistung des Modells nach der Feinabstimmung verbessert hat. Zuerst erstellen wir eine Liste mit prädikatisierten Bezeichnungen und geben sie zusammen mit den tatsächlichen Bezeichnungen an die Funktion evaluate weiter.
y_pred = predict(X_test, model, tokenizer)
evaluate(y_true, y_pred)Die Modellgenauigkeit verbesserte sich um etwa 32,31 %, und auch die übrigen Leistungskennzahlen sehen erstaunlich gut aus. Abgesehen von der Kategorie "Bücher" konnte das Modell die Kategorien recht genau identifizieren.
Accuracy: 0.860
Accuracy for label Electronics: 0.825
Accuracy for label Household: 0.926
Accuracy for label Books: 0.683
Accuracy for label Clothing: 0.947
Classification Report:
precision recall f1-score support
Electronics 0.97 0.82 0.89 40
Household 0.88 0.93 0.90 81
Books 0.90 0.68 0.78 41
Clothing 0.88 0.95 0.91 38
micro avg 0.90 0.86 0.88 200
macro avg 0.91 0.85 0.87 200
weighted avg 0.90 0.86 0.88 200
Confusion Matrix:
[[33 6 1 0]
[ 1 75 2 3]
[ 0 3 28 2]
[ 0 1 0 36]]Achte darauf, dass du das Kaggle-Notizbuch speicherst, indem du oben rechts auf die Schaltfläche "Version speichern" klickst. Wähle dann die Option Schnellspeicherung und ändere die Option zum Speichern der Ausgabe so, dass die Modelldatei und der gesamte Code gespeichert werden.
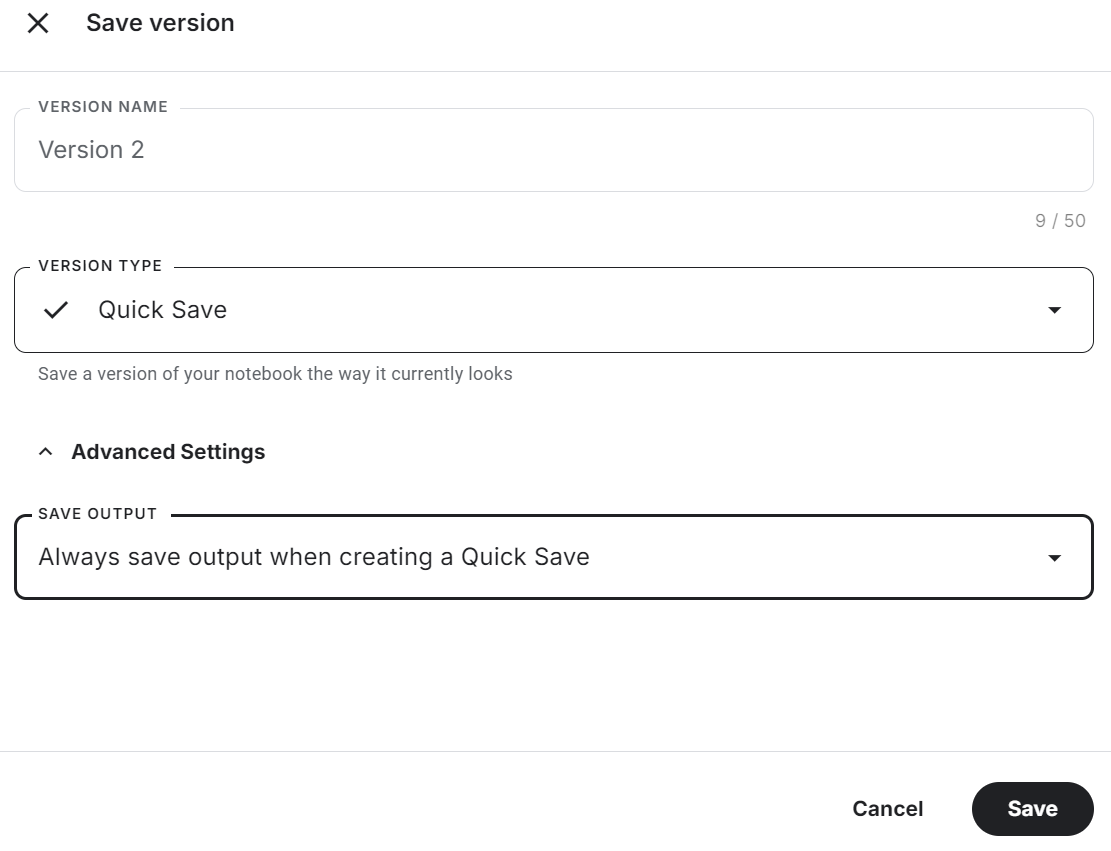
Wenn du bei der Feinabstimmung des Modells auf Probleme stößt, lies bitte den Abschnitt Feinabstimmung von Phi-3.5 für die Textklassifizierung Kaggle-Notizbuch.
Um das Modell zusammenzuführen und nach Hugging Face zu exportieren, erstellen wir zunächst ein neues Kaggle-Notizbuch und fügen das gespeicherte Notizbuch hinzu, um auf das feinabgestimmte Modell und den Tokenizer zuzugreifen.
Das Hinzufügen eines weiteren Kaggle-Notebooks ist ähnlich wie das Hinzufügen eines Datensatzes und eines Modells. Klicke auf die Schaltfläche "+ Eingabe hinzufügen", füge den Link des Notizbuchs ein und drücke dann die Schaltfläche "Hinzufügen".
Setze die Hugging Face API als Umgebungsvariable mithilfe der Kaggle-Geheimnisse und installiere alle notwendigen Python-Pakete zum Laden und Zusammenführen des Modells.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peftSetze die Variablen des Basismodells und des Feinabstimmungsmodells mit der Modell-ID und dem Standort des Modellübernehmers.
# Model
base_model = "microsoft/Phi-3.5-mini-instruct"
fine_tuned_model = "/kaggle/input/fine-tune-phi-3-5-for-text-classification/Phi-3.5-mini-instruct/"Lade das vollständige Modell aus dem Hugging Face Hub zusammen mit dem Tokenizer.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)Verbinde das Basismodell mit dem Adopter mit zwei Codezeilen.
# Merge adapter with base model
model = PeftModel.from_pretrained(base_model_reload, fine_tuned_model)
model = model.merge_and_unload()Um zu testen, ob das Modell erfolgreich zusammengeführt wurde, erstellen wir eine Textgenerierungspipeline mit dem zusammengeführten Modell und dem Tokenizer und übergeben die Beispielabfrage, um die Antwort zu generieren.
text = "Inalsa Dazzle Glass Top, 3 Burner Gas Stove with Rust Proof Powder Coated Body, Black Toughened Glass Top, 2 Medium and 1 Small High Efficiency Brass Burners, Aluminum Mixing Tubes, Powder Coated Body, Inbuilt Stainless Steel Drip Trays, 360 degree Swivel Nozzle,Bigger Legs to Facilitate Cleaning Under Cooktop"
prompt = f"""Classify the E-commerce text into Electronics, Household, Books and Clothing.
text: {text}
label: """.strip()
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipe(prompt, max_new_tokens=4, do_sample=True, temperature=0.1)
print(outputs[0]["generated_text"].split("label: ")[-1].strip())1].strip())Das Modell hat die Produktionskategorie genau vorhergesagt.
HouseholdWir werden das vollständige Modell lokal speichern, indem wir es mit dem Modellverzeichnis versehen.
model_dir = "Phi-3.5-mini-instruct-Ecommerce-Text-Classification"
model.save_pretrained(model_dir)
tokenizer.save_pretrained(model_dir)Schiebe das gespeicherte Modell in die Hugging Face Nabe. Melde dich zunächst mit dem API-Schlüssel, den du aus den Kaggle-Geheimnissen entnommen hast, bei der Hugging Face CLI an und verwende dann die Funktion push_to_hub, um sowohl das Modell als auch den Tokenizer zu pushen.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
model.push_to_hub(model_dir, use_temp_dir=False)
tokenizer.push_to_hub(model_dir, use_temp_dir=False)Es hat ein neues Modell-Repository erstellt und alle Dateien in das Hugging Face Modell-Repository verschoben.
Quelle: kingabzpro/Phi-3.5-mini-instruct-Ecommerce-Text-Classification
Wenn du Probleme beim Zusammenführen und Exportieren des Modells hast, schau dir den Phi-3.5 Fine-tuned Adapter zum vollständigen Modell an Kaggle-Notizbuch.
Schau dir auch unser neuestes Tutorial auf an, um Llama 3.2 zu optimieren und lokal zu nutzen: Eine Schritt-für-Schritt-Anleitung. In diesem Tutorial lernst du, wie du das Modell auf einem benutzerdefinierten Datensatz mit freien GPUs fein abstimmst, das Modell zusammenführst und in den Hugging Face Hub exportierst und das fein abgestimmte Modell in das GGUF-Format konvertierst, damit es lokal mit der Jan-Anwendung verwendet werden kann.
Große Sprachmodelle werden immer kleiner und effizienter, was zu geringeren Betriebskosten und besserer Anpassungsfähigkeit in verschiedenen Bereichen führt. In diesem Tutorium haben wir die Modelle Phi-3.5 Mini, Vision und MoE kennengelernt. Wir haben auch gelernt, wie man mit Kaggle Notebooks auf Phi-3.5 Mini-Modelle zugreifen kann.
Als Nächstes haben wir die Modelle mit Klassifizierungsdaten verfeinert und ihre Leistung bewertet. Dabei erzielten wir eine deutliche Verbesserung von 65 % auf 86 % Genauigkeit - eine bemerkenswerte Leistung. Eine solche Leistung ist mit RAG oder Funktionsaufrufen allein nicht zu erreichen.
Schließlich haben wir die LoRA in das Basismodell integriert und das komplette Modell in den Hugging Face Hub exportiert, wo es für jeden zugänglich ist.
Der nächste Schritt auf deiner Reise ist es, ein Projekt zu erstellen, indem du die Liste der 12 LLM-Projekte für alle Niveaus. Es enthält LLM-Projekte für Anfänger, Mittelstufenschüler, Abschlussschüler und Experten. Zu jedem Projekt gibt es einen Quellcode, eine visuelle Anleitung und weiterführende Links.
Top LLM-Kurse
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
