
Curso
Introdução a LLMs em Python
3 h
33.6K
A Microsoft se juntou ao cenário competitivo de modelos de linguagem grandes junto com a Meta AI com a introdução da série Phi-3.5. Essa série inclui um modelo de linguagem pequeno, um modelo de linguagem de visão e emprega um mistura de especialistas para obter um desempenho de alto nível.
Neste tutorial, exploraremos a família de modelos Microsoft Phi-3.5. Carregaremos o modelo Phi-3.5-mini-instruct e o ajustaremos para classificar produtos de comércio eletrônico com base em suas descrições de texto. Nas etapas finais, demonstraremos como mesclar o LoRA (Low-Rank Adaptation) com o modelo de base e enviá-lo para o Hugging Face. Isso permitirá a implantação eficiente da nuvem, tornando o modelo acessível para vários aplicativos.
Faça o teste Conceitos de Master Large Language Models (LLMs) e aprenda sobre aplicações de LLM, metodologias de treinamento, considerações éticas e as pesquisas mais recentes.

Imagem do autor
O Microsoft Phi-3.5 apresenta três modelos inovadores: Phi-3.5-mini, Phi-3.5-vision e a mais recente adição, Phi-3.5-MoE, um modelo Mixture-of-Experts.
O Phi-3.5-mini é otimizado para suporte multilíngue aprimorado com um impressionante comprimento de contexto de 128K. Apesar de seu tamanho menor, ele oferece um desempenho que rivaliza com modelos maiores, graças a aprimoramentos rigorosos por meio de ajuste fino supervisionado, otimização de política proximal e otimização de preferência direta, garantindo o cumprimento preciso das instruções.
O Phi-3.5-vision é um modelo multimodal leve e de ponta que foi treinado nos conjuntos de dados compostos por dados sintéticos e sites públicos filtrados. Ele se destaca na compreensão e no raciocínio de imagens de vários quadros, o que o torna ideal para comparação detalhada de imagens, resumo/contação de histórias de várias imagens e resumo de vídeos, com amplo potencial de aplicação.
O modelo de destaque, Phi-3.5-MoE, apresenta uma arquitetura Mixture-of-Experts com 16 especialistas e 6,6 bilhões de parâmetros ativos. Ele oferece desempenho excepcional com latência reduzida e segurança robusta, além de suporte multilíngue abrangente.
A família de modelos Phi-3.5 oferece soluções econômicas e de alto desempenho para a comunidade de código aberto, promovendo modelos de linguagem pequenos e IA generativa.
Para saber mais sobre a arquitetura, os recursos e os aplicativos do Phi-3, siga o tutorial do Phi-3: Você pode usar o menor modelo de IA da Microsoft guide.
Nesta seção, carregaremos o modelo Phi-3.5-mini-instruct e executaremos a inferência do modelo na plataforma Kaggle.
pip.%%capture
%pip install -U transformers acceleratetext-generation com modelo e tokenizador. from transformers import AutoTokenizer,AutoModelForCausalLM,pipeline
import torch
base_model = "microsoft/Phi-3.5-mini-instruct"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the tallest building in the world?"}
]
# Apply the chat template to the messages
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# Generate the output using the pipeline
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
# Print the generated text
print(outputs[0]["generated_text"])Obtivemos um resultado preciso e detalhado.
<|system|>
You are a helpful assistant.<|end|>
<|user|>
What is the tallest building in the world?<|end|>
<|assistant|>
As of my knowledge cutoff in 2023, the tallest building in the world is the Burj Khalifa, located in Dubai, United Arab Emirates. It stands at a remarkable 828 meters (2,716.5 feet) tall once its antenna is included. Completed in January 2010, the Burj Khalifa marks a significant achievement in architecture and engineering, setting numerous records. It provides office space, luxury condominiums, and various leisure facilities. This landmark continues toprompt = """
In a call center environment, classify customer interactions as 'Fraudulent' or 'Non-Fraudulent'.
Consider factors such as the nature of the inquiry, caller verification details, transaction history, and any red flags raised during the call.
[Lisa Adams, contacts the call center claiming unauthorized transactions on her credit card statement. She demands a full refund, asserting that she has never visited the merchant in question.] =
"""
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])Como podemos ver, o modelo teve um desempenho muito bom, sinalizando a chamada como fraudulenta e fornecendo uma explicação.
In a call center environment, classify customer interactions as 'Fraudulent' or 'Non-Fraudulent'.
Consider factors such as the nature of the inquiry, caller verification details, transaction history, and any red flags raised during the call.
[Lisa Adams, contacts the call center claiming unauthorized transactions on her credit card statement. She demands a full refund, asserting that she has never visited the merchant in question.] =
Call Interaction Classification: Fraudulent
Explanation:
The situation described by Lisa Adams indicates a potential case of credit card fraud. There are several red flags in this interaction that suggest the customer might be reporting unauthorized transactions:
1. The caller claims unauthorized transactions - This is a common indicator of fraud, especially if the transactions were for places or services the customer did not recognize or didn't patronize according to their personal knowledge or documented transaction history (e.g., no visits to theSe você estiver tendo problemas para executar o modelo na plataforma Kaggle, consulte a seção Inferência de modelo simples do Phi-3.5 notebook do Kaggle. Ele vem com uma configuração e um código pré-construídos, além de saídas.
Neste guia, aprenderemos a carregar e processar os dados de classificação de texto do comércio eletrônico. Também carregaremos o modelo e o tokenizador, avaliaremos o modelo no conjunto de dados de teste antes do ajuste fino, criaremos o treinador, faremos o ajuste fino do modelo no conjunto de treinamento e testaremos o modelo após o ajuste fino.
Se você é novo no processo, não deixe de ler nosso guia, Guia introdutório para ajuste fino de LLMse aprenda a teoria por trás do ajuste fino do LLM.
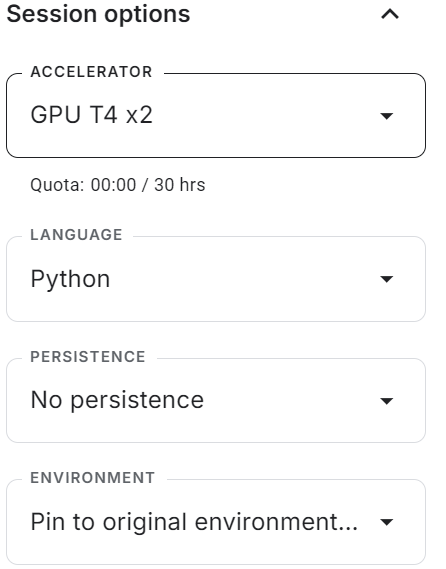
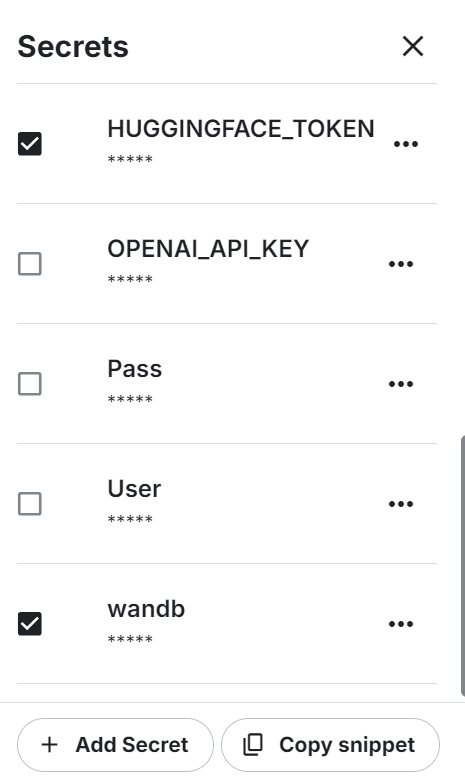
Inicie o novo notebook do Kaggle com a aceleração de GPU ativada. Em seguida, certifique-se de que você definiu o token da API Hugging Face e Weights & Biases como variáveis de ambiente usando os segredos do Kaggle.
Instale todos os pacotes Pythons necessários.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trlFaça login no serviço Weights and biases, assine a chave da API e inicie o novo projeto.
import wandb
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune Phi-3.5-it on Ecommerce Text Classification',
job_type="training",
anonymous="allow"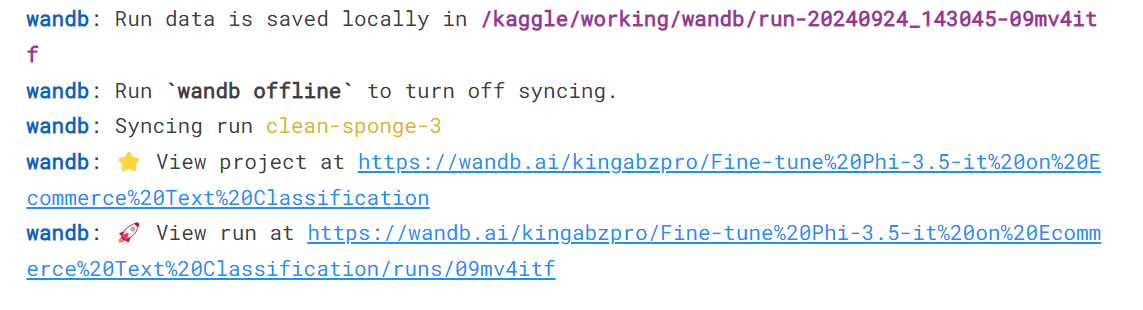
No final, carregue todos os pacotes e funções Python necessários que usaremos durante o processo de ajuste fino e avaliação.
import numpy as np
import pandas as pd
import os
from tqdm import tqdm
import bitsandbytes as bnb
import torch
import torch.nn as nn
import transformers
from datasets import Dataset
from peft import LoraConfig, PeftConfig
from trl import SFTTrainer
from trl import setup_chat_format
from transformers import (AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging)
from sklearn.metrics import (accuracy_score,
classification_report,
confusion_matrix)
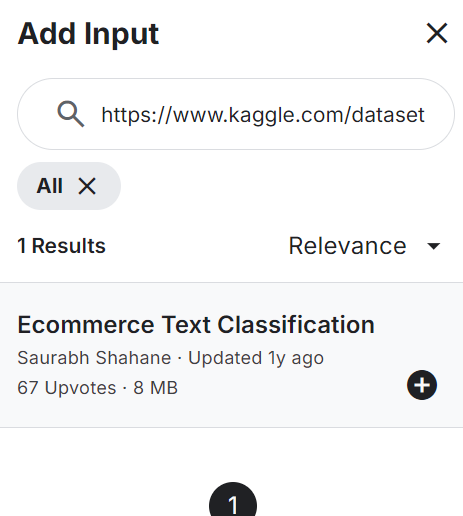
from sklearn.model_selection import train_test_splitAdicione a Classificação de texto de comércio eletrônico ao seu notebook, conforme mostrado abaixo. O conjunto de dados consiste em duas colunas: rótulos (categorias de comércio eletrônico) e descrições de texto do produto.
Carregue o arquivo CSV, processe-o e visualize as cinco primeiras linhas.
df = pd.read_csv("/kaggle/input/ecommerce-text-classification/ecommerceDataset.csv")
df.columns = ["label","text"]
df.loc[:,'label'] = df.loc[:,'label'].str.replace('Clothing & Accessories','Clothing')
df.head()O conjunto de dados consiste na descrição dos produtos e no rótulo da categoria.

Embaralhe o conjunto de dados e selecione apenas as 2.000 linhas superiores. Este é um guia de exemplo, destinado a acelerar o processo de ajuste fino por meio do ajuste fino do modelo em um conjunto limitado de amostras.
Em seguida, dividiremos os dados em conjuntos de dados de treinamento, avaliação e teste.
# Shuffle the DataFrame and select only 2000 rows
df = df.sample(frac=1, random_state=85).reset_index(drop=True).head(2000)
# Split the DataFrame
train_size = 0.8
eval_size = 0.1
# Calculate sizes
train_end = int(train_size * len(df))
eval_end = train_end + int(eval_size * len(df))
# Split the data
X_train = df[:train_end]
X_eval = df[train_end:eval_end]
X_test = df[eval_end:]Criaremos duas funções. A função generate_prompt converterá as colunas de texto no prompt, incluindo instruções, descrições de texto e rótulos. A função generate_test_prompt é a mesma, mas sem o rótulo.
# Define the prompt generation functions
def generate_prompt(data_point):
return f"""
Classify the E-commerce text into Electronics, Household, Books and Clothing.
text: {data_point["text"]}
label: {data_point["label"]}""".strip()
def generate_test_prompt(data_point):
return f"""
Classify the E-commerce text into Electronics, Household, Books and Clothing.
text: {data_point["text"]}
label: """.strip()
# Generate prompts for training and evaluation data
X_train.loc[:,'text'] = X_train.apply(generate_prompt, axis=1)
X_eval.loc[:,'text'] = X_eval.apply(generate_prompt, axis=1)
# Generate test prompts and extract true labels
y_true = X_test.loc[:,'label']
X_test = pd.DataFrame(X_test.apply(generate_test_prompt, axis=1), columns=["text"])Converta os quadros de dados de treinamento e avaliação do pandas nos conjuntos de dados do Hugging Face.
# Convert to datasets
train_data = Dataset.from_pandas(X_train[["text"]])
eval_data = Dataset.from_pandas(X_eval[["text"]])
train_data['text'][3]O texto consiste em instruções do sistema, uma descrição de texto do produto e um rótulo.

Carregue o modelo quantizado de 4 bits e o tokenizador do Hugging Face Hub usando o ID do repositório. Em seguida, configure o modelo e o tokenizador para que estejam prontos para serem usados.
base_model_name = "microsoft/Phi-3.5-mini-instruct"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16",
)
model = AutoModelForCausalLM.from_pretrained(
base_model_name,
device_map="auto",
torch_dtype="float16",
quantization_config=bnb_config,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
tokenizer.pad_token_id = tokenizer.eos_token_idPrecisamos avaliar o modelo básico antes de fazer o ajuste fino para determinar se o ajuste fino melhorou os resultados ou não. Para isso, criaremos uma função predict que usa o conjunto de dados de teste e gera categorias de comércio eletrônico com base no produto e na descrição do texto.
def predict(test, model, tokenizer):
y_pred = []
categories = ["Electronics", "Household", "Books", "Clothing"]
for i in tqdm(range(len(test))):
prompt = test.iloc[i]["text"]
pipe = pipeline(task="text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=4,
temperature=0.1)
result = pipe(prompt)
answer = result[0]['generated_text'].split("label:")[-1].strip()
# Determine the predicted category
for category in categories:
if category.lower() in answer.lower():
y_pred.append(category)
break
else:
y_pred.append("none")
return y_pred
y_pred = predict(X_test, model, tokenizer)Temos uma lista de categorias previstas e agora vamos compará-las com as categorias reais para gerar o relatório de avaliação do modelo. A função "evaluate" (avaliar) usa uma lista de categorias previstas e reais e gera um relatório de avaliação detalhado. Esse relatório inclui a precisão média, a precisão individual de cada categoria, um relatório de classificação e uma matriz de confusão.
def evaluate(y_true, y_pred):
labels = ["Electronics", "Household", "Books", "Clothing"]
mapping = {label: idx for idx, label in enumerate(labels)}
def map_func(x):
return mapping.get(x, -1) # Map to -1 if not found, but should not occur with correct data
y_true_mapped = np.vectorize(map_func)(y_true)
y_pred_mapped = np.vectorize(map_func)(y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_true=y_true_mapped, y_pred=y_pred_mapped)
print(f'Accuracy: {accuracy:.3f}')
# Generate accuracy report
unique_labels = set(y_true_mapped) # Get unique labels
for label in unique_labels:
label_indices = [i for i in range(len(y_true_mapped)) if y_true_mapped[i] == label]
label_y_true = [y_true_mapped[i] for i in label_indices]
label_y_pred = [y_pred_mapped[i] for i in label_indices]
label_accuracy = accuracy_score(label_y_true, label_y_pred)
print(f'Accuracy for label {labels[label]}: {label_accuracy:.3f}')
# Generate classification report
class_report = classification_report(y_true=y_true_mapped, y_pred=y_pred_mapped, target_names=labels, labels=list(range(len(labels))))
print('\nClassification Report:')
print(class_report)
# Generate confusion matrix
conf_matrix = confusion_matrix(y_true=y_true_mapped, y_pred=y_pred_mapped, labels=list(range(len(labels))))
print('\nConfusion Matrix:')
print(conf_matrix)
evaluate(y_true, y_pred)Obtivemos uma precisão média de 65%. Vamos determinar se o ajuste fino pode melhorar essa pontuação.
Accuracy: 0.645
Accuracy for label Electronics: 0.950
Accuracy for label Household: 0.531
Accuracy for label Books: 0.561
Accuracy for label Clothing: 0.658
Classification Report:
precision recall f1-score support
Electronics 0.46 0.95 0.62 40
Household 0.83 0.53 0.65 81
Books 0.96 0.56 0.71 41
Clothing 0.86 0.66 0.75 38
micro avg 0.69 0.65 0.67 200
macro avg 0.78 0.67 0.68 200
weighted avg 0.79 0.65 0.67 200
Confusion Matrix:
[[38 0 1 0]
[33 43 0 2]
[ 9 6 23 2]
[ 2 3 0 25]]Extraia o nome do modelo linear do modelo.
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)
modules['gate_up_proj', 'down_proj', 'qkv_proj', 'o_proj']Use o nome do módulo linear para criar o LoRA. Faremos apenas o ajuste fino do LoRA e deixaremos o restante do modelo para economizar memória e acelerar o tempo de treinamento.
Em seguida, configure os hiperparâmetros do modelo para o ambiente do Kaggle. Você pode alterar esses parâmetros para melhorar a precisão e reduzir o tempo de treinamento com base na sua máquina. Para saber mais sobre cada hiperparâmetro, siga o link Ajuste fino do Llama 2 para você aprender sobre cada hiperparâmetro.
Agora, configuraremos um treinador de ajuste fino supervisionado (SFT) e forneceremos um conjunto de dados de treinamento e avaliação, configuração do LoRA, argumento de treinamento, tokenizador e modelo.
output_dir="Phi-3.5-mini-instruct"
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules,
)
training_arguments = TrainingArguments(
output_dir=output_dir, # directory to save and repository id
num_train_epochs=1, # number of training epochs
per_device_train_batch_size=1, # batch size per device during training
gradient_accumulation_steps=4, # number of steps before performing a backward/update pass
gradient_checkpointing=True, # use gradient checkpointing to save memory
optim="paged_adamw_8bit",
logging_steps=1,
learning_rate=2e-5, # learning rate, based on QLoRA paper
weight_decay=0.001,
fp16=False,
bf16=False,
max_grad_norm=0.3, # max gradient norm based on QLoRA paper
max_steps=-1,
warmup_ratio=0.03, # warmup ratio based on QLoRA paper
group_by_length=False,
lr_scheduler_type="cosine", # use cosine learning rate scheduler
report_to="wandb", # report metrics to w&b
eval_strategy="steps", # save checkpoint every epoch
eval_steps = 0.2
)
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_data,
eval_dataset=eval_data,
peft_config=peft_config,
dataset_text_field="text",
tokenizer=tokenizer,
max_seq_length=512,
packing=False,
dataset_kwargs={
"add_special_tokens": False,
"append_concat_token": False,
}
)Usaremos a função .train para iniciar o processo de ajuste fino.
# Train model
trainer.train()A perda foi reduzida gradualmente, e poderíamos ter obtido resultados ainda melhores com mais épocas.
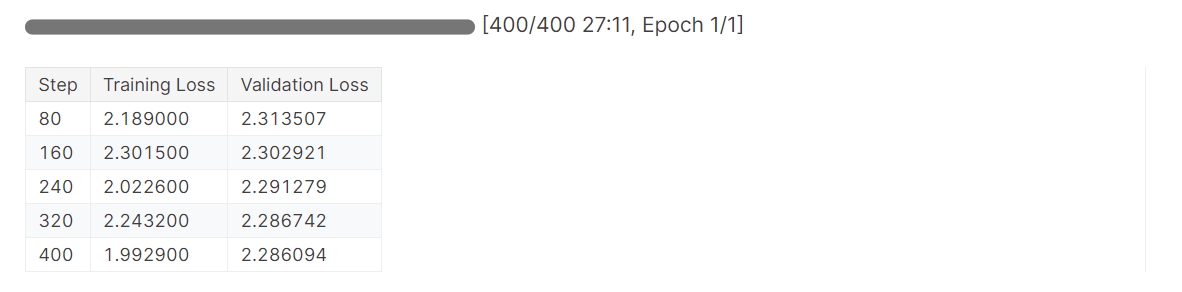
Conclua a execução do Weights & Biases para gerar o relatório de avaliação.
wandb.finish()
model.config.use_cache = True
Você pode analisar o desempenho do modelo visitando o site Weights & Biases, selecionando seu projeto e visualizando a análise de treinamento.
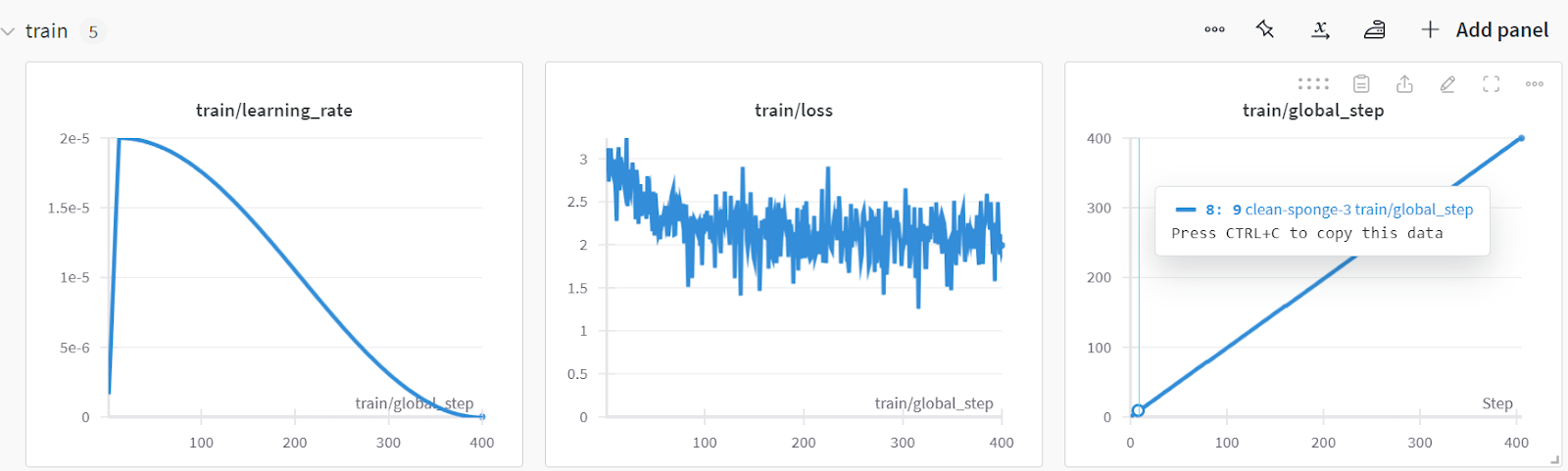
Salve o modelo e o tokenizador localmente para que possamos usá-los posteriormente para mesclar modelos e enviá-los ao servidor remoto.
# Save trained model and tokenizer
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)Este guia tem um código bastante pesado. Se estiver procurando uma solução mais simples, você pode ajustar um modelo de código aberto seguindo o LlaMA-Factory WebUI Beginner's Guide: Ajuste fino de LLMs tutorial. Para uma solução ainda mais simples, em que você não precisa se preocupar com problemas de hardware, recomendamos o Fine-tuning GPT-4o Mini: A Step-by-Step Guide (Guia passo a passo) tutorial. Isso ajudará você a fazer o ajuste fino na nuvem com o mínimo de código.
Vamos testar se o desempenho do modelo melhorou após o ajuste fino. Primeiro, geraremos uma lista de rótulos predicados e a forneceremos à função evaluate junto com os rótulos reais.
y_pred = predict(X_test, model, tokenizer)
evaluate(y_true, y_pred)A precisão do modelo melhorou em aproximadamente 32,31%, e o restante das métricas de desempenho parece incrível. Com exceção da categoria Livros, o modelo foi capaz de identificar as categorias com bastante precisão.
Accuracy: 0.860
Accuracy for label Electronics: 0.825
Accuracy for label Household: 0.926
Accuracy for label Books: 0.683
Accuracy for label Clothing: 0.947
Classification Report:
precision recall f1-score support
Electronics 0.97 0.82 0.89 40
Household 0.88 0.93 0.90 81
Books 0.90 0.68 0.78 41
Clothing 0.88 0.95 0.91 38
micro avg 0.90 0.86 0.88 200
macro avg 0.91 0.85 0.87 200
weighted avg 0.90 0.86 0.88 200
Confusion Matrix:
[[33 6 1 0]
[ 1 75 2 3]
[ 0 3 28 2]
[ 0 1 0 36]]Certifique-se de salvar o notebook do Kaggle clicando no botão "Save Version" (Salvar versão) no canto superior direito. Em seguida, selecione a opção de salvamento rápido e altere a opção de saída de salvamento para incluir o salvamento do arquivo de modelo e de todo o código.
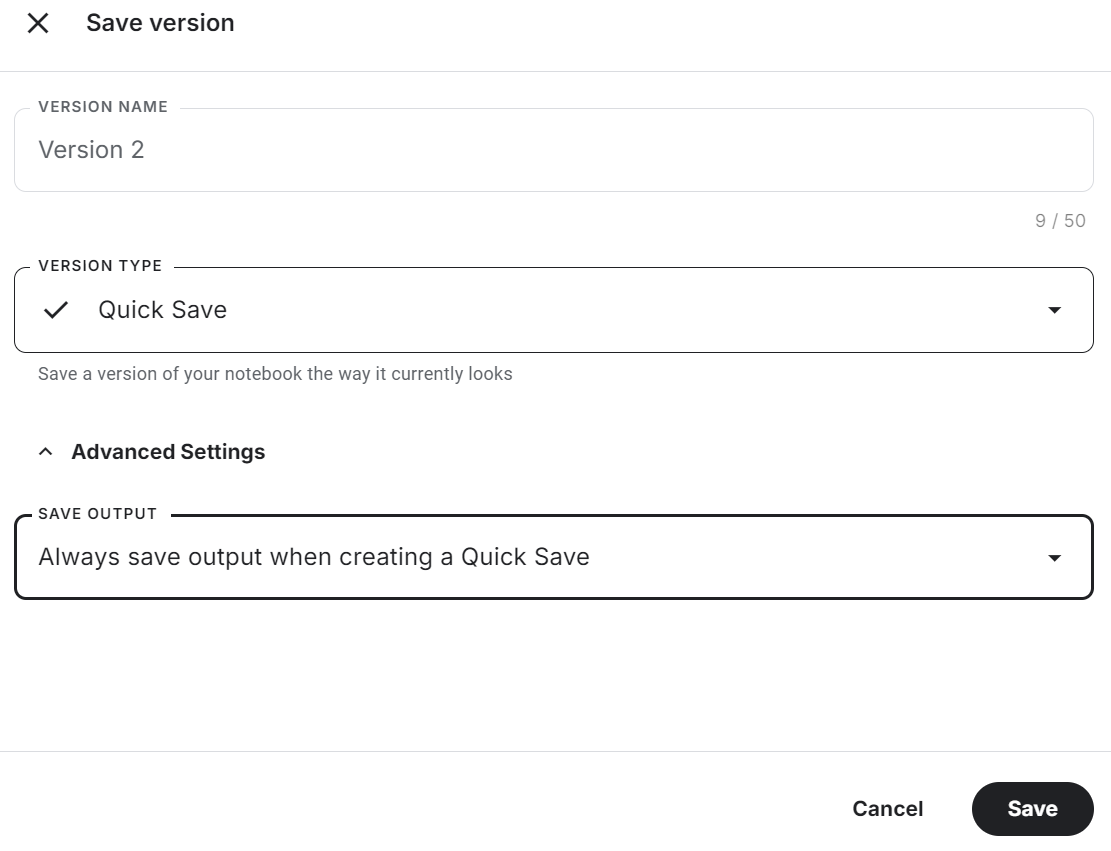
Se você encontrar problemas ao fazer o ajuste fino do modelo, consulte o Fine-tune Phi-3.5 for Text Classification notebook do Kaggle.
Para mesclar e exportar o modelo para o Hugging Face, primeiro criaremos um novo notebook do Kaggle e adicionaremos o notebook salvo para acessar o modelo ajustado e o tokenizador.
Se você adicionar outro notebook do Kaggle, será semelhante a adicionar um conjunto de dados e um modelo. Clique no botão "+ Adicionar entrada", cole o link do notebook e pressione o botão Adicionar.
Definir a API Hugging Face como uma variável de ambiente usando os segredos do Kaggle e instalar todos os pacotes Python necessários para carregar e mesclar o modelo.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peftDefina o modelo básico e as variáveis do modelo ajustado com o ID do modelo e o local do adotante do modelo.
# Model
base_model = "microsoft/Phi-3.5-mini-instruct"
fine_tuned_model = "/kaggle/input/fine-tune-phi-3-5-for-text-classification/Phi-3.5-mini-instruct/"Carregue o modelo completo do hub Hugging Face junto com o tokenizador.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)Mesclar o modelo básico com o adotado usando duas linhas de código.
# Merge adapter with base model
model = PeftModel.from_pretrained(base_model_reload, fine_tuned_model)
model = model.merge_and_unload()Para testar se o modelo foi mesclado com sucesso, criaremos um pipeline de geração de texto com o modelo mesclado e o tokenizador, e passaremos o prompt de amostra para gerar a resposta.
text = "Inalsa Dazzle Glass Top, 3 Burner Gas Stove with Rust Proof Powder Coated Body, Black Toughened Glass Top, 2 Medium and 1 Small High Efficiency Brass Burners, Aluminum Mixing Tubes, Powder Coated Body, Inbuilt Stainless Steel Drip Trays, 360 degree Swivel Nozzle,Bigger Legs to Facilitate Cleaning Under Cooktop"
prompt = f"""Classify the E-commerce text into Electronics, Household, Books and Clothing.
text: {text}
label: """.strip()
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipe(prompt, max_new_tokens=4, do_sample=True, temperature=0.1)
print(outputs[0]["generated_text"].split("label: ")[-1].strip())1].strip())O modelo previu com precisão a categoria de produção.
HouseholdSalvaremos o modelo completo localmente, fornecendo a ele o diretório do modelo.
model_dir = "Phi-3.5-mini-instruct-Ecommerce-Text-Classification"
model.save_pretrained(model_dir)
tokenizer.save_pretrained(model_dir)Empurre o modelo salvo para o hub do Hugging Face. Primeiro, faça login na CLI do Hugging Face usando a chave de API extraída dos segredos do Kaggle e, em seguida, use a função push_to_hub para enviar o modelo e o tokenizador.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)
model.push_to_hub(model_dir, use_temp_dir=False)
tokenizer.push_to_hub(model_dir, use_temp_dir=False)Ele criou um novo repositório de modelos e enviou todos os arquivos para o repositório de modelos do Hugging Face.
Fonte: kingabzpro/Phi-3.5-mini-instruct-Ecommerce-Text-Classification
Se você estiver tendo problemas para mesclar o modelo e exportá-lo, consulte o Phi-3.5 Fine-tuned Adapter para o modelo completo Caderno do Kaggle.
Além disso, dê uma olhada no nosso mais novo tutorial em Ajuste fino do Llama 3.2 e uso local: Um guia passo a passo. Neste tutorial, você aprenderá a fazer o ajuste fino do modelo em um conjunto de dados personalizado usando GPUs gratuitas, mesclar e exportar o modelo para o Hugging Face Hub e converter o modelo ajustado para o formato GGUF para que possa ser usado localmente com o aplicativo Jan.
Os grandes modelos de linguagem estão se tornando menores e mais eficientes, levando a custos operacionais reduzidos e maior adaptabilidade em vários campos. Neste tutorial, exploramos os modelos Phi-3.5 Mini, Vision e MoE. Também aprendemos a acessar os modelos Phi-3.5 Mini usando o Kaggle Notebooks.
Em seguida, ajustamos os modelos em dados de classificação e avaliamos seu desempenho, obtendo uma melhoria significativa de 65% para 86% de precisão - uma conquista notável. Esse desempenho não pode ser obtido apenas com o RAG ou com a chamada de função.
Por fim, integramos o LoRA ao modelo básico e exportamos o modelo completo para o Hugging Face Hub, onde ele está disponível para uso de todos.
A próxima etapa de sua jornada é criar um projeto seguindo a lista de 12 projetos de LLM para todos os níveis. Inclui projetos de LLM para iniciantes, alunos intermediários, alunos do último ano e especialistas. Cada projeto vem com um código-fonte, um guia visual e links de suporte.
Principais cursos de LLM
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Aashi Dutt
Tutorial
Dimitri Didmanidze

