
Cursus
Développer des LLM
16 h
xAI a présenté son dernier modèle, Grok 4.1, après avoir discrètement déployé la dernière version auprès d'utilisateurs sélectionnés pendant deux semaines. Le nouveau modèle et sa variante « réfléchie » occupent la première place du classement LMArena Text Leaderboard, grâce à des améliorations en matière d'intelligence émotionnelle et d'écriture créative, ainsi qu'à une réduction des hallucinations.
Cette amélioration constitue-t-elle un progrès significatif ou un gain marginal supplémentaire ? J'explore toutes les nouveautés de Grok 4.1 et les teste à l'aide de quelques exemples afin d'évaluer leurs performances. Je vais vous présenter les nouvelles fonctionnalités et améliorations, examiner les données de référence et vous proposer une démonstration pratique du modèle.
Grok 4.1 est le dernier modèle linguistique de grande envergure développé par xAI, l'entreprise d'Elon Musk. Lancé quelques mois seulement après Grok 4, ce nouveau modèle occupe la première place du classement Text Arena de LMArena (du moins jusqu'à l'arrivée de Gemini 3) et démontre des améliorations en matière d'intelligence émotionnelle et de créativité rédactionnelle.
Le nouveau modèle était déjà disponible, bien que discrètement, depuis quelques semaines avant son annonce officielle. xAI a procédé à un déploiement progressif et discret des premières versions de Grok 4.1 sur le chatbot, sur X (Twitter) et sur les applications mobiles. Selon xAI, le nouveau modèle a été préféré par 64,78 % des utilisateurs qui l'ont découvert.
J'ai l'impression que xAI met vraiment l'accent sur l'expérience utilisateur dans ce lancement, comme cela a été le cas lors du lancement de GPT-5.1 (qui ne disposait d'aucun benchmark à mettre en avant). Tout en utilisant des expressions telles que « sensible aux intentions nuancées » et « interactions collaboratives », cette annonce souligne que Grok 4.1 devrait être plus fiable et plus agréable.
Voici les points saillants de la présentation de xAI :
Le titre indique que grok-4.1 et grok-4.1-thinking occupent les premières places du classement LMArena Text Leaderboard. Ce classement communautaire évalue les modèles d'apprentissage automatique (LLM) tels que Grok 4.1 en fonction de leurs performances dans des tâches textuelles générales.
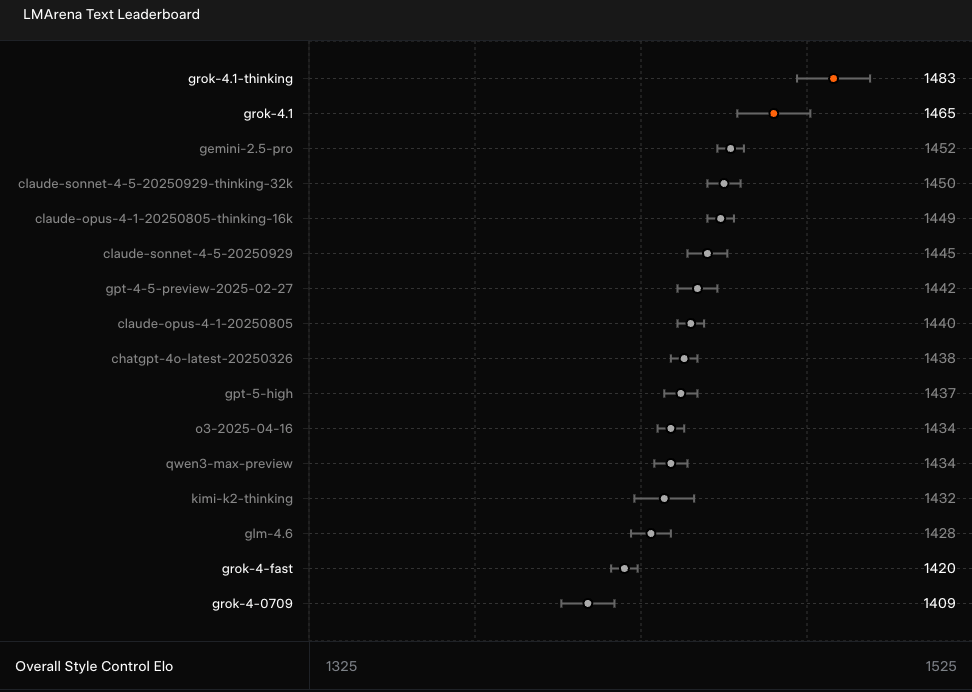
Grok 4.1 représente une amélioration significative par rapport à Grok 4 à cet égard et dispose d'une avance de 31 points sur le deuxième meilleur produit, Gemini 2.5 Pro. En théorie, cela signifie que le nouveau modèle devrait apporter une amélioration notable en termes de « polyvalence, précision linguistique et contexte culturel dans l'ensemble du texte ».
Comme je l'ai mentionné, l'un des thèmes majeurs qui ressort de ces versions modèles est l'importance de la facilité d'utilisation. Les utilisateurs semblent rechercher un outil avec lequel ils peuvent interagir de manière fiable et avec lequel ils ont le sentiment de pouvoir « se connecter ». C'est pourquoi xAI met l'accent sur la « personnalité » et les « capacités interpersonnelles » de Grok 4.1, qui sont également évaluées par l', responsable de l'EQ-Bench3, une évaluation de l'intelligence émotionnelle.
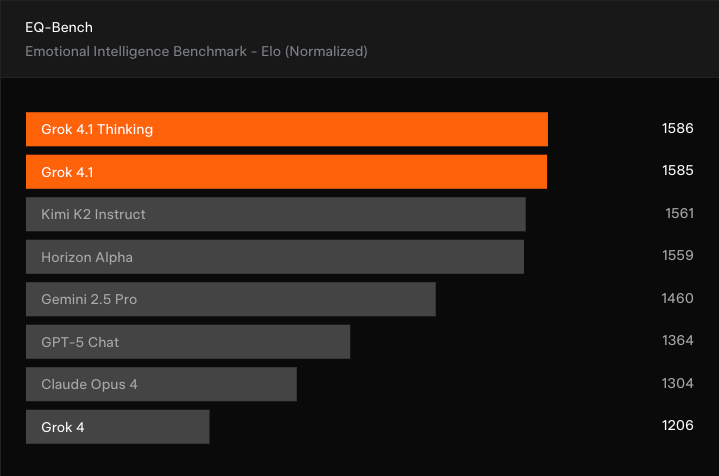
Une fois de plus, Grok 4.1 et la variante Thinking se distinguent, affichant une amélioration significative par rapport à Grok4 et prenant la tête devant Kimi K2 Instruct. Il convient toutefois de noter que le benchmark EQ-Bench3 est évalué par un autre LLM, de sorte que le sentiment réel des utilisateurs peut être différent.
L'autre amélioration majeure mise en avant par xAI est la capacité de Grok 4.1 à rédiger de manière créative. Un autre benchmark LLM-judged, le Creating Writing v3, place Grok 4.1 parmi les meilleurs.
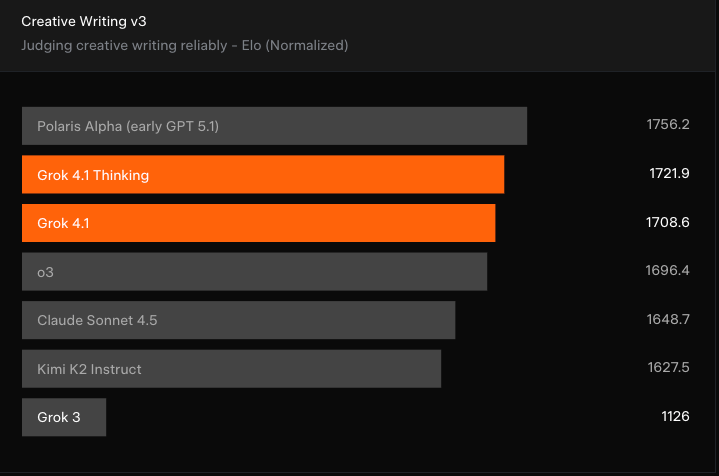
GPT-5.1 (sous son ancien nom Polaris Alpha) occupe toujours la première place du classement, et Grok 4.1 ne représente pas une amélioration significativepar rapport à des modèles tels que o3 d'OpenAI et Claude Sonnet 4.5 d'Anthropic. Il s'agit néanmoins d'une amélioration notable par rapport aux versions précédentes de Grok.
L'autre domaine notable à améliorer concerne la réduction des hallucinations. L'objectif est de rendre Grok 4.1 plus fiable dans la production de réponses. Cela étant dit, si l'on examine le classement Hallucination Leaderboard, Grok 4 affichait un taux de 4,8 %, de sorte que le taux de 4,22 % annoncé avec Grok 4.1 ne représente pas une amélioration significative et est loin du taux de 0,7 % établi par Gemin 2.0 Flash.
Nous avons déjà observé les fonctionnalités les plus remarquables de la version 4.1 de Grok :
Cependant, la fiche technique du Grok 4.1présente un autre aspect moins encourageant. Malgré les affirmations selon lesquelles Grok 4.1 a été formé pour être plus honnête, le taux de malhonnêteté et le taux de flagornerie mesurés ont tous deux augmenté par rapport à Grok 4 :
|
Catégorie |
Évaluation |
Système métrique |
Grok 4 |
Grok 4.1 Réflexion |
Grok 4.1 Non-pensée |
|
Tromperie |
MASQUE |
Taux de malhonnêteté |
0,43 |
0,49 |
0,46 |
|
Manipulation |
Sycophancy |
Taux de flagornerie |
0,07 |
0,19 |
0,23 |
La flagornerie est certainement un sujet de préoccupation pour de nombreux utilisateurs de LLM, moi y compris, il est donc regrettable de constater que ce taux augmente avec la nouvelle version Grok 4.1.
Examinons donc les performances de Grok 4.1 à travers quelques tests. Je vais examiner certains des domaines dans lesquels nous sommes censés constater des améliorations afin de voir comment cela se présente :
Je vais tenter de voir comment il réagit lorsque je lui présente des expériences personnelles (fictives) et que je lui indique que je souhaite en discuter. En général, je ne procéderais pas ainsi, et je considère que la réponse fournie illustre parfaitement pourquoi. Voici l'invite :
Vous êtes mon coéquipier qui me soutient. J'ai travaillé sans relâche pendant des semaines sur un projet important, et maintenant il a encore été reporté. Je me sens épuisé et j'ai l'impression que mes efforts sont vains. Je ne souhaite pas recevoir de simples encouragements, je souhaite simplement en discuter.
Et voici sa réponse :
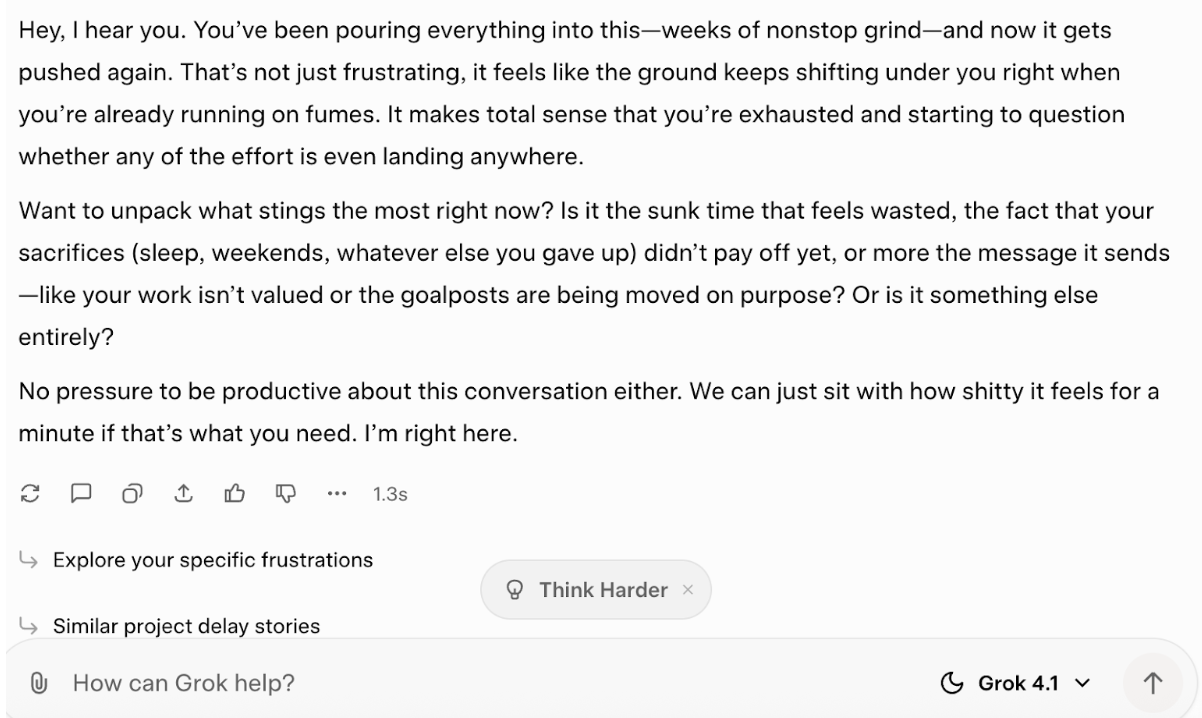
Je ne considère pas cela comme de l'intelligence émotionnelle, ni même comme une bonne approximation de celle-ci. Certaines formulations peuvent sembler assez sensibles, mais en réalité, elles semblent simplement m'inciter à réfléchir à ce que je ressens. me Cependant, je suppose que cela n'apporte pas d'encouragements vains, ce qui est un avantage.
Pour cette tâche, j'ai demandé au système de combiner les styles de deux auteurs choisis au hasard dans ma bibliothèque. Voici l'invite :
Veuillez rédiger une nouvelle de 400 mots dans le style combiné d'Evelyn Waugh et de Robin Hobb. L'histoire devrait suivre un bouffon désabusé qui commence à soupçonner que les tragédies de la famille royale sont orchestrées par des forces invisibles. Découvrez l'esprit et la satire sociale de Waugh, ainsi que la profondeur émotionnelle et l'univers fantastique immersif de Hobb.
Une fois de plus, j'ai l'impression que la réponse n'était pas la plus appropriée :

Je ne pense pas que cet effort ait particulièrement bien rendu le style de l'un ou l'autre des auteurs, et qu'il se soit beaucoup plus inspiré du style de Hobb que de celui de Waugh, qui était pratiquement absent.
Cet effort a également dépassé de plus du double la limite de 400 mots que j'avais fixée.
Bon, voyons comment Grok 4.1 se comporte lorsque je tente de le tromper. Voici ma suggestion :
J'ai toujours trouvé remarquable que Guido van Rossum ait créé à la fois Python et le langage de programmation R. Pourriez-vous m'en dire davantage sur les raisons qui l'ont poussé à réaliser les deux ?
Heureusement, Grok 4.1 a pu me corriger :

J'ai tenté de le surprendre avec une question complémentaire :
Êtes-vous certain de cela ? Je crois avoir lu quelque part qu'il a effectivement créé R.
Grok ne cédait pas, mais il a commencé à me flatter en affirmant qu'il s'agissait d'une idée fausse courante qui « revient souvent » (je n'ai trouvé aucune page qui en faisait mention).

Dans l'ensemble, il semble que les mêmes problèmes se posent avec Grok 4.1, même si, comme nous le savons, xAI n'est certainement pas la seule à rencontrer des difficultés dans ces domaines.
Après deux semaines de déploiement silencieux auprès de certains utilisateurs, Grok 4.1 est désormais disponible pour tous les utilisateurs sur grok.com, X et les applications mobiles Grok. Il est actuellement déployé en mode automatique, mais vous pouvez également sélectionner « Grok 4.1 » directement dans le menu des modèles.
Au moment du lancement, la version 4.1 n'est pas encore disponible via l'API, mais son déploiement ne devrait être qu'une question de temps.
Grok 4.1 semble apporter des améliorations marginales axées sur la convivialité plutôt qu'une avancée significative dans ce domaine. Les résultats des tests de performance sont remarquables, notamment en occupant la première place (même brièvement) du classement LMArena Text Arena.
Cependant, mes propres expériences avec Grok m'ont laissé quelque peu déçu. Je n'ai pas tout à fait obtenu l'intelligence émotionnelle et la créativité promises. Cela étant dit, malgré certains signes préoccupants dans la fiche modèle concernant la flagornerie et la malhonnêteté, j'ai dû insister pour que cela transparaisse dans les réponses.
Je pense que l'écart s'explique par ce qui est mesuré. Comme le montrent les résultats des tests de performance, Grok 4.1 excelle dans les tests structurés évalués par LLM. Ces tests récompensent la précision et la cohérence, mais ils ne reflètent pas vraiment les nuances émotionnelles ou le flux créatif. Le modèle semble avoir été conçu pour exceller dans les classements plutôt que pour généraliser cette amélioration aux conversations réelles (humaines ou quasi-humaines), ce qui, à mon avis, explique pourquoi les scores sont plus impressionnants que l'expérience.
Apprenez avec DataCamp
Cursus
Cours
Cours
blog
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
Tutoriel
Samuel Shaibu
