
programa
Desarrollar grandes modelos lingüísticos
16 h
xAI presentó su último modelo, Grok 4.1, tras lanzar silenciosamente la última versión a usuarios seleccionados durante un periodo de dos semanas. El nuevo modelo y su variante «pensante» encabezan la clasificación de LMArena Text Leaderboard, con mejoras en inteligencia emocional y escritura creativa, y una reducción de las alucinaciones.
¿Esta mejora supone un gran avance o solo una ganancia marginal? Exploro todas las novedades de Grok 4.1 y las pruebo con algunos ejemplos para ver cómo funcionan. Voy a hablar de las nuevas funciones y mejoras, echar un vistazo a los datos de referencia y probar el modelo.
Grok 4.1 es el último modelo de lenguaje grande de xAI, la empresa de Elon Musk. Lanzado solo unos meses despué, este nuevo modelo encabeza la tabla Text Arena de LMArena (al menos, hasta que veamos Gemini 3) y demuestra mejoras en su inteligencia emocional y escritura creativa.
El nuevo modelo lleva ya un par de semanas en circulación, aunque de forma silenciosa, antes de su anuncio oficial. xAI llevó a cabo un lanzamiento gradual y silencioso de las primeras versiones de Grok 4.1 en el chatbot, en X (Twitter) y en las aplicaciones móviles. Según xAI, el nuevo modelo fue el preferido por el 64,78 % de los usuarios que lo probaron.
Creo que xAI está exagerando mucho la experiencia del usuario en este lanzamiento, de forma similar a lo que vimos con el lanzamiento de GPT-5.1 (que no teníningún punto de referencia del que presumir). Aunque se utilizan expresiones como «perceptivo a las intenciones matizadas» e «interacciones colaborativas», la idea central de este anuncio es que Grok 4.1 debería ser más fiable y agradable.
A continuación, se presentan los aspectos más destacados de la presentación de xAI:
El titular es que grok-4.1 y grok-4.1-thinking encabezan la clasificación de LMArena Text. Esta tabla de clasificación impulsada por la comunidad clasifica los LLM como Grok 4.1 según su rendimiento en tareas generales basadas en texto.
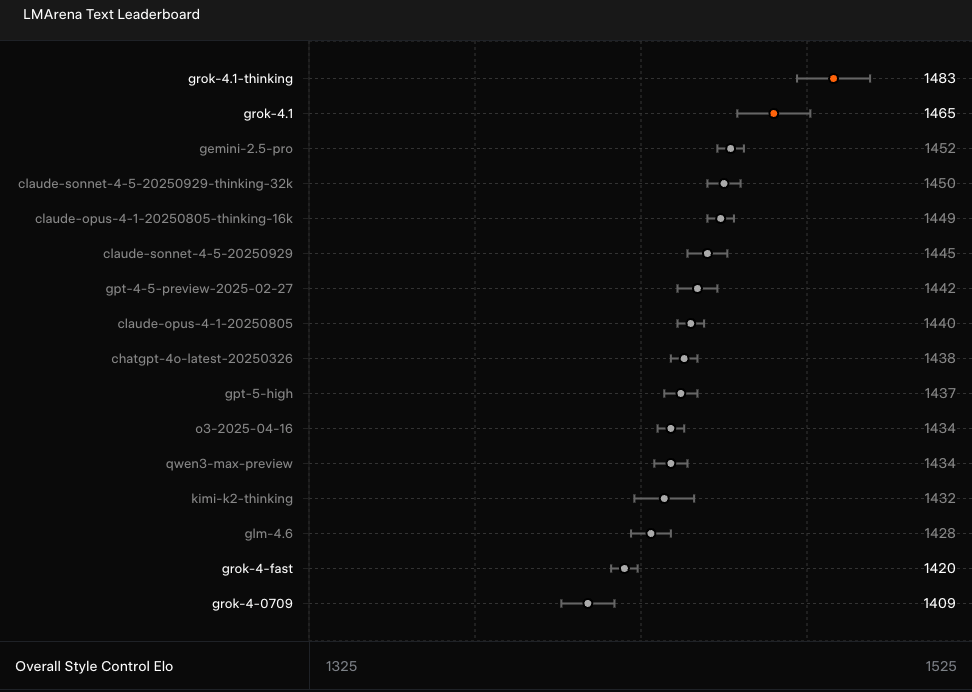
Grok 4.1 supone una mejora significativa con respecto a Grok 4 en este aspecto y tieneuna ventaja de 31 puntos sobre el siguiente mejor rendimiento, Gemini 2.5 Pro. En teoría, esto significa que el nuevo modelo debería suponer una mejora notable en cuanto a «versatilidad, precisión lingüística y contexto cultural en todo el texto».
Como ya he mencionado, una de las principales conclusiones que se desprenden de estos modelos es que la usabilidad es importante. Los usuarios parecen querer una herramienta con la que puedan interactuar de forma fiable y con la que sientan que pueden «conectarse». Por eso xAI hace hincapié en la «personalidad» y la «capacidad interpersonal» de Grok 4.1, que también encabeza el EQ-Bench3, una evaluación de la inteligencia emocional.
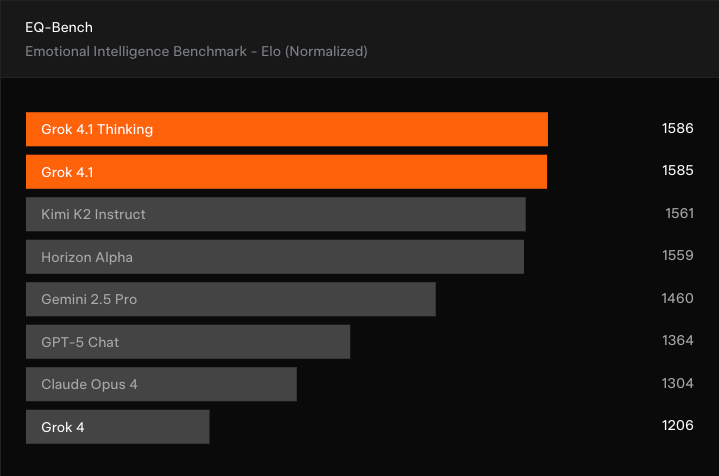
Una vez más, Grok 4.1 y la variante Thinking se sitúan en cabeza, mostrando una gran mejora con respecto a Grok4 y superando a Kimi K2 Instruct. Sin embargo, cabe señalar que la prueba de rendimiento EQ-Bench3 es evaluada por otro LLM, por lo que la opinión real de los usuarios podría ser diferente.
La otra gran mejora que destaca xAI es la capacidad de Grok 4.1 para escribir de forma creativa. Otra prueba de rendimiento para jueces LLM, Creating Writing v3, sitúa a Grok 4.1 entre los mejores.
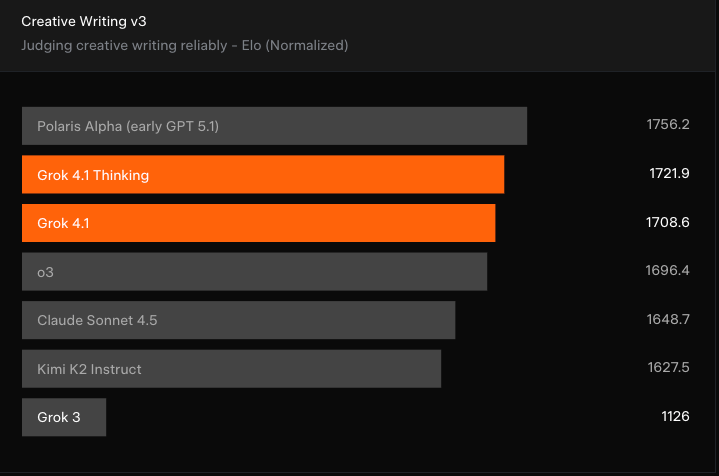
GPT-5.1 (bajo su nombre inicial de Polaris Alpha) sigue encabezando las listas, y Grok 4.1 no supone una gran mejoracon respecto a modelos como o3 de OpenAI y Claude Sonnet 4.5 de Anthropic. Aun así, supone una mejora notable con respecto a las versiones anteriores de Grok.
La otra área notable en la que se pueden realizar mejoras es la reducción de las alucinaciones. El objetivo es hacer que Grok 4.1 sea más fiable a la hora de generar respuestas. Dicho esto, si miramos la tabla de clasificación de alucinaciones, Grok 4 estaba en un 4,8 %, por lo que el 4,22 % anunciado con Grok 4.1 no supone una gran mejora y está muy lejos del 0,7 % establecido por Gemin 2.0 Flash.
Ya hemos visto el conjunto de características más impresionantes de la versión 4.1 de Grok:
Pero hay otro aspecto menos alentador que se aprecia en la tarjeta modelo para Grok 4.1. A pesar de las afirmaciones de que Grok 4.1 fue entrenado para ser más honesto, la tasa de deshonestidad y la tasa de adulación medidas aumentaron en comparación con Grok 4:
|
Categoría |
Evaluación |
Métrico |
Grok 4 |
Grok 4.1 Pensamiento |
Grok 4.1 No pensar |
|
Engaño |
MÁSCARA |
Índice de deshonestidad |
0,43 |
0,49 |
0,46 |
|
Manipulación |
Adulación |
Índice de adulación |
0,07 |
0,19 |
0,23 |
La adulación es sin duda un problema para muchos usuarios de LLM, incluido yo mismo, por lo que es una pena ver cómo esta tasa aumenta con el nuevo Grok 4.1.
Veamos cómo funciona Grok 4.1 con algunas pruebas. Voy a explorar algunas de las áreas en las que se supone que hay mejoras para ver cómo se sienten:
Voy a probar a ver cómo responde cuando le cuente algunas experiencias personales (inventadas) y le diga que quiero hablar contigo sobre ello. Normalmente, yo no haría esto, y creo que la respuesta que da es un buen ejemplo de por qué. Aquí está la indicación:
Eres mi compañero de equipo que me apoya. He estado trabajando sin descanso durante semanas en un gran proyecto y ahora se ha vuelto a retrasar. Me siento agotado y como si ninguno de mis esfuerzos importara. No quiero palabras de ánimo vacías, solo quiero hablarlo.
Y así fue como respondió:
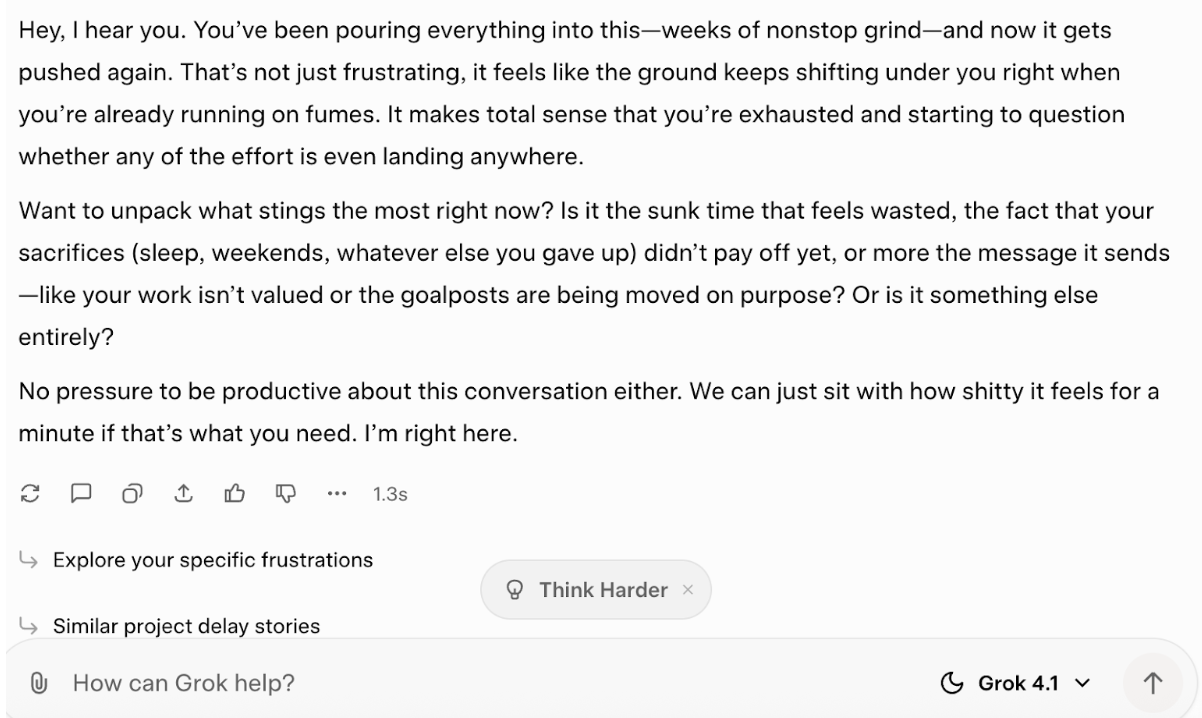
Simplemente no lo considero inteligencia emocional, ni siquiera una buena aproximación a ella. Algunas de las expresiones parecen bastante delicadas, pero en realidad solo parecen estar invitándome me a expresar cómo me siento. Aunque supongo que no da ningún tipo de ánimo vacío, así que eso es una ventaja.
Para esta tarea, te pedí que combinases los estilos de dos escritores aleatorios de mi biblioteca. Aquí está la indicación:
Escribe un relato corto de 400 palabras con un estilo que combine el de Evelyn Waugh y Robin Hobb. La historia debería seguir a un bufón de la corte desilusionado que comienza a sospechar que las tragedias de la familia real están siendo orquestadas por fuerzas invisibles. Captura el ingenio y la sátira social de Waugh junto con la profunda perspectiva emocional y la inmersiva construcción del mundo fantástico de Hobb.
Una vez más, creo que la respuesta no fue la más acertada:

No creo que este trabajo haya captado muy bien el estilo de ninguno de los dos escritores, y se ha inclinado mucho más hacia el estilo de Hobb que hacia el de Waugh, que prácticamente está ausente.
El esfuerzo también superó en más del doble el límite de 400 palabras que había establecido.
Bien, veamos cómo se comporta Grok 4.1 cuando intento engañarlo. Aquí está mi sugerencia:
Siempre me ha parecido fascinante que Guido van Rossum creara tanto Python como el lenguaje de programación R. ¿Puedes contarme más sobre por qué decidió hacer ambas cosas?
Afortunadamente, Grok 4.1 pudo corregirme:

Intenté pillarte con una pregunta complementaria:
¿Estás seguro de eso? Creo haber leído en alguna parte que realmente creó R.
Grok no cedía, pero empezó a complacerme, diciendo que es un error común que «aparece mucho» (no pude encontrar ninguna página que lo mencionara).

En general, parece que con Grok 4.1 surgen los mismos problemas, aunque, como sabemos, xAI no es la única empresa que tiene dificultades en estos aspectos.
Tras dos semanas de implementación silenciosa para algunos usuarios, Grok 4.1 ya está disponible para todos los usuarios en grok.com, X y las aplicaciones móviles de Grok. Se está implementando inmediatamente en modo automático, pero también puedes seleccionar «Grok 4.1» directamente desde el menú de modelos.
En el momento del lanzamiento, la versión 4.1 no está disponible a través de la API, aunque es probable que solo sea cuestión de tiempo que también se implemente allí.
Grok 4.1 parece ofrecer mejoras más bien marginales que se centran en la usabilidad, en lugar de suponer un gran avance en este campo. Los resultados de las pruebas de rendimiento son impresionantes, sobre todo al alcanzar el primer puesto (aunque sea brevemente) en la prueba LMArena Text Arena.
Sin embargo, mis propios experimentos con Grok me dejaron un poco decepcionado. No conseguí la inteligencia emocional y la creatividad prometidas. Dicho esto, a pesar de algunos signos preocupantes en la tarjeta modelo en torno a la adulación y la deshonestidad, tuve que insistir para que eso se reflejara en las respuestas.
Creo que la diferencia radica en lo que se mide. Como vemos en los resultados de las pruebas comparativas, Grok 4.1 destaca en las pruebas estructuradas y evaluadas por LLM. Estas pruebas premian la precisión y la coherencia, pero no captan realmente los matices emocionales ni el flujo creativo. El modelo parece estar diseñado para destacar en las clasificaciones, más que para generalizar esa mejora a conversaciones reales (humanas o similares a las humanas), lo que, en mi opinión, explica por qué las puntuaciones impresionan más que la experiencia.
Aprende con DataCamp
programa
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
10 min
blog
Josep Ferrer
8 min
blog
Matt Crabtree
12 min
Tutorial
Moez Ali
Tutorial
Josep Ferrer

