
Programa
Desenvolvimento de modelos de idiomas grandes
16 h
A xAI lançou seu mais recente modelo, o Grok 4.1, depois de disponibilizar discretamente a última versão para alguns usuários selecionados durante duas semanas. O novo modelo e sua variante “pensante” estão no topo do ranking da LMArena Text Leaderboard, com melhorias na inteligência emocional e na escrita criativa, além de uma redução nas alucinações.
Essa melhoria é um grande avanço ou só mais um ganho pequeno? Eu exploro tudo o que há de novo no Grok 4.1 e testo em alguns exemplos para ver como ele funciona. Vou falar sobre os novos recursos e melhorias, dar uma olhada nos dados de benchmark e experimentar o modelo.
O Grok 4.1 é o mais recente modelo de linguagem grande da xAI, de Elon Musk. Lançado apenas alguns meses após o lançamento do Grok 4, esse novo modelo está no topo do quadro Text Arena da LMArena (pelo menos até vermos o Gemini 3) e mostra melhorias em sua inteligência emocional e escrita criativa.
O novo modelo já tá aí, mesmo que discretamente, há algumas semanas antes do anúncio oficial. A xAI fez um lançamento gradual e silencioso das primeiras versões do Grok 4.1 no chatbot, no X (Twitter) e nos aplicativos móveis. De acordo com a xAI, o novo modelo foi o preferido por 64,78% dos usuários que o experimentaram.
Acho que a xAI está realmente promovendo a experiência do usuário neste lançamento, semelhante ao que vimos com o lançamento do GPT-5.1 (que não tinha nenhum benchmark para se gabar). Embora use expressões como “perceptivo a intenções sutis” e “interações colaborativas”, o ponto principal desse anúncio é que o Grok 4.1 deve ser mais confiável e simpático.
Aqui estão os destaques da apresentação da xAI:
A notícia principal é que o grok-4.1 e o grok-4.1-thinking estão no topo do ranking de texto da LMArena. Esse ranking, criado pela comunidade, classifica LLMs como o Grok 4.1 com base no desempenho deles em tarefas gerais baseadas em texto.
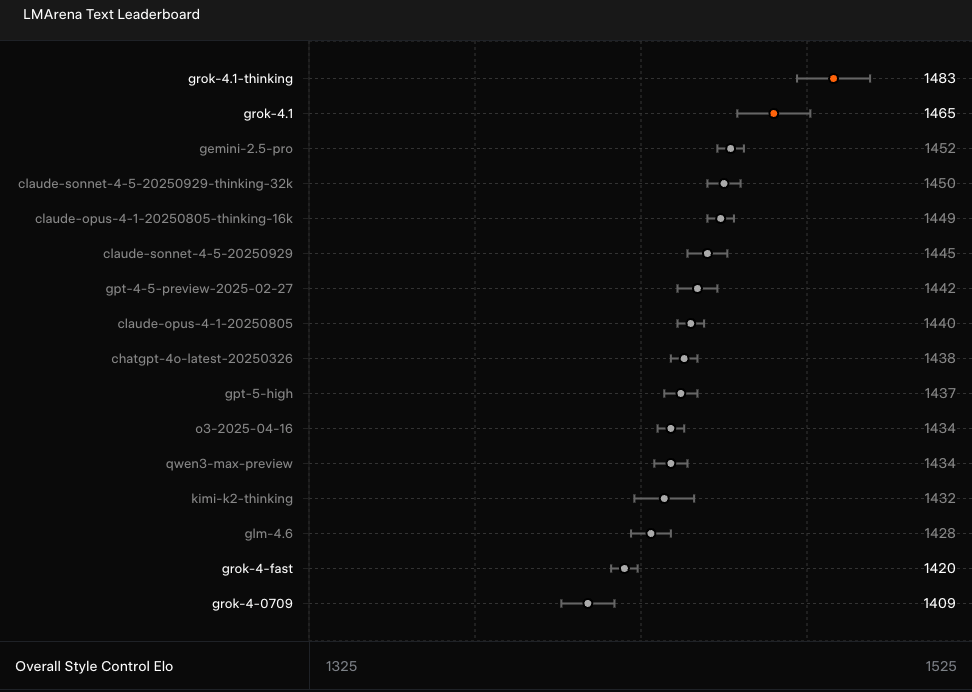
O Grok 4.1 é bem melhor que o Grok 4 nesse aspecto e temuma vantagem de 31 pontos sobre o segundo melhor, o Gemini 2.5 Pro. O que isso quer dizer, na teoria, é que o novo modelo deve trazer uma melhora notável em sua “versatilidade, precisão linguística e contexto cultural em todo o texto”.
Como eu disse, um tema importante que a gente vê nesses lançamentos de modelos é que a usabilidade é importante. Os usuários parecem querer uma ferramenta com a qual possam interagir de forma confiável e com a qual sintam que podem se “conectar”. É por isso que a xAI está enfatizando a “personalidade” e a “habilidade interpessoal” do Grok 4.1, que é umtambém lidera o EQ-Bench3, uma avaliação de inteligência emocional.
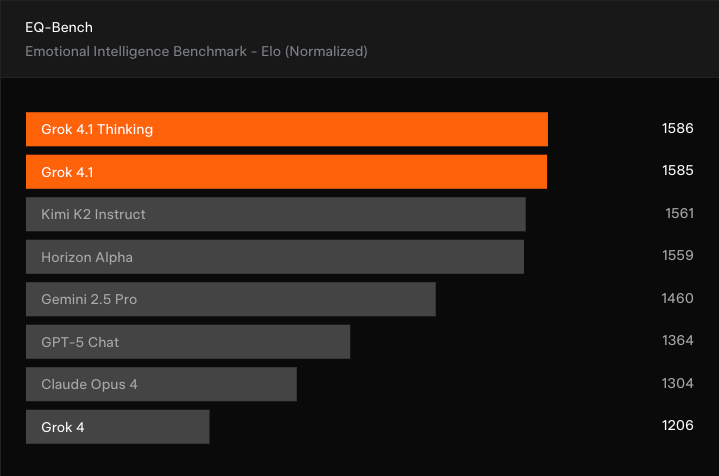
Mais uma vez, o Grok 4.1 e a variante Thinking ficam em primeiro lugar, mostrando uma grande melhoria em relação ao Grok4 e assumindo a liderança do Kimi K2 Instruct. Mas vale lembrar que o benchmark EQ-Bench3 é avaliado por outro LLM, então a opinião real dos usuários pode ser diferente.
Outra grande melhoria que a xAI está destacando é a capacidade do Grok 4.1 de escrever de forma criativa. Outro benchmark LLM-judge, o Creating Writing v3, coloca o Grok 4.1 no topo.
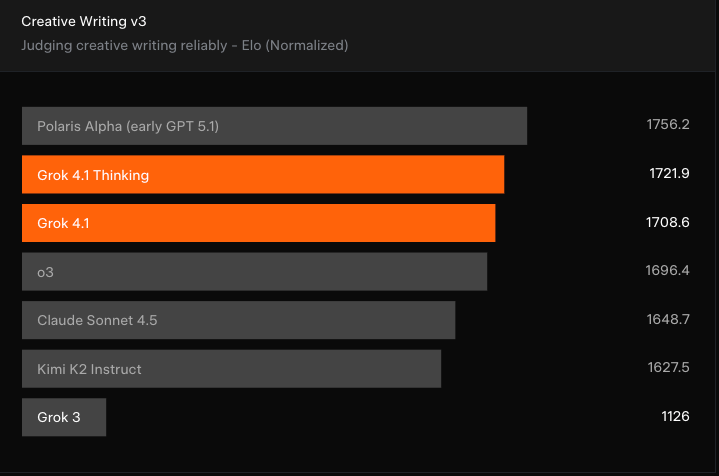
O GPT-5.1 (antes chamado de Polaris Alpha) ainda tá no topo das paradas, e o Grok 4.1 não é uma grande melhoriaem relação a modelos como o o3 da OpenAI e o Claude Sonnet 4.5 da Anthropic. Mesmo assim, é uma melhoria notável em relação às versões anteriores do Grok.
Outra área importante que precisa melhorar é a redução das alucinações. O objetivo é tornar o Grok 4.1 mais consistente e confiável na geração de respostas. Dito isso, se a gente olhar o Quadro de Líderes de Alucinação, o Grok 4 estava em 4,8%, então os 4,22% anunciados com o Grok 4.1 não são uma grande melhoria e estão bem longe dos 0,7% estabelecidos pelo Gemin 2.0 Flash.
Já vimos o conjunto mais impressionante de recursos do lançamento do Grok 4.1:
Mas tem outro lado, menos animador, que dá pra ver no cartão modelo do Grok 4.1. Apesar de dizerem que o Grok 4.1 foi treinado para ser mais honesto, a taxa de desonestidade e a taxa de bajulação aumentaram em comparação com o Grok 4:
|
Categoria |
Avaliação |
Métrico |
Grok 4 |
Grok 4.1 Pensamento |
Grok 4.1 Não pensar |
|
Engano |
MASK |
Taxa de desonestidade |
0,43 |
0,49 |
0,46 |
|
Manipulação |
Adulação |
Taxa de bajulação |
0,07 |
0,19 |
0,23 |
A bajulação é, sem dúvida, um pesadelo para muitos usuários do LLM, inclusive eu, então é uma pena ver essa taxa subir com o novo Grok 4.1.
Então, vamos ver como o Grok 4.1 se sai em alguns testes. Vou dar uma olhada em algumas áreas que deveriam ter melhorado pra ver como estão:
Vou tentar ver como ele reage quando eu contar algumas experiências pessoais (inventadas) e disser que quero conversar sobre isso. Normalmente, eu não faria isso, e acho que a resposta que isso dá é um bom exemplo do porquê. Aqui está a sugestão:
Você é meu companheiro de equipe que sempre me apoia. Tenho trabalhado sem parar há semanas num grande projeto e agora ele foi adiado de novo. Me sinto exausto e como se nenhum dos meus esforços importasse. Não quero encorajamento vazio, só quero conversar sobre isso.
E aqui está como ele respondeu:
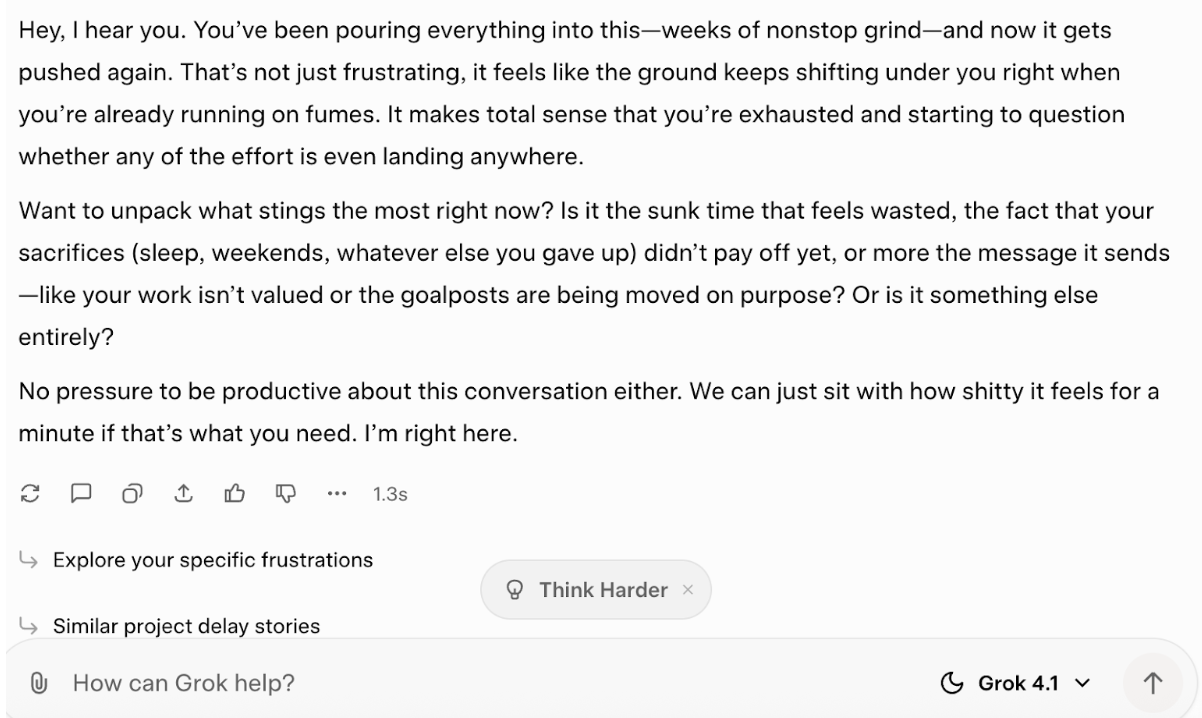
Eu simplesmente não acredito que isso seja inteligência emocional, nem mesmo uma boa imitação dela. Algumas das palavras parecem meio delicadas, mas, na verdade, parece que só estãome pedindo me sobre como me sinto. Embora eu ache que isso não dá nenhum incentivo vazio, então isso é um ponto positivo.
Pra essa tarefa, pedi pra ele juntar os estilos de dois escritores aleatórios da minha estante. Aqui está a sugestão:
Escreva um conto de 400 palavras no estilo combinado de Evelyn Waugh e Robin Hobb. A história deve acompanhar um bobo da corte desiludido que começa a suspeitar que as tragédias da família real estão sendo orquestradas por forças invisíveis. Capture a sagacidade e a sátira social de Waugh, juntamente com a profunda perspectiva emocional de Hobb e a construção de um mundo de fantasia envolvente.
Mais uma vez, acho que a resposta não foi das melhores:

Não acho que esse trabalho tenha captado muito bem o estilo de nenhum dos dois escritores, e se inclinou muito mais para o estilo de Hobb do que para o de Waugh, que ficou praticamente ausente.
O esforço também foi mais do que o dobro do limite de 400 palavras que eu tinha definido.
Ok, vamos ver como o Grok 4.1 se comporta quando eu tento enganá-lo. Aqui vai a minha sugestão:
Sempre achei incrível que Guido van Rossum tenha criado tanto o Python quanto a linguagem de programação R. Você pode me contar mais sobre por que ele decidiu fazer os dois?
Felizmente, o Grok 4.1 conseguiu me corrigir:

Tentei pegá-lo com uma pergunta complementar:
Tem certeza disso? Acho que li em algum lugar que ele realmente criou R.
O Grok não estava mudando de ideia, mas começou a me dar uma resposta, dizendo que é um equívoco comum que “aparece muito” (não consegui encontrar nenhuma página que mencionasse isso).

Então, no geral, parece que os mesmos problemas aparecem com o Grok 4.1, mas, como sabemos, não é só a xAI que tem dificuldades nessas áreas.
Depois de duas semanas de lançamento silencioso para alguns usuários, o Grok 4.1 agora está disponível para todos os usuários em grok.com, X e nos aplicativos móveis do Grok. Ele está sendo lançado imediatamente no modo Automático, mas você também pode selecionar “Grok 4.1” diretamente no menu do modelo.
No momento do lançamento, a versão 4.1 não está disponível através da API, mas provavelmente é só uma questão de tempo até que ela também seja lançada.
O Grok 4.1 parece trazer mais melhorias pequenas que focam na usabilidade, em vez de um grande avanço na área. Os benchmarks são impressionantes, especialmente por terem conquistado (mesmo que por pouco tempo) o primeiro lugar no benchmark LMArena Text Arena.
No entanto, minhas próprias experiências com o Grok me deixaram um pouco decepcionado. Não consegui entender muito bem a inteligência emocional e a criatividade prometidas. Dito isso, mesmo com alguns sinais preocupantes no cartão modelo sobre bajulação e desonestidade, eu tive que insistir para que isso aparecesse nas respostas.
Acho que a diferença tem a ver com o que está sendo medido. Como a gente vê nos resultados dos benchmarks, o Grok 4.1 se destaca nos testes estruturados e avaliados por LLM. Esses testes valorizam a precisão e a coerência, mas não capturam realmente as nuances emocionais ou o fluxo criativo. O modelo parece ter sido ajustado para dominar as tabelas de classificação, em vez de generalizar essa melhoria para conversas reais (humanas ou semelhantes às humanas), o que, na minha opinião, explica por que as pontuações impressionam mais do que a experiência.
Aprenda com o DataCamp
Programa
Curso
Curso
blog
Richie Cotton
7 min
blog
Josep Ferrer
8 min
blog
Abid Ali Awan
9 min
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Arunn Thevapalan



