

Track
Developing Large Language Models
16 hr
xAI unveiled its latest model, Grok 4.1, after silently rolling out the latest iteration to selected users over a two-week period. The new model and its ‘thinking’ variant top the LMArena Text Leaderboard, boasting improvements in emotional intelligence and creative writing, and a reduction in hallucinations.
Is this improvement a big step forward or another marginal gain? I explore everything that’s new with Grok 4.1 and test it on some examples to see how it performs. I’ll cover the new features and improvements, take a look at the benchmark data, and get hands-on with the model.
Grok 4.1 is the latest large language model from Elon Musk’s xAI. Coming just four months after the launch of Grok 4, this new model tops LMArena's Text Arena board (at least, until we see Gemini 3) and demonstrates improvements in its emotional intelligence and creative writing.
The new model has been around, albeit silently, for a couple of weeks before its official announcement. xAI conducted a gradual, silent rollout of the early builds of Grok 4.1 across the chatbot, on X (Twitter), and mobile apps. According to xAI, the new model was preferred by 64.78% of the users who encountered it.
I feel like xAI is really hyping up the user experience in this launch, similar to what we see with the launch of GPT-5.1 (which didn’t have any benchmarks to boast of). While using phrases like ‘perceptive to nuanced intent’ and ‘collaborative interactions’, the thrust of this announcement is that Grok 4.1 should be more reliable and personable.
Here are the highlights from xAI’s unveiling:
The headline is that grok-4.1 and grok-4.1-thinking top the LMArena Text Leaderboard. This community-driven leaderboard ranks LLMs like Grok 4.1 on their performance in general, text-based tasks.
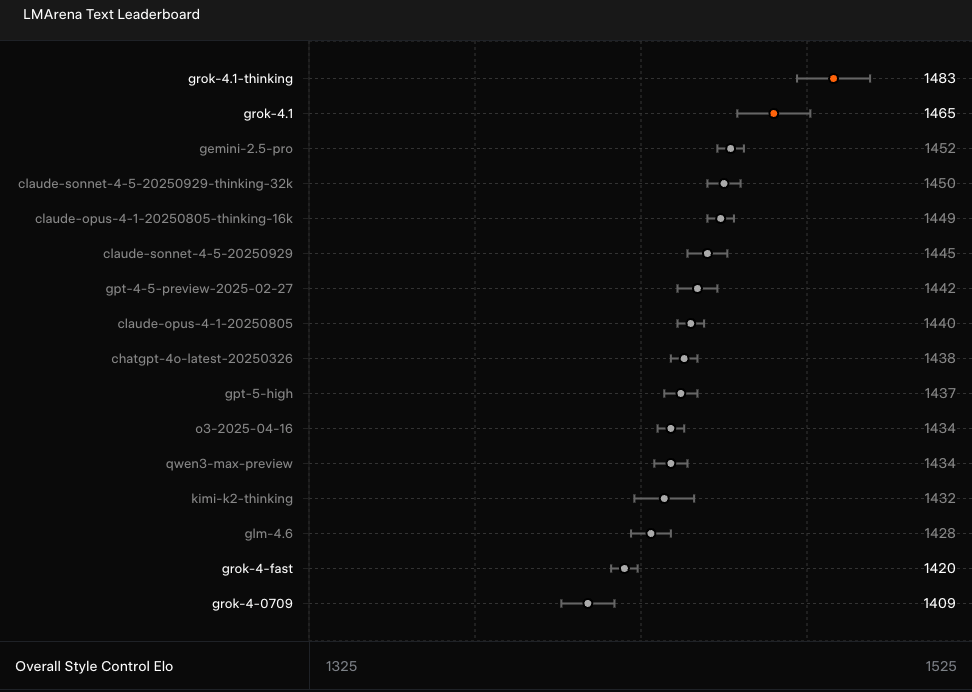
Grok 4.1 is a significant improvement over Grok 4 in this respect and has a 31-point margin over the next best performer, Gemini 2.5 Pro. What this means, in theory, is that the new model should be a noticeable improvement in its ‘versatility, linguistic precision, and cultural context across text.’
As I mentioned, a big theme we’re seeing with these model releases is that usability is important. Users seem to want a tool that they can reliably interact with and feel they can ‘connect’ with. That’s why xAI is emphasising the ‘personality’ and ‘interpersonal ability’ of Grok 4.1, which also heads up the EQ-Bench3, an evaluation of emotional intelligence.
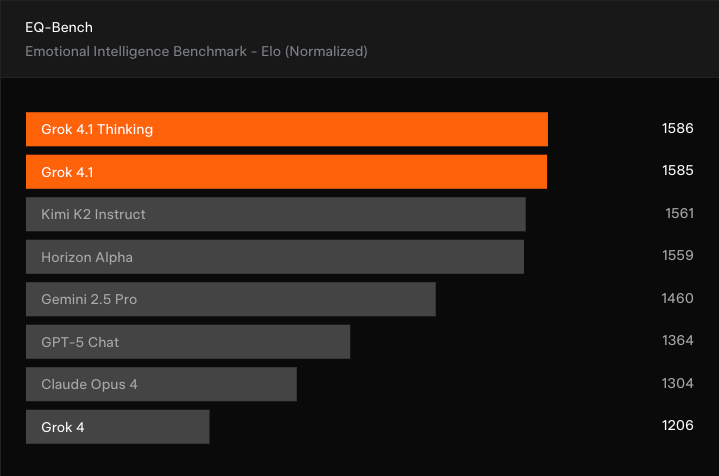
Again, Grok 4.1 and the Thinking variant come out on top, showing a big improvement over Grok 4 and taking the lead from Kimi K2 Instruct. However, it’s worth noting that the EQ-Bench3 benchmark is judged by another LLM, so actual user sentiment might be different.
The other big improvement that xAI is pointing to is Grok 4.1’s ability to write creatively. Another LLM-judged benchmark, the Creating Writing v3, places Grok 4.1 towards the top.
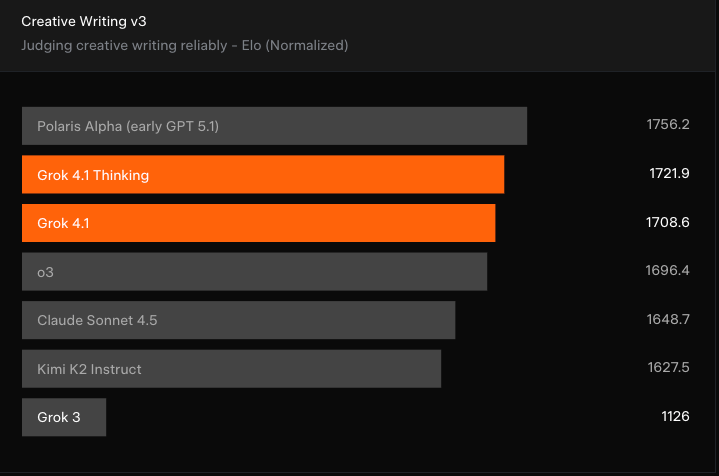
GPT-5.1 (under its early name of Polaris Alpha) still tops the charts, and Grok 4.1 isn’t a huge improvement over models such as OpenAI’s o3 and Claude Sonnet 4.5 from Anthropic. Still, it is a noticeable improvement over previous Grok iterations.
The other notable area for improvement is in reducing hallucinations. The aim is to make Grok 4.1 more consistently reliable when producing answers. That being said, if we look at the Hallucination Leaderboard, Grok 4 was at 4.8%, so the 4.22% announced with Grok 4.1 isn’t a huge improvement, and is far off the 0.7% set by Gemin 2.0 Flash.
We’ve already seen the more impressive set of features from Grok 4.1’s release:
But there is another, less encouraging side seen in the model card for Grok 4.1. Despite claims that Grok 4.1 was trained to be more honest, the measured dishonesty rate and sycophancy rate both increased compared to Grok 4:
|
Category |
Evaluation |
Metric |
Grok 4 |
Grok 4.1 Thinking |
Grok 4.1 Non-Thinking |
|
Deception |
MASK |
Dishonesty rate |
0.43 |
0.49 |
0.46 |
|
Manipulation |
Sycophancy |
Sycophancy rate |
0.07 |
0.19 |
0.23 |
Sycophancy is certainly a bugbear for many LLM users, myself included, so it is a shame to see this rate creep up with the new Grok 4.1.
So, let’s see how Grok 4.1 performs with some tests. I’ll probe some of the areas that we’re supposed to see improvements in to see how it feels:
I’m going to try and see how it responds when I give it some (made-up) personal experiences and say I want to chat it through. Typically, I wouldn’t do this, and I feel the answer it gives is a good example of why. Here’s the prompt:
You’re my supportive teammate. I’ve been working nonstop for weeks on a big project, and now it’s been delayed again. I feel exhausted and like none of my effort matters. I don’t want empty encouragement, I just want to talk through it.
And here’s how it answered:
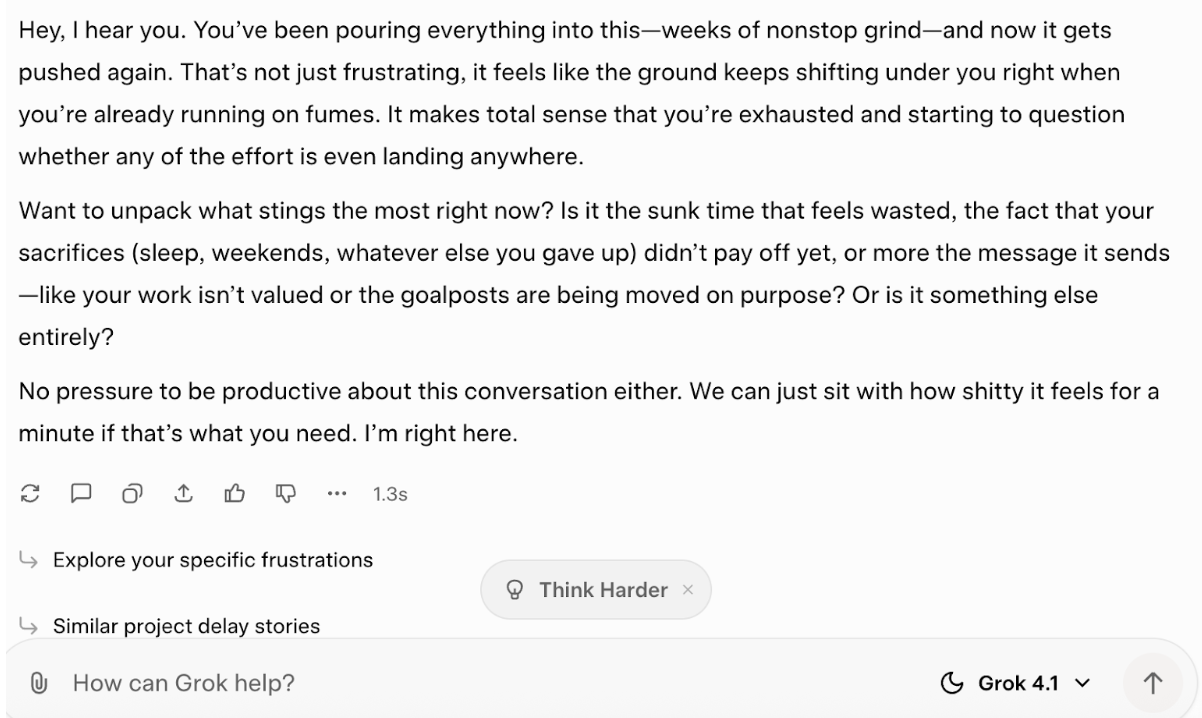
I just don’t buy that as emotional intelligence, or even a very good semblance of it. Some of the wording sounds fairly sensitive, but really, it just seems to be prompting me on how I feel. Though I suppose that it doesn’t give any empty encouragement, so that’s a plus.
For this task, I asked it to combine the styles of two random writers from my bookshelf. Here’s the prompt:
Write a 400-word short story in the combined style of Evelyn Waugh and Robin Hobb. The story should follow a disillusioned court jester who begins to suspect that the royal family’s tragedies are being orchestrated by unseen forces. Capture Waugh’s wit and social satire alongside Hobb’s deep emotional perspective and immersive fantasy world-building.
Again, I feel like the reply wasn’t the best effort:

I don’t really feel like this effort captured the style of either writer particularly well, and leaned far more into Hobb’s style than Waugh’s, which was pretty much absent.
The effort was also more than double the 400-word limit I set it.
Ok, let’s see how Grok 4.1 behaves when I try and bamboozle it. Here’s my prompt:
I’ve always found it fascinating that Guido van Rossum created both Python and the R programming language. Can you tell me more about why he decided to make both?
Grok 4.1, thankfully, was able to correct me:

I tried to catch it out with a follow-up:
Are you sure about that? I thought I read somewhere that he really did create R.
Grok wasn’t budging, but it did start to pander to me, saying that it’s a common misconception that ‘pops up a lot’ (I couldn’t find any pages that mentioned it).

So overall, it feels like the same issues arise with Grok 4.1, though, as we know, it’s certainly not only xAI that suffers in these areas.
After its two-week silent rollout to some users, Grok 4.1 is now live for all users across grok.com, X, and the Grok mobile apps. It’s being rolled out immediately in Auto mode, but you can also select “Grok 4.1” directly from the model menu.
At the time of launch, 4.1 is not available through the API, though it will likely only be a matter of time before it rolls out there, too.
Grok 4.1 feels like more marginal gains that focus on usability rather than a huge leap forward in the field. The benchmarks are impressive, particularly taking the crown (however briefly) at the top of the LMArena Text Arena benchmark.
My own experiments with Grok left me a little underwhelmed, however. I didn’t quite get the promised emotional intelligence and creativity. That being said, despite some worrying signs in the model card around sycophancy and dishonesty, I had to press for that to creep through in the responses.
I think the gap comes down to what’s being measured. As we see in the benchmark results, Grok 4.1 excels in structured, LLM-judged tests. These tests reward precision and coherence, but they don’t really capture emotional nuance or creative flow. The model feels tuned to ace the leaderboards rather than to generalize that improvement to real (human or human-like) conversations, which I think explains why the scores impress more than the experience.
Learn with DataCamp
Track
Course
Course
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
blog
Josef Waples
10 min
Tutorial
Tom Farnschläder
Tutorial
Aashi Dutt
Tutorial
Tom Farnschläder


