
Cours
Introduction à MongoDB en Python
3 h
24K
L'intelligence artificielle infiltrant et remodelant tous les secteurs d'activité, l'accent est toujours mis sur les nouvelles caractéristiques et fonctionnalités, mais que se passe-t-il en coulisses ? Derrière chaque application d'IA se cache quelque chose de moins prestigieux mais d'incroyablement crucial : l'infrastructure qui l'alimente. Quels sont donc les outils qui permettent à l'apprentissage automatique de prospérer ?
Dans un monde axé sur les données, tout commence par la manière dont les données sont stockées et, surtout, par la manière dont elles sont recherchées. C'est là que les bases de données vectorielles entrent en jeu.
Qu'est-ce qu'une base de données vectorielle ? Une base de données vectorielle est une base de données spécialement conçue pour stocker et rechercher des encastrements vectoriels, ce qui permet aux développeurs d'utiliser diverses fonctionnalités d'IA telles que la recherche sémantique, la reconnaissance d'images, les chatbots, et bien d'autres encore.
Mais qu'est-ce que cela signifie exactement ? Pour bien comprendre ce qu'est une base de données vectorielle, revenons quelques instants en arrière. Démystifions ces bases de données intégrales en reprenant les bases dès le début, en commençant par l'acteur clé de ce processus : l'intégration vectorielle.
Un vecteur (dans le contexte de l'intelligence artificielle) est simplement une liste de nombres qui représente la signification sémantique d'une image, d'une phrase, d'un son et même d'une vidéo. Cette séquence de nombres aide les ordinateurs à comprendre comment chaque donnée est similaire à une autre : Ils placent les données (comme les mots ou les images) comme des points sur une "carte mathématique" où les concepts similaires sont plus proches les uns des autres.
Nous pouvons considérer que l'intégration de vecteurs revient à transformer un élément de données en coordonnées GPS - des données ayant des significations similaires (comme "chien" et "chiot") se retrouvent dans le même quartier !
Pourquoi devons-nous transformer nos données en vecteurs ? Imaginez que vous essayez d'expliquer à une machine la différence entre un chat et un chien. Alors que les êtres humains sont capables de comprendre cette différence, une machine ne peut saisir et comprendre que des chiffres : Il est impossible d'expliquer à votre ordinateur portable la différence entre Toto et Garfield.
En transformant vos données en structures vectorielles spécifiques où chaque nombre est ordonné de manière unique en fonction des données sources, votre machine est capable de comprendre les relations entre différents points de données !
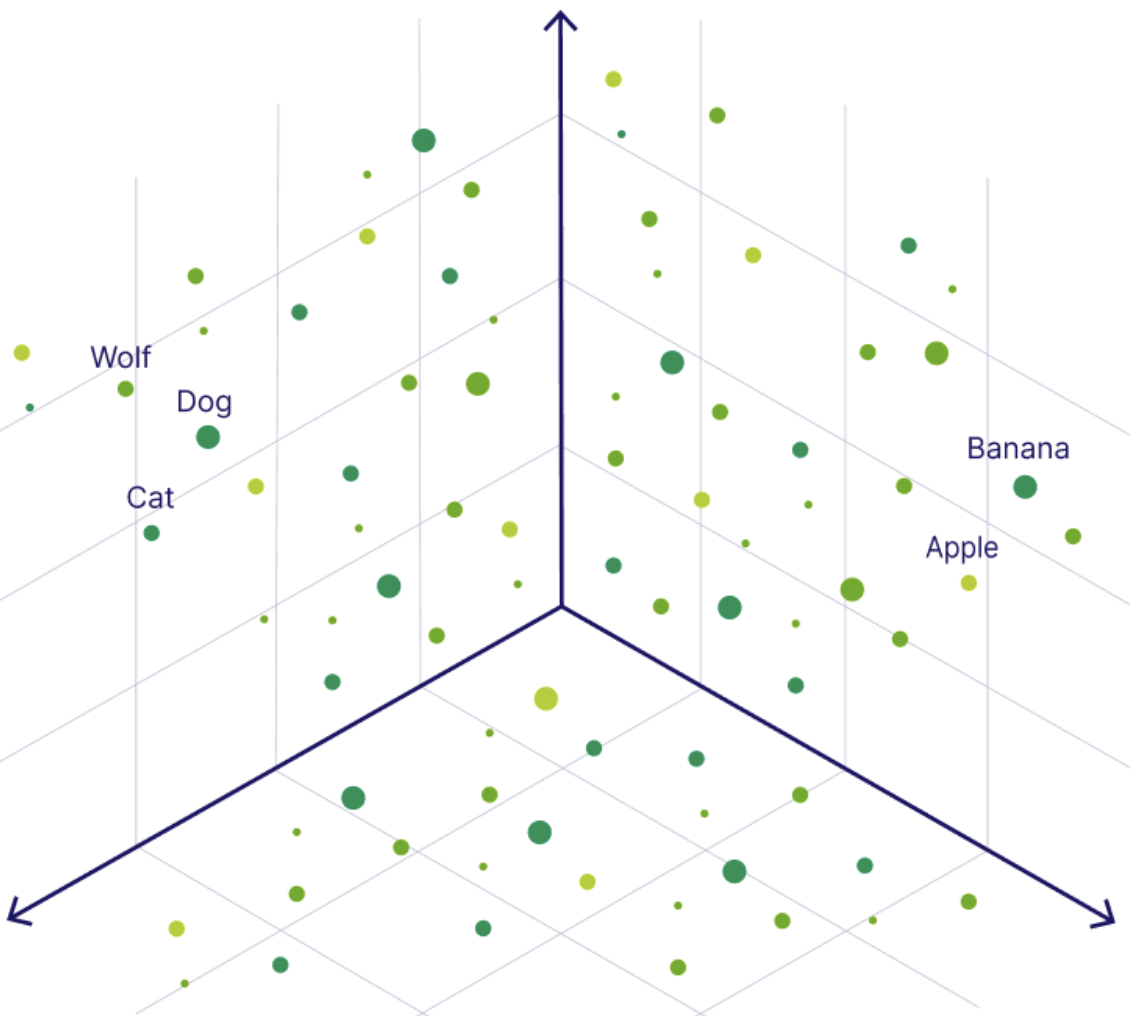
Présentation d'un encastrement vectoriel dans un espace multidimensionnele. Source de l'image.
Voyons comment cela est possible en discutant de la recherche par similarité.
La recherche par similarité est la technique utilisée pour trouver les documents les plus similaires à la requête initiale de l'utilisateur. Effectuer une recherche à l'aide de vecteurs revient à demander : "Laquelle de ces images ressemble le plus à un chat ?" au lieu de se contenter de faire correspondre exactement le mot "chat".
Comme il s'agit de vecteurs dans un espace multidimensionnel, des mathématiques interviennent dans ce processus pour nous aider à déterminer quelles sont les intégrations les plus semblables.
Il existe une multitude d'algorithmes de recherche de similitudes, mais les trois plus courants sont les suivants :
La similarité cosinus mmesure l'angle entre deux vecteurs (elle ne se soucie pas de la taille du vecteur) et est le plus souvent utilisée pour l'intégration de textes, la similarité sémantique et les systèmes de recommandation. Il aide les développeurs à comparer la direction générale des vecteurs, ce qui permet de déterminer le contenu général des documents, d'où son importance pour les sujets cités.
La distance euclidienne mesurela distance en ligne droite entre deux vecteurs dans l'espace. Une bonne façon de l'envisager est de mesurer le chemin le plus court entre deux points sur une carte !
Cette distance est la plus simple car si la distance calculée est très petite, cela signifie que les coordonnées vectorielles sont très proches, ou très similaires, l'une de l'autre.
Cette métrique étant très sensible aux grandeurs, elle est surtout utile lorsque les encastrements ont trait à des valeurs numériques. Cela est particulièrement utile pour les moteurs de recommandation qui permettent aux utilisateurs de savoir ce qu'ils doivent commander en fonction du nombre de fois qu'ils ont acheté un article dans le passé.
La similarité du produit des points mesure non seulement le produit des magnitudes vectorielles, mais aussi le cosinus de l'angle qui les sépare. Cela signifie que le produit de points s'intéresse à la fois à la longueur (magnitude) et à la direction des vecteurs !
Lorsque les vecteurs sont normalisés (la magnitude du vecteur est égale à un mais la direction reste la même), la similitude du produit de point devient la même que la similitude du cosinus puisque la magnitude n'est plus prise en compte.
La similarité du produit de points est le plus souvent utilisée dans des domaines tels quele traitement du langage naturel (NLP) et la vision par ordinateur.
Vous avez donc maintenant vos données brutes représentées sous forme d'intégrations vectorielles. Nous allons nous plonger dans toutes les possibilités incroyables qui s'offrent à vous lorsque vos données sont représentées par ces encastrements.
La recherche sémantique est un moyen de rechercher des données sur la base du sens réel de la requête de l'utilisateur, et non pas seulement une recherche de correspondance exacte. Cela signifie qu'au lieu d'effectuer une recherche basée sur des mots-clés spécifiques, les résultats seront affichés même si un mot est mal orthographié, et les résultats seront affichés sur la base des synonymes de la requête initiale.
Par exemple, si un utilisateur recherche "les meilleurs cafés près de chez moi", une recherche exacte ne fera apparaître que les "cafés" spécifiquement étiquetés, alors qu'un moteur de recherche sémantique comprendra et affichera les lieux qui proposent du "thé", du "café", des "pâtisseries", ou d'autres résultats qu'une compréhension contextuelle plus approfondie permettrait d'obtenir.
Comment cette recherche est-elle possible ? Encastrements vectoriels ! Supposons que nous intégrions la requête d'un utilisateur et les données (telles que les descriptions de lieux). Cela permet de les comparer les uns aux autres dans un espace multidimensionnel, en recherchant les vecteurs les plus proches les uns des autres à l'aide de méthodes telles que la recherche de similitudes.
Par exemple, si l'utilisateur demande "meilleurs cafés près de chez moi" et qu'il dispose d'une base de données remplie de descriptions de lieux Google Maps qui ont été intégrées, la recherche sémantique affichera les lieux dont les intégrations sont les plus similaires à la requête initiale, même si le mot "café" n'est jamais utilisé dans ces descriptions de lieux !
Les systèmes de recommandation utilisent des données pour aider les gens à trouver ce qui leur plairait statistiquement le plus, en fonction de leurs achats précédents, de leur historique de recherche, d'informations environnementales et démographiques, etc. Ils sont utilisés dans presque tous les secteurs, du divertissement à la finance.
Les plateformes les plus évidentes qui utilisent des systèmes de recommandation sont des entreprises comme Spotify, Netflix et Amazon, mais il y en a dans tous les secteurs, d'autant plus que de plus en plus d'entreprises adoptent des politiques en matière d'IA.
Ils sont parfaitement formés pour comprendre les différentes caractéristiques, les décisions antérieures et les préférences des utilisateurs sur la base d'une multitude d'interactions, notamment les clics, les mentions "j'aime" et les vues. Nous avons tous l'habitude de nous voir recommander de nouveaux produits, films ou chansons en fonction de nos achats antérieurs, mais comment un algorithme peut-il savoir ce que nous sommes susceptibles d'aimer ? Encastrements vectoriels !
À un niveau très élevé, les systèmes de recommandation comparent divers éléments aux préférences connues de l'utilisateur. Pour que ces recommandations aient un sens, les utilisateurs et les objets sont convertis en vecteurs intégrés. Il existe deux techniques très courantes pour cela : les recommandations basées sur le contenu et le filtrage collaboratif.
Prenons l'exemple des films. Avec les recommandations basées sur le contenu, les films sont intégrés en fonction de leurs différentes caractéristiques, et les utilisateurs sont intégrés en fonction des films qu'ils ont regardés par le passé. Ce système peut alors recommander de nouveaux films dont les vecteurs sont les plus proches des vecteurs de préférence de l'utilisateur, ou des films qu'il a regardés par le passé.
Avec le filtrage collaboratif, de nombreux utilisateurs sont pris en considération. Au lieu de se concentrer sur un seul utilisateur et un seul objet, le filtrage collaboratif trouve plusieurs utilisateurs dont les vecteurs sont les plus proches des vôtres et recommande des objets ou des films qu'ils ont appréciés.
Les chatbots ou RAG constituent une autre application intéressante des vector embeddings.
La génération augmentée par récupération est une façon d'utiliser réellement et pleinement les capacités des grands modèles de langage (LLM) en intégrant des informations externes et actualisées afin que les LLM puissent générer des réponses plus précises. En effet, les LLM sont normalement formés sur des données statiques, ils ont donc une base de connaissances limitée et ne sont pas en mesure d'accéder à des données locales ou personnalisées.
Avec les embeddings vectoriels, il est possible d'enregistrer des données personnalisées dans une base de données vectorielle, ce qui permet de créer une base de données personnalisées entièrement personnalisable qui peut être utilisée dans n'importe quel projet ! Les données étant stockées sous forme de vecteurs intégrés, il est possible d'extraire des documents sémantiquement similaires directement de la base de données en fonction de la requête de l'utilisateur.
L'avantage de RAG est qu'il est parfait pour diverses tâches, telles que répondre à des questions et générer du texte. Cela signifie qu'il est parfait pour créer des chatbots formés à partir de données personnalisées !
Ce ne sont là que quelques-unes des possibilités offertes par les encastrements vectoriels.
Les propriétés fondamentales des bases de données vectorielles sont, bien sûr, le fait qu'elles peuvent stocker et traiter efficacement les vecteurs, qu'elles sont parfaites pour travailler avec des données à très haute dimension et qu'elles permettent des requêtes très rapides.
Avec une base de données relationnelle traditionnelle, les utilisateurs sont obligés de traiter des données structurées, car les bases de données relationnelles gèrent des colonnes et des lignes de données dans des tableaux. Les utilisateurs sont également contraints d'utiliser des progiciels tiers pour traiter les bases de données relationnelles et les processus liés aux vecteurs, car les bases de données structurées ne sont pas en mesure de stocker ou d'effectuer des recherches à partir d'incorporations vectorielles de manière native.
Les bases de données vectorielles sont conçues pour ce type de travail : Les données sont stockées et traitées sous forme de vecteurs, ce qui signifie que des applications plus complexes, axées sur l'IA, peuvent être construites simplement. Les bases de données vectorielles sont également connues pour leurs performances, leur capacité à évoluer, leur flexibilité et leur fiabilité. Ils sont conçus pour traiter des ensembles de données volumineux, sont capables de prendre en charge des données non structurées et semi-structurées, et permettent aux développeurs de gérer leurs projets avec souplesse.
Voici un aperçu plus approfondi de la différence entre les bases de données vectorielleset les bases de données relationnelles traditionnelles :
|
Aspect |
Bases de données vectorielles |
Bases de données relationnelles traditionnelles |
|
Modèle de données primaires |
Stocke les données sous forme de vecteurs à haute dimension (souvent des centaines de milliers de dimensions). |
Stocke des données structurées dans des tableaux de lignes et de colonnes dactylographiées. |
|
Paradigme de base de l'interrogation |
Recherche de similarité (par exemple, le plus proche voisin) sur les vecteurs intégrés. |
Requêtes de correspondance exacte, d'intervalle, d'agrégation et de jointure sur des colonnes bien définies. |
|
Prise en charge native des encastrements |
Stockage intégré, indexation (par exemple, HNSW, IVF) et récupération rapide des encastrements vectoriels. |
Pas de type de vecteur natif ; nécessite des extensions externes ou des pipelines pour gérer les incorporations. |
|
La performance à l'échelle |
Optimisé pour la recherche de similarités en moins d'une seconde sur des millions, voire des milliards de vecteurs. |
Optimisé pour les transactions ACID et les opérations relationnelles ; la recherche vectorielle est lente ou déchargée. |
|
Flexibilité des données |
Traite les données non structurées et semi-structurées (texte, images, audio) une fois converties en vecteurs. |
Les données non structurées doivent être transformées ou stockées séparément (par exemple, les BLOB). |
|
Modèle d'évolutivité |
Partage horizontal des index vectoriels ; conçu pour un fonctionnement distribué. |
Mise à l'échelle verticale et horizontale mature pour les données tabulaires, mais les index s'envolent avec les vecteurs à haute dimension. |
|
Flux de travail du développeur |
Un système pour le stockage d'enregistrements et l'exécution de requêtes d'IA/sémantique ; une pile plus simple pour les applications de ML/AI. |
Nécessite des magasins de vecteurs ou des bibliothèques séparées, ainsi qu'un code ETL pour se synchroniser avec la base de données relationnelle. |
|
Cas d'utilisation typiques |
Recherche sémantique, recommandation, recherche d'images/audio, RAG pour LLM, détection d'anomalies. |
Applications OLTP/OLAP, registres financiers, inventaire, CRM, analyses BI traditionnelles. |
|
Points forts |
Vitesse de recherche en haute dimension, simplicité pour les projets d'intelligence artificielle, échelle, flexibilité. |
Cohérence forte (ACID), outils matures, analyses SQL riches, jointures complexes. |
|
Compromis / limites |
Plus faible pour les jointures relationnelles complexes et les transactions sur plusieurs lignes. |
Faible prise en charge native de la similarité vectorielle, moins adaptée aux charges de travail à forte intensité d'IA. |
Si beaucoup connaissent MongoDB comme une base de données NoSQL basée sur des documents, nombreux sont ceux qui ignorent qu'il s'agit en fait d'une base de données vectorielle, grâce à MongoDB Atlas Vector Search !
Compte tenu des racines de MongoDB en tant que base de données NoSQL, ceux qui découvrent ce type de base de données pourraient bénéficier d'une introduction à NoSQL.
La puissance de MongoDB en tant que base de données vectorielles réside dans le fait que les encastrements vectoriels s'intègrent naturellement dans son modèle de document flexible. MongoDB Atlas Vector Search permet aux développeurs de stocker et d'interroger des encastrements vectoriels directement à l'intérieur de n'importe quelle collection. Cela signifie que vos encastrements vectoriels sont stockés directement à côté de vos données sources pour une consultation aisée.
Grâce à ce format, les développeurs sont en mesure d'effectuer une recherche hybride, quiest une combinaison de recherche en texte intégral et de recherche sémantique, avec l'avantage supplémentaire de garantir l'affichage non seulement de résultats contextuellement similaires, mais aussi de résultats synonymes. Nous pouvons considérer la recherche hybride comme un bibliothécaire super intelligent qui non seulement trouve des livres portant exactement le même titre que celui que vous avez demandé, mais qui vous suggère également des livres dont l'histoire est similaire à la vôtre !
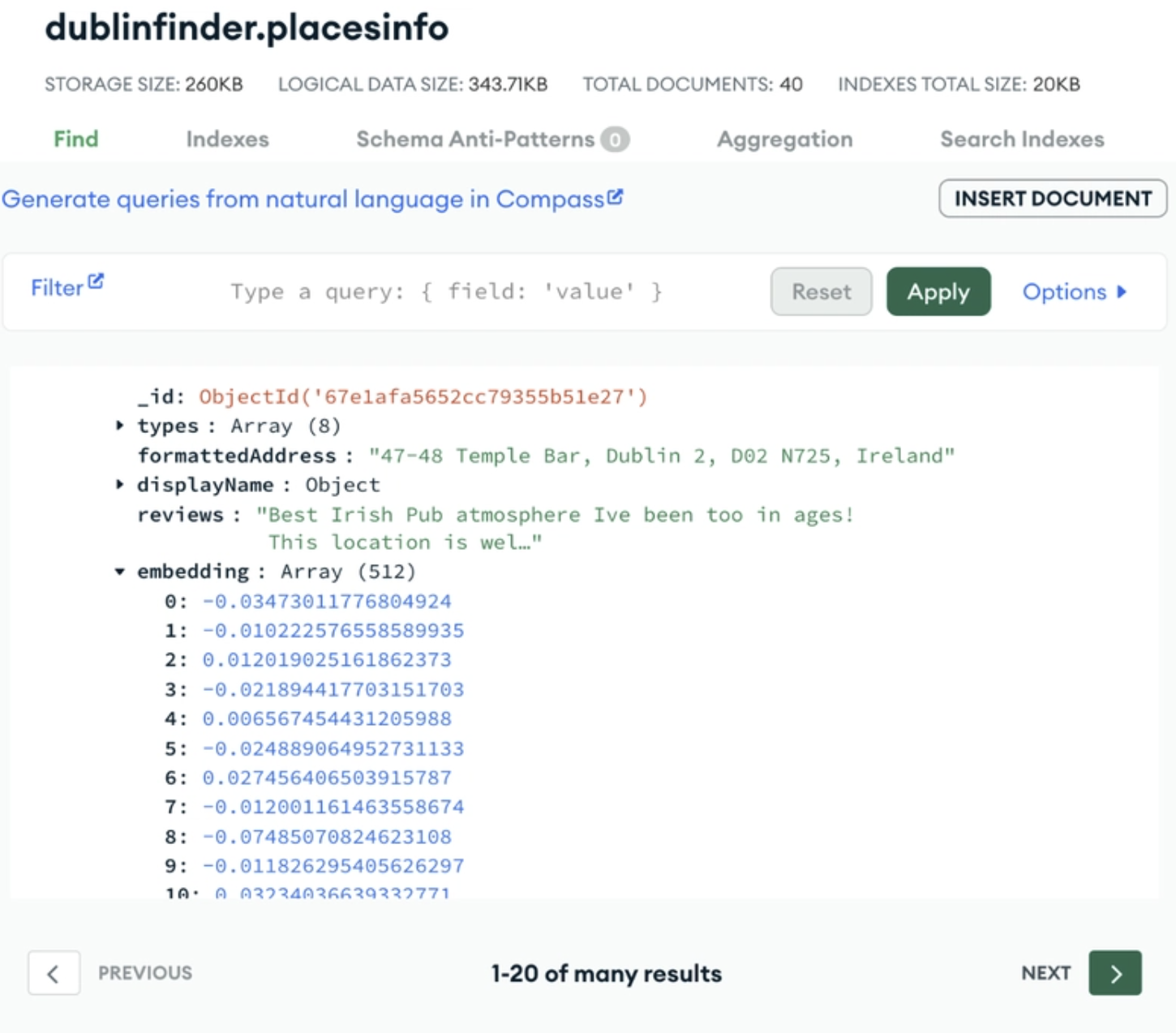
Un exemple de stockage de votre intégration vectorielle à côté de vos données sources dans MongoDB Atlas. Source de l'image.
Un autre avantage de ce format est que les développeurs peuvent utiliser pleinement l'ensemble de la plateforme MongoDB dans leurs applications d'IA très performantes et complexes. Des fonctionnalités telles que le traitement de flux, l'analyse en temps réel, les requêtes géospatiales et bien d'autres encore peuvent être facilement intégrées dans une seule et même application.
L'acquisition récente de Voyage AI par MongoDBpermet à de simplifier encore plus ce processus. Les modèles d'intégration de classe mondiale et les réankers fournis permettent aux développeurs de transformer leurs données en vecteurs d'une précision extrêmement élevée, compétitifs dans l'espace, permettant une inférence rapide et une prise en charge multilingue.
Voyons comment démarrer avec MongoDB Atlas Vector Search.
Pour commencer à utiliser MongoDB Atlas Vector Search, veuillez suivrele guide de démarrage rapidequi vous guidera à travers un processus d'installation de 15 minutes.
Il vous montrera comment :
Les bases de données vectorielles se sont avérées indispensables à la création d'applications complexes d'intelligence artificielle. Elles facilitent le processus de développement lorsqu'il s'agit d'intégrer des vecteurs, ce qui est nécessaire pour ces applications plus avancées, et la beauté de MongoDB est que les développeurs n'ont pas besoin de réinventer toute leur pile pour commencer à en tirer profit.
En utilisant la puissance du modèle documentaire, MongoDB permet aux développeurs de disposer de leur base de données vectorielle. Il est possible de combiner en un seul endroit des champs structurés, des données non structurées, et des encastrements à haute dimension !
Quelques points clés à retenir :
Pour vraiment comprendre la puissance d'une base de données vectorielle dans votre application d'IA,créez un cluster gratuitvia la plateforme MongoDB et essayez-le par vous-même.
Apprenez à travailler avec des LLM en Python directement dans votre navigateur

Apprenez-en plus sur MongoDB avec ces cours !
Cours
Cours
Cours