
Curso
Introducción a MongoDB en Python
3 h
24K
Con la inteligencia artificial infiltrándose y remodelando todas las industrias, la atención se centra siempre en las nuevas características y funcionalidades, pero ¿qué ocurre entre bastidores? Detrás de cada aplicación de IA hay algo un poco menos glamuroso pero increíblemente crucial: la infraestructura que la alimenta. Entonces, ¿qué herramientas hacen posible que prospere el machine learning?
En un mundo basado en los datos, todo empieza realmente por cómo se almacenan los datos y, lo que es más importante, cómo se buscan. Aquí es donde entran en juego las bases de datos vectoriales.
Entonces, ¿qué es exactamente una base de datos vectorial? Una base de datos vectorial es una base de datos diseñada específicamente para almacenar y buscar sobre incrustaciones vectoriales, lo que permite a los programadores utilizar diversas funcionalidades de IA como la búsqueda semántica, el reconocimiento de imágenes, los chatbots y mucho más.
Pero, ¿qué significa eso exactamente? Para entender bien qué es una base de datos vectorial, retrocedamos un par de pasos. Desmitifiquemos estas bases de datos integrales cubriendo lo básico desde el principio, empezando por el actor clave de este proceso: el vector incrustado.
Un vector (en el contexto de la inteligencia artificial) es simplemente una lista de números que representa el significado semántico de una imagen, una frase, audio e incluso vídeo. Esta secuencia de números ayuda a los ordenadores a comprender en qué se parece cada dato: Colocan los datos (como palabras o imágenes) como puntos en un "mapa matemático" en el que los conceptos similares están más cerca unos de otros.
Podemos pensar en las incrustaciones vectoriales como si convirtiéramos un dato en una coordenada GPS: ¡datos con significados similares (como "perro" y "cachorro") acaban en el mismo vecindario!
¿Por qué necesitamos convertir nuestros datos en vectores? Pues imagínate intentar explicar a una máquina la diferencia entre un gato y un perro. Mientras que los seres humanos son capaces de comprender esta diferencia, una máquina sólo puede captar y comprender los números: Es imposible explicarle a tu portátil la diferencia entre Toto y Garfield.
Al convertir tus datos en estructuras vectoriales específicas en las que cada número está ordenado de forma única según esos datos de origen, ¡tu máquina es capaz de comprender las relaciones entre varios puntos de datos!
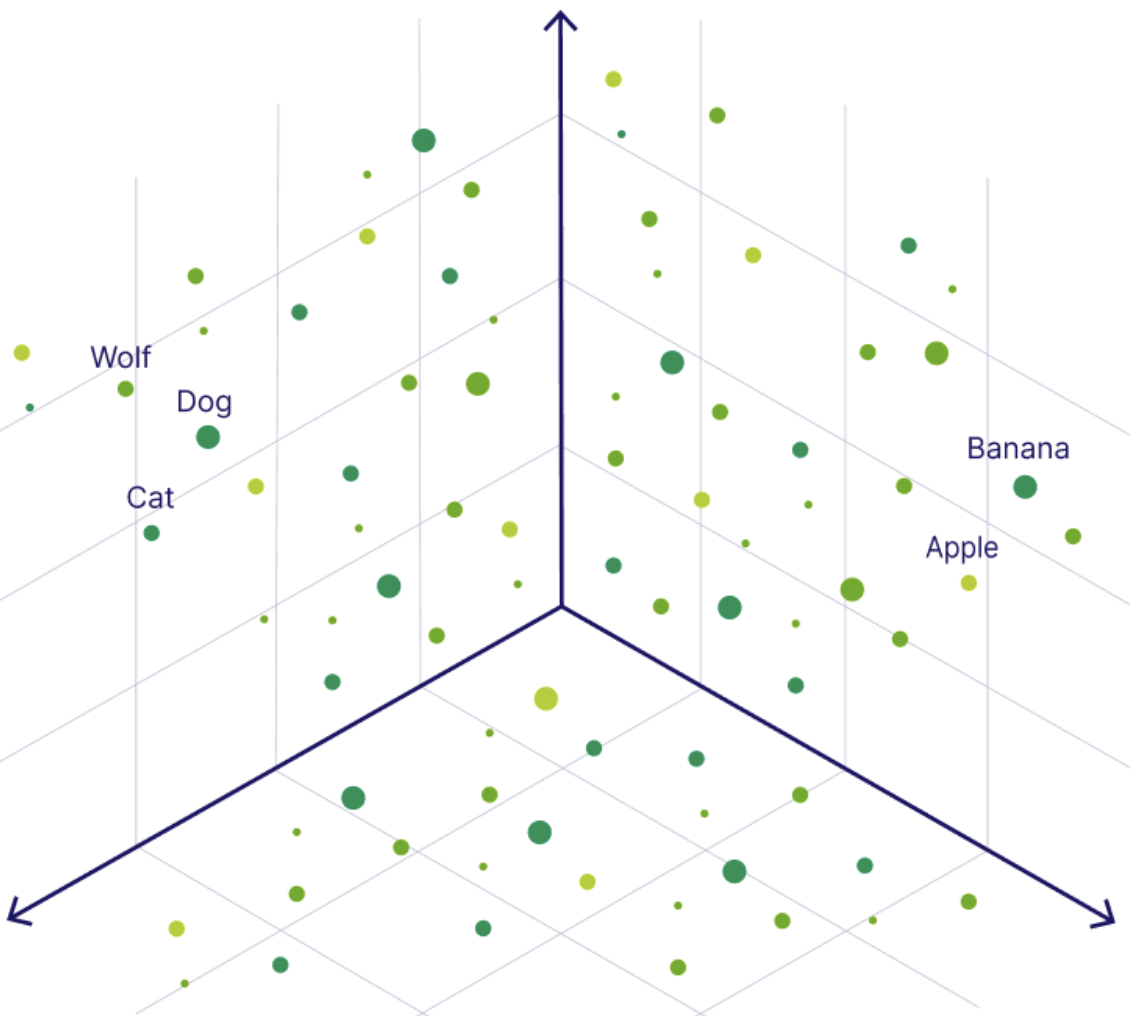
Mostrar una incrustación vectorial en el espacio multidimensionale. Fuente de la imagen.
Repasemos cómo es esto posible hablando de la búsqueda por similitud.
La búsqueda por similitud es la técnica utilizada para ayudar a encontrar los documentos más parecidos a la consulta original de un usuario. Buscar con vectores es como preguntarse: "¿Cuál de estas imágenes se parece más a un gato?", en lugar de limitarse a buscar la palabra "gato" exactamente.
Como estamos tratando con vectores en un espacio multidimensional, en este proceso intervienen algunas matemáticas para ayudarnos a averiguar qué incrustaciones son más parecidas.
Existen multitud de algoritmos de búsqueda de similitudes, pero los tres más comunes son:
La similitud del coseno me mide el ángulo entre dos vectores (no le importa el tamaño del vector) y es la más utilizada para la incrustación de textos, la similitud semántica y los sistemas de recomendación. Ayuda a los programadores a comparar la dirección general de los vectores, lo que a su vez ayuda a averiguar el contenido general de los documentos, por eso es tan importante para los temas indicados.
La distancia euclidiana midees la distancia en línea recta entre dos vectores en el espacio. Una buena forma de pensar en ello es medir el camino más corto entre dos puntos de un mapa.
Esta distancia es la más sencilla, ya que si la distancia calculada es muy pequeña, significa que las coordenadas vectoriales están muy cerca, o son muy parecidas entre sí.
Como esta métrica es muy sensible a las magnitudes, es más útil cuando las incrustaciones tienen que ver con valores numéricos. Esto es especialmente útil para los motores de recomendación, que permiten a los usuarios saber qué pedir a continuación en función de cuántas veces han comprado un artículo en el pasado.
La similitud del producto de puntos mide no sólo el producto de las magnitudes de los vectores, sino también el coseno del ángulo entre ellos. Esto significa que el producto punto se preocupa tanto de la longitud (magnitud) como de la dirección de los vectores.
Cuando los vectores se normalizan (la magnitud del vector es uno, pero la dirección sigue siendo la misma), la similitud producto punto pasa a ser la misma que la similitud coseno, puesto que ya no se tiene en cuenta la magnitud.
El producto punto de similitud es el más utilizado en ámbitoscomo el procesamiento del lenguaje natural (PLN) y la visión por ordenador.
Así pues, ahora tienes tus datos brutos representados como incrustaciones vectoriales. Vamos a sumergirnos en todas las increíbles posibilidades que se abren al tener tus datos representados por estas incrustaciones.
La búsqueda semántica es una forma de buscar datos basada en el significado real de la consulta de un usuario, no sólo en la búsqueda de coincidencias exactas. Esto significa que, en lugar de buscar basándose en palabras clave específicas, se mostrarán resultados aunque una palabra esté mal escrita, y se mostrarán resultados basados en sinónimos de la consulta original.
Por ejemplo, si un usuario busca "las mejores cafeterías cerca de mí", con la búsqueda exacta sólo aparecerán las específicamente etiquetadas como "cafeterías", mientras que un buscador semántico entendería y mostraría los lugares que tienen "té", "café", "pastelería" u otros hallazgos que una comprensión contextual más profunda daría como resultado.
Entonces, ¿cómo se hace posible esta búsqueda? ¡Incrustaciones vectoriales! Digamos que incrustamos la consulta de un usuario y los datos (como las descripciones de la ubicación). Esto permite compararlos entre sí en un espacio multidimensional, buscando los vectores más próximos entre sí mediante métodos como la búsqueda de similitudes.
Por ejemplo, si el usuario tiene la consulta "las mejores cafeterías cerca de mí" y una base de datos llena de descripciones de lugares de Google Maps que se han incrustado, la búsqueda semántica mostrará los lugares cuyas incrustaciones sean más similares a la consulta original, ¡incluso si la palabra "cafetería" no se utiliza nunca en esas descripciones de lugares!
Los sistemas de recomendación utilizan datos para ayudar a las personas a encontrar lo que estadísticamente más les gustaría, basándose en compras anteriores, historial de búsqueda, información demográfica y del entorno, etc. Se utilizan en casi todos los sectores, desde el entretenimiento hasta las finanzas.
Algunas de las plataformas más obvias que utilizan sistemas de recomendación son empresas como Spotify, Netflix y Amazon, pero están en todos los sectores, especialmente a medida que más y más empresas adoptan políticas de IA.
Están totalmente entrenados para comprender las distintas características, decisiones previas y preferencias de los usuarios basándose en multitud de interacciones, como clics, me gusta y visualizaciones. Todos estamos familiarizados con que nos recomienden nuevos productos, películas o canciones basándose en compras anteriores, pero ¿cómo puede saber un algoritmo lo que nos puede gustar? ¡Incrustaciones vectoriales!
Desde un nivel muy alto, los sistemas de recomendación comparan varios elementos con las preferencias conocidas de un usuario. Para que estas recomendaciones tengan sentido, tanto los usuarios como los objetos se convierten en incrustaciones vectoriales. Existen dos técnicas muy comunes para ello: las recomendaciones basadas en el contenido y el filtrado colaborativo.
Utilicemos el cine como ejemplo. Con las recomendaciones basadas en el contenido, las películas se incrustan en función de sus diversas características, y los usuarios se incrustan en función de las películas que han visto en el pasado. Este sistema puede entonces recomendar nuevas películas con los vectores más próximos a los vectores de preferencia del usuario, o a las películas que ha visto en el pasado.
Con el filtrado colaborativo, se tienen en cuenta muchos usuarios. En lugar de centrarse en un único usuario y en un artículo, el filtrado colaborativo encuentra a varios usuarios que tienen los vectores más parecidos al tuyo y recomienda artículos o películas que les han gustado.
Otro gran uso de las incrustaciones vectoriales es con los chatbots o RAG.
La generación aumentada por recuperación es una forma de utilizar verdadera y plenamente las capacidades de los grandes modelos lingüísticos (LLM), integrando información externa y actualizada para que los LLM puedan generar respuestas más precisas. Esto se debe a que los LLM se entrenan normalmente con datos estáticos, por lo que tienen una base de conocimientos limitada y no pueden acceder a datos locales o personalizados.
Con las incrustaciones vectoriales, es posible guardar datos personalizados en una base de datos vectorial, ¡lo que permite crear una base de datos totalmente personalizable de datos personalizados que puede utilizarse en cualquier proyecto! Como los datos se almacenan como incrustaciones vectoriales, es posible recuperar documentos semánticamente similares directamente de la base de datos a partir de la consulta del usuario.
Lo bueno de RAG es que es perfecto para diversas tareas, como responder preguntas y generar texto. Esto significa que es perfecto para construir chatbots entrenados con datos personalizados.
Éstas son sólo algunas de las posibilidades que ofrecen las incrustaciones vectoriales.
Las propiedades fundamentales de las bases de datos vectoriales son, por supuesto, el hecho de que pueden almacenar y manejar vectores de forma eficiente, son estupendas para trabajar con datos de muy alta dimensión y permiten realizar consultas superrápidas.
Con una base de datos relacional tradicional, los usuarios se ven obligados a tratar con datos estructurados, ya que las bases de datos relacionales manejan columnas y filas de datos dentro de tablas. Los usuarios también se ven obligados a utilizar paquetes de terceros para tratar con bases de datos relacionales y procesos relacionados con vectores, ya que las bases de datos estructuradas no pueden almacenar ni buscar sobre incrustaciones vectoriales de forma nativa.
Las bases de datos vectoriales están diseñadas para este tipo de trabajo: Los datos se almacenan y procesan como vectores, lo que significa que se pueden crear de forma sencilla aplicaciones más complejas centradas en la IA. Las bases de datos vectoriales también son conocidas por su rendimiento, capacidad de ampliación, flexibilidad y fiabilidad. Están diseñados para manejar conjuntos de datos masivos, son capaces de admitir datos no estructurados y semiestructurados, y permiten a los programadores flexibilidad sobre sus proyectos.
Aquí tienes una visión más profunda de la diferencia entre las bases de datos vectorialesy las bases de datos relacionales tradicionales:
|
Aspecto |
Bases de datos vectoriales |
Bases de datos relacionales tradicionales |
|
Modelo de datos primarios |
Almacena los datos como vectores de alta dimensión (a menudo cientos de miles de dimensiones). |
Almacena datos estructurados en tablas de filas y columnas mecanografiadas. |
|
Paradigma básico de consulta |
Búsqueda de similitudes (por ejemplo, vecino más próximo) sobre incrustaciones vectoriales. |
Consultas de coincidencia exacta, rango, agregación y unión en columnas bien definidas. |
|
Soporte nativo para incrustaciones |
Almacenamiento incorporado, indexación (por ejemplo, HNSW, IVF) y recuperación rápida de incrustaciones vectoriales. |
No tiene tipo vectorial nativo; requiere extensiones externas o canalizaciones para manejar las incrustaciones. |
|
Rendimiento a escala |
Optimizado para la búsqueda de similitudes en menos de un segundo entre millones y miles de millones de vectores. |
Optimizado para transacciones ACID y operaciones relacionales; la búsqueda vectorial es lenta o se descarga. |
|
Flexibilidad de los datos |
Maneja entradas no estructuradas y semiestructuradas (texto, imágenes, audio) una vez convertidas en vectores. |
Mejor con esquemas estrictamente estructurados; los datos no estructurados deben transformarse o almacenarse por separado (por ejemplo, BLOBs). |
|
Modelo de escalabilidad |
Fragmentación/partición horizontal de índices vectoriales; diseñado para funcionamiento distribuido. |
Escalado vertical y horizontal maduro para datos tabulares, pero globo de índices con vectores de alta dimensión. |
|
Flujo de trabajo de los programadores |
Un sistema para almacenar incrustaciones + ejecutar consultas de IA/semántica; pila más sencilla para aplicaciones de ML/AI. |
Requiere almacenes o bibliotecas vectoriales independientes, además de código ETL glue para sincronizar con la BD relacional. |
|
Casos de uso típicos |
Búsqueda semántica, recomendación, recuperación de imágenes/audio, RAG para LLMs, detección de anomalías. |
Aplicaciones OLTP/OLAP, libros de contabilidad, inventario, CRM, analítica BI tradicional. |
|
Puntos fuertes |
Alta velocidad de búsqueda dimensional, simplicidad para proyectos de IA, escala, flexibilidad. |
Coherencia sólida (ACID), herramientas maduras, análisis SQL enriquecidos, uniones complejas. |
|
Contrapartidas / límites |
Más débil en uniones relacionales complejas y transacciones de varias filas. |
Escaso soporte nativo para la similitud vectorial, menos adecuado para cargas de trabajo intensivas en IA. |
Aunque mucha gente conoce MongoDB como una base de datos NoSQL basada en documentos, muchos no saben que en realidad es una base de datos vectorial, ¡gracias a MongoDB Atlas Vector Search!
Dadas las raíces de MongoDB como base de datos NoSQL, quienes no conozcan este tipo de base de datos podrían beneficiarse deuna Introducción a NoSQL.
El aspecto más potente de MongoDB como base de datos vectorial es la naturalidad con la que las incrustaciones vectoriales encajan en su flexible modelo de documento. Atlas Vector Search de MongoDB permite a los programadores almacenar y consultar incrustaciones vectoriales directamente dentro de cualquier colección. Esto significa que tus incrustaciones vectoriales se almacenan directamente junto a tus datos de origen para facilitar su consulta.
Gracias a este formato, los programadores pueden realizar búsquedas híbridas, queson una combinación de búsqueda de texto completo y búsqueda semántica, con la ventaja adicional de garantizar que no sólo se muestren resultados contextualmente similares, sino también resultados sinónimos. Podemos pensar en la búsqueda híbrida como si tuviéramos un bibliotecario superinteligente que no sólo encuentra libros con el mismo título exacto que has pedido, ¡sino que también te sugiere otros con historias similares!
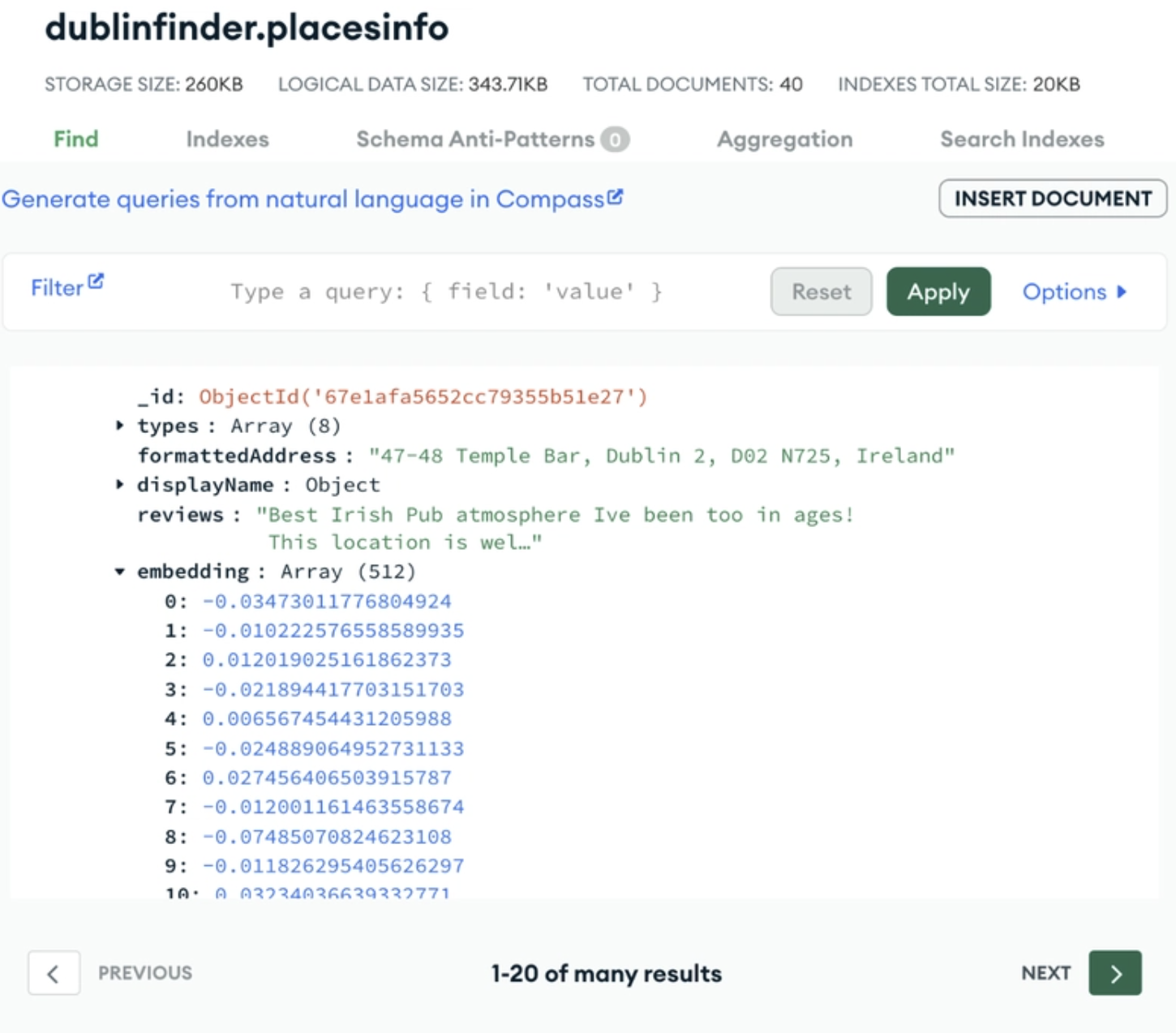
Un ejemplo de almacenamiento de tu incrustación vectorial junto a tus datos de origen en MongoDB Atlas. Fuente de la imagen.
Otra ventaja de este formato es que los programadores pueden utilizar plenamente toda la plataforma de MongoDB en sus aplicaciones de IA de alto rendimiento y complejidad. Funciones como el procesamiento de flujos, el análisis en tiempo real, las consultas geoespaciales, etc., pueden incorporarse fácilmente a cualquier aplicación.
La reciente adquisiciónde Voyage AI por parte de MongoDBayuda a a que este proceso sea aún más sencillo. Los modelos de incrustación y rerankers de categoría mundial que se proporcionan permiten a los programadores que sus datos se transformen en vectores que tienen una precisión extremadamente alta, son competitivos en el espacio y permiten una inferencia rápida y soporte multilingüe.
Vamos a repasar cómo empezar con la Búsqueda Vectorial Atlas de MongoDB.
Para empezar a utilizar MongoDB Atlas Vector Search, siguela guía de inicio rápido quete llevará a través de un proceso de configuración de 15 minutos.
Te mostrará cómo hacerlo:
Las bases de datos vectoriales han demostrado ser una necesidad para construir aplicaciones complejas de IA. Ayudan a suavizar el proceso de desarrollo cuando se trabaja con incrustaciones vectoriales que son necesarias para estas aplicaciones más avanzadas, y lo bueno de MongoDB es que los programadores no necesitan reinventar toda su pila para empezar a beneficiarse de ellas.
Al utilizar la potencia del modelo de documentos, MongoDB dota a los programadores de su base de datos vectorial. ¡Es posible combinar campos estructurados, datos no estructurados e incrustaciones de alta dimensión en un solo lugar!
Algunos puntos clave:
Para comprender realmente el poder que tendrá una base de datos vectorial en tu aplicación de IA,crea un clúster gratuitoa través de la plataforma de MongoDB y pruébalo por ti mismo.
Aprende a trabajar con LLMs en Python directamente en tu navegador

¡Aprende más sobre MongoDB con estos cursos!
Curso
Curso
Curso
blog
Kurtis Pykes
11 min
blog
blog
Mike Shakhomirov
11 min
Tutorial
DataCamp Team