
Curso
Introduction to MongoDB in Python
3 h
24K
Com a inteligência artificial se infiltrando e remodelando todos os setores, o foco principal está sempre nos novos recursos e funcionalidades, mas o que acontece nos bastidores? Por trás de cada aplicativo de IA há algo um pouco menos glamouroso, mas incrivelmente crucial: a infraestrutura que o alimenta. Então, quais ferramentas possibilitam que o machine learning prospere?
Em um mundo orientado por dados, tudo realmente começa com a forma como os dados são armazenados e, mais importante, como os dados são pesquisados. É nesse ponto que os bancos de dados vetoriais entram em ação.
Então, o que exatamente é um banco de dados vetorial? Um banco de dados vetorial é um banco de dados projetado especificamente para armazenar e pesquisar em incorporações vetoriais, permitindo que os desenvolvedores utilizem várias funcionalidades de IA, como pesquisa semântica, reconhecimento de imagens, chatbots e muito mais.
Mas o que isso significa exatamente? Para que você entenda completamente o que é um banco de dados vetorial, vamos voltar algumas etapas. Vamos desmistificar esses bancos de dados integrais, abordando nossos conceitos básicos desde o início, começando com o principal participante desse processo: a incorporação de vetores.
Um vetor (no contexto da inteligência artificial) é simplesmente uma lista de números que representa o significado semântico de uma imagem, uma frase, um áudio e até mesmo um vídeo. Essa sequência de números ajuda os computadores a entender como cada dado é semelhante ao outro: Eles colocam os dados (como palavras ou imagens) como pontos em um "mapa matemático" em que conceitos semelhantes estão mais próximos.
Você pode pensar em incorporação de vetores como se estivesse transformando um dado em uma coordenada de GPS - dados com significados semelhantes (como "cachorro" e "filhote") acabam na mesma vizinhança!
Por que precisamos transformar nossos dados em vetores? Bem, imagine tentar explicar a uma máquina a diferença entre um gato e um cachorro. Embora os seres humanos sejam capazes de entender essa diferença, uma máquina só pode compreender e entender números: É impossível explicar ao seu laptop a diferença entre o Toto e o Garfield.
Ao transformar seus dados em estruturas vetoriais específicas, em que cada número é ordenado exclusivamente de acordo com os dados de origem, sua máquina é capaz de entender as relações entre vários pontos de dados!
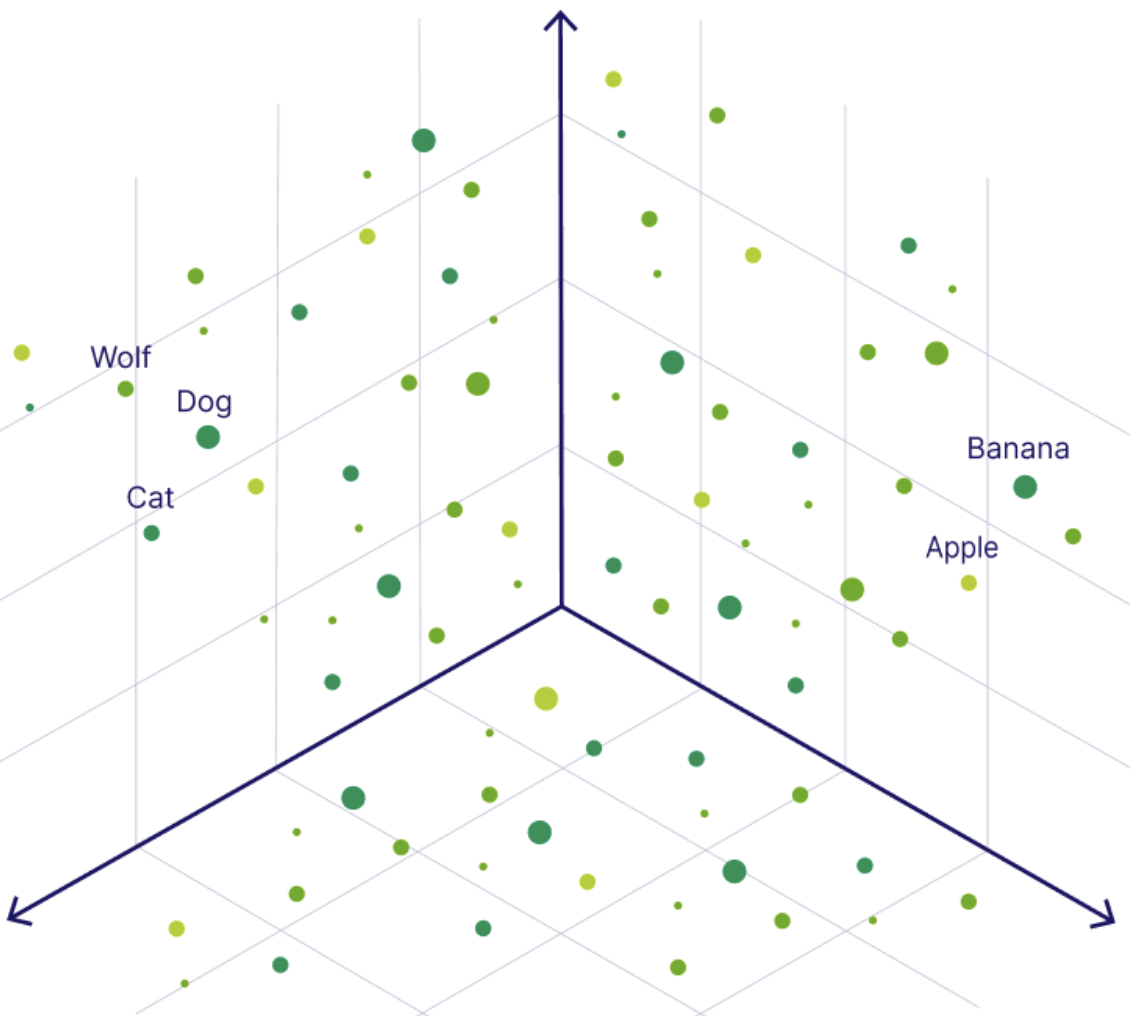
Apresentando uma incorporação de vetor no espaço multidimensionale. Fonte da imagem.
Vamos explicar como isso é possível, discutindo a pesquisa por similaridade.
A pesquisa de similaridade é a técnica usada para ajudar a encontrar os documentos mais semelhantes à consulta original de um usuário. Fazer uma pesquisa com vetores é como perguntar: "Qual dessas imagens se parece mais com um gato?" em vez de apenas corresponder exatamente à palavra "gato".
Como estamos lidando com vetores em um espaço multidimensional, um pouco de matemática é envolvida nesse processo para nos ajudar a descobrir quais são as incorporações mais parecidas.
Há uma infinidade de algoritmos de pesquisa de similaridade, mas os três mais comuns são:
A similaridade de cosseno mmede o ângulo entre dois vetores (não se importa com o tamanho do vetor) e é mais comumente usada para incorporação de texto, similaridade semântica e sistemas de recomendação. Ele ajuda os desenvolvedores a comparar a direção geral dos vetores, o que, por sua vez, ajuda a descobrir o conteúdo geral dos documentos, razão pela qual é tão importante para os tópicos listados.
A distância euclidiana medea distância em linha reta entre dois vetores no espaço. Uma ótima maneira de pensar sobre isso é medir o caminho mais curto entre dois pontos em um mapa!
Essa distância é a mais direta, pois se a distância calculada for muito pequena, isso significa que as coordenadas do vetor estão muito próximas ou são muito semelhantes entre si.
Como essa métrica é muito sensível a magnitudes, ela é mais útil quando as incorporações têm a ver com valores numéricos. Isso é especialmente útil para mecanismos de recomendação que permitem que os usuários saibam o que pedir em seguida com base no número de vezes que compraram um item no passado.
A similaridade do produto escalar mede não apenas o produto das magnitudes dos vetores, mas também o cosseno do ângulo entre eles. Isso significa que o produto escalar se preocupa tanto com o comprimento (magnitude) quanto com a direção dos vetores!
Quando os vetores são normalizados (a magnitude do vetor é uma, mas a direção permanece a mesma), a similaridade do produto escalar se torna a mesma que a similaridade do cosseno, pois a magnitude não é mais levada em conta.
A similaridade do produto de pontos é mais comumente usada em áreas como processamento de linguagem natural (NLP) e visão computacional.
Portanto, agora você tem seus dados brutos representados como embeddings de vetores. Vamos nos aprofundar em todas as incríveis possibilidades que se abrem quando você tem seus dados representados por esses embeddings.
A pesquisa semântica é uma maneira de pesquisar dados com base no significado real da consulta de um usuário, e não apenas na pesquisa de correspondência exata. Isso significa que, em vez de pesquisar com base em palavras-chave específicas, os resultados serão exibidos mesmo que uma palavra esteja escrita incorretamente, e os resultados serão exibidos com base em sinônimos da consulta original.
Por exemplo, se um usuário estiver pesquisando "os melhores cafés perto de mim", com a pesquisa exata, apenas os "cafés" especificamente rotulados aparecerão, enquanto um mecanismo de pesquisa semântica entenderia e mostraria lugares que têm "chá", "café", "bolos" ou outras descobertas que uma compreensão contextual mais profunda resultaria.
Então, como essa busca é possível? Embeddings vetoriais! Digamos que incorporamos a consulta de um usuário e os dados (como descrições de locais). Isso permite compará-los entre si no espaço multidimensional, procurando os vetores mais próximos uns dos outros usando métodos como a pesquisa de similaridade.
Por exemplo, se o usuário tiver a consulta "melhores cafés perto de mim" e um banco de dados repleto de descrições de locais do Google Maps que foram incorporadas, a pesquisa semântica mostrará os locais cujas incorporações são mais semelhantes à consulta original, mesmo que a palavra "café" nunca seja usada nessas descrições de locais!
Os sistemas de recomendação usam dados para ajudar as pessoas a encontrar o que, estatisticamente, mais lhes agradaria, com base em compras anteriores, histórico de pesquisa, informações ambientais e demográficas e muito mais. Eles são usados em quase todos os setores, desde entretenimento até finanças.
Algumas das plataformas mais óbvias que utilizam sistemas de recomendação são empresas como Spotify, Netflix e Amazon, mas elas estão em todos os setores, especialmente à medida que mais e mais empresas adotam políticas de IA.
Eles são totalmente treinados para entender as várias características, decisões anteriores e preferências dos usuários com base em várias interações, incluindo cliques, curtidas e visualizações. Portanto, todos nós estamos familiarizados com a recomendação de novos produtos, filmes ou músicas com base em compras anteriores, mas como um algoritmo pode saber do que podemos gostar? Embeddings vetoriais!
Em um nível muito alto, os sistemas de recomendação comparam vários itens com as preferências conhecidas de um usuário. Para ajudar a tornar essas recomendações significativas, tanto os usuários quanto os itens são convertidos em embeddings de vetores. Há duas técnicas muito comuns para isso: recomendações baseadas em conteúdo e filtragem colaborativa.
Vamos usar filmes como exemplo. Com as recomendações baseadas em conteúdo, os filmes são incorporados com base em seus vários recursos, e os usuários são incorporados com base nos filmes que assistiram no passado. Esse sistema pode então recomendar novos filmes com vetores mais próximos dos vetores de preferência do usuário ou dos filmes que ele assistiu no passado.
Com a filtragem colaborativa, muitos usuários são levados em consideração. Em vez de se concentrar apenas em um único usuário e um item, a filtragem colaborativa encontra vários usuários que têm vetores mais próximos dos seus e recomenda itens ou filmes de que eles gostaram.
Outro ótimo uso para embeddings vetoriais é com chatbots ou RAG.
A geração aumentada por recuperação é uma maneira de realmente utilizar plenamente os recursos dos modelos de linguagem grandes (LLMs), integrando informações externas e atualizadas para que os LLMs possam gerar respostas mais precisas. Isso ocorre porque os LLMs normalmente são treinados em dados estáticos, portanto, eles têm uma base de conhecimento limitada e não conseguem acessar nenhum dado local ou personalizado.
Com as incorporações vetoriais, é possível salvar dados personalizados em um banco de dados vetorial, o que permite criar um banco de dados totalmente personalizável de dados personalizados que podem ser usados em qualquer projeto! Com os dados sendo armazenados como embeddings de vetores, é possível recuperar documentos semanticamente semelhantes diretamente do banco de dados com base na consulta do usuário.
O aspecto positivo do RAG é que ele é perfeito para várias tarefas, como responder a perguntas e gerar texto. Isso significa que ele é perfeito para criar chatbots treinados com base em dados personalizados!
Esses são apenas alguns dos recursos que são possíveis com a incorporação de vetores.
As propriedades fundamentais dos bancos de dados vetoriais são, obviamente, o fato de que eles podem armazenar e manipular vetores com eficiência, são ótimos para trabalhar com dados de dimensões muito altas e permitem consultas muito rápidas.
Com um banco de dados relacional tradicional, os usuários são forçados a lidar com dados estruturados, pois os bancos de dados relacionais lidam com colunas e linhas de dados dentro de tabelas. Os usuários também são obrigados a usar pacotes de terceiros para lidar com bancos de dados relacionais e processos relacionados a vetores, já que os bancos de dados estruturados não conseguem armazenar ou pesquisar incorporação de vetores de forma nativa.
Os bancos de dados vetoriais são projetados para esse tipo de trabalho: Os dados são armazenados e processados como vetores, o que significa que aplicativos mais complexos e focados em IA podem ser criados de forma simples. Os bancos de dados vetoriais também são conhecidos por seu desempenho, capacidade de dimensionamento, flexibilidade e confiabilidade. Eles são projetados para lidar com conjuntos de dados maciços, são capazes de suportar dados não estruturados e semiestruturados e permitem flexibilidade ao desenvolvedor em seus projetos.
Veja a seguir uma análise mais detalhada da diferença entre os bancos de dados vetoriaise os bancos de dados relacionais tradicionais:
|
Aspecto |
Bancos de dados vetoriais |
Bancos de dados relacionais tradicionais |
|
Modelo de dados primários |
Armazena dados como vetores de alta dimensão (geralmente centenas de milhares de dimensões). |
Armazena dados estruturados em tabelas de linhas e colunas digitadas. |
|
Paradigma de consulta principal |
Pesquisa de similaridade (por exemplo, o vizinho mais próximo) em embeddings de vetores. |
Consultas de correspondência exata, intervalo, agregação e união em colunas bem definidas. |
|
Suporte nativo para incorporações |
Armazenamento integrado, indexação (por exemplo, HNSW, IVF) e recuperação rápida de embeddings de vetores. |
Nenhum tipo de vetor nativo; requer extensões externas ou pipelines para lidar com embeddings. |
|
Desempenho em escala |
Otimizado para pesquisa de similaridade em menos de um segundo em milhões a bilhões de vetores. |
Otimizado para transações ACID e operações relacionais; a pesquisa vetorial é lenta ou não é carregada. |
|
Flexibilidade de dados |
Lida com entradas não estruturadas e semiestruturadas (texto, imagens, áudio) depois de convertidas em vetores. |
Melhor com esquemas estritamente estruturados; os dados não estruturados devem ser transformados ou armazenados separadamente (por exemplo, BLOBs). |
|
Modelo de escalabilidade |
Sharding/particionamento horizontal de índices vetoriais; projetado para operação distribuída. |
Escalonamento vertical e horizontal maduro para dados tabulares, mas os índices balão com vetores de alta dimensão. |
|
Fluxo de trabalho do desenvolvedor |
Um sistema para armazenar embeddings + executar consultas de IA/semântica; pilha mais simples para aplicativos de ML/IA. |
Requer armazenamentos ou bibliotecas de vetores separados, além de código de ETL para sincronizar com o banco de dados relacional. |
|
Casos de uso típicos |
Pesquisa semântica, recomendação, recuperação de imagem/áudio, RAG para LLMs, detecção de anomalias. |
Aplicativos OLTP/OLAP, registros financeiros, inventário, CRM, análise de BI tradicional. |
|
Pontos fortes |
Velocidade de pesquisa de alta dimensão, simplicidade para projetos de IA, escala e flexibilidade. |
Forte consistência (ACID), ferramentas maduras, análises SQL avançadas, junções complexas. |
|
Compensações / limites |
Mais fraco em uniões relacionais complexas e transações com várias linhas. |
Suporte nativo insatisfatório para similaridade de vetores, menos adequado para cargas de trabalho pesadas de IA. |
Embora muitas pessoas conheçam o MongoDB como um banco de dados NoSQL baseado em documentos, muitas não sabem que ele é, na verdade, um banco de dados vetorial, graças ao MongoDB Atlas Vector Search!
Dadas as raízes do MongoDB como um banco de dados NoSQL, os novatos nesse tipo de banco de dados podem se beneficiar deuma Introdução ao NoSQL.
O aspecto poderoso do MongoDB como um banco de dados vetorial é a naturalidade com que as incorporações vetoriais podem se encaixar em seu modelo de documento flexível. O MongoDB Atlas Vector Search permite que os desenvolvedores armazenem e consultem embeddings vetoriais diretamente em qualquer coleção. Isso significa que suas incorporações vetoriais são armazenadas diretamente ao lado dos dados de origem para facilitar a consulta.
Devido a esse formato, os desenvolvedores podem realizaruma pesquisa híbrida, que é uma combinação de texto completo e pesquisa semântica, com o benefício adicional de garantir que sejam mostrados não apenas resultados contextualmente semelhantes, mas também resultados sinônimos. Podemos pensar na pesquisa híbrida como um bibliotecário superinteligente que não apenas encontra livros com o mesmo título que você pediu, mas também sugere livros com histórias semelhantes!
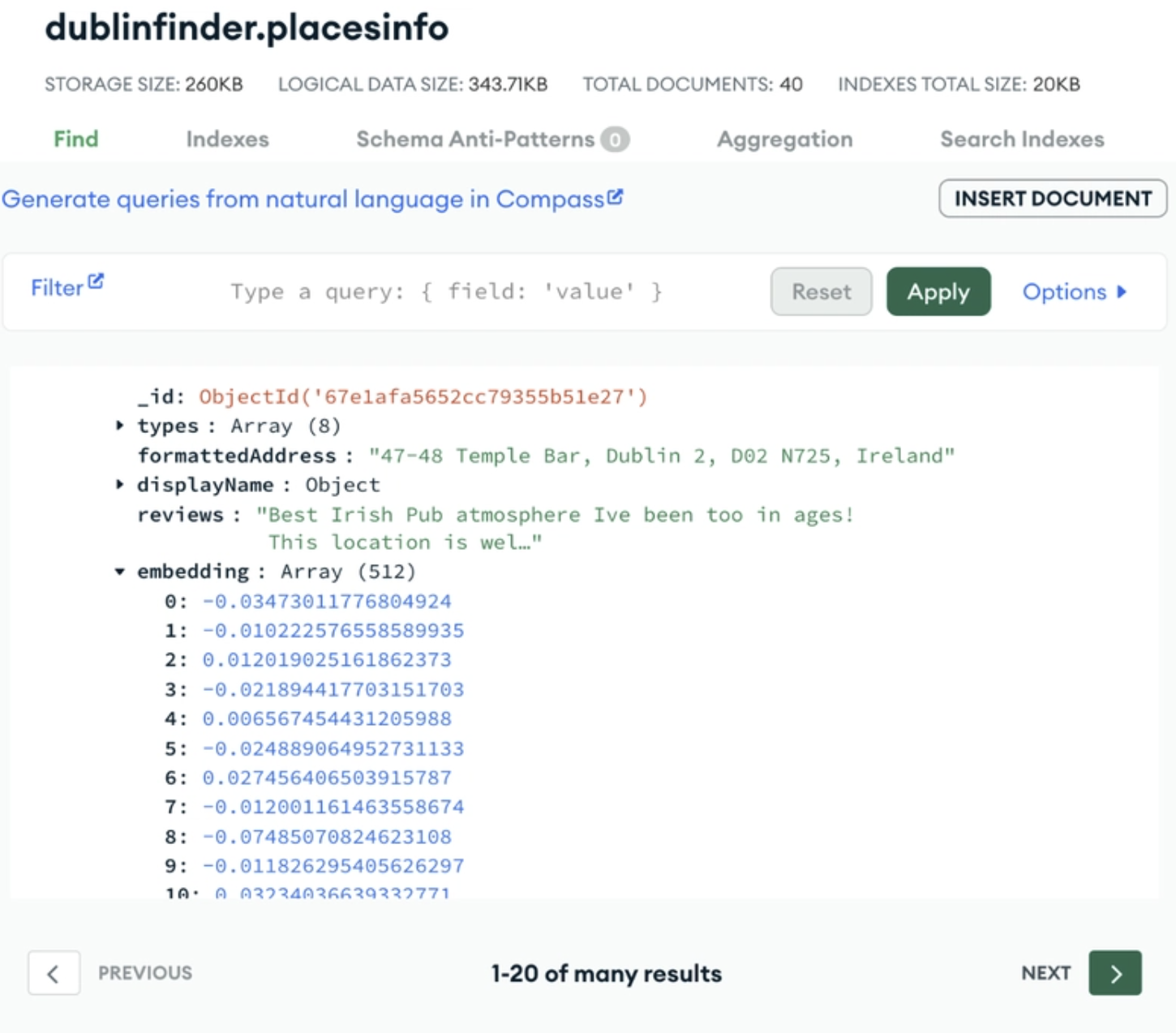
Um exemplo de armazenamento da incorporação de vetor ao lado dos dados de origem no MongoDB Atlas. Fonte da imagem.
Outro benefício desse formato é que os desenvolvedores podem utilizar totalmente a plataforma inteira do MongoDB em seus aplicativos de IA complexos e de alto desempenho. Recursos como processamento de fluxo, análise em tempo real, consultas geoespaciais e outros podem ser facilmente incorporados a um único aplicativo.
A recente aquisiçãoda Voyage AI pela MongoDBajuda o a tornar esse processo ainda mais simples. Os modelos de incorporação de classe mundial e os rerankers fornecidos permitem que os desenvolvedores tenham seus dados transformados em vetores com precisão extremamente alta, competitivos no espaço e que permitem inferência rápida e suporte a vários idiomas.
Vamos ver como você pode começar a usar o MongoDB Atlas Vector Search.
Para começar a usar o MongoDB Atlas Vector Search, sigao guia de início rápidoque levará você por um processo de configuração de 15 minutos.
Ele mostrará a você como fazer:
Os bancos de dados vetoriais provaram ser uma necessidade para a criação de aplicativos complexos de IA. Eles ajudam a facilitar o processo de desenvolvimento ao trabalhar com embeddings vetoriais necessários para esses aplicativos mais avançados, e a beleza do MongoDB é que os desenvolvedores não precisam reinventar toda a pilha para começar a se beneficiar deles.
Ao utilizar o poder do modelo de documento, o MongoDB capacita os desenvolvedores com seu banco de dados vetorial. É possível combinar campos estruturados, dados não estruturados e embeddings de alta dimensão em um único lugar!
Algumas conclusões importantes:
Para realmente entender o poder que um banco de dados vetorial terá em seu aplicativo de IA, crieum cluster gratuitopor meio da plataforma do MongoDB e experimente você mesmo.
Saiba como trabalhar com LLMs em Python diretamente em seu navegador

Saiba mais sobre o MongoDB com estes cursos!
Curso
Curso
Curso
blog
blog
Zoumana Keita
12 min
blog
Kurtis Pykes
11 min
blog
Summer Worsley
13 min

